Pandas des Anfängers, vom Anfänger, für den Anfänger [Python]
Bevor Sie diesen Artikel lesen
Dies ist eine Zusammenfassung dessen, was ich geschrieben habe, damit ich es nicht vergesse, mit ein paar zusätzlichen Informationen. Wenn es schwer zu lesen oder zu verstehen ist, kommentieren Sie bitte, da wir es korrigieren werden.
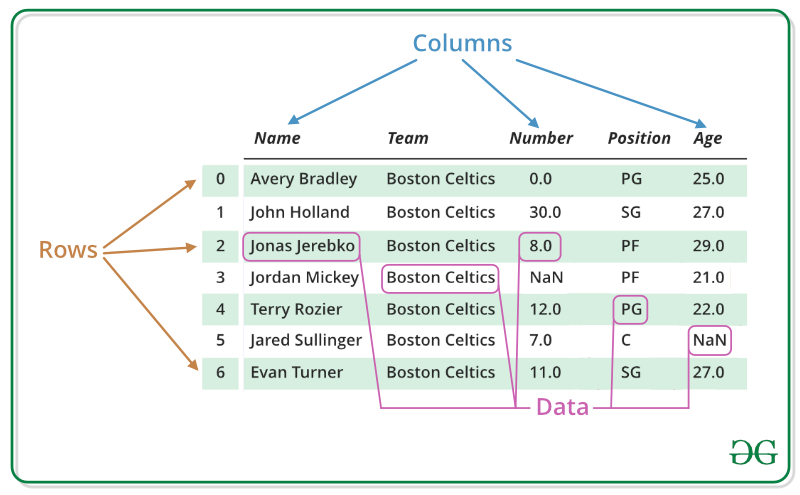 Referenz: https://www.geeksforgeeks.org/python-pandas-dataframe/
Referenz: https://www.geeksforgeeks.org/python-pandas-dataframe/
Entwicklungsumgebung zu verwenden
- anaconda
- Pycharm
- Python3.7.7
Verlauf bearbeiten -2020/04/05 -2020/04/05 --Zusatz: Daten löschen
Bevor Sie Pandas starten
#Installieren, importieren
pip install pandas
import pandas as pd
Lass uns tatsächlich mit Pandas spielen.
Daten bekommen
Wenn Sie etwas mit Pandas machen wollen, müssen Sie es bekommen. Bereiten Sie es als CSV vor. Dieses Mal werde ich eine Person verwenden, die mit dem Coronavirus (Präfektur Hyogo) infiziert ist.
url = "https://web.pref.hyogo.lg.jp/kk03/corona_hasseijyokyo.html"
dfs = pd.read_html(url)
print(dfs[0].head())
#HTML-Tabelle an der Eingabeaufforderung anzeigen
>>>
0 1 2 3 4 5 6
0 Anzahl Alter Geschlecht Wohnort Beruf Datum der Ankündigung Bemerkungen
1 162 40 Männlicher Kobe City Doctor 1. April NaN
2 161 20 Männlich Itami Gesundheits- und Sozialamt Gerichtsstand Angestellter Mitarbeiter 1. April NaN
3 160 50 Frau Takarazuka City Arbeitslos 1. April NaN
4 159 60 Männlich Takarazuka City Doctor 1. April NaN
#Machen Sie die Tabelle auf HTML csv.
#Texteditor
import csv
tables = pd.read_html("https://web.pref.hyogo.lg.jp/kk03/corona_hasseijyokyo.html", header=0)
data = tables[0]
data.to_csv("coronaHyogo.csv", index=False) #Ausgabe
Lesen Sie CSV
dfs = pd.read_csv('C:/Users/Desktop/coronaHyogo.csv')
print (dfs)
#Öffnen Sie CSV mit Pandas
>>>
Anzahl Alter Geschlecht Wohnort Beruf Datum der Ankündigung Bemerkungen
0 169 40 Männlich Amagasaki City Büroangestellter 2. April NaN
1 168 60 Männlich Ashiya City Büroangestellter 2. April NaN
2 167 50 Männlich Itami Gesundheits- und Sozialamt Gerichtsstand Mitarbeiter des Unternehmens 2. April NaN
3 166 20 Weibliche Itami City NaN 2. April NaN
4 165 20 Männlich Akashi City NaN 2. April NaN
.. ... .. .. ... ... ... ...
64 105 70 Männlich Itami City Arbeitslos 21. März NaN
65 104 80 Frau Takarazuka City Arbeitslos 21. März Gestorben
66 103 60 Männlich Amagasaki City Büroangestellter 21. März NaN
67 102 40 Rückkehrerin (angekündigt vom Himeji City Health Center) Arbeitslos 21. März NaN
68 101 20 Männlich Amagasaki City Student 20. März NaN
Bestätigung der Daten
dfs.shape #Überprüfen Sie die Anzahl der Zeilen und Spalten im Datenrahmen
>>> (69, 7)
dfs.index #Index prüfen
>>> RangeIndex(start=0, stop=69, step=1)
dfs.columns #Spalte prüfen
>>> Index(['Nummer', 'Alter', 'Sex', 'Residenz', 'Beruf', 'Ankündigungsdatum', 'Bemerkungen'], dtype='object')
dfs.dtypes #Überprüfen Sie den Datentyp jeder Spalte des Datenrahmens
>>>
Nummer int64
Alter int64
Geschlechtsobjekt
Wohnortobjekt
Berufsobjekt
Ankündigungsdatum Objekt
Bemerkungen Objekt
dtype: object
Extraktion von Informationen
df.head(3)
#Auszug aus dem Kopf in die dritte Zeile.
>>>
Anzahl Alter Geschlecht Wohnort Beruf Datum der Ankündigung Bemerkungen
0 169 40 Männlich Amagasaki City Büroangestellter 2. April NaN
1 168 60 Männlich Ashiya City Büroangestellter 2. April NaN
2 167 50 Männlich Itami Gesundheits- und Sozialamt Gerichtsstand Mitarbeiter des Unternehmens 2. April NaN
dfs.tail()
#Von hinten herausziehen.
>>>
Anzahl Alter Geschlecht Wohnort Beruf Datum der Ankündigung Bemerkungen
64 105 70 Männlich Itami City Arbeitslos 21. März NaN
65 104 80 Frau Takarazuka City Arbeitslos 21. März Gestorben
66 103 60 Männlich Amagasaki City Büroangestellter 21. März NaN
67 102 40 Rückkehrerin (angekündigt vom Himeji City Health Center) Arbeitslos 21. März NaN
68 101 20 Männlich Amagasaki City Student 20. März NaN
dfs[["Alter","Sex","Ankündigungsdatum"]].head()
#Geben Sie eine Spalte an und extrahieren Sie.
>>>
Alter Geschlecht Ankündigungsdatum
0 40 Männlich 2. April
1 60 Männlich 2. April
2 50 Männlich 2. April
3 20 Frauen 2. April
4 20 Männlich 2. April
row2 = dfs.iloc[3]
print(row2)
#Es werden nur die dritten Daten von oben angezeigt.
>>>
Nummer 166
Alter 20
Geschlecht Weiblich
Wohnort Itami City
Beruf NaN
Ankündigungsdatum 2. April
Bemerkungen NaN
Datenformung
dfs.rename(columns={'Sex': 'sex'}, inplace=True)
dfs.head()
#Namensänderung (Geschlecht zu Geschlecht)
>>>
Anzahl Alter Geschlecht Wohnort Beruf Datum der Ankündigung Bemerkungen
0 169 40 Männlich Amagasaki City Büroangestellter 2. April NaN
1 168 60 Männlich Ashiya City Büroangestellter 2. April NaN
2 167 50 Männlich Itami Gesundheits- und Sozialamt Gerichtsstand Mitarbeiter des Unternehmens 2. April NaN
dfs.set_index('Alter', inplace=True)
dfs.head()
#
>>>
Nummer Geschlecht Wohnort Beruf Datum der Bekanntmachung Bemerkungen
Alter
40 169 Männlich Amagasaki City Büroangestellter 2. April NaN
60 168 Männlich Büroangestellter der Stadt Ashiya 2. April NaN
50 167 Männlich Itami Gesundheits- und Sozialamt Gerichtsstand Mitarbeiter 2. April NaN
dfs.index
>>>
Int64Index([40, 60, 50, 20, 20, 70, 50, 40, 20, 50, 60, 60, 60, 10, 30, 60, 10,
30, 20, 60, 60, 30, 60, 60, 20, 70, 60, 20, 20, 30, 40, 40, 30, 20,
20, 50, 30, 70, 60, 60, 70, 20, 60, 30, 50, 40, 30, 10, 50, 70, 20,
80, 20, 80, 40, 70, 30, 80, 60, 70, 40, 70, 90, 80, 70, 80, 60, 40,
20],
df.sort_values(by="Alter", ascending=True).head() # ascending=Wahr in aufsteigender Reihenfolge
# 'Alter'Absteigende Spalten
# df.sort_values(['Alter', 'Ankündigungsdatum'], ascending=False).head() #Mehrfach ist möglich
>>>
Anzahl Geschlecht Wohnort Beruf Datum der Ankündigung Bemerkungen
Alter
10 122 Studentin in Kobe City 27. März NaN
10 153 Studentin der Stadt Amagasaki 1. April NaN
10 156 Studentin der Kawanishi City Berufsschule 1. April NaN
20 135 Frau Itami Gesundheits- und Sozialamt Gerichtsstand Mitarbeiterin 30. März NaN
20 117 Männlich Nishinomiya City Doctor 24. März NaN
#Daten löschen
print(df.drop(columns=['Nummer','Residenz']))
Zählen Sie die Anzahl der Daten
dfs['Alter'].value_counts()
60 15
20 13
70 9
30 9
40 8
50 6
80 5
10 3
90 1
Name:Alter, dtype: int64
Finden Sie statistische Indikatoren
#durchschnittlich
mean = dfs['Alter'].mean()
print(mean) #46.3768115942029
#gesamt
sum = dfs['Alter'].sum()
print(sum) #3200
#Median
median = dfs['Alter'].median()
print(median) #50.0
#Maximalwert
dfsmax = dfs['Alter'].max()
print(dfsmax) #90
#Mindestwert
dfsmin = dfs['Alter'].min()
print(dfsmin) #10
#Standardabweichung
std = dfs['Alter'].std()
print(std) #21.418176344401118
#Verteilt
var = dfs['Alter'].var()
print(var) #458.73827791986366
Recommended Posts