Extrahieren Sie die Tabelle der Bilddateien mit OneDrive & Python
Ich möchte die Tabelle aus dem Bild extrahieren
Möglicherweise möchten Sie die Tabelle ** in der Bilddatei ** als Tabellendaten extrahieren.
Beispiel: "Scannen Sie ein Papierbuch oder Dokument und digitalisieren Sie es als Bilddatei oder PDF-Datei".
(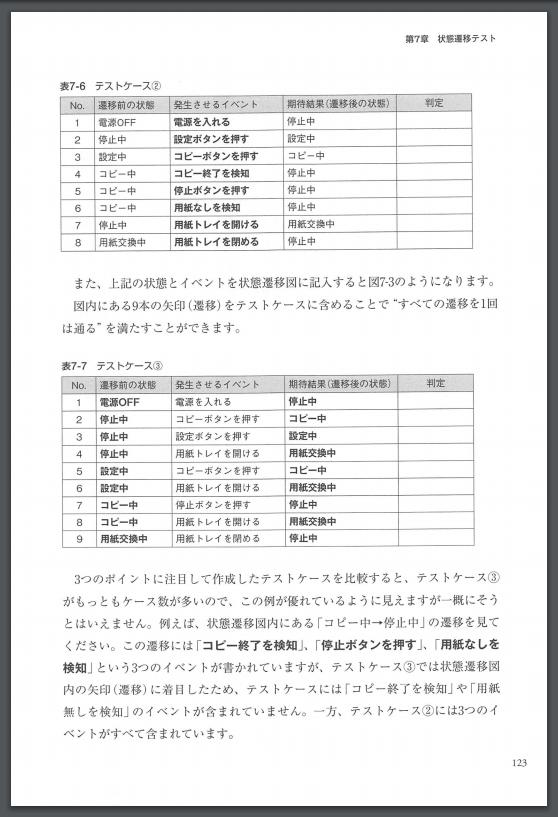
Die Tabelle in dieser Tabelle wird nicht OCR-verarbeitet ** nur ein Bild **, daher wird sie nicht als Zeichen erkannt, geschweige denn als Tabelle.
Daher kann es natürlich nicht so wie es ist als Tabellendaten behandelt werden. Gibt es dann keine andere Wahl, als die Daten aufzugeben und stetig zu tabellieren? Nein, ** gib nicht auf! ** ** **
So extrahieren Sie Tabellendaten aus einem Bild
Selbst aus solchen Bildern (jpg, png, pdf usw.) kann die Tabelle im nächsten Schritt als Daten extrahiert werden.
Vorbereitung Registrieren Sie sich für Microsoft OneDrive (kostenlos) 0. Konvertieren Sie Bilddateien (JPG, PNG usw.) in PDF-Dateien (dieser Schritt ist für PDF von Anfang an nicht erforderlich).
- Speichern Sie die PDF-Datei in OneDrive, konvertieren Sie sie in Word und wenden Sie die OCR-Verarbeitung an
- Speichern Sie OCR-verarbeitetes Word als PDF
- Extrahieren Sie die Tabelle als PDF mit Python
Ich werde unterwegs Word verwenden, aber ich werde das kostenlose Office Online verwenden, damit Microsoft Word nicht auf Ihrem PC installiert sein muss.
Dann werde ich diesmal anhand der PDF-Datei von ↓ erklären.
(
Wenn Sie eine Tabelle aus einer Bilddatei (jpg, png usw.) extrahieren möchten, konvertieren Sie sie zuerst in eine PDF-Datei. Es gibt auch einen kostenlosen Webdienst, der Bilddateien in PDF konvertiert. Der einfachste ist jedoch [Klicken Sie mit der rechten Maustaste auf die Bilddatei-> Drucken> Wählen Sie im zu druckenden Drucker "Microcoft Print to PDF" aus].
Vorbereitung Registrieren Sie ein Konto bei OneDrive
Registrieren Sie Ihr Konto bei Microsoft OneDrive. Frei.
[Holen Sie sich ein Microsoft-Konto] (https://www.microsoft.com/ja-jp/office/homeuse/onedrive-guide.aspx)
1. Speichern Sie die PDF-Datei in OneDrive
Laden Sie die Ziel-PDF-Datei auf OneDrive hoch.
Klicken Sie mit der rechten Maustaste auf die Datei und wählen Sie Öffnen.
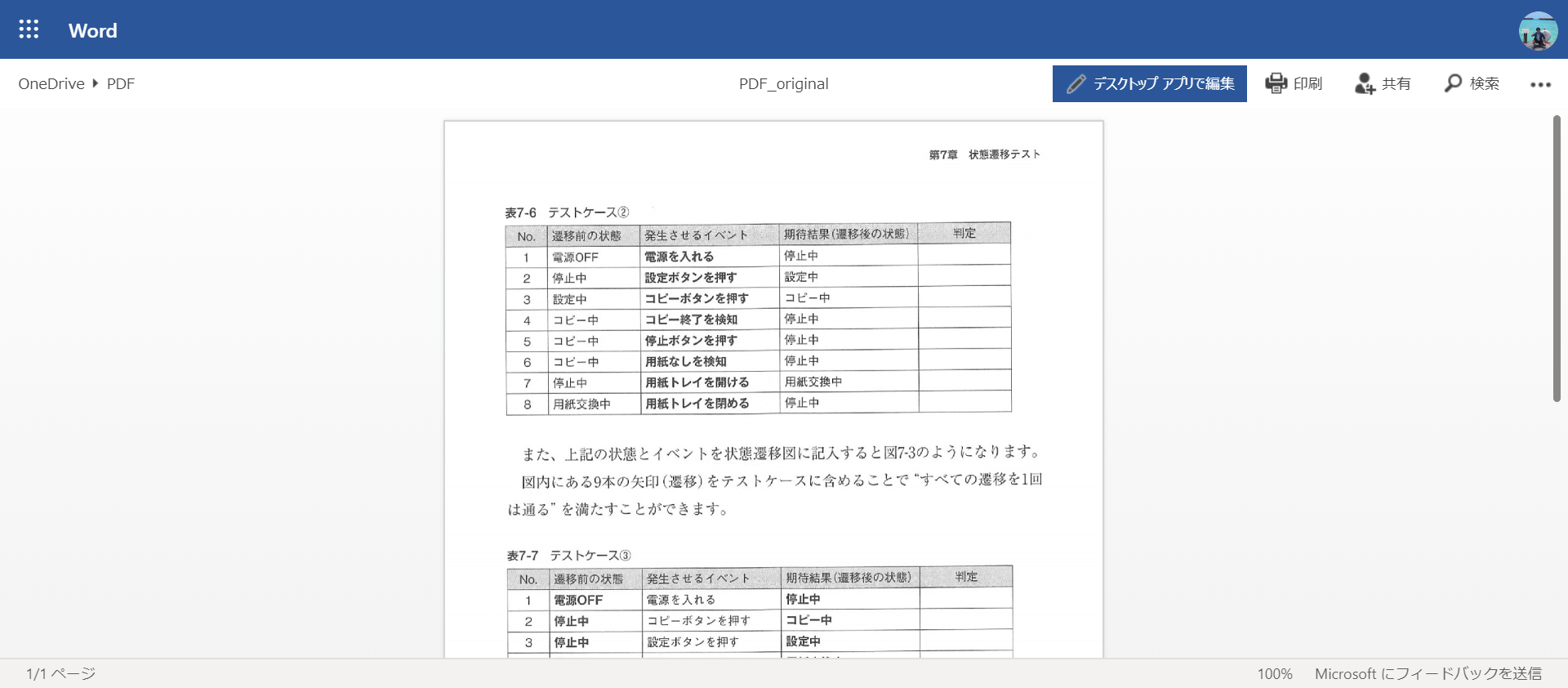
Wenn Sie zu diesem Zeitpunkt versuchen, in der Tabelle eine Auswahl zu treffen, können Sie die Zeichen als Text auswählen. Die Tabellenstruktur wird ebenfalls erkannt.
Klicken Sie auf die Schaltfläche "Mit Desktop App bearbeiten". Dann werden Sie gefragt, ob Sie die Datei konvertieren möchten. Klicken Sie daher auf die Schaltfläche "Konvertieren".
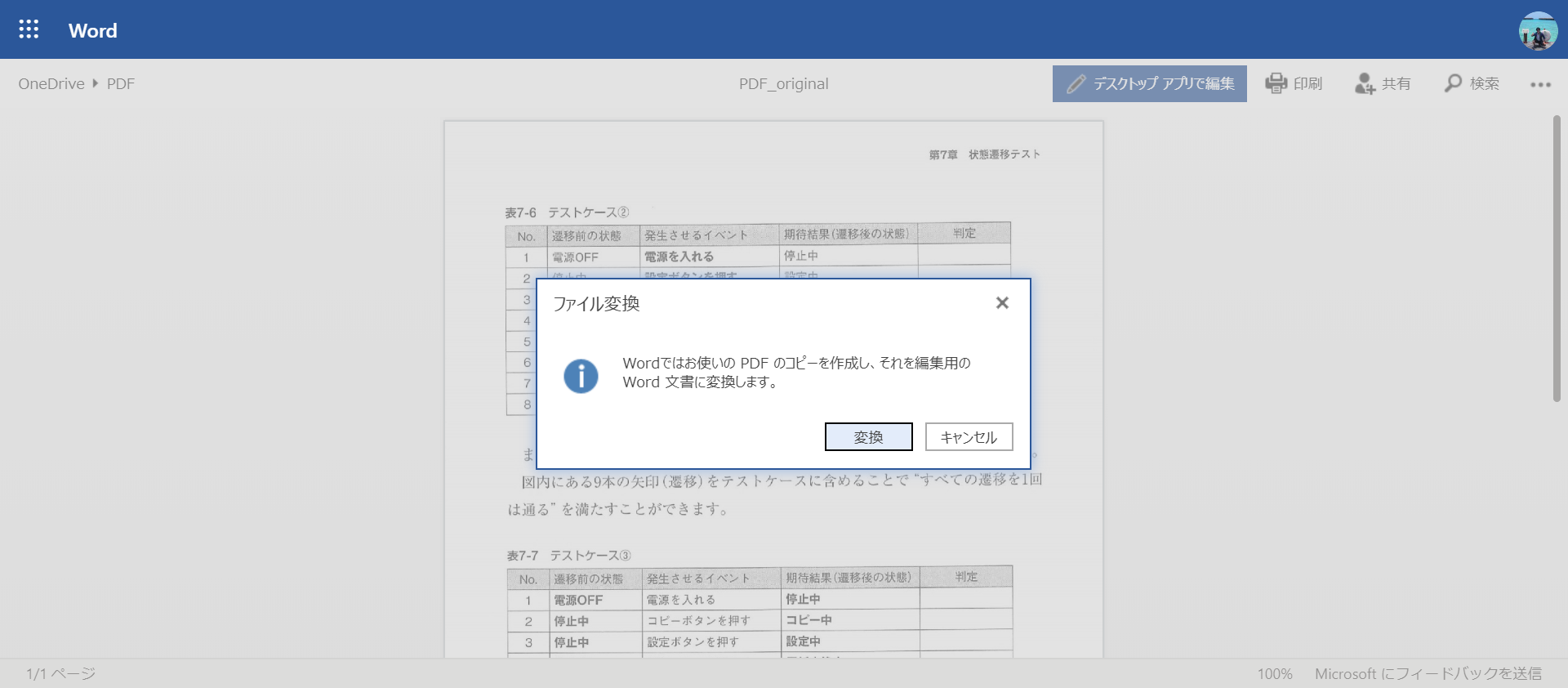
Dann erfolgt die Konvertierung. Wenn die Konvertierung abgeschlossen ist, wird ein Bestätigungsbildschirm angezeigt. Drücken Sie daher auf "Bearbeiten".
Dadurch wird Word in Ihrem Browser geöffnet. Es wird ordnungsgemäß als Tabellendaten konvertiert.
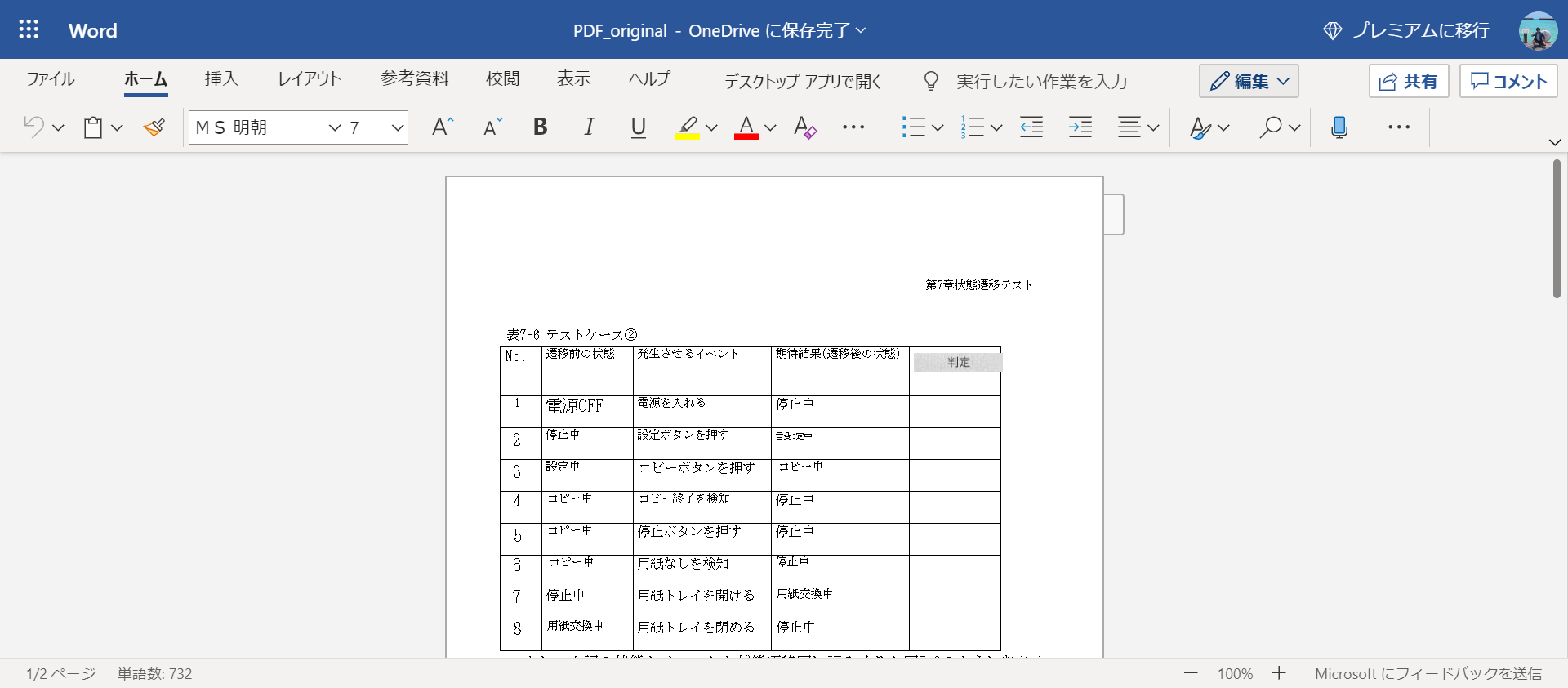
Es kann einige Stellen geben, an denen die Zeichen nicht richtig erkannt werden. Wenn Sie dies an dieser Stelle beheben können, beheben Sie es manuell. In diesem Fall kann "Kopieren" "Coby" sein, aber die Konvertierung ist fast korrekt. Es ist eine ziemliche Erkennungsgenauigkeit!
2. Speichern Sie OCR-verarbeitetes Word als PDF
PDF-Dateien sind in Python einfacher zu handhaben als Word-Dateien. Konvertieren Sie sie daher in PDF und laden Sie sie herunter.
Wählen Sie oben links "Datei" und dann Speichern unter → Als PDF herunterladen.

3. Extrahieren Sie die Tabelle in PDF mit Python
Öffnen wir die heruntergeladene PDF-Datei. Im Gegensatz zum Original-PDF wird die Tabelle ordnungsgemäß als Tabelle erkannt. Es ist nicht gut, die Schriftart zu sehen, weil sie groß oder klein ist, aber Sie müssen sich keine Sorgen machen, da sie als DataFrame von Pandas extrahiert wird.
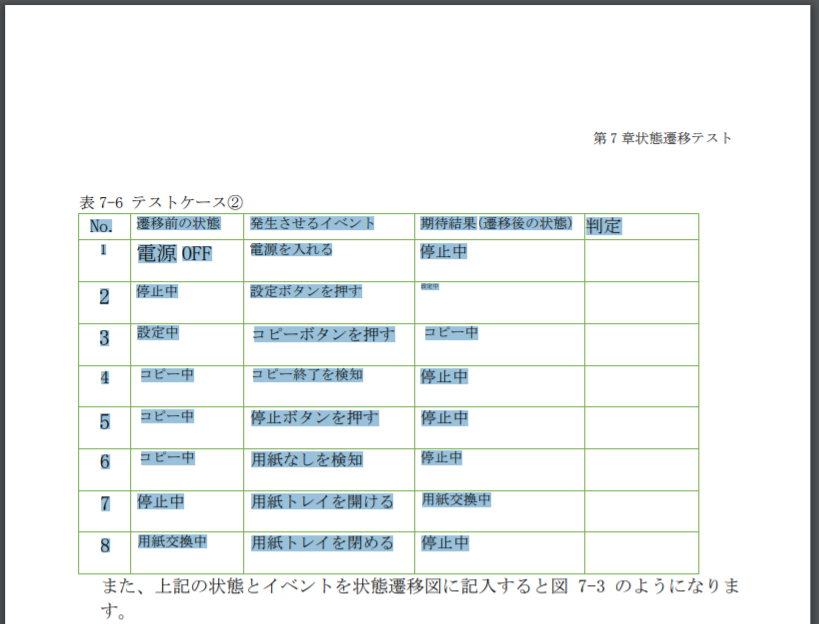
Übrigens, wenn Sie zu diesem Punkt kommen, ist der Rest eine einfache Tabelle, die Python nach der im Artikel "Tabelle in PDF mit Python extrahieren" eingeführten Methode verwendet. Kann extrahiert werden.
python
import pandas as pd
import tabula
# lattice=True, um die Zelle anhand der Tabellenachse zu bestimmen
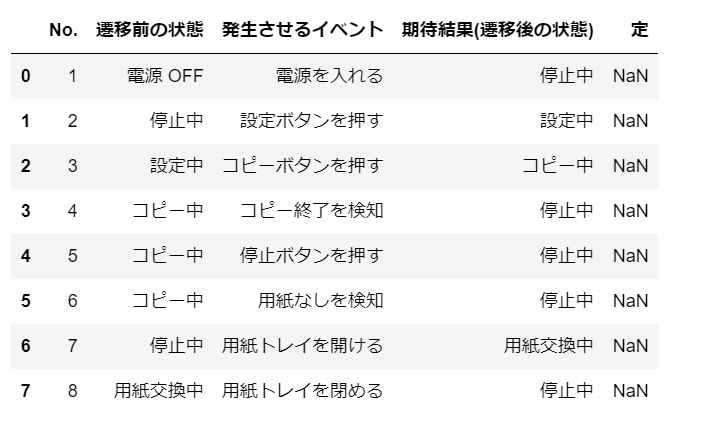
dfs = tabula.read_pdf("PDF_ocr.pdf", lattice=True, pages='1')
for df in dfs:
display(df)
Ausführungsergebnis
Recommended Posts