[PYTHON] Erfahren Sie anhand eines einfachen Regressionsmodells den Ablauf der Bayes'schen Schätzung und die Verwendung von Pystan
Einführung
[Einführung in die Datenanalyse durch Bayes'sche statistische Modellierung beginnend mit R und Stan](https://www.amazon.co.jp/%E5%AE%9F%E8%B7%B5Data-Science%E3%82%B7%E3%83] % AA% E3% 83% BC% E3% 82% BA-R% E3% 81% A8Stan% E3% 81% A7% E3% 81% AF% E3% 81% 98% E3% 82% 81% E3% 82 % 8B-% E3% 83% 99% E3% 82% A4% E3% 82% BA% E7% B5% B1% E8% A8% 88% E3% 83% A2% E3% 83% 87% E3% 83% AA% E3% 83% B3% E3% 82% B0% E3% 81% AB% E3% 82% 88% E3% 82% 8B% E3% 83% 87% E3% 83% BC% E3% 82% BF% E5% 88% 86% E6% 9E% 90% E5% 85% A5% E9% 96% 80-KS% E6% 83% 85% E5% A0% B1% E7% A7% 91% E5% AD% A6% Ich las E5% B0% 82% E9% 96% 80% E6% 9B% B8 / dp / 4065165369). Es war leicht zu verstehen und ich konnte es lesen, ohne es zu verstopfen. es wird empfohlen. Zum besseren Verständnis möchte ich den Inhalt des Buches nachverfolgen und ausprobieren. Dieses Buch verwendet R und Stan, aber hier verwenden wir Python und Pystan. Der allgemeine Inhalt dieses Beitrags lautet wie folgt:
- Satz von Bayes
- MCMC-Methode
- Wie benutzt man Pystan?
- Einfaches Regressionsmodell
Sie lernen den Fluss der Bayes'schen Schätzung und die Verwendung von Pystan anhand eines einfachen Modells, das als einfaches Regressionsmodell bezeichnet wird.
0. Modul
Hier importieren Sie die erforderlichen Module im Voraus.
import numpy as np
import matplotlib.pyplot as plt
import pystan
import arviz
plt.rcParams["font.family"] = "Times New Roman" #Stellen Sie die gesamte Schriftart ein
plt.rcParams["xtick.direction"] = "in" #Nach innen die x-Achsen-Skalierungslinie
plt.rcParams["ytick.direction"] = "in" #Y-Achsen-Skalierungslinie nach innen
plt.rcParams["xtick.minor.visible"] = True #Hinzufügen einer x-Achsen-Hilfsskala
plt.rcParams["ytick.minor.visible"] = True #Hinzufügen einer Hilfsskala der y-Achse
plt.rcParams["xtick.major.width"] = 1.5 #Linienbreite der x-Achsen-Hauptskalenlinie
plt.rcParams["ytick.major.width"] = 1.5 #Linienbreite der Hauptskalenlinie der y-Achse
plt.rcParams["xtick.minor.width"] = 1.0 #Linienbreite der Hilfsskalenlinie der x-Achse
plt.rcParams["ytick.minor.width"] = 1.0 #Linienbreite der Hilfsskalenlinie der y-Achse
plt.rcParams["xtick.major.size"] = 10 #Länge der x-Achsen-Hauptskalenlinie
plt.rcParams["ytick.major.size"] = 10 #Länge der Hauptmaßstablinie der y-Achse
plt.rcParams["xtick.minor.size"] = 5 #Länge der Hilfsskala der x-Achse
plt.rcParams["ytick.minor.size"] = 5 #Länge der Hilfsskala der y-Achse
plt.rcParams["font.size"] = 14 #Schriftgröße
plt.rcParams["axes.linewidth"] = 1.5 #Gehäusedicke
1. Satz von Bayes
Die Bayes'sche Schätzung basiert auf dem Bayes'schen Theorem.
p(\theta|x)=p(\theta) \frac{p(x|\theta)}{\int p(x|\theta)p(\theta)d\theta}
Hier
(Ex-post-Verteilung) = (Vorherige Verteilung) \times \frac{(Haftung)}{(周辺Haftung)}
Die periphere Wahrscheinlichkeit ist eine Normalisierungskonstante, die den integrierten Wert der posterioren Verteilung auf 1 setzt. Daher gilt die folgende Beziehung, wobei der Grenzwahrscheinlichkeitsterm weggelassen wird.
(Ex-post-Verteilung) \propto (Vorherige Verteilung) \times (Haftung)
1.1 Beispiel
Betrachten Sie die Bayes'sche Schätzung des Mittelwerts am Beispiel der Wahrscheinlichkeitsvariablen $ x $, die einer Normalverteilung folgt. Angenommen, Sie wissen, dass die Standardabweichung 1 ist. Die Wahrscheinlichkeitsdichtefunktion der Normalverteilung ist wie folgt.
\begin{align} p(x|\mu, \sigma=1) &= \frac{1}{\sqrt{2\pi\sigma^2}}\exp{\left(-\frac{(x-\mu)^2}{2\sigma^2}\right)} \\
&= \frac{1}{\sqrt{2\pi}}\exp{\left(-\frac{(x-\mu)^2}{2}\right)} \end{align}
np.random.seed(seed=1) #Zufälliger Samen
mu = 5.0 #durchschnittlich
s = 1.0 #Standardabweichung
N = 10 #Menge
x = np.random.normal(mu,s,N)
print(x)
array([6.62434536, 4.38824359, 4.47182825, 3.92703138, 5.86540763,
2.6984613 , 6.74481176, 4.2387931 , 5.3190391 , 4.75062962])
Finden Sie die Wahrscheinlichkeit (Wahrscheinlichkeit), die obigen Daten zu erhalten. Die Daten sind $ D $. Da die Ereignisse, die die einzelnen Daten erhalten, unabhängig sind, werden die Wahrscheinlichkeiten für das Erhalten der einzelnen Daten multipliziert.
f(D|\mu) = \prod_{i=0}^{N-1} \frac{1}{\sqrt{2\pi}}\exp{\left(-\frac{(x_i-\mu)^2}{2}\right)}
Obwohl nicht im Buch, lassen Sie uns die obige Funktion visualisieren. Hier wird es als die Methode mit der höchsten Wahrscheinlichkeit bezeichnet, den Maximalwert der Wahrscheinlichkeitsfunktion zu nehmen und zu bestimmen, dass der Durchschnitt 5 beträgt (Punktschätzung).
mu_ = np.linspace(-5.0,15.0,1000)
f_D = 1.0
for x_ in x:
f_D *= 1.0/np.sqrt(2.0*np.pi) * np.exp(-(x_-mu_)**2 / 2.0) #Haftungsfunktion
fig,axes = plt.subplots(figsize=(8,6))
axes.plot(mu_,np.log(f_D))
axes.set_xlabel(r"$\mu$")
axes.set_ylabel(r"$log (f(D|\mu))$")
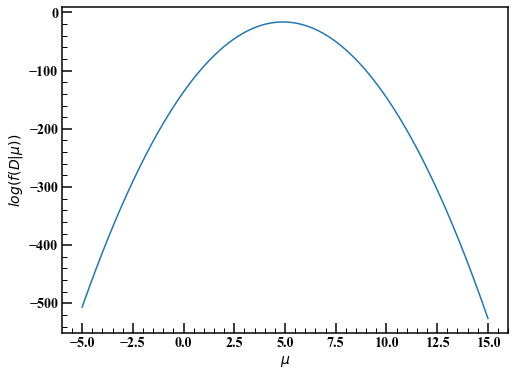
Kehren wir zur Bayes'schen Schätzung zurück und bestimmen die vorherige Verteilung. Wenn Sie den Parameter $ \ mu $ nicht im Voraus kennen, folgen Sie dem Prinzip unzureichender Gründe und ziehen Sie vorerst eine breite Verteilung in Betracht. Diesmal beträgt die Verteilung 10000 und der Durchschnitt 0.
Nach der Bayes'schen Schätzung kann die posteriore Verteilung komplex und schwer zu integrieren sein. Selbst wenn Sie die Wahrscheinlichkeitsdichtefunktion der posterioren Verteilung erhalten, kann die Wahrscheinlichkeit, dass der Durchschnittswert zwischen 4 und 6 liegt, nicht erhalten werden, wenn Sie sie beispielsweise nicht integrieren können. Die MCMC-Methode ist in solchen Fällen nützlich. In diesem Beispiel gibt es nur einen Parameter. Teilen wir ihn also durch $ \ mu $ anstelle der MCMC-Methode und sehen, wie die hintere Verteilung aussieht.
f_mu = 1.0/np.sqrt(20000.0*np.pi) * np.exp(-mu_**2.0 / 20000) #Vorherige Verteilung
f_mu_poster = f_mu * f_D #(Vorherige Verteilung)×(Haftung)
f_mu_poster /= np.sum(f_mu_poster) #Setzen Sie den integrierten Wert auf 1
fig,axes = plt.subplots(figsize=(8,6))
axes.plot(mu_,f_mu,label="Prior distribution")
axes.plot(mu_,f_mu_poster,label="Posterior distribution")
axes.legend(loc="best")
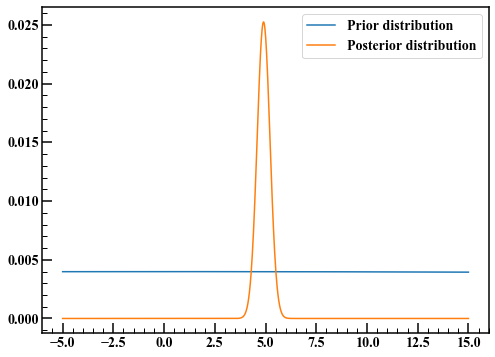
Die Vorverteilung war breitschwänzig, aber die von Bayes aktualisierte hintere Verteilung hat schmale Schwänze. Der erwartete Wert der posterioren Verteilung scheint bei 5 zu liegen, wie durch die wahrscheinlichste Methode erhalten.
2. MCMC-Methode
Die MCMC-Methode ist eine Abkürzung für die Markov-Ketten-Monte-Carlo-Methode. Dies ist eine Zufallszahlengenerierungsmethode, die die Markov-Kette verwendet, bei der der Wert zu einem bestimmten Zeitpunkt nur vom vorherigen Zeitpunkt beeinflusst wird. Bei der Bayes'schen Schätzung werden Zufallszahlen, die der posterioren Verteilung von Parametern folgen, durch die MCMC-Methode erzeugt und anstelle der Integration verwendet. Wenn Sie beispielsweise den erwarteten Wert der posterioren Verteilung ermitteln möchten, können Sie ihn ermitteln, indem Sie den Durchschnitt der Zufallszahlen berechnen.
2.1 Metropolis Hastings-Methode (MH-Methode)
Beschreibt einen Algorithmus, der Zufallszahlen generiert, die einer bestimmten Wahrscheinlichkeitsverteilung folgen. Der Einfachheit halber werden wir nur einen Parameter schätzen.
- Bestimmen Sie den Anfangswert der Zufallszahl $ \ hat {\ theta} $.
- Generieren Sie Zufallszahlen, die einer Normalverteilung mit einem Mittelwert von 0 und einer Varianz von $ \ sigma ^ 2 $ folgen.
- Berechnen Sie die Summe aus Zufallszahl und Anfangswert $ \ hat {\ theta} $. Sei dies $ \ theta ^ {suggest} $.
- Berechnen Sie das Verhältnis der Wahrscheinlichkeitsdichten von $ \ hat {\ theta} $ und $ \ theta ^ {suggest} $.
- Wenn das Verhältnis der Wahrscheinlichkeitsdichten größer als 1 ist, wird $ \ theta ^ {suggest} $ angenommen, und wenn es 1 oder weniger ist, wird dieser Wert als Wahrscheinlichkeit verwendet und angenommen oder zurückgewiesen.
Die angenommene Zufallszahl wird als Anfangswert verwendet und viele Male wiederholt. Je höher die Wahrscheinlichkeitsdichte ist, desto einfacher ist es, Zufallszahlen zu übernehmen, sodass es sich anfühlt, als würde es der Wahrscheinlichkeitsverteilung folgen. Lassen Sie uns anhand des Beispiels in 1.1 eine Zufallszahl generieren, die der posterioren Verteilung mit der obigen Methode folgt.
np.random.seed(seed=1) #Zufälliger Samen
def posterior_dist(mu): #Ex-post-Verteilung
#(Vorherige Verteilung)×(Haftung)
return 1.0/np.sqrt(20000.0*np.pi) * np.exp(-mu**2.0 / 20000) \
* np.prod(1.0/np.sqrt(2.0*np.pi) * np.exp(-(x-mu)**2 / 2.0))
def MH_method(N,s):
rand_list = [] #Angenommene Zufallszahl
theta = 1.0 #1.Bestimmen Sie den Anfangswert entsprechend
for i in range(N):
rand = np.random.normal(0.0,s) #2.Generieren Sie Zufallszahlen, die einer Normalverteilung mit Mittelwert 0 und Standardabweichung s folgen
suggest = theta + rand #3.
dens_rate = posterior_dist(suggest) / posterior_dist(theta) #4.Wahrscheinlichkeitsdichteverhältnis
# 5.
if dens_rate >= 1.0 or np.random.rand() < dens_rate:
theta = suggest
rand_list.append(theta)
return rand_list
Wiederholen Sie die Schritte 1 bis 5 50.000 Mal, wobei die Standardabweichung der in Schritt 2 generierten Zufallszahlen 1 ist.
rand_list = MH_method(50000,1.0)
len(rand_list) / 50000
0.3619
Die Wahrscheinlichkeit, dass eine Zufallszahl angenommen wird, wird als Akzeptanzrate bezeichnet. Diesmal waren es 36,2%.
fig,axes = plt.subplots(figsize=(8,6))
axes.plot(rand_list)
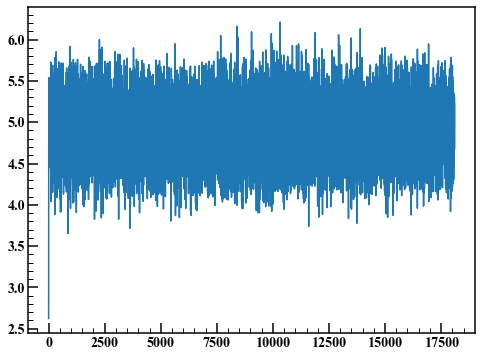
Ein solcher Graph wird als Trace-Plot bezeichnet. Die ersten Punkte sind aufgrund des Einflusses der Anfangswerte instationär. Hier werden die ersten 1000 Punkte verworfen und ein Histogramm gezeichnet.
fig,axes = plt.subplots(figsize=(8,6))
axes.hist(rand_list[1000:],30)
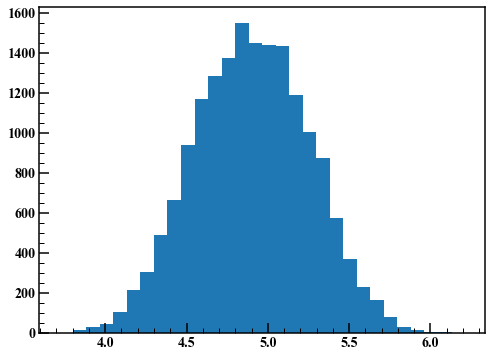
Ich habe ein gutes Ergebnis erzielt. Stellen Sie als nächstes die Standardabweichung der in Schritt 2 generierten Zufallszahlen auf 0,01 ein und wiederholen Sie den gleichen Vorgang.
rand_list = MH_method(50000,0.01)
len(rand_list) / 50000
0.98898
Die Akzeptanzquote ist auf 98,9% gestiegen.
fig,axes = plt.subplots(figsize=(8,6))
axes.plot(rand_list)
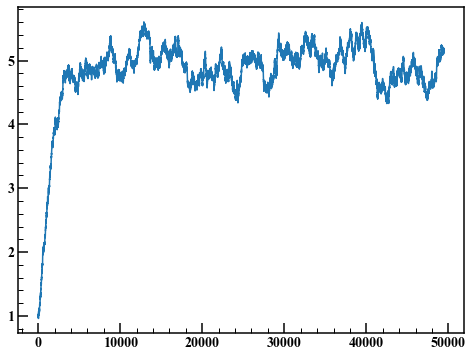
Verwerfen Sie die ersten 10.000 Punkte und zeichnen Sie ein Histogramm.
fig,axes = plt.subplots(figsize=(8,6))
axes.hist(rand_list[10000:],30)
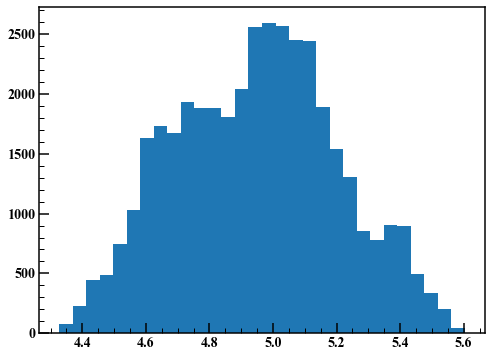
Wie Sie sehen können, hängt das Ergebnis der MH-Methode von der Streuung der in Schritt 2 verwendeten Zufallszahlen ab. Die Hamilton-Monte-Carlo-Methode ist einer der Algorithmen zur Lösung dieses Problems. Stan profitiert von einer Vielzahl cleverer Algorithmen.
3. Wie benutzt man Pystan?
Der Stan-Code erfordert einen Datenblock, einen Parameterblock und einen Modellblock. Der Datenblock beschreibt die Informationen der zu verwendenden Daten, der Parameterblock beschreibt die zu schätzenden Parameter und der Modellblock beschreibt die vorherige Verteilung und Wahrscheinlichkeit. Der Block generierte Mengen kann anhand der geschätzten Parameter Zufallszahlen generieren. Ich habe die Beschreibungsmethode im Kommentar im Stan-Code geschrieben.
stan_code = """
data {
int N; //Stichprobengröße
vector[N] x; //Daten
}
parameters {
real mu; //durchschnittlich
real<lower=0> sigma; //Standardabweichung<lower=0>Gibt an, dass nur Werte größer oder gleich 0 angenommen werden
}
model {
//Normalverteilung des Mittelwerts mu, Standardabweichung Sigma
x ~ normal(mu, sigma); // "~"Das Symbol zeigt an, dass die linke Seite der Verteilung der rechten Seite folgt
}
generated quantities{
//Holen Sie sich die posteriore Vorhersageverteilung
vector[N] pred;
//Im Gegensatz zu Python beginnen Indizes bei 1
for (i in 1:N) {
pred[i] = normal_rng(mu, sigma);
}
}
"""
Kompilieren Sie den Stan-Code.
sm = pystan.StanModel(model_code=stan_code) #Stan-Code kompilieren
Fassen Sie die zu verwendenden Daten zusammen. Entspricht dem Variablennamen, der im Datenblock des obigen Stan-Codes deklariert ist.
#Stellen Sie die Daten zusammen
stan_data = {"N":len(x), "x":x}
Bevor wir MCMC ausführen, werfen wir einen Blick auf die Argumente der Stichprobenmethode.
- Anzahl der Iterationen iter: Die Anzahl der generierten Zufallszahlen. Wenn nichts angegeben ist, wird standardmäßig 2000 verwendet. Wenn die Konvergenz schlecht ist, kann dies ein großer Wert sein.
- Aufwärmen der Einbrennperiode: Wie das Trace-Diagramm in 2.1 wird es zunächst vom Anfangswert beeinflusst. Um diesen Effekt zu vermeiden, verwerfen Sie die durch das Aufwärmen angegebenen Punkte.
- Dünn dünner: Nehmen Sie für jede Dünnheit eine Zufallszahl an. Da die MCMC-Methode die Markov-Kette verwendet, ist sie vor einiger Zeit betroffen und weist eine Autokorrelation auf. Reduzieren Sie diesen Effekt.
- Kettenketten: Um die Konvergenz zu bewerten, wird der Anfangswert geändert und Zufallszahlen werden durch MCMC-Kettenzeiten generiert. Wenn die Ergebnisse jedes Versuchs ähnlich sind, kann beurteilt werden, dass sie konvergiert haben.
Führen Sie MCMC aus.
#Führen Sie MCMC aus
mcmc_normal = sm.sampling(
data = stan_data,
iter = 2000,
warmup = 1000,
chains = 4,
thin = 1,
seed = 1
)
Zeigen Sie das Ergebnis an. Die verwendeten Daten waren Zufallszahlen nach einer Normalverteilung mit einem Mittelwert von 5 und einer Standardabweichung von 1. mu repräsentiert den Durchschnitt und Sigma repräsentiert die Standardabweichung. Beschreibt jedes Element in der Ergebnistabelle.
- Mittelwert: Erwarteter Wert der posterioren Verteilung
- se_mean: Der erwartete Wert der posterioren Verteilung geteilt durch die Quadratwurzel der Anzahl gültiger Proben [^ 1]
- sd: Standardabweichung der posterioren Verteilung
- 2,5% -97,5%: Bayes-Kreditintervall. Ordnen Sie die Zufallszahlen, die der posterioren Verteilung folgen, in aufsteigender Reihenfolge an und überprüfen Sie die Werte, die den 2,5% bis 97,5% -Punkten entsprechen. Wenn Sie diesen Unterschied berücksichtigen, erhalten Sie ein Bayes'sches Kreditintervall von 95% (Vertrauensintervall).
- n_eff: Anzahl der angenommenen Zufallszahlen
- Rhat: Repräsentiert das Verhältnis der Verteilung aller Zufallszahlen einschließlich verschiedener Ketten zum Durchschnittswert der Verteilung von Zufallszahlen innerhalb derselben Kette. Wenn Ketten 3 oder mehr sind, scheint Rhat kleiner als 1,1 zu sein.
- lp__: Logistische hintere Wahrscheinlichkeit [^ 2]
mcmc_normal
Inference for Stan model: anon_model_710b192b75c183bf7f98ae89c1ad472d.
4 chains, each with iter=2000; warmup=1000; thin=1;
post-warmup draws per chain=1000, total post-warmup draws=4000.
mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat
mu 4.9 0.01 0.47 4.0 4.61 4.89 5.18 5.87 1542 1.0
sigma 1.46 0.01 0.43 0.89 1.17 1.38 1.66 2.58 1564 1.0
pred[1] 4.85 0.03 1.58 1.77 3.88 4.86 5.83 8.0 3618 1.0
pred[2] 4.9 0.03 1.62 1.66 3.93 4.9 5.89 8.11 3673 1.0
pred[3] 4.87 0.03 1.6 1.69 3.86 4.85 5.86 8.14 3388 1.0
pred[4] 4.86 0.03 1.57 1.69 3.89 4.87 5.81 7.97 3790 1.0
pred[5] 4.88 0.03 1.6 1.67 3.89 4.89 5.89 7.98 3569 1.0
pred[6] 4.86 0.03 1.61 1.56 3.94 4.87 5.81 8.01 3805 1.0
pred[7] 4.89 0.03 1.6 1.7 3.9 4.88 5.86 8.09 3802 1.0
pred[8] 4.88 0.03 1.61 1.62 3.87 4.88 5.9 8.12 3210 1.0
pred[9] 4.87 0.03 1.6 1.69 3.86 4.87 5.85 8.1 3845 1.0
pred[10] 4.91 0.03 1.63 1.73 3.91 4.88 5.9 8.3 3438 1.0
lp__ -7.63 0.03 1.08 -10.48 -8.03 -7.29 -6.85 -6.57 1159 1.0
Samples were drawn using NUTS at Wed Jan 1 14:32:42 2020.
For each parameter, n_eff is a crude measure of effective sample size,
and Rhat is the potential scale reduction factor on split chains (at
convergence, Rhat=1).
Als ich fit.plot () ausprobierte, erschien WARNING, also folge ihm.
WARNING:pystan:Deprecation warning.
PyStan plotting deprecated, use ArviZ library (Python 3.5+).
pip install arviz; arviz.plot_trace(fit))
Sie können das Trace-Diagramm und die posteriore Verteilung leicht überprüfen.
arviz.plot_trace(mcmc_normal)
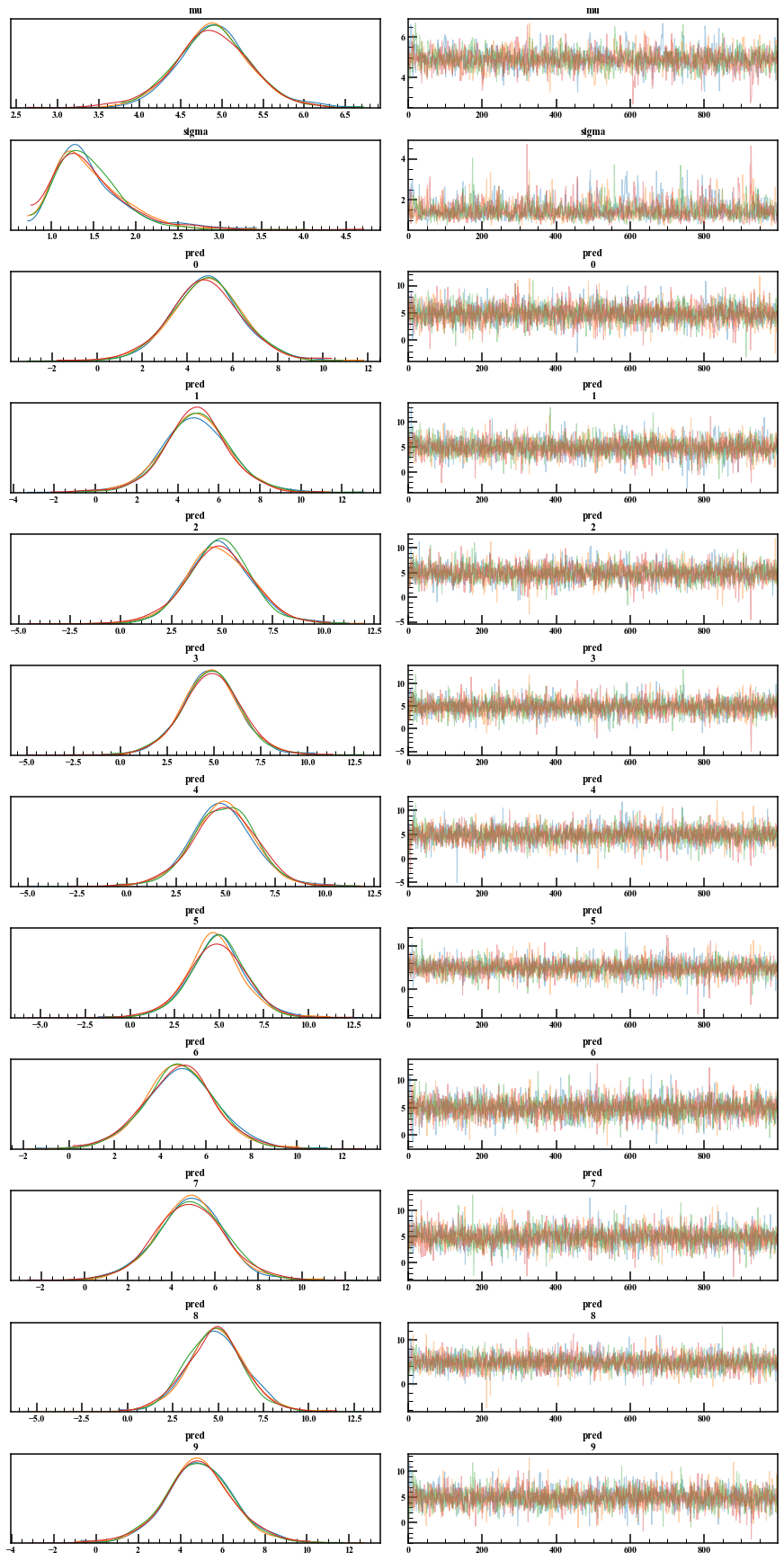
Wenn Sie etwas tun möchten, indem Sie direkt mit dem MCMC-Sample spielen, oder wenn Sie sich mehr an das Diagramm halten möchten, können Sie es mit Extract extrahieren. Standardmäßig ist permuted = True, was eine Zufallszahl gemischter Ordnung zurückgibt. Ich möchte, dass der Trace-Plot Zeitreihen sind. Lassen Sie dieses Argument also falsch. Inc_warmup gibt auch an, ob die Einbrennperiode eingeschlossen werden soll. Außerdem ergab fit ["Variablenname"] Zufallszahlen ohne die Einbrennzeit.
mcmc_extract = mcmc_normal.extract(permuted=False, inc_warmup=True)
mcmc_extract.shape
(2000, 4, 13)
Wenn Sie die Abmessungen überprüfen, ist dies (Iter, Ketten, Anzahl der Parameter). Obwohl die Anzahl der Diagramme 12 beträgt, gibt es eine 13. Dimension, aber wenn ich sie zeichne und überprüfe, sieht es aus wie lp__.
4. Einfache Regressionsanalyse
Zusammenfassend werden wir bisher eine einfache Regressionsanalyse mit Bayes'scher Schätzung durchführen. Sei $ y $ die Antwortvariable und $ x $ die erklärende Variable. Angenommen, $ y $ folgt einer Normalverteilung mit dem Mittelwert $ \ mu = ax + b $ und der Standardabweichung $ \ sigma ^ 2 $ mit dem Gradienten $ a $ und dem Abschnitt $ b $.
\begin{align}
\mu &= ax + b \\
y &\sim \mathcal{N}(\mu,\sigma^2)
\end{align}
Es zeigt auch die Notationen, die häufig in anderen einfachen Beschreibungen der Regressionsanalyse zu finden sind.
\begin{align}
y &= ax + b + \varepsilon \\
\varepsilon &\sim \mathcal{N}(0,\sigma^2)
\end{align}
Die beiden obigen Formeln sind gleich. Der erste gezeigte Ausdruck ist bequemer zum Schreiben von Stan-Code. In diesem Beispiel wird der Prozess zum Erhalten von $ y $ festgelegt und der Wert daraus abgetastet, um eine Bayes'sche Schätzung durchzuführen. Schauen Sie sich das Modell an und machen Sie einen Versuch und Irrtum, um es zu ändern.
4.1 Datenbestätigung
Erstellen Sie zunächst die Daten, die Sie verwenden möchten.
np.random.seed(seed=1) #Zufälliger Samen
a,b = 3.0,1.0 #Neigung und Schnitt
sig = 2.0 #Standardabweichung
x = 10.0* np.random.rand(100)
y = a*x + b + np.random.normal(0.0,sig,100)
Plotten und überprüfen. Zusätzlich wird die lineare Regression nach der Methode der kleinsten Quadrate angezeigt.
a_lsm,b_lsm = np.polyfit(x,y,1) #Lineare Regression mit Methode der kleinsten Quadrate(2.936985017531063, 1.473914508297817)
fig,axes = plt.subplots(figsize=(8,6))
axes.scatter(x,y)
axes.plot(np.linspace(0.0,10.0,100),a_lsm*np.linspace(0.0,10.0,100)+b_lsm)
axes.set_xlabel("x")
axes.set_ylabel("y")
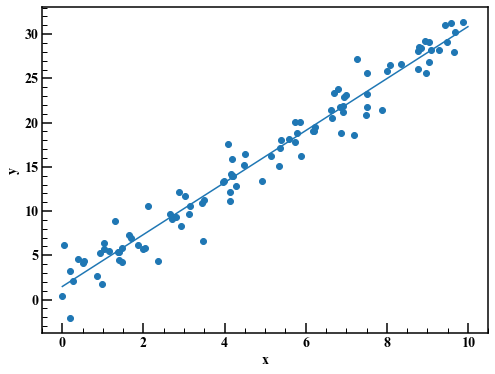
4.2 Berücksichtigung des Datengenerierungsprozesses und der Erstellung von Stan-Code
Angenommen, Sie haben den Prozess der Datenerstellung vollständig vergessen, sehen Sie sich das Diagramm an und denken Sie, dass $ y $ und $ x $ wahrscheinlich in einer proportionalen Beziehung stehen. Schreiben Sie den Stan-Code unter der Annahme, dass die Variabilität einer Normalverteilung folgt.
stan_code = """
data {
int N; //Stichprobengröße
vector[N] x; //Daten
vector[N] y; //Daten
int N_pred; //Voraussichtliche Stichprobengröße
vector[N_pred] x_pred; //Voraussichtliche Daten
}
parameters {
real a; //Neigung
real b; //Sektion
real<lower=0> sigma; //Standardabweichung<lower=0>Gibt an, dass nur Werte größer oder gleich 0 angenommen werden
}
transformed parameters {
vector[N] mu = a*x + b;
}
model {
// b ~ normal(0, 1000)Vorherige Verteilung angeben
//Normalverteilung des Mittelwerts mu, Standardabweichung Sigma
y ~ normal(mu, sigma); // "~"Das Symbol zeigt an, dass die linke Seite der Verteilung der rechten Seite folgt
}
generated quantities {
vector[N_pred] y_pred;
for (i in 1:N_pred) {
y_pred[i] = normal_rng(a*x_pred[i]+b, sigma);
}
}
"""
Der neu eingeführte transformierte Parameterblock kann mithilfe der im Parameterblock deklarierten Variablen neue Variablen erstellen. Diesmal ist es eine einfache Formel, daher gibt es keinen großen Unterschied. Wenn es sich jedoch um eine komplizierte Formel handelt, erhalten Sie eine bessere Übersicht. Wenn Sie die vorherige Verteilung angeben, schreiben Sie außerdem als "b ~ normal (0, 1000)" in den auskommentierten Modellblock.
4.3 MCMC ausführen
Kompilieren Sie den Stan-Code und führen Sie MCMC aus.
sm = pystan.StanModel(model_code=stan_code) #Stan-Code kompilieren
x_pred = np.linspace(0.0,11.0,200)
stan_data = {"N":len(x), "x":x, "y":y, "N_pred":200, "x_pred":x_pred}
#Führen Sie MCMC aus
mcmc_linear = sm.sampling(
data = stan_data,
iter = 4000,
warmup = 1000,
chains = 4,
thin = 1,
seed = 1
)
4.4 Überprüfen der Ergebnisse
print(mcmc_linear)
Inference for Stan model: anon_model_28ac7b1919f5bf2d52d395ee71856f88.
4 chains, each with iter=4000; warmup=1000; thin=1;
post-warmup draws per chain=3000, total post-warmup draws=12000.
mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat
a 2.94 9.0e-4 0.06 2.82 2.89 2.94 2.98 3.06 4705 1.0
b 1.47 5.1e-3 0.35 0.79 1.24 1.47 1.71 2.16 4799 1.0
sigma 1.83 1.7e-3 0.13 1.59 1.74 1.82 1.92 2.12 6199 1.0
mu[1] 13.72 1.8e-3 0.19 13.35 13.59 13.72 13.85 14.09 10634 1.0
mu[2] 22.63 2.2e-3 0.24 22.16 22.47 22.63 22.78 23.1 11443 1.0
Samples were drawn using NUTS at Wed Jan 1 15:07:22 2020.
For each parameter, n_eff is a crude measure of effective sample size,
and Rhat is the potential scale reduction factor on split chains (at
convergence, Rhat=1).
Es wird weggelassen, da es sich um eine sehr lange Ausgabe handelt. Mit Blick auf Rhat scheint die Konvergenz in Ordnung zu sein. Das 95% -Kreditintervall ist aus der posterioren Prognoseverteilung ersichtlich.
reg_95 = np.quantile(mcmc_linear["y_pred"],axis=0,q=[0.025,0.975]) #Ex-post-Vorhersageverteilung
fig,axes = plt.subplots(figsize=(8,6))
axes.scatter(x,y,label="Data",c="k")
axes.plot(x_pred,np.average(mcmc_linear["y_pred"],axis=0),label="Expected value")
axes.fill_between(x_pred,reg_95[0],reg_95[1],alpha=0.1,label="95%")
axes.legend(loc="best")
axes.set_xlabel("x")
axes.set_ylabel("y")
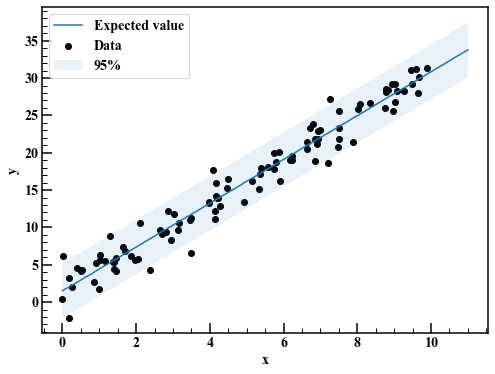
Es sieht im Allgemeinen gut aus.
Zusammenfassung
Durch die Bayes'sche Schätzung des einfachen Regressionsmodells lernte ich den Fluss der Bayes'schen Schätzung und die Verwendung von Stan. Zeichnen Sie den Fluss der Bayes'schen Schätzung erneut auf.
- Überprüfen Sie die Daten: Erfassen Sie die Struktur der Daten, indem Sie sie in einem Diagramm darstellen.
- Berücksichtigung des Datengenerierungsprozesses und der Erstellung von Stan-Code: Schreiben Sie Stan-Code, indem Sie die Datenstruktur formulieren.
- MCMC ausführen: Führen Sie MCMC aus, um die posteriore Verteilung zu erhalten.
- Überprüfen Sie das Ergebnis: Überprüfen Sie das Ergebnis und ändern Sie das Modell wiederholt.
Dieses Mal habe ich ein einfaches Modell verwendet, aber beim nächsten Mal möchte ich ein allgemeineres Modell wie ein Zustandsraummodell ausprobieren.