[PYTHON] Gesichtserkennung mit Haar Cascades
Basierend auf py_face_detection.markdown In "Open CV-Python Tutorials" japanische Übersetzung [Face Detection using Haar Cascades] (http://docs.opencv.org/3.0-beta/doc/py_tutorials/py_objdetect/py_face_detection/py_face_detection.html#face-detection) Ich habe eine Übersetzung von gemacht. Die japanische Übersetzung wird nach dem englischen Original hinzugefügt. Ich hoffe, es hilft Ihnen, sich für den Algorithmus zu interessieren.
Die folgende Seite ist oben, also brauche ich meine beschissene Übersetzung nicht mehr.
OpenCV-Python-Tutorial-Dokumentenseite an der Tottori University [Gesichtserkennung mit Haar Cascades] (http://labs.eecs.tottori-u.ac.jp/sd/Member/oyamada/OpenCV/html/py_tutorials/py_objdetect/py_face_detection/py_face_detection.html#face-detection)
Face Detection using Haar Cascades {#tutorial_py_face_detection} Gesichtserkennung mit Haar Cascades
Goal
In this session,
- We will see the basics of face detection using Haar Feature-based Cascade Classifiers
- We will extend the same for eye detection etc.
In diesem Abschnitt,
--Lernen Sie die Grundlagen der Gesichtserkennung mit dem Cascade-Klassifikator, der auf Haar-Funktionen basiert. ――Es wird erweitert und zur Augenerkennung verwendet.
Basics
Object Detection using Haar feature-based cascade classifiers is an effective object detection method proposed by Paul Viola and Michael Jones in their paper, "Rapid Object Detection using a Boosted Cascade of Simple Features" in 2001. It is a machine learning based approach where a cascade function is trained from a lot of positive and negative images. It is then used to detect objects in other images. Die Objekterkennung mit dem auf Haarmerkmalen basierenden Cascade-Klassifikator ist eine effiziente Methode zur Objekterkennung, die von Paul Viola und Michael Jones als "Schnelle Objekterkennung mit a" beschrieben wird. Vorgeschlagen in einem Artikel in Boosted Cascade of Simple Features "(2001). Die Technik ist ein auf maschinellem Lernen basierender Ansatz, bei dem jeder Kaskadenklassifizierer aus einer großen Anzahl positiver und negativer Bilder trainiert wird. Nach dem Training wird es verwendet, um Objekte in anderen Bildern zu erkennen.
Here we will work with face detection. Initially, the algorithm needs a lot of positive images (images of faces) and negative images (images without faces) to train the classifier. Then we need to extract features from it. For this, haar features shown in below image are used. They are just like our convolutional kernel. Each feature is a single value obtained by subtracting sum of pixels under white rectangle from sum of pixels under black rectangle.
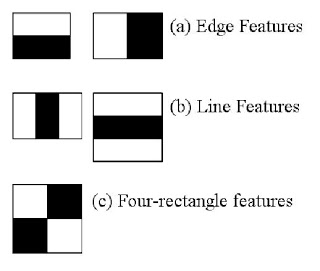
Beginnen wir jetzt mit der Gesichtserkennung. Erstens verwendet der Algorithmus eine große Anzahl positiver Bilder (Gesichtsbilder) und negativer Bilder (gesichtslose Bilder), um den Klassifikator zu trainieren. Als nächstes müssen wir die Features aus dem Bild extrahieren. Zu diesem Zweck werden die in der folgenden Abbildung gezeigten Haar-Merkmale verwendet. Haarmerkmale sind wie ein Faltungskern. Jedes Merkmal ist eine einzelne Zahl, die die Summe der Helligkeit der Pixel an der Position des schwarzen Quadrats abzüglich der Gesamthelligkeit der Pixel an der Position des weißen Quadrats darstellt.
Now all possible sizes and locations of each kernel is used to calculate plenty of features. (Just imagine how much computation it needs? Even a 24x24 window results over 160000 features). For each feature calculation, we need to find sum of pixels under white and black rectangles. To solve this, they introduced the integral images. It simplifies calculation of sum of pixels, how large may be the number of pixels, to an operation involving just four pixels. Nice, isn't it? It makes things super-fast.
Zu diesem Zeitpunkt werden alle möglichen Größen und Positionen jedes Kernels verwendet, um eine große Anzahl von Features zu berechnen. (Stellen Sie sich vor, wie viele Berechnungen erforderlich sind. Selbst ein 24x24-Pixel-Fenster verfügt über mehr als 16000 Funktionen.) Um dieses Problem zu lösen, wurde ein integriertes Bild eingeführt. Durch Verwendung des integrierten Bildes ist es einfach, den Gesamtpixelwert zu berechnen. Egal wie viele Pixel es gibt, wir ersetzen es durch eine Operation, die die Werte von vier Pixeln (im integrierten Bild) verwendet. Es wäre nett. Durch die Verwendung des integrierten Bildes ist es sehr schnell.
But among all these features we calculated, most of them are irrelevant. For example, consider the image below. Top row shows two good features. The first feature selected seems to focus on the property that the region of the eyes is often darker than the region of the nose and cheeks. The second feature selected relies on the property that the eyes are darker than the bridge of the nose. But the same windows applying on cheeks or any other place is irrelevant. So how do we select the best features out of 160000+ features? It is achieved by Adaboost.

Die meisten dieser berechneten Merkmale sind jedoch irrelevant (für die Gesichtsidentifikation). Ein Beispiel finden Sie in der folgenden Abbildung. Die obere Reihe zeigt zwei gute Eigenschaften. Das erste ausgewählte Merkmal scheint sich auf die Eigenschaft zu konzentrieren, dass die Augenpartie tendenziell dunkler ist als die Nasen- und Wangenbereiche. Das zweite ausgewählte Merkmal hängt von der Eigenschaft ab, dass der Bereich beider Augen dunkler als die Nasenmuskulatur ist. Aber selbst im selben Fenster ist das auf der Wange oder anderswo verwendete irrelevant (um festzustellen, ob es sich um ein Gesicht handelt). Wie wählen Sie die optimalen Mehrfachfunktionen aus über 16000 Funktionen aus? Es wurde von ** Ada Boost ** erreicht.
For this, we apply each and every feature on all the training images. For each feature, it finds the best threshold which will classify the faces to positive and negative. But obviously, there will be errors or misclassifications. We select the features with minimum error rate, which means they are the features that best classifies the face and non-face images. (The process is not as simple as this. Each image is given an equal weight in the beginning. After each classification, weights of misclassified images are increased. Then again same process is done. New error rates are calculated. Also new weights. The process is continued until required accuracy or error rate is achieved or required number of features are found).
Dadurch wird jede Funktion auf alle Trainingsbilder angewendet. Finden Sie für jedes Feature den besten Schwellenwert, um Gesichtskandidaten in positive und negative zu klassifizieren. Es ist jedoch klar, dass Fehler und Fehlklassifizierungen auftreten. Wählen Sie die Funktion mit der niedrigsten Fehlerrate. Mit anderen Worten, es ist die Merkmalsmenge, die Gesichts- und Nichtgesichtsbilder am besten klassifiziert. (Der eigentliche Vorgang ist nicht so einfach wie hier beschrieben. Anfangs erhalten alle Bilder das gleiche Gewicht. Nach jeder Klassifizierung werden die falsch klassifizierten Bilder gewichtet. Dieser Vorgang entspricht der erforderlichen Genauigkeit. Es wird wiederholt, bis die Fehlerrate erreicht ist oder die Merkmalsmenge der Anzahl der angeforderten Werte gefunden wurde.)
Final classifier is a weighted sum of these weak classifiers. It is called weak because it alone can't classify the image, but together with others forms a strong classifier. The paper says even 200 features provide detection with 95% accuracy. Their final setup had around 6000 features. (Imagine a reduction from 160000+ features to 6000 features. That is a big gain).
Der letzte Diskriminator wird als Gewichtung dieser schwachen Diskriminatoren erhalten. Es wird als schwacher Klassifikator bezeichnet, da es Bilder nicht selbst klassifizieren kann, aber es wird mit mehreren anderen schwachen Klassifikatoren kombiniert, um einen starken Klassifikator zu bilden. Dem Papier zufolge ermöglichen sogar 200 Funktionen eine Erkennung mit einer Genauigkeit von 95%. Ihre endgültige Konfiguration verwendet ungefähr 6000 Funktionen. (Berücksichtigen Sie, dass die Anzahl der Funktionen von über 160.000 auf 6000 reduziert wurde. Sie wird erheblich gesunken sein.)
So now you take an image. Take each 24x24 window. Apply 6000 features to it. Check if it is face or not. Wow.. Wow.. Isn't it a little inefficient and time consuming? Yes, it is. Authors have a good solution for that.
Also werde ich jetzt ein Bild vorbereiten. Wenden Sie jedes 24x24-Pixel-Fenster an. Wenden Sie 6000 Funktionen auf das Fenster an. Überprüfen Sie, ob es sich um ein Gesicht oder ein Nicht-Gesicht handelt. Oh, bist du ein bisschen lächerlich und ineffizient und verschwendest deine Zeit? Korrekt. Die Autoren haben eine gute Lösung dafür.
In an image, most of the image region is non-face region. So it is a better idea to have a simple method to check if a window is not a face region. If it is not, discard it in a single shot. Don't process it again. Instead focus on region where there can be a face. This way, we can find more time to check a possible face region.
In einem einzelnen Bild sind die meisten Bereiche des Bildes Nichtgesichtsbereiche. Es ist daher eine gute Idee, auf einfache Weise sicherzustellen, dass der Fensterbereich nicht der Gesichtsbereich ist. Wenn der Fensterbereich nicht der Gesichtsbereich ist, werfen Sie ihn sofort weg. Es wird nicht erneut verarbeitet (mit einem starken Diskriminator). Konzentrieren Sie sich stattdessen auf Bereiche, die Gesichter sein können. Auf diese Weise können Sie mehr Zeit damit verbringen, nach möglichen Gesichtsbereichen zu suchen.
For this they introduced the concept of Cascade of Classifiers. Instead of applying all the 6000 features on a window, group the features into different stages of classifiers and apply one-by-one. (Normally first few stages will contain very less number of features). If a window fails the first stage, discard it. We don't consider remaining features on it. If it passes, apply the second stage of features and continue the process. The window which passes all stages is a face region. How is the plan !!!
Darüber führten sie das Konzept des ** Kaskadenklassifikators ** ein. Anstatt alle 6000 Features auf einen Fensterbereich anzuwenden, wird der Feature-Set in Klassifizierer gruppiert, die zu verschiedenen Stufen gehören, und einzeln angewendet. (Normalerweise enthalten die ersten Stufen eine sehr kleine Anzahl von Funktionen.)
Wenn Sie auf der ersten Stufe in einem Fensterbereich versagen. Verwerfen Sie diesen Fensterbereich. Die verbleibenden Funktionen in diesem Bereich werden nicht berücksichtigt. Wenn es in der ersten Stufe erfolgreich ist, wenden Sie die zweite Feature-Gruppe an und setzen Sie die Verarbeitung fort. Der Fensterbereich, der durch alle Stufen geführt wird, ist der Gesichtsbereich.
Authors' detector had 6000+ features with 38 stages with 1, 10, 25, 25 and 50 features in first five stages. (Two features in the above image is actually obtained as the best two features from Adaboost). According to authors, on an average, 10 features out of 6000+ are evaluated per sub-window.
Der Detektor des Autors ist ein 38-stufiger Klassifikator mit mehr als 6000 Merkmalen, mit 1, 10, 25, 25, 50 Merkmalen in den ersten 5 Stufen. (Die beiden Merkmale in der obigen Abbildung wurden von Adaboost tatsächlich als die beiden besten Merkmale erhalten.) Nach Angaben des Autors durchschnittlich 10 von 6000 oder mehr pro Unterfenster. Merkmale werden ausgewertet
So this is a simple intuitive explanation of how Viola-Jones face detection works. Read paper for more details or check out the references in Additional Resources section. Hier finden Sie eine schnelle und intuitive Erklärung der Funktionsweise der Viola-Jones-Gesichtserkennung. Weitere Informationen finden Sie im Dokument oder in den Referenzinformationen im Abschnitt Zusätzliche Ressourcen.
Haar-cascade Detection in OpenCV Haarkaskadenerkennung in OpenCV
OpenCV comes with a trainer as well as detector. If you want to train your own classifier for any object like car, planes etc. you can use OpenCV to create one. Its full details are given here: Cascade Classifier Training.
OpenCV hat einen Trainer sowie einen Detektor. Wenn Sie Ihre eigenen Klassifikatoren für Objekte wie Autos und Flugzeuge trainieren (lernen) möchten, können Sie OpenCV dafür verwenden. Die Details finden Sie hier. Learning Cascade Detector.
Here we will deal with detection. OpenCV already contains many pre-trained classifiers for face, eyes, smile etc. Those XML files are stored in opencv/data/haarcascades/ folder. Let's create face and eye detector with OpenCV.
Jetzt lass es uns erkennen. OpenCV enthält bereits geschulte Detektoren wie Gesichtserkennung, Augenerkennung und Lächelnerkennung. Diese XMLs werden im Ordner opencv / data / haarcascades / gespeichert. Lassen Sie uns einen OpenCV-Gesichts- und Augendetektor herstellen.
First we need to load the required XML classifiers. Then load our input image (or video) in grayscale mode.
Zunächst müssen Sie den angegebenen XML-Klassifikator lesen. Lesen Sie dann das Eingabebild (oder Video) im Graustufenmodus.
python
import numpy as np
import cv2
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
eye_cascade = cv2.CascadeClassifier('haarcascade_eye.xml')
img = cv2.imread('sachin.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
Now we find the faces in the image. If faces are found, it returns the positions of detected faces as Rect(x,y,w,h). Once we get these locations, we can create a ROI for the face and apply eye detection on this ROI (since eyes are always on the face !!! ).
Finden Sie nun das Gesicht im Bild. Wenn ein Gesicht gefunden wird, wird die Position jedes erkannten Gesichts von Rect (x, y, w, h) zurückgegeben. Sobald diese Positionen gefunden wurden, können Sie den ROI für das Gesicht festlegen und die Augenerkennung auf diesen ROI anwenden. (Weil ich immer Augen auf meinem Gesicht habe)
python
faces = face_cascade.detectMultiScale(gray, 1.3, 5)
for (x,y,w,h) in faces:
cv2.rectangle(img,(x,y),(x+w,y+h),(255,0,0),2)
roi_gray = gray[y:y+h, x:x+w]
roi_color = img[y:y+h, x:x+w]
eyes = eye_cascade.detectMultiScale(roi_gray)
for (ex,ey,ew,eh) in eyes:
cv2.rectangle(roi_color,(ex,ey),(ex+ew,ey+eh),(0,255,0),2)
cv2.imshow('img',img)
cv2.waitKey(0)
cv2.destroyAllWindows()
Result looks like below: Das Ergebnis ist wie folgt:

Additional Resources
-# Video Lecture on Face Detection and Tracking 2. An interesting interview regarding Face Detection by Adam Harvey
Exercises
Recommended Posts