[PYTHON] Erste Anime-Gesichtserkennung mit Chainer
Ich wollte Deep Learning ausprobieren, aber mit Caffe war ich frustriert, ohne das Gefühl zu haben, "zu schreiben", aber Chainer erschien, also beschloss ich, es auszuprobieren.
Wie auch immer, ich werde es mit der Gesichtserkennung von Anime versuchen, was ich schon immer machen wollte. Eigentlich würde ich gerne versuchen, Gesichtsdetektor + Zeichen nach Gesicht zu klassifizieren, aber zuerst möchte ich Gesichter und andere klassifizieren.
Übrigens, wenn es um die Gesichtserkennung in Anime geht, gibt es einen Detector von OpenCV + Cascade, der ihn recht gut erkennt. Aber,
――Prinzipiell können Sie von vorne nichts anderes als das Gesicht erkennen. ――Es wird nicht erkannt, auch wenn es etwas geneigt ist.
Da es Probleme wie gibt, möchte ich die Erkennungsgenauigkeit irgendwie verbessern.
Schritt 1: Bereiten Sie das Testbild vor
Ich beschloss, es selbst vorzubereiten und es auch für andere Aufgaben zu verwenden. Es dauert ungefähr 20 Stunden. Poyo-n.
Politik
- Verwenden Sie OpenCV und lbpcascade_animeface, um ein Gesicht aus einem Anime-Frame auszuschneiden.
- Setzen Sie das falsch erkannte Bild von dort in den richtigen Antwortsatz ein.
- Extrahieren Sie mit OpenCV erneut den Rahmen, in dem das Gesicht nicht erkannt wurde.
- Suchen Sie aus dem Bild in 3. das Bild, das das Gesicht tatsächlich zeigt, schneiden Sie das Zielgesicht aus und fügen Sie es dem richtigen Antwortsatz hinzu.
- Schneiden Sie den Rest zufällig ohne Gesicht aus dem Rahmen und fügen Sie ihn dem falschen Antwortsatz hinzu.
- Drehen Sie jedes Bild um 90 Grad, 180 Grad und 270 Grad, um die Daten mit dem Faktor vier zu multiplizieren.
- Auf 64x64 konvertiert, da aufgrund des Netzwerkdesigns dieselbe Eingabegröße erforderlich war.
Trainingsset
- 1101025 (34.355 Gesichtsdaten, 76.170 andere Bilder)
- AngelBeats !, Kilmy Baby, Fest ... usw. ――Ich wollte das auswählen, das ein anderes Muster zu haben scheint.
Validierungssatz
―― 8.525 Blatt (Gesichtsdaten 3.045 Blatt, andere Bilder 5.480 Blatt)
- Kin Mosa
Ich mag die Tatsache nicht, dass das Verhältnis von Trainingssatz und Validierungssatz nicht gleich ist, aber ich werde vorerst weitermachen.
Bildbeispiel
--Gesichtsbild

- Das ganze

Schritt 2: Erstellen Sie einen Lernenden
CNN
network/frgnet64.py
import chainer
import chainer.functions as F
class FrgNet64(chainer.FunctionSet):
insize = 64
def __init__(self):
super(FrgNet64, self).__init__(
conv1 = F.Convolution2D(3, 96, 5, pad=2),
bn1 = F.BatchNormalization(96),
conv2 = F.Convolution2D(96, 128, 5, pad=2),
bn2 = F.BatchNormalization(128),
conv3 = F.Convolution2D(128, 256, 3, pad=1),
conv4 = F.Convolution2D(256, 384, 3, pad=1),
fc5 = F.Linear(18816, 2048),
fc6 = F.Linear(2048, 2),
)
def forward_but_one(self, x_data, train=True):
x = chainer.Variable(x_data, volatile=not train)
h = F.max_pooling_2d(F.relu(self.bn1(self.conv1(x))), 5, stride=2)
h = F.max_pooling_2d(F.relu(self.bn2(self.conv2(h))), 5, stride=2)
h = F.max_pooling_2d(F.relu(self.conv3(h)), 3, stride=2)
h = F.leaky_relu(self.conv4(h), slope=0.2)
h = F.dropout(F.leaky_relu(self.fc5(h), slope=0.2), train=train)
return self.fc6(h)
def calc_confidence(self, x_data):
h = self.forward_but_one(x_data, train=False)
return F.softmax(h)
def forward(self, x_data, y_data, train=True):
""" You must subtract the mean value from the data before. """
y = chainer.Variable(y_data, volatile=not train)
h = self.forward_but_one(x_data, train=train)
return F.softmax_cross_entropy(h, y), F.accuracy(h, y)
- Wenn die Anzahl der vollständig verbundenen Schichten drei beträgt, kann die Genauigkeit geringfügig verbessert werden, die Verarbeitungsgeschwindigkeit ist jedoch erheblich gesunken, sodass wir sie nicht verwendet haben.
Code lernen
network/manager.py
import numpy as np
import time
import six
from util import loader
from chainer import cuda, optimizers
class NetSet:
def __init__(self, meanpath, model, gpu=-1):
self.mean = loader.load_mean(meanpath)
self.model = model
self.gpu = gpu
self.insize = model.insize
if gpu >= 0:
cuda.init(gpu)
self.model.to_gpu()
def calc_max_label(self, prob_arr):
h, w = prob_arr.shape
labels = [0] * h
for i in six.moves.range(0, h):
label = prob_arr[i].argmax()
labels[i] = (label, prob_arr[i][label])
return labels
def forward_data_seq(self, dataset, batchsize):
sum_loss = 0
sum_accuracy = 0
for i in range(0, len(dataset), batchsize):
mini_dataset = dataset[i:i+batchsize]
x_batch, y_batch = self.create_minibatch(mini_dataset)
loss, acc = self.forward_minibatch(x_batch, y_batch)
loss_data = loss.data
acc_data = acc.data
if self.gpu >= 0:
loss_data = cuda.to_cpu(loss_data)
acc_data = cuda.to_cpu(acc_data)
sum_loss += float(loss_data) * len(mini_dataset)
sum_accuracy += float(acc_data) * len(mini_dataset)
return sum_loss, sum_accuracy
def forward_minibatch(self, x_batch, y_batch, train=False):
if self.gpu >= 0:
x_batch = cuda.to_gpu(x_batch)
y_batch = cuda.to_gpu(y_batch)
return self.model.forward(x_batch, y_batch, train=False)
def create_minibatch(self, dataset):
minibatch = np.ndarray(
(len(dataset), 3, self.insize, self.insize), dtype=np.float32)
minibatch_label = np.ndarray((len(dataset),), dtype=np.int32)
for idx, tuple in enumerate(dataset):
path, label = tuple
minibatch[idx] = loader.load_image(path, self.mean, False)
minibatch_label[idx] = label
return minibatch, minibatch_label
def create_minibatch_random(self, dataset, batchsize):
if dataset is None or len(dataset) == 0:
return self.create_minibatch([])
rs = np.random.random_integers(0, high=len(dataset) - 1, size=(batchsize,))
minidataset = []
for idx in rs:
minidataset.append(dataset[idx])
return self.create_minibatch(minidataset)
train/batch.py
import numpy as np
import sys
import time
import six
import six.moves.cPickle as pickle
from util import loader, visualizer
from chainer import cuda, optimizers
from network.manager import NetSet
class Trainer(NetSet):
""" Network utility class """
def __init__(self, trainlist, validlist, meanpath, model,
optimizer, weight_decay=0.0001, gpu=-1):
super(Trainer, self).__init__(meanpath, model, gpu)
self.trainset = loader.load_image_list(trainlist)
self.validset = loader.load_image_list(validlist)
self.optimizer = optimizer
self.wd_rate = weight_decay
if gpu >= 0:
cuda.init(gpu)
self.model.to_gpu()
optimizer.setup(model.collect_parameters())
def train_random(self, batchsize, lr_decay=0.1, valid_interval=500,
model_interval=10, log_interval=100, max_epoch=100):
epoch_iter = 0
if batchsize > 0:
epoch_iter = len(self.trainset) // batchsize + 1
begin_at = time.time()
for epoch in six.moves.range(1, max_epoch + 1):
print('epoch {} starts.'.format(epoch))
train_duration = 0
sum_loss = 0
sum_accuracy = 0
N = batchsize * log_interval
for iter in six.moves.range(1, epoch_iter):
iter_begin_at = time.time()
x_batch, y_batch = self.create_minibatch_random(self.trainset, batchsize)
loss, acc = self.forward_minibatch(x_batch, y_batch)
train_duration += time.time() - iter_begin_at
if epoch == 1 and iter == 1:
visualizer.save_model_graph(loss, 'graph.dot')
visualizer.save_model_graph(loss, 'graph.split.dot', remove_split=True)
print('model graph is generated.')
sum_loss += float(cuda.to_cpu(loss.data)) * batchsize
sum_accuracy += float(cuda.to_cpu(acc.data)) * batchsize
if iter % log_interval == 0:
throughput = batchsize * iter / train_duration
print('training: iteration={:d}, mean loss={:.8f}, accuracy rate={:.6f}, learning rate={:f}, weight decay={:f}'
.format(iter + (epoch - 1) * epoch_iter, sum_loss / N, sum_accuracy / N, self.optimizer.lr, self.wd_rate))
print('epoch {}: passed time={}, throughput ({} images/sec)'
.format(epoch, train_duration, throughput))
sum_loss = 0
sum_accuracy = 0
if iter % valid_interval == 0:
N_test = len(self.validset)
valid_begin_at = time.time()
valid_sum_loss, valid_sum_accuracy = self.forward_data_seq(self.validset, batchsize, train=False)
valid_duration = time.time() - valid_begin_at
throughput = N_test / valid_duration
print('validation: iteration={:d}, mean loss={:.8f}, accuracy rate={:.6f}'
.format(iter + (epoch - 1) * epoch_iter, valid_sum_loss / N_test, valid_sum_accuracy / N_test))
print('validation time={}, throughput ({} images/sec)'
.format(valid_duration, throughput))
sys.stdout.flush()
self.optimizer.lr *= lr_decay
self.wd_rate *= lr_decay
if epoch % model_interval == 0:
print('saving model...(epoch {})'.format(epoch))
pickle.dump(self.model, open('model-' + str(epoch) + '.dump', 'wb'), -1)
print('train finished, total duration={} sec.'
.format(time.time() - begin_at))
pickle.dump(self.model, open('model.dump', 'wb'), -1)
def forward_data_seq(self, dataset, batchsize, train=True):
sum_loss = 0
sum_accuracy = 0
for i in range(0, len(dataset), batchsize):
mini_dataset = dataset[i:i+batchsize]
x_batch, y_batch = self.create_minibatch(mini_dataset)
loss, acc = self.forward_minibatch(x_batch, y_batch, train)
loss_data = loss.data
acc_data = acc.data
if self.gpu >= 0:
loss_data = cuda.to_cpu(loss_data)
acc_data = cuda.to_cpu(acc_data)
sum_loss += float(loss_data) * len(mini_dataset)
sum_accuracy += float(acc_data) * len(mini_dataset)
return sum_loss, sum_accuracy
def forward_minibatch(self, x_batch, y_batch, train=True):
if self.gpu >= 0:
x_batch = cuda.to_gpu(x_batch)
y_batch = cuda.to_gpu(y_batch)
if train:
self.optimizer.zero_grads()
loss, acc = self.model.forward(x_batch, y_batch, train)
if train:
loss.backward()
self.optimizer.weight_decay(self.wd_rate)
self.optimizer.update()
return loss, acc
util/loader.py
import os
import numpy as np
import six.moves.cPickle as pickle
from PIL import Image
### functions to load files, such as model.dump, images, and mean file.
def unpickle(filepath):
return pickle.load(open(filepath, 'rb'))
def load_model(filepath):
""" load trained model.
If the model is trained on GPU, then you must initialize cuda-driver before.
"""
return unpickle(filepath)
def load_mean(filepath):
""" load mean file
"""
return unpickle(filepath)
def load_image_list(filepath):
""" load image-file list. Image-file list file consists of filepath and the label.
"""
tuples = []
for line in open(filepath):
pair = line.strip().split()
if len(pair) == 0:
continue
elif len(pair) > 2:
raise ValueError("list file format isn't correct: [filepath] [label]")
else:
tuples.append((pair[0], np.int32(pair[1])))
return tuples
def image2array(img):
return np.asarray(img).transpose(2, 0, 1).astype(np.float32)
def load_image(path, mean, flip=False):
image = image2array(Image.open(path))
image -= mean
if flip:
return image[:, :, ::-1]
else:
return image
Da main.py chaotisch ist, werde ich nur den Trainingsteil extrahieren.
main.py
### a function for training.
def train(trainlist, validlist, meanpath, modelname, batchsize, max_epoch=100, gpu=-1):
model = None
if modelname == "frg64":
model = FrgNet64()
elif modelname == "frg128":
model = FrgNet128()
optimizer = optimizers.MomentumSGD(lr=0.001, momentum=0.9)
trainer = batch.Trainer(trainlist, validlist, meanpath, model,
optimizer, 0.0001, gpu)
trainer.train_random(batchsize, lr_decay=0.97, valid_interval=1000,
model_interval=5, log_interval=20, max_epoch=max_epoch)
Beim Lernen wird grundsätzlich eine GPU verwendet. Da die Bildgröße klein ist, ist die CPU-Seite nicht für Multithreading geschrieben.
Schritt 3: Lernen
Parameter
| Parameter | Wert einstellen | Bemerkungen |
|---|---|---|
| learning rate | 0.001 | 0 für jede 1 Epoche.97 multiplizieren |
| Mini-Chargengröße | 10 | |
| Gewichtsabschwächung | 0.0001 | Jedes Mal, wenn die Epoche abläuft, wird der Koeffizient λ zu 0.97 multiplizieren |
| momentum | 0.9 | Standardwert von Chainer |
――Ich habe versucht, die Lernrate zu senken, als die Fehleränderung flach wurde, aber ich habe sie gestoppt, weil der Fehler für den Validierungssatz nicht gut konvergierte. ――Ich habe zuerst die Mini-Batch-Größe bei 100 ausprobiert, sie aber kleiner gemacht, weil der Unterschied zwischen dem Trainingssatz und dem Validierungssatz groß war. ――Der Gewichtsabschwächungskoeffizient hätte festgelegt werden können, aber ich befürchtete, dass sich die Lernrate und der Wert irgendwann umkehren würden, sodass ich ihn schrittweise reduziere.
Umgebung
| Version etc. | |
|---|---|
| GPU | GeForce GTX TITAN X |
| Python | Python 3.4.3 |
Ergebnis
Benötigte Zeit
Insgesamt dauerte es weniger als 3 Stunden und der Trainingsfehler war fast 0, so dass er mit Epoche 30 endete. Die Bildverarbeitungsgeschwindigkeit ist ungefähr
- Während des Trainings 560 Blatt / Sek
- Validierung von 780 Blatt / Sek
war.
Error
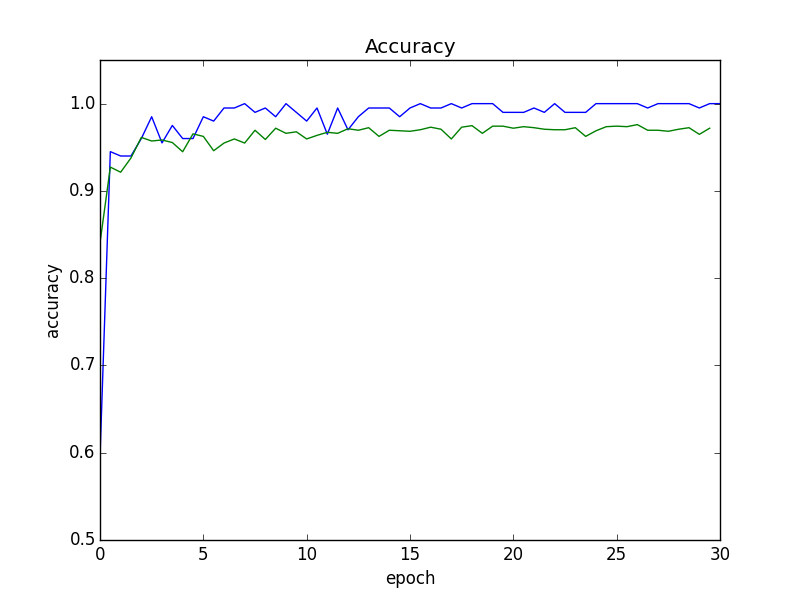
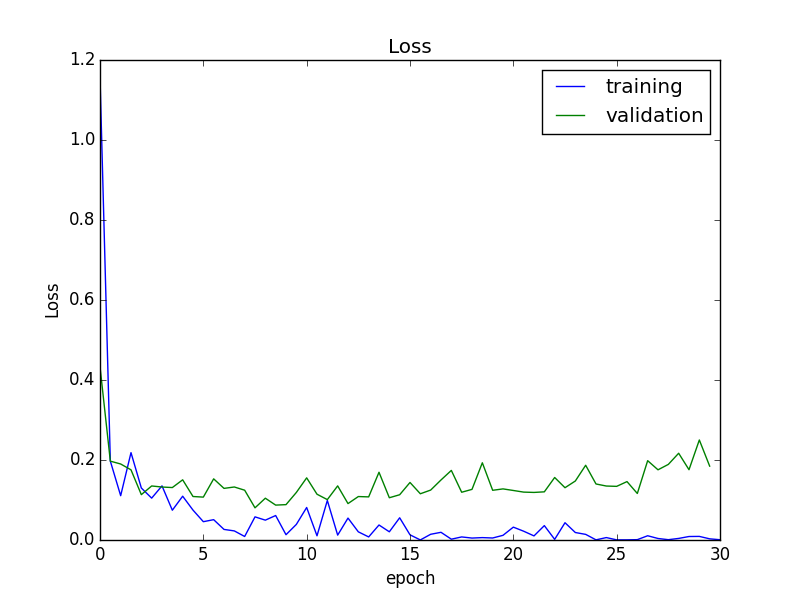
Von der Mitte aus ist die Erkennungsgenauigkeit fast konvergiert, aber der Fehler in Bezug auf den Validierungssatz hat leicht zugenommen. Daher werden wir in den nachfolgenden Experimenten das Modell am Ende der 15. Epoche verwenden, das den kleinsten Fehler aufweist.
Dieses Modell hatte eine Erkennungsgenauigkeit von 95,5% für den Validierungssatz. Unten finden Sie ein Beispiel für einen fehlgeschlagenen Fall.
Beispiel für eine Fehlerkennung
Fälle, die fälschlicherweise als Gesichter erkannt werden

Es scheint, dass einige Testdaten fehlerhaft sind (Kennzeichnungsfehler). ..
Fall, in dem das Gesicht nicht erkannt werden kann

Es gibt einige Daten, bei denen ich das Gesicht nicht sauber ausgeschnitten habe, aber ich habe das Gefühl, einen Fehler zu machen, also mache ich mir ein wenig Sorgen ...
Schritt 4: Geben Sie die tatsächlichen Daten ein
Schneiden Sie das Bild im Schiebefenster aus und fügen Sie es in das trainierte Netzwerk ein. Wenn Sie es einfach ausschneiden, wird es eine beträchtliche Anzahl von Blättern sein, also nachdem Sie die Breite des Bildes auf 512 reduziert haben,
--Aspektverhältnis 1: 1
- (Größe, Schritt) hat 3 Muster von (48, 16), (72, 24), (144, 48)
Ich habe es mit ausgeschnitten und es während des Trainings auf die gleiche Größe wie 64x64 angepasst. (Im vorliegenden Bild gibt es insgesamt 630 Möglichkeiten) (Korrigiert am 8. August 2015)
Wenn Sie es in das Netzwerk einfügen und den Bereich extrahieren können, der für das Gesicht in Frage kommt, sieben Sie den Bereich basierend auf IoU (Intersection over Union)> = 30%, und der Ausgabewert (Wahrscheinlichkeit) des Netzwerks ist das Maximum. Ich wähle einen. (Ich weiß nicht, ob der absolute Wert dieses Wertes sinnvoll ist) IoU mit anderen Bereichen als dem Gesicht wird nicht besonders berücksichtigt.
Experiment
Es wird im Vergleich zum Ergebnis eines Versuchs mit OpenCV + lbpcascade_animeface veröffentlicht. Die Ergebnisse können sich jedoch abhängig von den Parametern ändern, daher denke ich nicht, dass dies unbedingt ein fairer Vergleich ist. (Oben ist das von CNN erkannte Bild und unten ist das von OpenCV erkannte Bild.) Die durchschnittliche Ausführungszeit betrug ungefähr 0,8 Sekunden für CNN (GPU) und ungefähr 0,35 Sekunden für OpenCV (CPU).
Zunächst aus den Bildern, die sowohl von OpenCV als auch von diesem CNN erkannt werden konnten. Wie erwartet sieht die Position des Anime-Gesichts genau aus.

 © Yui Hara / Yoshibunsha / Kiniro Mosaic Production Committee
© Yui Hara / Yoshibunsha / Kiniro Mosaic Production Committee
Als nächstes kommt das Bild mit einem Profil, das ich für diese Zeit angestrebt habe. Die Position des Rahmens ist empfindlich, aber ich kann das Profil erkennen, das nicht von OpenCV aufgenommen wurde. Es gibt jedoch einen seltsamen Rahmen zwischen Alice und Shinobu. ..

 © Yui Hara / Yoshibunsha / Kiniro Mosaic Production Committee
© Yui Hara / Yoshibunsha / Kiniro Mosaic Production Committee
Schließlich,

 © Koi / Yoshibunsha / Ist Ihre Bestellung ein Produktionskomitee?
© Koi / Yoshibunsha / Ist Ihre Bestellung ein Produktionskomitee?
Ah, der Behälter, der Behälter wird erkannt. .. Natürlich hat OpenCV es genauer erkannt. traurig
Zusammenfassung
Als Gefühl habe ich das Gefühl, dass die Anzahl der Fälle, die erfasst werden können, viel höher ist als die der OpenCV-Version, aber gleichzeitig hatte ich den Eindruck, dass die Rate der Fehlerkennung anderer Teile als des Gesichts als Gesicht ebenfalls gestiegen ist. Darauf bezogen ...
Was hat funktioniert
- Verbreitung von Trainingsdaten ――Wenn ich dem Bild eine Drehung hinzufügte und die Daten weitergab, erhöhte sich die Konvergenzgeschwindigkeit dramatisch. Immerhin wurde mir klar, dass die Datenmenge wichtig ist.
- Anpassung der Mini-Chargengröße ――Wenn ich die Parameter durch gleichzeitiges Zuführen von 100 Blättern aktualisierte, konvergierte der Trainingsfehler, aber der Validierungsfehler ließ bald nach. Als ich es jedoch auf 10 reduzierte, erhöhte sich die Genauigkeit der Validierung um etwa 2pt, was den Eindruck erweckt, dass es so wie es war effektiv war.
Verbesserungspunkte, Reflexion usw.
-
Detektor --Detection ist ein einfaches Schiebefenster, daher nimmt es viel Zeit in Anspruch. Um dies zu vermeiden, begrenzen wir die Größe des zugeschnittenen Bildes. In diesem Fall kann jedoch das Gesicht, das den Bildschirm ausfüllt, nicht erkannt werden. .. ――Diesmal ist es die Gesichtserkennung, daher denke ich nicht, dass es ein großes Problem ist, aber das Seitenverhältnis ist auf 1: 1 festgelegt. ――Ich bin der Meinung, dass ich von Anfang an standortbezogene Daten hätte verwenden sollen.
-
Trainingsdaten ―― Immerhin habe ich das Gefühl, dass der absolute Betrag noch gering war.
- Falsche Antwortdaten (Qualität) waren möglicherweise nicht ausreichend. Ich habe zufällig ein Bild ohne Gesicht abgeschnitten, aber es gab viele Bilder, in denen das Objekt selbst kaum reflektiert wurde und die Grenze des Objekts nicht erfasst wurde. Daher denke ich, dass es als Daten immer noch schwach war. .. Die hohe Falsch-Positiv-Rate ist wahrscheinlich auf ihren Einfluss zurückzuführen.
Nächster··
Ich frage mich, ob ich mit den Daten mit dem Positionsetikett einen Detektor herstellen möchte. Selbst wenn die Genauigkeit herauskommt, kommt die Geschwindigkeit bei der aktuellen Methode nicht heraus, daher möchte ich [SPP-net] ausprobieren (http://arxiv.org/abs/1406.4729).
Quellcode
Da sich die Version von Chainer geändert hat und nicht funktioniert, habe ich den korrigierten Code auf Github hochgeladen. https://github.com/homuler/pyon2-detector/
Recommended Posts