[PYTHON] Datenanalyse vor der Erzeugung der Titanic-Features von Kaggle
Einführung
Ich habe versucht, die Überlebenden der Titanic vorherzusagen, die ein Tutorial von Kaggle ist.
** Dieses Mal werden wir, anstatt ein Modell für maschinelles Lernen zu erstellen, um die Überlebenswahrscheinlichkeit vorherzusagen, die Beziehungen zwischen den Daten untersuchen und untersuchen, welche Art von Menschen überlebt haben **.
Und ich möchte die erhaltenen Ergebnisse verwenden, um fehlende Werte zu ergänzen und Merkmalsmengen zu generieren.
1. Datenübersicht
Importieren Sie die Bibliothek und lesen und überprüfen Sie die Zugdaten
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
data=pd.read_csv("/kaggle/input/titanic/train.csv")
data.head()
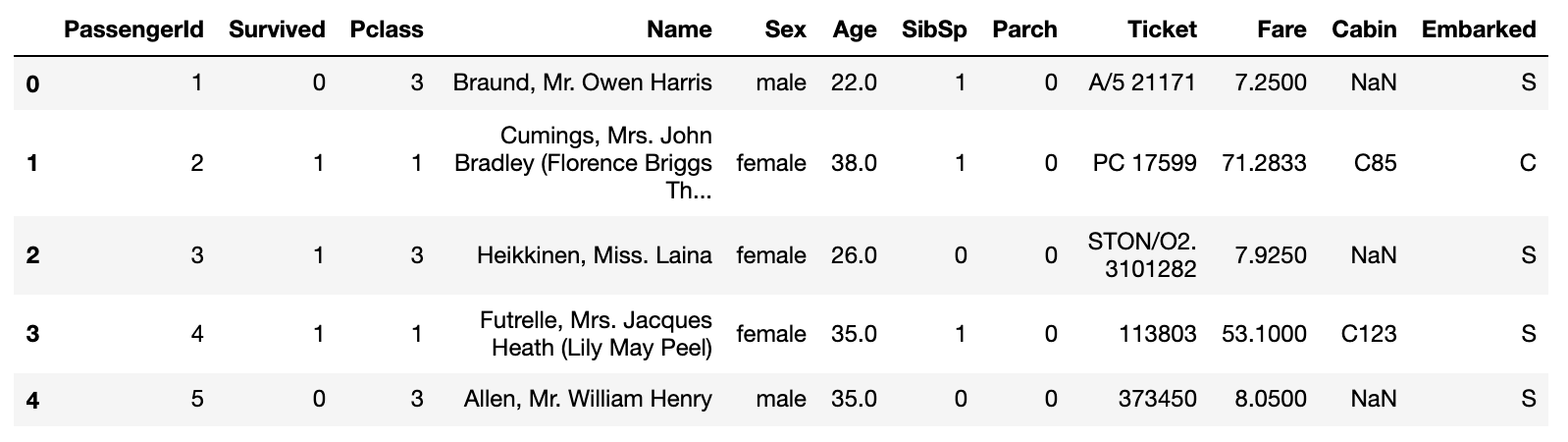 ** Arten von Funktionen **
・ PassengerId: Passagier-ID
・ Überlebt: Leben und Tod (0: Tod, 1: Überleben)
・ Klasse: Passagier soziale Klasse (1: Obere, 2: Mittlere, 3: Untere)
· Name Name
・ Geschlecht: Geschlecht
・ Alter: Alter
・ SibSp: Anzahl der Brüder und Ehepartner, die zusammen reiten
・ Parch: Anzahl der Eltern und Kinder, die zusammen fahren
・ Ticket: Ticketnummer
・ Tarif: Boarding-Gebühr
・ Kabine: Zimmernummer
・ Eingeschifft: Hafen an Bord
** Arten von Funktionen **
・ PassengerId: Passagier-ID
・ Überlebt: Leben und Tod (0: Tod, 1: Überleben)
・ Klasse: Passagier soziale Klasse (1: Obere, 2: Mittlere, 3: Untere)
· Name Name
・ Geschlecht: Geschlecht
・ Alter: Alter
・ SibSp: Anzahl der Brüder und Ehepartner, die zusammen reiten
・ Parch: Anzahl der Eltern und Kinder, die zusammen fahren
・ Ticket: Ticketnummer
・ Tarif: Boarding-Gebühr
・ Kabine: Zimmernummer
・ Eingeschifft: Hafen an Bord
Betrachten wir zunächst die fehlenden Werte der Daten, die zusammenfassende Statistik und den Korrelationskoeffizienten zwischen den einzelnen Merkmalen.
#Überprüfen Sie, ob Werte fehlen
data.isnull().sum()
| Anzahl der fehlenden Werte | |
|---|---|
| PassengerId | 0 |
| Survived | 0 |
| Pclass | 0 |
| Name | 0 |
| Sex | 0 |
| Age | 177 |
| SibSp | 0 |
| Parch | 0 |
| Ticket | 0 |
| Fare | 0 |
| Cabin | 687 |
| Embarked | 2 |
#Überprüfen Sie die zusammenfassenden Statistiken
#Sie können den Maximalwert, den Minimalwert, den Durchschnittswert und die Anzahl der Brüche überprüfen.
#Berechnet durch Ausschließen fehlender Werte
data.describe()
| PassengerId | Survived | Pclass | Age | SibSp | Parch | Fare | |
|---|---|---|---|---|---|---|---|
| count | 891.000000 | 891.000000 | 891.000000 | 714.000000 | 891.000000 | 891.000000 | 891.000000 |
| mean | 446.000000 | 0.383838 | 2.308642 | 29.699118 | 0.523008 | 0.381594 | 32.204208 |
| std | 257.353842 | 0.486592 | 0.836071 | 14.526497 | 1.102743 | 0.806057 | 49.693429 |
| min | 1.000000 | 0.000000 | 1.000000 | 0.420000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 223.500000 | 0.000000 | 2.000000 | 20.125000 | 0.000000 | 0.000000 | 7.910400 |
| 50% | 446.000000 | 0.000000 | 3.000000 | 28.000000 | 0.000000 | 0.000000 | 14.454200 |
| 75% | 668.500000 | 1.000000 | 3.000000 | 38.000000 | 1.000000 | 0.000000 | 31.000000 |
| max | 891.000000 | 1.000000 | 3.000000 | 80.000000 | 8.000000 | 6.000000 | 512.329200 |
#Überprüfen Sie den Korrelationskoeffizienten jedes Merkmals
data.corr()
| PassengerId | Survived | Pclass | Age | SibSp | Parch | Fare | |
|---|---|---|---|---|---|---|---|
| PassengerId | 1.000000 | -0.005007 | -0.035144 | 0.036847 | -0.057527 | -0.001652 | 0.012658 |
| Survived | -0.005007 | 1.000000 | -0.338481 | -0.077221 | -0.035322 | 0.081629 | 0.257307 |
| Pclass | -0.035144 | -0.338481 | 1.000000 | -0.369226 | 0.083081 | 0.018443 | -0.549500 |
| Age | 0.036847 | -0.077221 | -0.369226 | 1.000000 | -0.308247 | -0.189119 | 0.096067 |
| SibSp | -0.057527 | -0.035322 | 0.083081 | -0.308247 | 1.000000 | 0.414838 | 0.159651 |
| Parch | -0.001652 | 0.081629 | 0.018443 | -0.189119 | 0.414838 | 1.000000 | 0.216225 |
| Fare | 0.012658 | 0.257307 | -0.549500 | 0.096067 | 0.159651 | 0.216225 | 1.000000 |
Ich würde gerne die Merkmale von Survived anhand des Korrelationskoeffizienten sehen, aber es ist ein wenig schwierig zu verstehen, ob es sich um eine Tabelle mit nur Zahlen handelt ... Daher werde ich die überlagerten Werte in dieser Tabelle entfernen und die absoluten Werte in der Heatmap anzeigen.
#Machen Sie den Wert zu einem absoluten Wert
corr_matrix = data.corr().abs()
#Erstellen Sie eine untere Dreiecksmatrix, korr_Auf die Matrix anwenden
map_data = corr_matrix.where(np.tril(np.ones(corr_matrix.shape), k=-1).astype(np.bool))
#Bestimmen Sie die Größe des Bildes und konvertieren Sie es in eine Heatmap
plt.figure(figsize=(10,10))
sns.heatmap(map_data, annot=True, cmap='Greens')
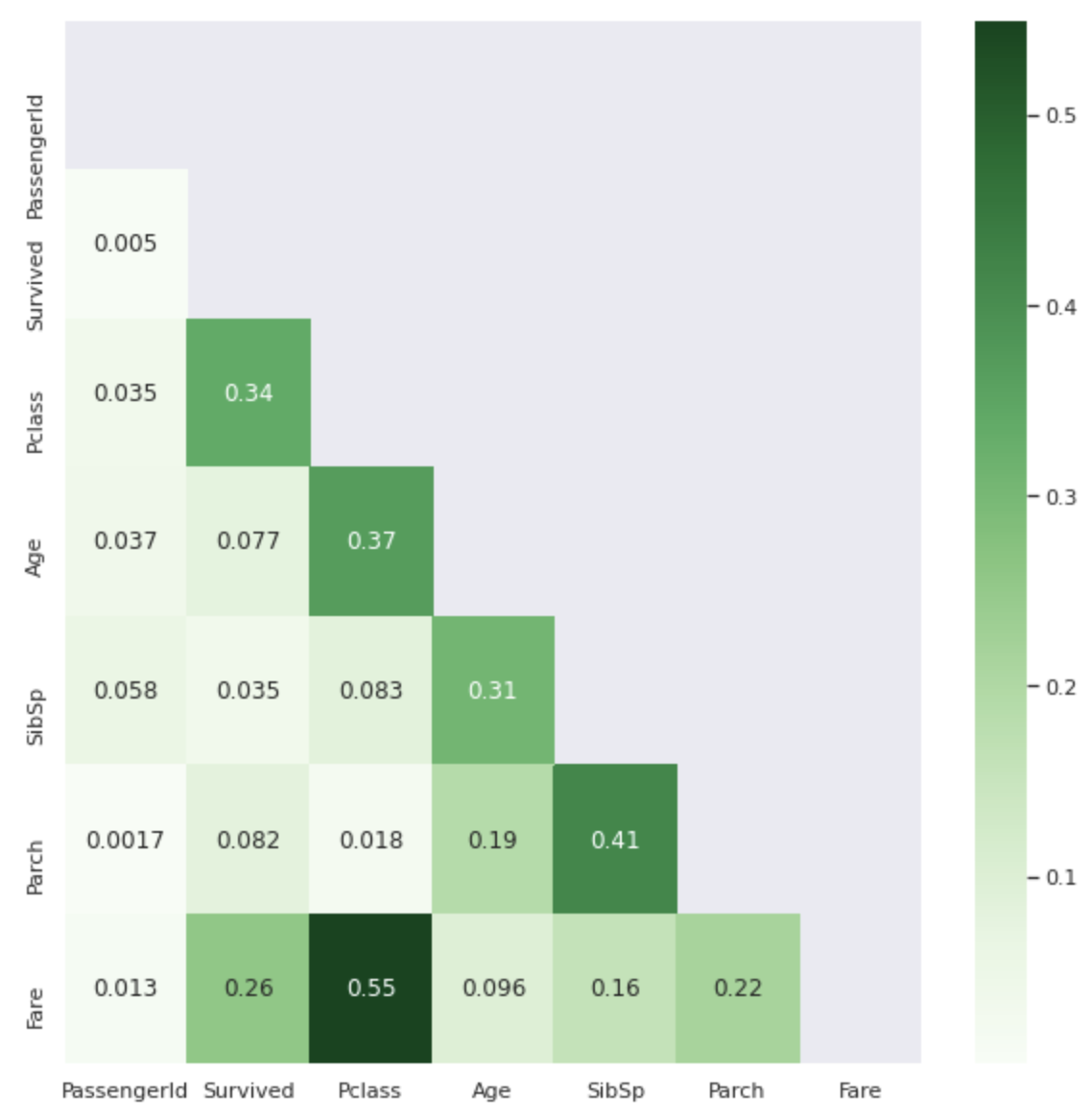 Je dunkler die Farbe, desto näher liegt der Korrelationskoeffizientenwert an 1.
Ist es nicht einfacher zu sehen als die Tabelle .corr ()?
Je dunkler die Farbe, desto näher liegt der Korrelationskoeffizientenwert an 1.
Ist es nicht einfacher zu sehen als die Tabelle .corr ()?
Ich weiß nichts über nicht numerische Funktionen (Name, Geschlecht, Ticket, Kabine, Einschiffung), aber aus der obigen Tabelle können Sie ersehen, dass ** Klasse und Tarif ** die Hauptakteure in Survived sind. ..
- Pclass Lassen Sie uns zunächst die Beziehung zwischen Pclass und Survived überprüfen.
sns.barplot(x='Pclass',y='Survived',hue='Sex', data=data)
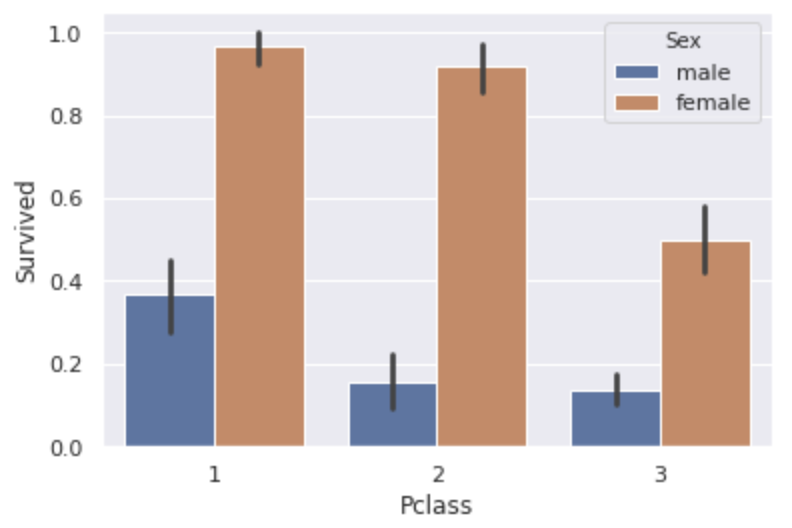 ** Je höher die Klasse, desto höher die Überlebensrate **.
Bedeutet das, dass je höher der Rang, desto bevorzugter geholfen wird?
Sie können auch sehen, dass ** Frauen in jeder Klasse mehr als die doppelte Überlebensrate von Männern ** haben.
Die Gesamtüberlebensrate der Männer betrug übrigens 18,9% und die der Frauen 74,2%.
** Je höher die Klasse, desto höher die Überlebensrate **.
Bedeutet das, dass je höher der Rang, desto bevorzugter geholfen wird?
Sie können auch sehen, dass ** Frauen in jeder Klasse mehr als die doppelte Überlebensrate von Männern ** haben.
Die Gesamtüberlebensrate der Männer betrug übrigens 18,9% und die der Frauen 74,2%.
- Fare Da der Minimalwert 0 und der Maximalwert 512 ist, untersuchen wir die Gesamtverteilung.
plt.figure(figsize=(20,8))
sns.distplot(data['Fare'], bins=50, kde=False)
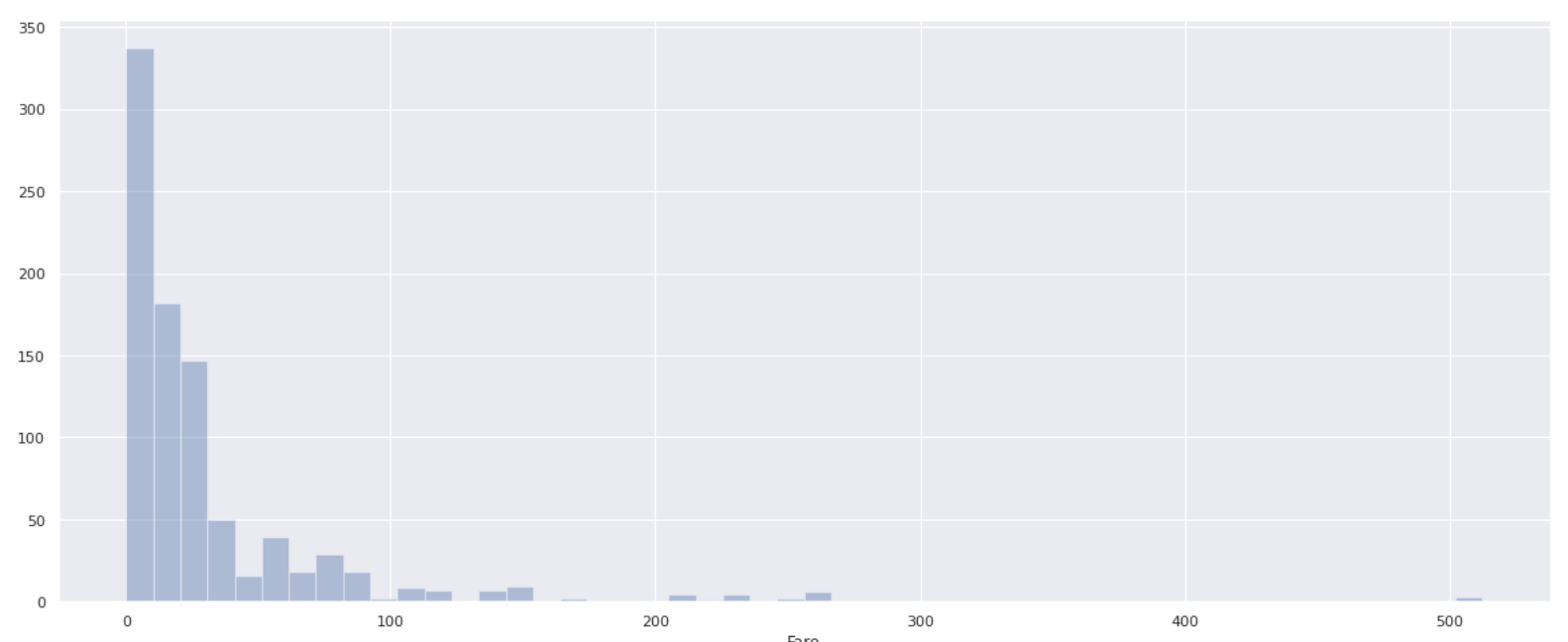
** Nur wenige Personen haben eine Boarding-Gebühr von über 100 und die meisten Passagiere haben eine Boarding-Gebühr von 0-100 **. Um zu untersuchen, wie sich die Überlebensrate in Abhängigkeit von der Boarding-Gebühr ändert, teilen Sie den Tarifwert durch 10 (0 bis 10, 10 bis 20, 20 bis 30 ...) und berechnen Sie jeweils die Überlebensrate.
#Aufgeteilt in 10'Fare_bin'Spalte zu Daten hinzufügen
data['Fare_bin'] = pd.cut(data['Fare'],[i for i in range(0,521,10)], right=False)
bin_list = []
survived_list = []
for i in range(0,511,10):
#Finden Sie die Überlebensrate in jedem Abschnitt
survived=data[data['Fare_bin'].isin([i])]['Survived'].mean()
#Schließen Sie den Abschnitt NaN aus und fügen Sie der Liste nur den Abschnitt hinzu, für den die Überlebensrate erforderlich ist
if survived >= 0:
bin_list.append(f'{i}~{i+10}')
survived_list.append(survived)
#Erstellen Sie einen Datenrahmen aus zwei Listen und verwandeln Sie ihn in ein Diagramm
plt.figure(figsize=(20,8))
fare_bin_df = pd.DataFrame({'Fare_bin':bin_list, 'Survived':survived_list})
sns.barplot(x='Fare_bin', y='Survived', data=fare_bin_df, color='skyblue')
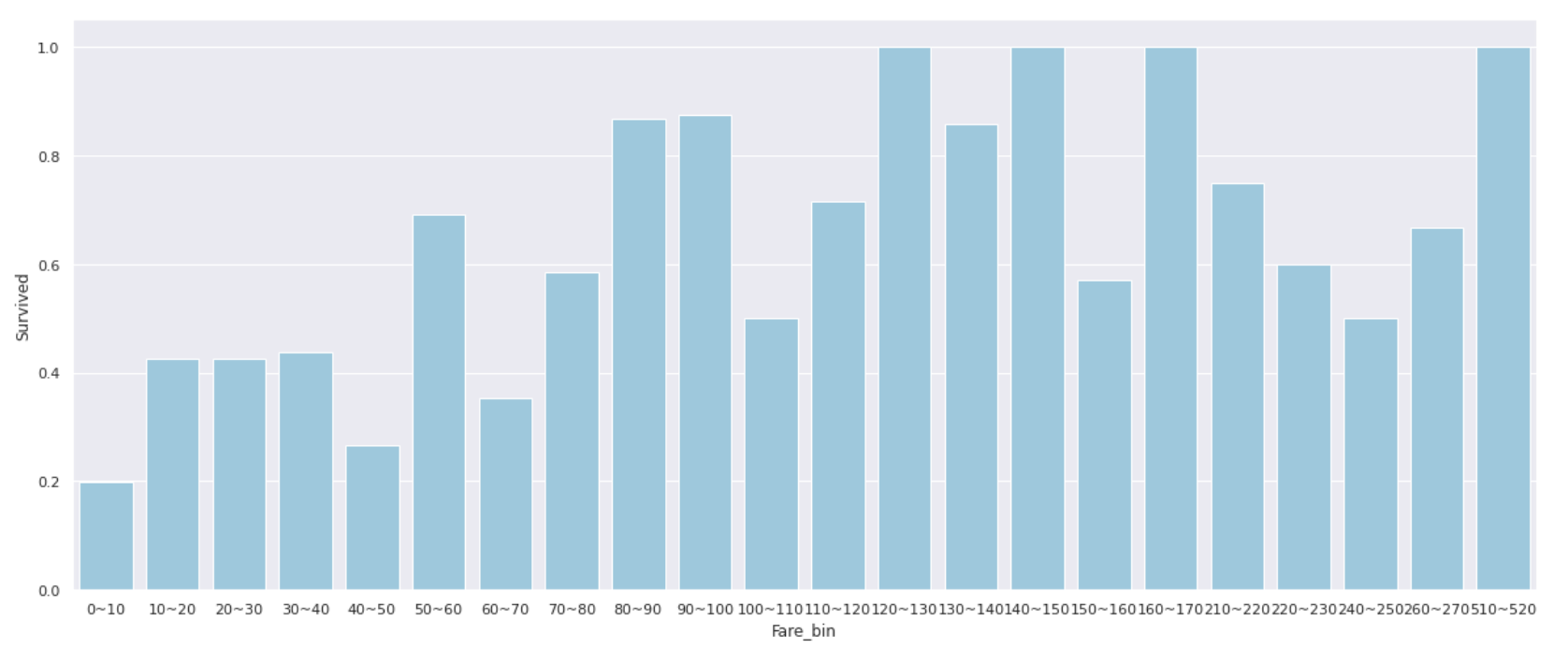
Menschen mit einem Tarif von 0 bis 10 haben eine extrem niedrige Überlebensrate von 20% oder weniger **, und wenn der Tarif 50 überschreitet, übersteigt die Überlebensrate häufig 50% **.
Anstatt den Wert so zu verwenden, wie er ist, kann es sinnvoll sein, __clified als Feature-Menge wie "Niedrig" für 0 bis 10 Personen und "Mittel" für 10 bis 50 Personen zu verwenden. ..
Außerdem betrug der Korrelationskoeffizient zwischen Pclass und Fare 0,55. Als ich mir die Beziehung zwischen den beiden ansah, wurde sie wie in der folgenden Grafik dargestellt.
(* P-Klasse für Personen mit einem Fahrpreis von 100 oder mehr wurde 1 so weggelassen)
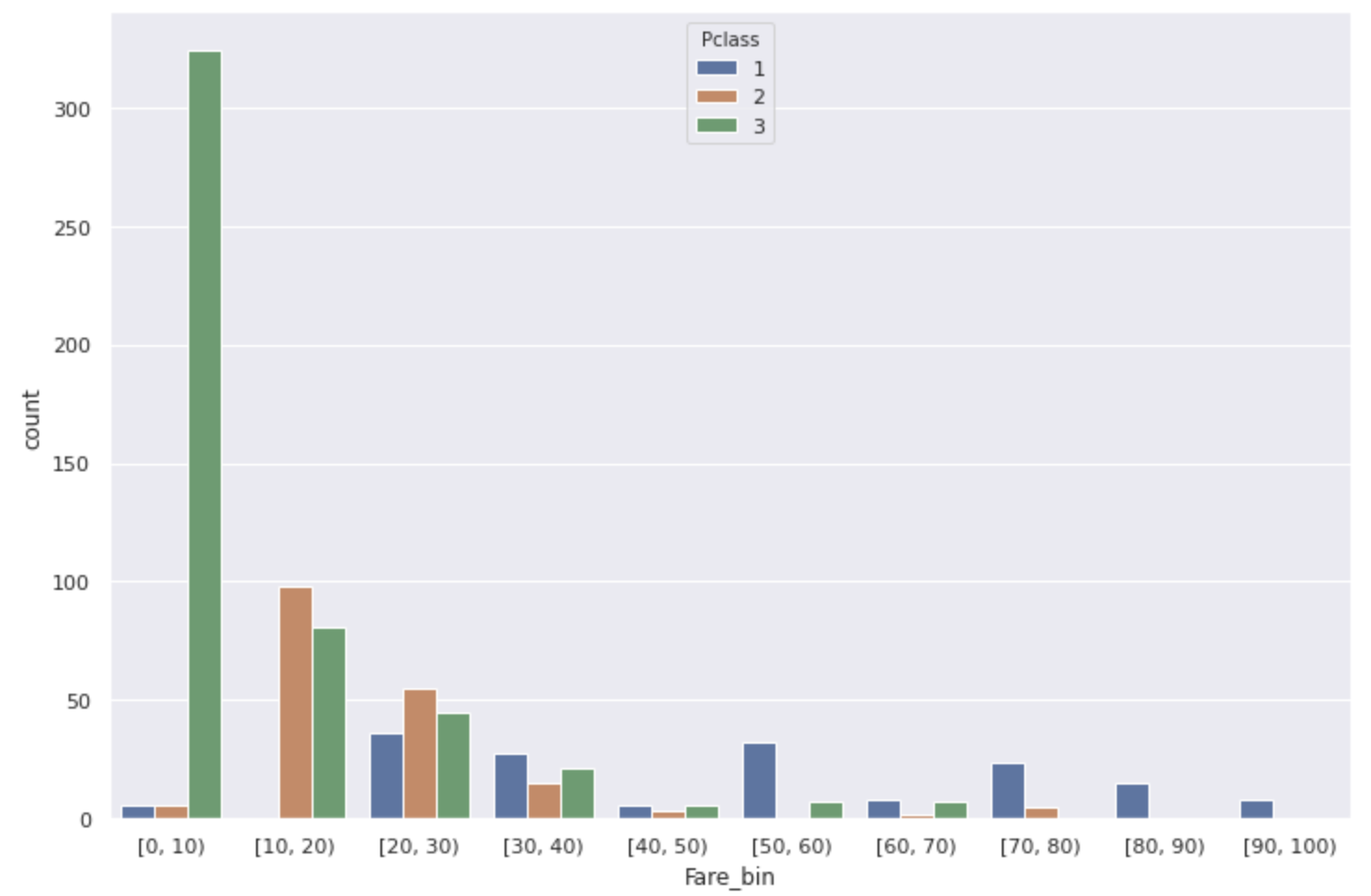 Die meisten Tarife [0,10], die eine niedrige Überlebensrate aufweisen, sind niedrigrangige Personen.
Die meisten Tarife [0,10], die eine niedrige Überlebensrate aufweisen, sind niedrigrangige Personen.
Betrachtet man die Daten, bei denen die Überlebensrate in den Diagrammen Survived und Fare_bin 1,0 beträgt, so sind ** die Nachnamen üblich ** oder ** die Ticketnummern gleich **.
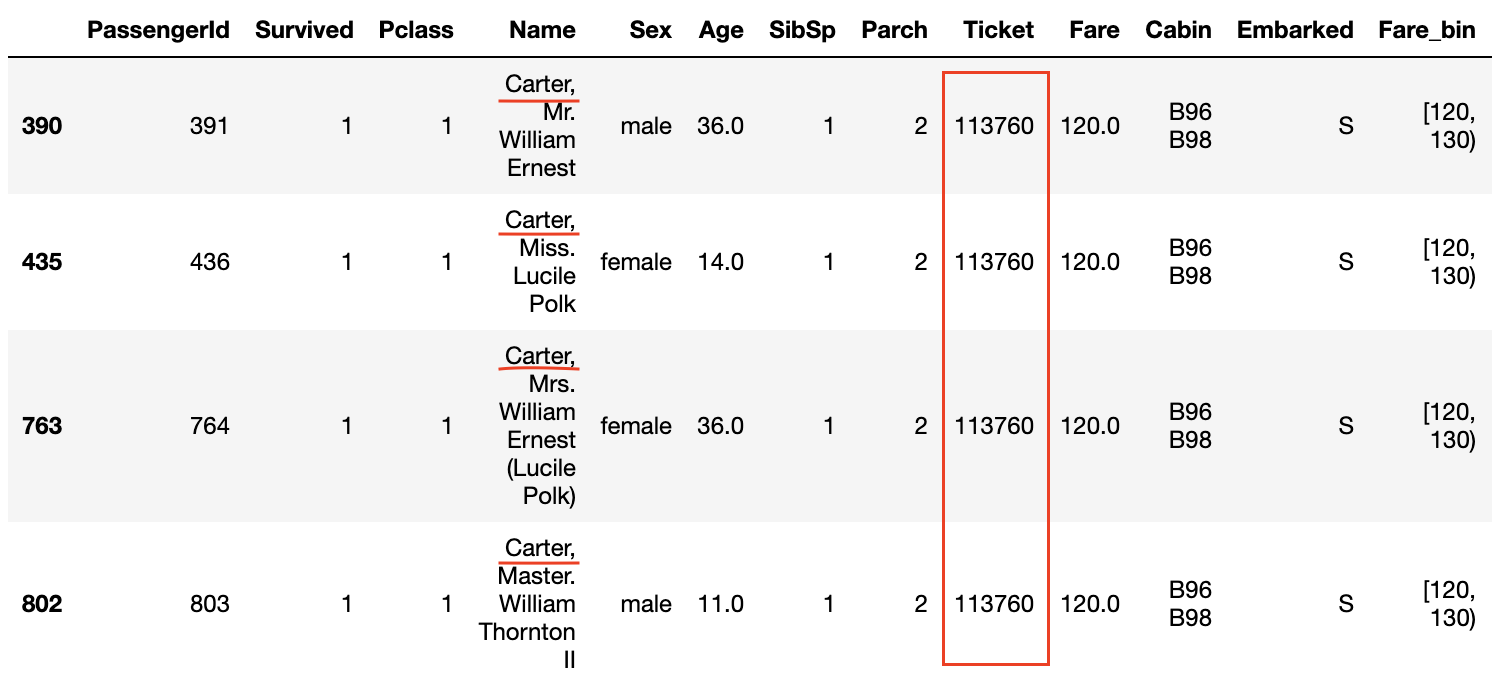
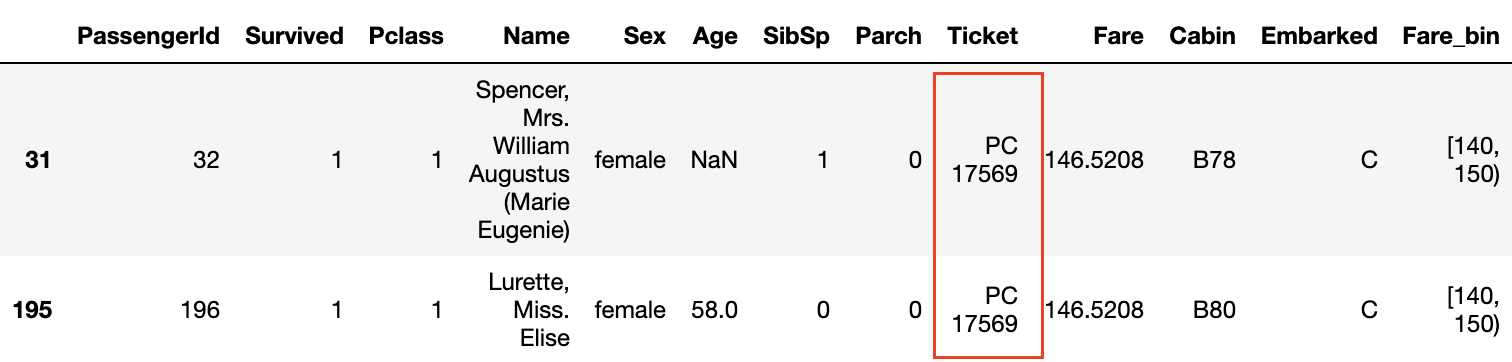
 Auch wenn die Pclass 3 ist und der Tarif nicht hoch ist, scheint die Überlebensrate hoch zu sein, wenn die Ticketnummern gleich sind **.
Auch wenn die Pclass 3 ist und der Tarif nicht hoch ist, scheint die Überlebensrate hoch zu sein, wenn die Ticketnummern gleich sind **.
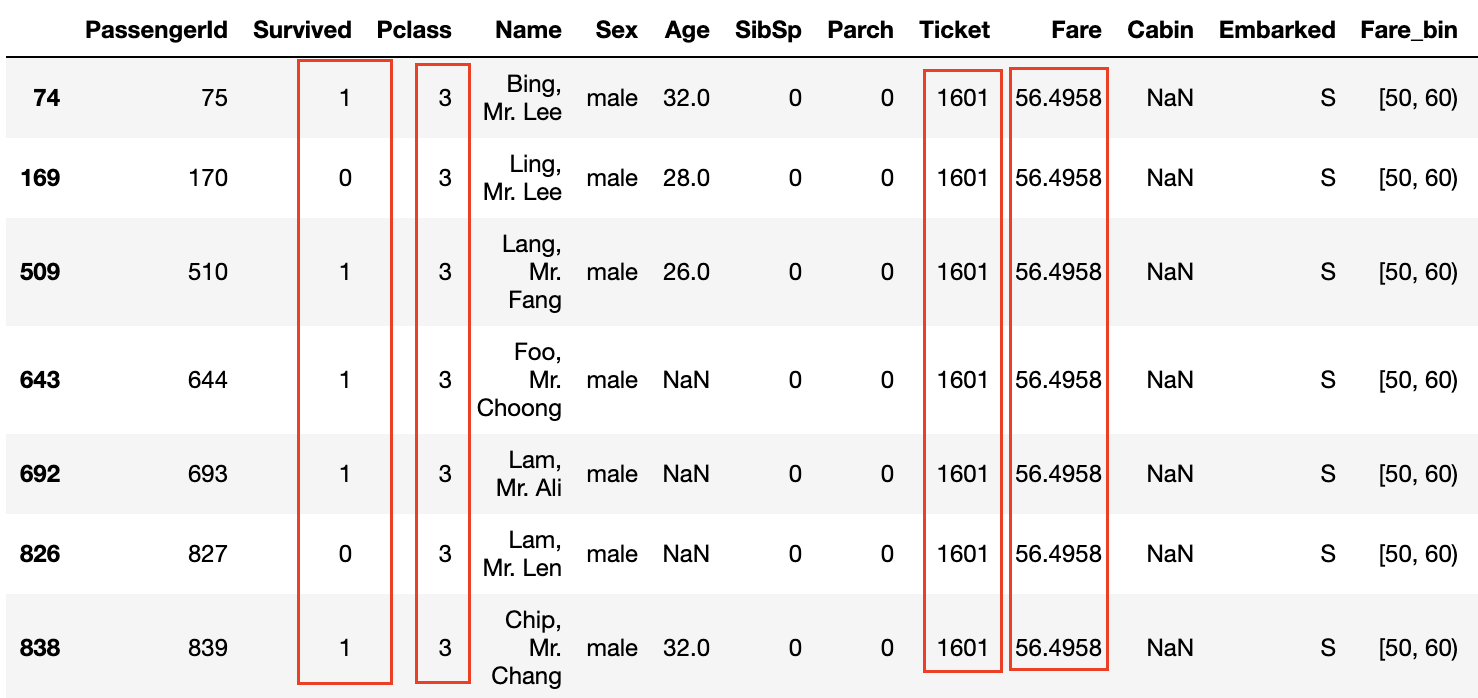 Die gleiche Ticketnummer bedeutet, dass ** die Familie und Freunde das Ticket zusammen gekauft haben ** und gemeinsam an Bord agieren und sich gegenseitig helfen konnten, wenn sie aus dem Schiff flüchteten. Es scheint so als.
Die gleiche Ticketnummer bedeutet, dass ** die Familie und Freunde das Ticket zusammen gekauft haben ** und gemeinsam an Bord agieren und sich gegenseitig helfen konnten, wenn sie aus dem Schiff flüchteten. Es scheint so als.
Lassen Sie uns herausfinden, ob es einen Unterschied in der Überlebensrate gibt, abhängig von der Anzahl der Familienmitglieder und der Ticketnummer.
4. SibSP und Parch
Erstellen Sie anhand der SibSp- und Parch-Werte, die auf den Titanic-Daten basieren, eine charakteristische Größe "Family_size", die angibt, wie viele Familien an Bord der Titanic waren.
#Family_Erstellen Sie eine Feature-Größe
data['Family_size'] = data['SibSp']+data['Parch']+1
fig,ax = plt.subplots(1,2,figsize=(20,8))
plt.figure(figsize=(12,8))
#Stellen Sie die Anzahl der Überlebenden und Todesfälle grafisch dar
sns.countplot(data['Family_size'],hue=data['Survived'], ax=ax[0])
#Family_Finden Sie die Überlebensrate für jede Größe
sns.barplot(x='Family_size', y='Survived',data=data, color='orange', ax=ax[1])
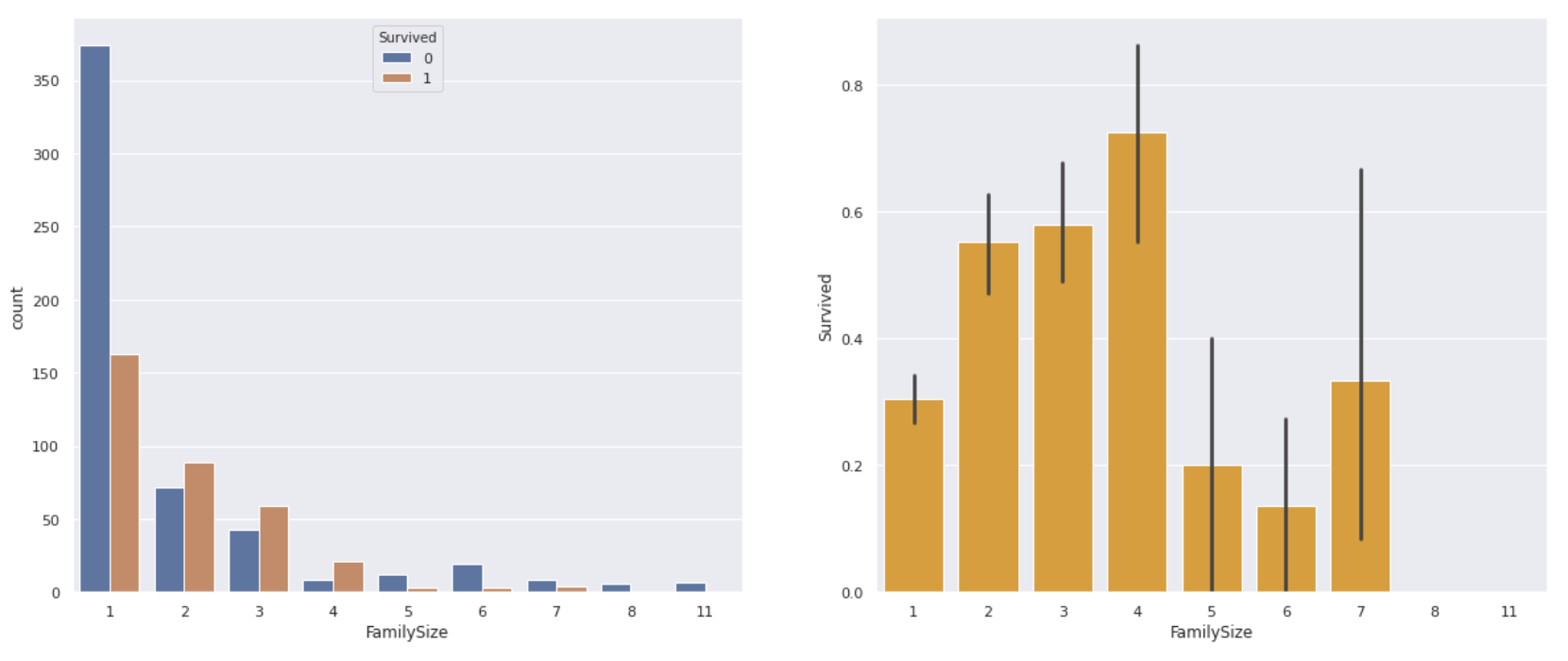
** Der Ein-Personen-Fahrer hatte eine niedrigere Überlebensrate als der Ein-Personen-Fahrer, und die Vier-Personen-Familie hatte die höchste Überlebensrate. ** Im Gegenteil, wenn die Anzahl der Familienmitglieder zu groß ist, scheint es schwierig zu sein, zusammen zu handeln oder zu überleben.
Wie bei Fare scheint es, dass es als Feature-Betrag verwendet werden kann, indem es entsprechend der Anzahl der Familienmitglieder in etwa 4 klassifiziert wird.
- Ticket Tragen Sie die Anzahl der doppelten Ticketnummern in die Spalte "Ticket_count" ein Damit scheint es, dass wir nicht nur die Überlebensrate nicht nur der Familie sehen können, sondern auch die Überlebensrate von ** (wahrscheinlich) Freunden, die an Bord des Schiffes gegangen sind **.
#Ticket_Erstellen Sie eine Spalte für die Zählung
data['Ticket_count'] = data.groupby('Ticket')['PassengerId'].transform('count')
#Finden Sie die Überlebensrate
plt.figure(figsize=(12,8))
sns.barplot(x='Ticket_count', y='Survived',data=data, color='skyblue')
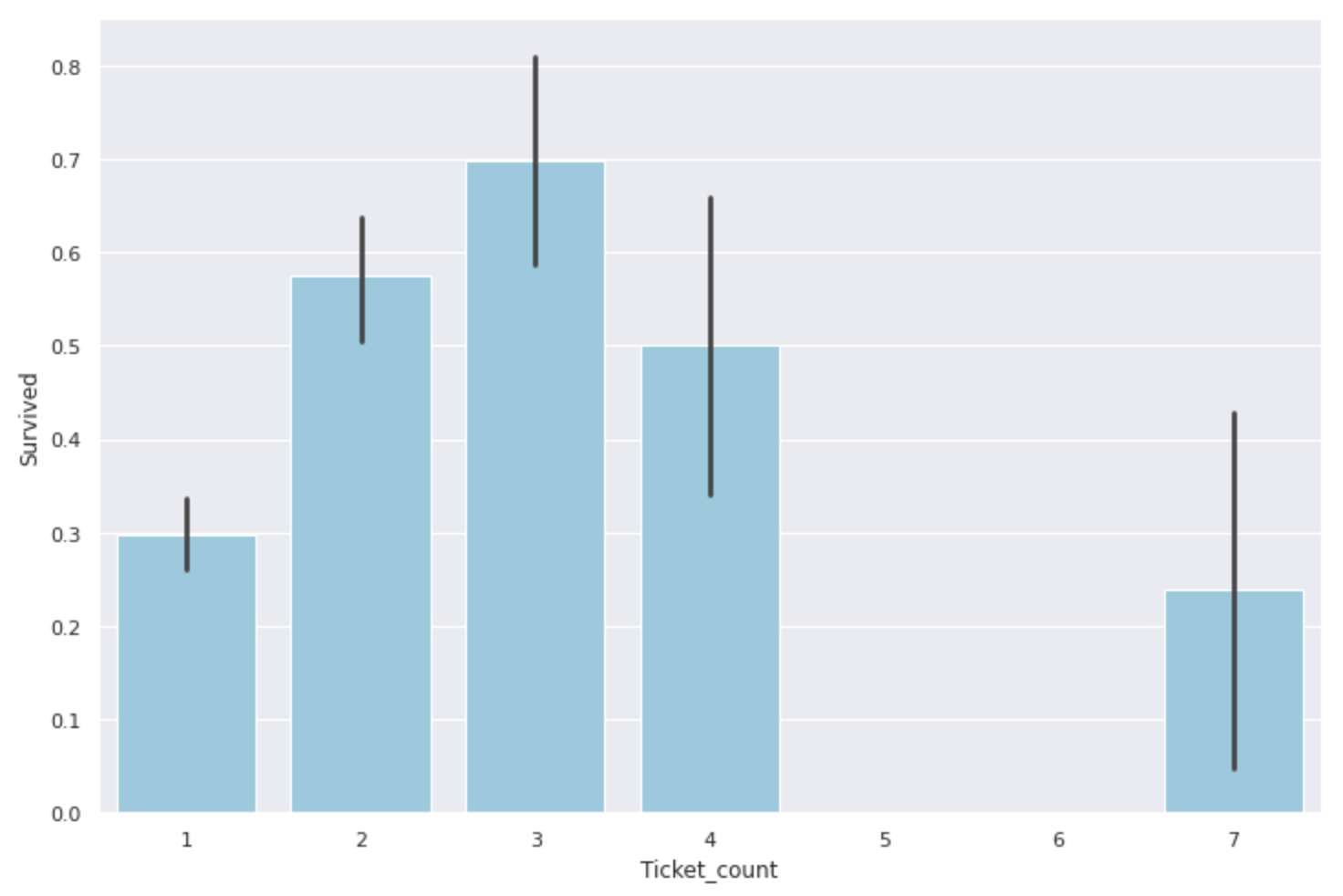
Wie bei der Anzahl der Familienmitglieder sind ** 2-4 Personen am hilfreichsten, und diejenigen, die alleine oder 5 oder mehr kommen, scheinen eine niedrige Überlebensrate zu haben **. Ähnlich wie bei Fare und Family_size kann dies auch als Feature-Menge klassifiziert werden.
Lassen Sie uns nun tiefer in die Informationen eintauchen, die Sie von Ihren Tickets erhalten. Ich habe auf diese Seite verwiesen, um eine detaillierte Klassifizierung der Tickets zu erhalten. Pyhayas Tagebuch: Analyse der Titanic-Daten von Kaggle
Es gibt Ticketnummern mit nur Nummern und solche mit Nummern und Alphabeten, daher werden wir sie klassifizieren.
#Holen Sie sich ein Ticket nur für Nummern
num_ticket = data[data['Ticket'].str.match('[0-9]+')].copy()
num_ticket_index = num_ticket.index.values.tolist()
#Tickets, bei denen nur Nummern aus den Originaldaten entfernt wurden und der Rest Alphabete enthält
num_alpha_ticket = data.drop(num_ticket_index).copy()
Lassen Sie uns zunächst sehen, wie die Ticketnummern mit nur Nummern verteilt werden.
#Da die Ticketnummer als Zeichenfolge eingegeben wird, wird sie in einen numerischen Wert konvertiert
num_ticket['Ticket'] = num_ticket['Ticket'].apply(lambda x:int(x))
plt.figure(figsize=(12,8))
sns.jointplot(x='PassengerId', y='Ticket', data=num_ticket)
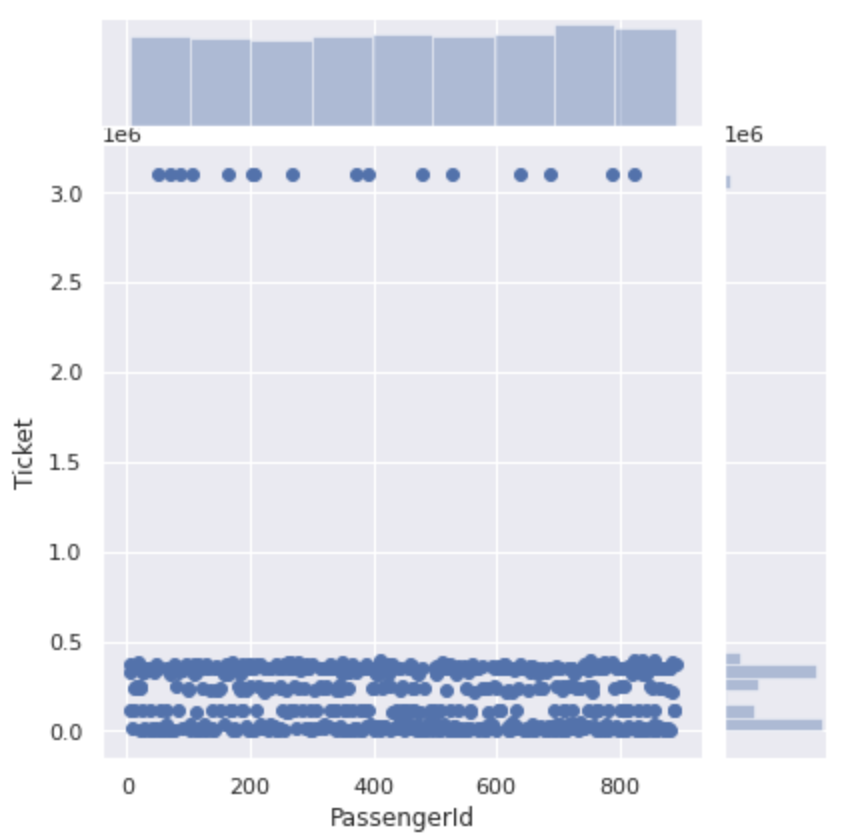 Es ist grob in Zahlen von 500.000 oder weniger und Zahlen von 3000000 oder mehr unterteilt.
Wenn Sie sich den Abschnitt von 0 bis 500000 genauer ansehen, ist die Ticketnummer für diesen Abschnitt in vier Teile unterteilt.
Es ist grob in Zahlen von 500.000 oder weniger und Zahlen von 3000000 oder mehr unterteilt.
Wenn Sie sich den Abschnitt von 0 bis 500000 genauer ansehen, ist die Ticketnummer für diesen Abschnitt in vier Teile unterteilt.
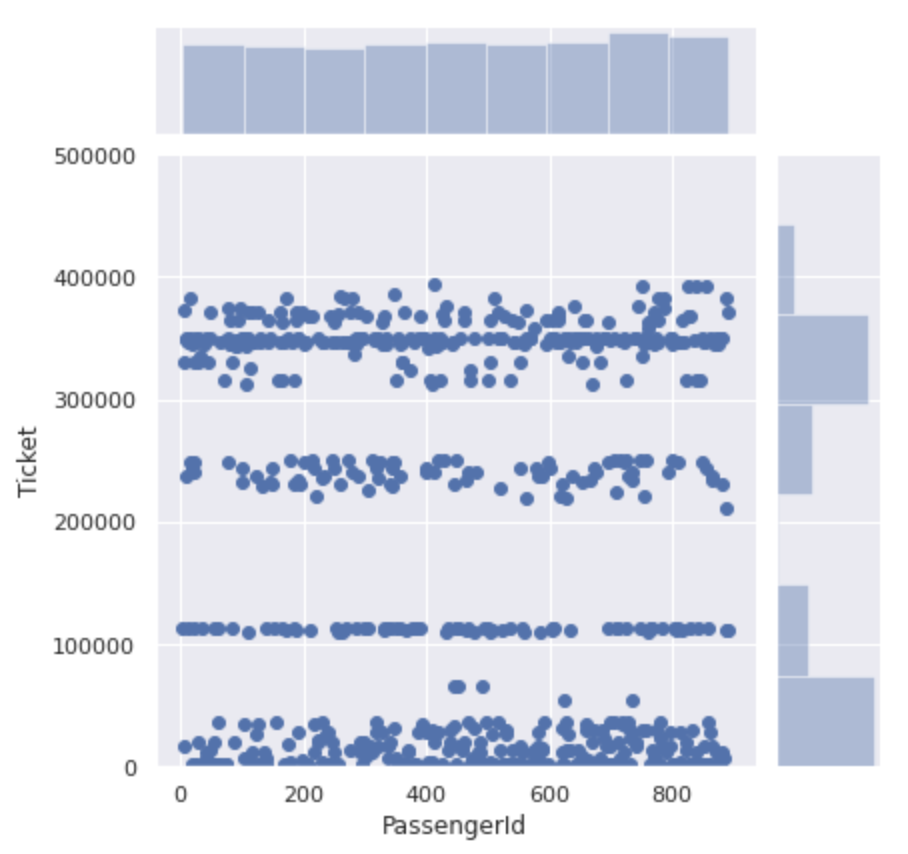 Es scheint, dass die Ticketnummern nicht nur Seriennummern sind, sondern ** für jede Nummer gibt es eine Gruppe **.
Lassen Sie uns dies als Gruppe klassifizieren und den Unterschied in der Überlebensrate von jeder sehen.
Es scheint, dass die Ticketnummern nicht nur Seriennummern sind, sondern ** für jede Nummer gibt es eine Gruppe **.
Lassen Sie uns dies als Gruppe klassifizieren und den Unterschied in der Überlebensrate von jeder sehen.
#0~Tickets mit 99999 Nummern sind in Klasse 0
num_ticket['Ticket_bin'] = 0
num_ticket.loc[(num_ticket['Ticket']>=100000) & (num_ticket['Ticket']<200000),'Ticket_bin'] = 1
num_ticket.loc[(num_ticket['Ticket']>=200000) & (num_ticket['Ticket']<300000),'Ticket_bin'] = 2
num_ticket.loc[(num_ticket['Ticket']>=300000) & (num_ticket['Ticket']<400000),'Ticket_bin'] = 3
num_ticket.loc[(num_ticket['Ticket']>=3000000),'Ticket_bin'] = 4
plt.figure(figsize=(12,8))
sns.barplot(x='Ticket_bin', y='Survived', data=num_ticket)
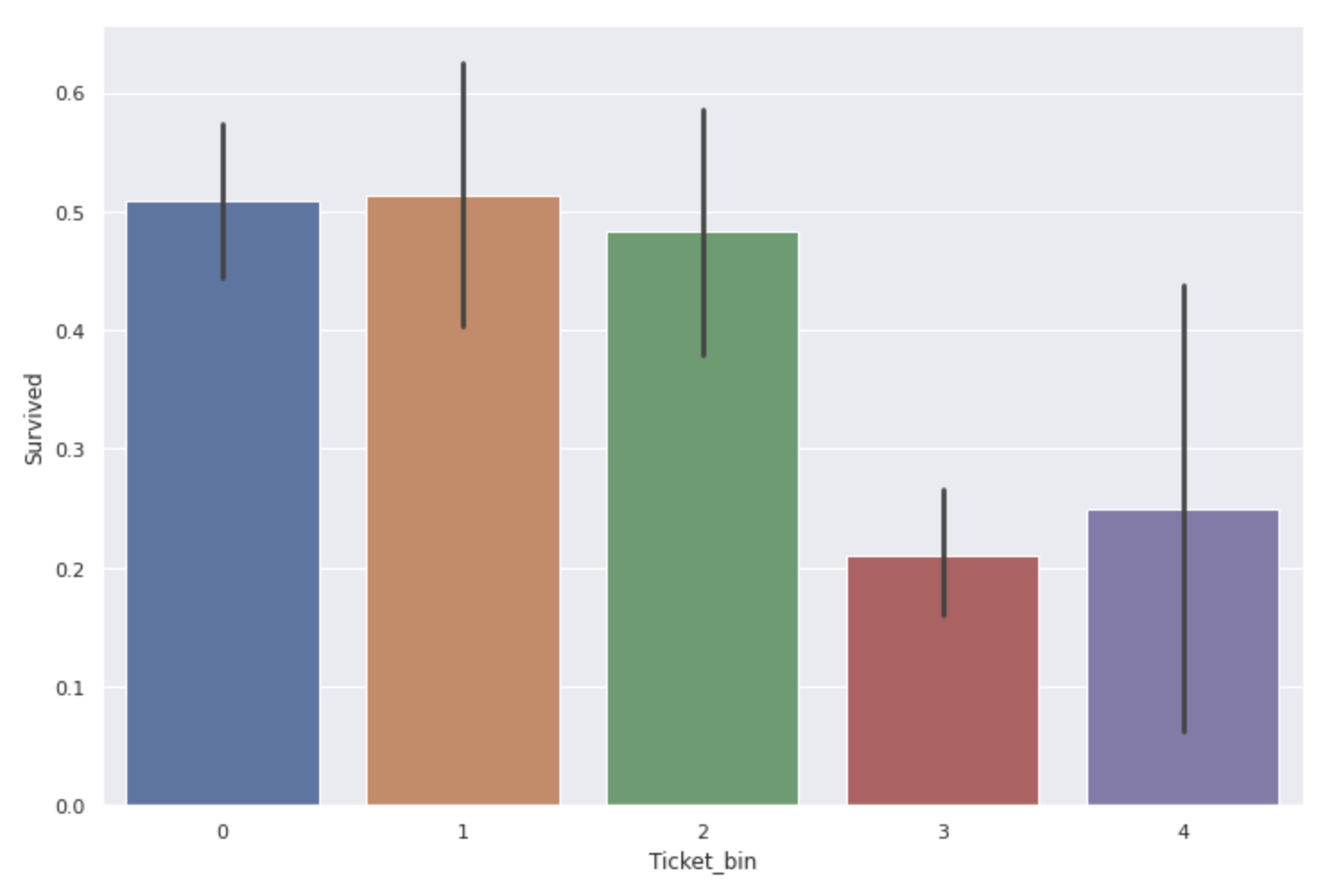 ** Die Überlebensrate von Personen mit Ticketnummern von 300000 ~ 400000 und 3000000 oder mehr ist erheblich niedrig **.
** Die Überlebensrate von Personen mit Ticketnummern von 300000 ~ 400000 und 3000000 oder mehr ist erheblich niedrig **.
Als nächstes werden wir uns auf die gleiche Weise mit Zahlen und Alphabet-Tickets befassen. Lassen Sie uns zunächst überprüfen, welche Art es gibt.
#Zum einfachen Anzeigen nach Typ sortieren
sorted(num_alpha_ticket['Ticket'].value_counts().items())
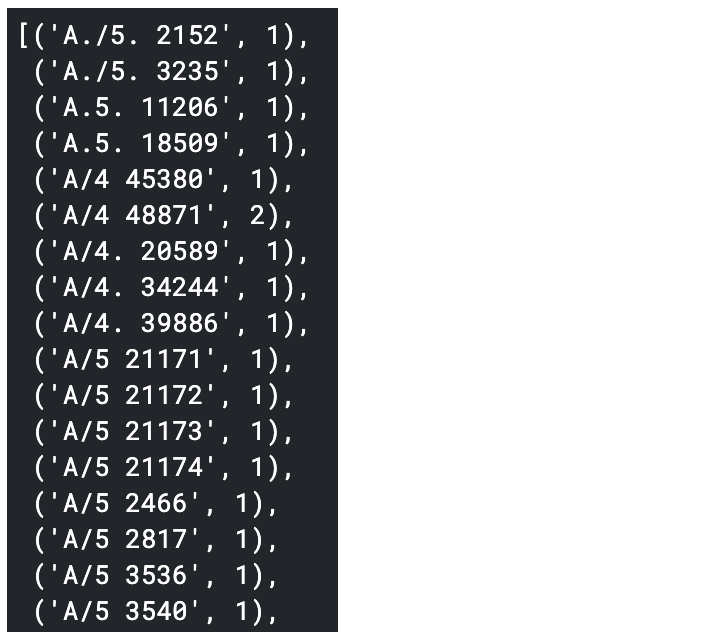 Da es viele Typen gibt, werden die Klassen 1 bis 10 denen mit einer bestimmten Nummer zugewiesen, und Klassen mit einer kleinen Nummer werden gemeinsam auf 0 gesetzt.
(Die Farbcodierung des Codes hat sich aufgrund des Einflusses von '' geändert ...)
Da es viele Typen gibt, werden die Klassen 1 bis 10 denen mit einer bestimmten Nummer zugewiesen, und Klassen mit einer kleinen Nummer werden gemeinsam auf 0 gesetzt.
(Die Farbcodierung des Codes hat sich aufgrund des Einflusses von '' geändert ...)
num_alpha_ticket['Ticket_bin'] = 0
num_alpha_ticket.loc[num_alpha_ticket['Ticket'].str.match('A.+'),'Ticket_bin'] = 1
num_alpha_ticket.loc[num_alpha_ticket['Ticket'].str.match('C.+'),'Ticket_bin'] = 2
num_alpha_ticket.loc[num_alpha_ticket['Ticket'].str.match('C\.*A\.*.+'),'Ticket_bin'] = 3
num_alpha_ticket.loc[num_alpha_ticket['Ticket'].str.match('F\.C.+'),'Ticket_bin'] = 4
num_alpha_ticket.loc[num_alpha_ticket['Ticket'].str.match('PC.+'),'Ticket_bin'] = 5
num_alpha_ticket.loc[num_alpha_ticket['Ticket'].str.match('S\.+.+'),'Ticket_bin'] = 6
num_alpha_ticket.loc[num_alpha_ticket['Ticket'].str.match('SC.+'),'Ticket_bin'] = 7
num_alpha_ticket.loc[num_alpha_ticket['Ticket'].str.match('SOTON.+'),'Ticket_bin'] = 8
num_alpha_ticket.loc[num_alpha_ticket['Ticket'].str.match('STON.+'),'Ticket_bin'] = 9
num_alpha_ticket.loc[num_alpha_ticket['Ticket'].str.match('W\.*/C.+'),'Ticket_bin'] = 10
plt.figure(figsize=(12,8))
sns.barplot(x='Ticket_bin', y='Survived', data=num_alpha_ticket)
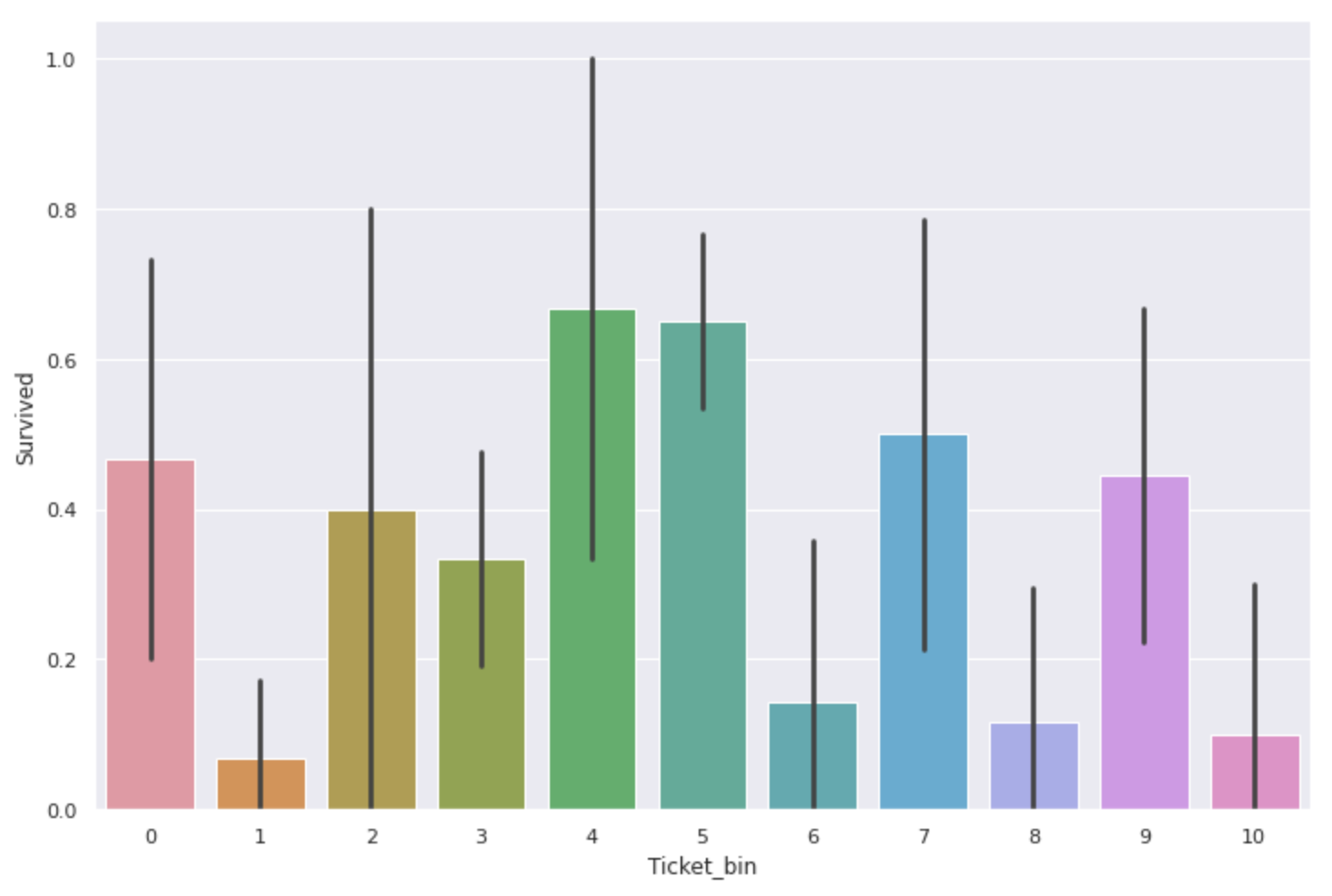 Auch hier gab es einen Unterschied in der Überlebensrate. ** Die mit 'F.C'und'PC' sind besonders teuer **.
Die Gesamtzahl der Ticketdaten einschließlich Alphabeten beträgt jedoch nur 230, und die Anzahl der Daten beträgt nur etwa ein Drittel derjenigen von Tickets mit nur Zahlen, sodass ** der Wert der Überlebensrate selbst möglicherweise nicht sehr glaubwürdig ist **. Vielleicht.
Auch hier gab es einen Unterschied in der Überlebensrate. ** Die mit 'F.C'und'PC' sind besonders teuer **.
Die Gesamtzahl der Ticketdaten einschließlich Alphabeten beträgt jedoch nur 230, und die Anzahl der Daten beträgt nur etwa ein Drittel derjenigen von Tickets mit nur Zahlen, sodass ** der Wert der Überlebensrate selbst möglicherweise nicht sehr glaubwürdig ist **. Vielleicht.
Es scheint, dass sich die Überlebensrate in Abhängigkeit von der Ticketnummer ** ändert, da die Nummern nach Ort und Rang des Zimmers ** aufgeteilt sind. Werfen wir einen Blick auf die Beziehungen zwischen Pclass und Fare, die wahrscheinlich mit Tickets zusammenhängen.
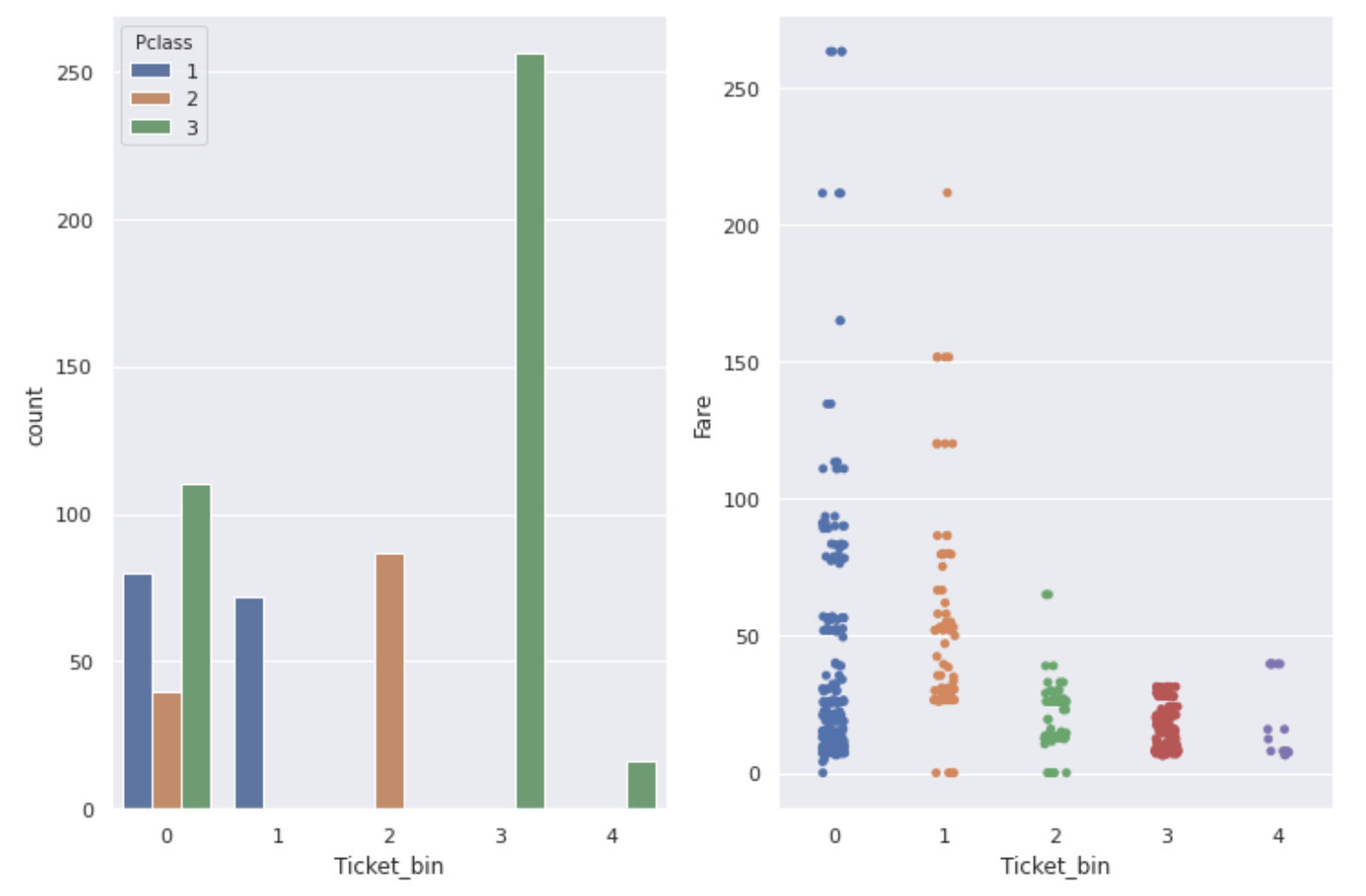
↓ Über Tickets mit nur Nummern
fig,ax = plt.subplots(1,2,figsize=(12,8))
sns.countplot(num_ticket['Ticket_bin'], hue=num_ticket['Pclass'], ax=ax[0])
sns.stripplot(x='Ticket_bin', y='Fare', data=num_ticket, ax=ax[1])
 ↓ Über Zahlen- und Alphabet-Tickets
↓ Über Zahlen- und Alphabet-Tickets
fig,ax = plt.subplots(1,2,figsize=(12,8))
sns.countplot(num_alpha_ticket['Ticket_bin'], hue=num_alpha_ticket['Pclass'], ax=ax[0])
sns.stripplot(x='Ticket_bin', y='Fare', data=num_alpha_ticket, ax=ax[1])
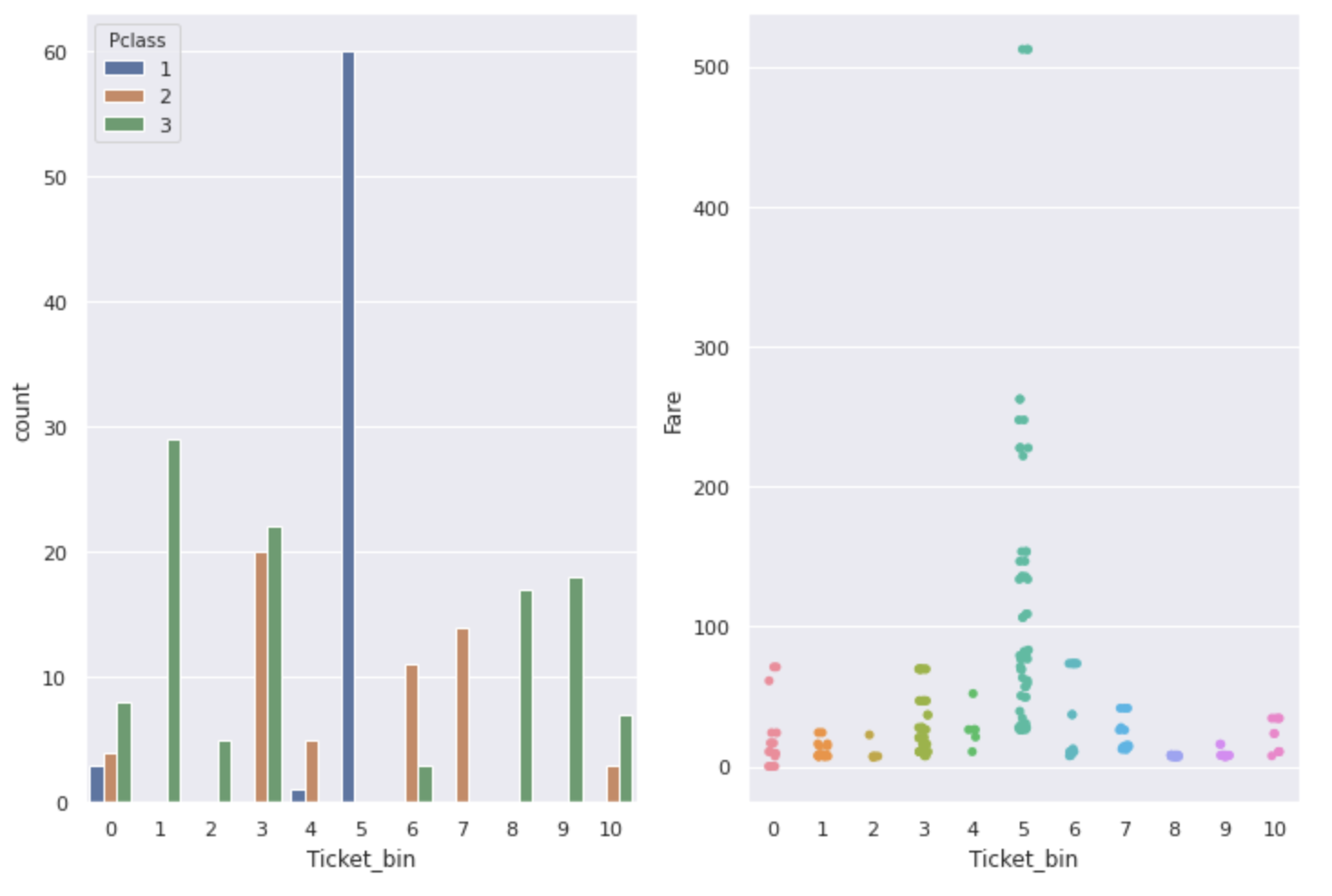
Wie Sie in der Grafik sehen können, sind ** Ticket, Pclass und Fare miteinander verbunden. Ticketnummern mit einer besonders hohen Überlebensrate haben einen hohen Fare, und die meisten Personen mit einer Pclass von 1 sind **.
Eine Ticketnummer, die auf den ersten Blick unbrauchbar erscheint, kann eine nützliche Funktion sein, wenn Sie auf diese Weise danach suchen.
- Age Da es fehlende Werte enthält, löschen Sie die Zeilen mit fehlenden Werten und klassifizieren Sie sie dann alle 10 Jahre, um die Überlebensrate zu überprüfen.
#Datenrahmen ohne fehlende Alterswerte'age_data'Erstellen
data_age = data.dropna(subset=['Age']).copy()
#Geteilt durch 10 Jahre
data_age['Age_bin'] = pd.cut(data_age['Age'],[i for i in range(0,81,10)])
fig, ax = plt.subplots(1,2, figsize=(20,8))
sns.barplot(x='Age_bin', y='Survived', data=data_age, color='coral', ax=ax[0])
sns.barplot(x='Age_bin', y='Survived', data=data_age, hue='Sex', ax=ax[1])
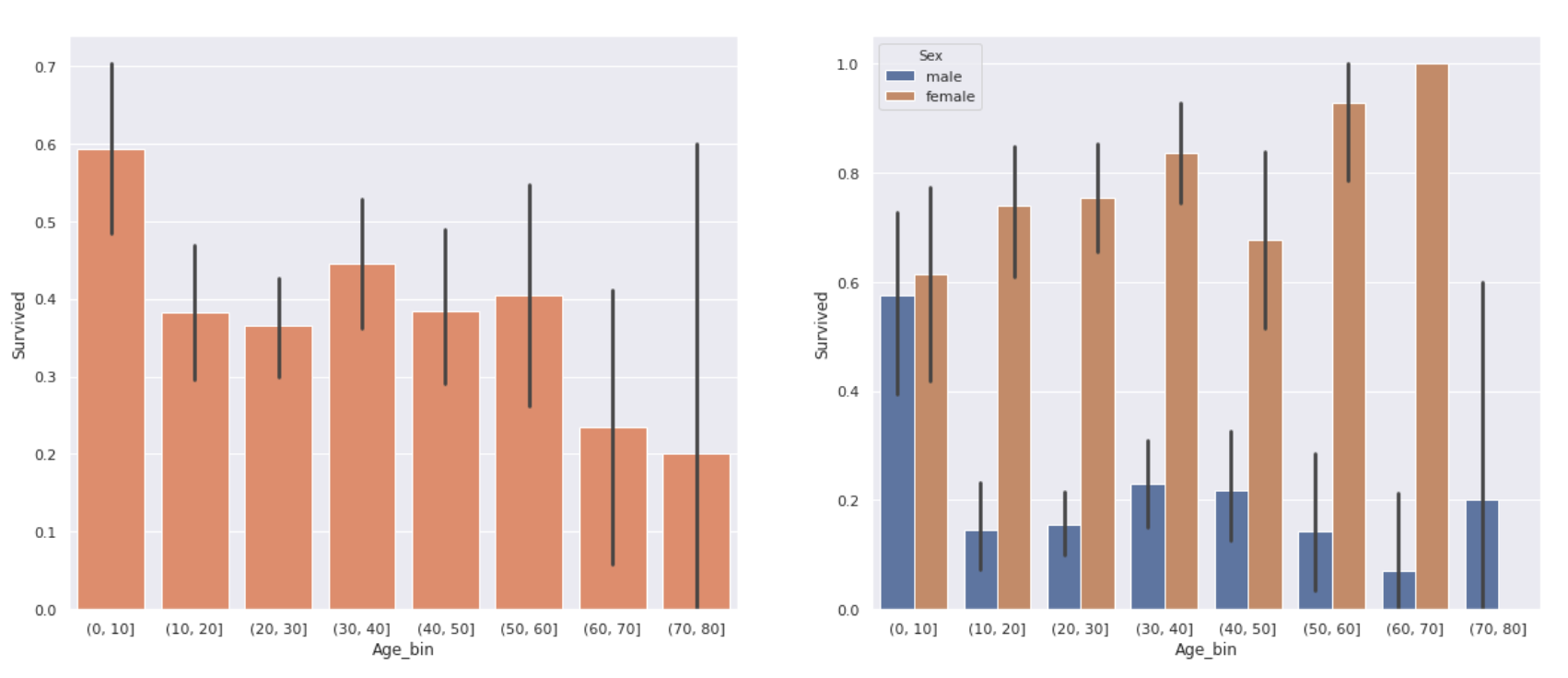
Die Grafik rechts ist eine nach Geschlecht getrennte Grafik links. Die Überlebensrate war je nach Alter unterschiedlich. ** Die Überlebensrate von Kindern unter 10 Jahren ist relativ hoch und die Überlebensrate von älteren Menschen über 60 Jahren ist mit etwa 20% recht niedrig **. Darüber hinaus gab es keinen signifikanten Unterschied in der Überlebensrate zwischen Teenagern und 50ern.
Betrachtet man jedoch jedes Geschlecht, ** haben Frauen eine erheblich höhere Überlebensrate, selbst wenn sie über 60 Jahre alt sind **. Die niedrige Überlebensrate älterer Menschen in der Grafik links kann auch auf die geringe Anzahl von Frauen über 60 Jahre zurückzuführen sein (nur 3).
- Embarked Gibt es einen Unterschied in Abhängigkeit vom Hafen, in dem die Passagiere an Bord gingen?
plt.figure(figsize=(12,8))
sns.barplot(x='Embarked', y='Survived', data=data)
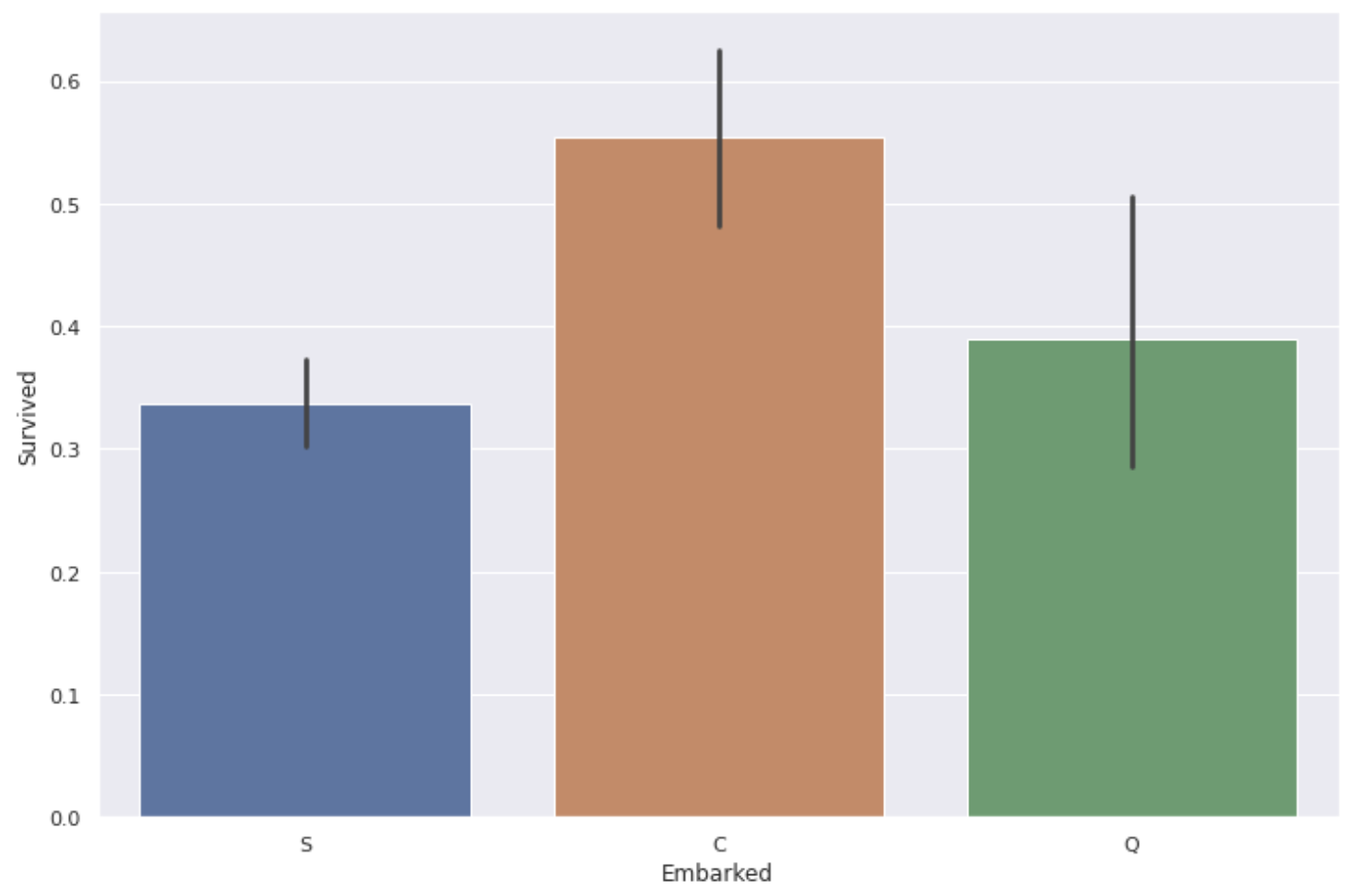 ** Die Überlebensrate von Personen, die aus dem Hafen von C (Cherbourg) einsteigen, ist etwas hoch **.
** Die Überlebensrate von Personen, die aus dem Hafen von C (Cherbourg) einsteigen, ist etwas hoch **.
Es ist unwahrscheinlich, dass sich der Port selbst auswirkt. Schauen wir uns also die Klassen und Tarife für jeden Porttyp an.
fig, ax = plt.subplots(1,2, figsize=(12,8))
sns.countplot(data['Embarked'], hue= data['Pclass'], ax=ax[0])
sns.boxplot(x='Embarked', y='Fare', data=data, sym='', ax=ax[1])
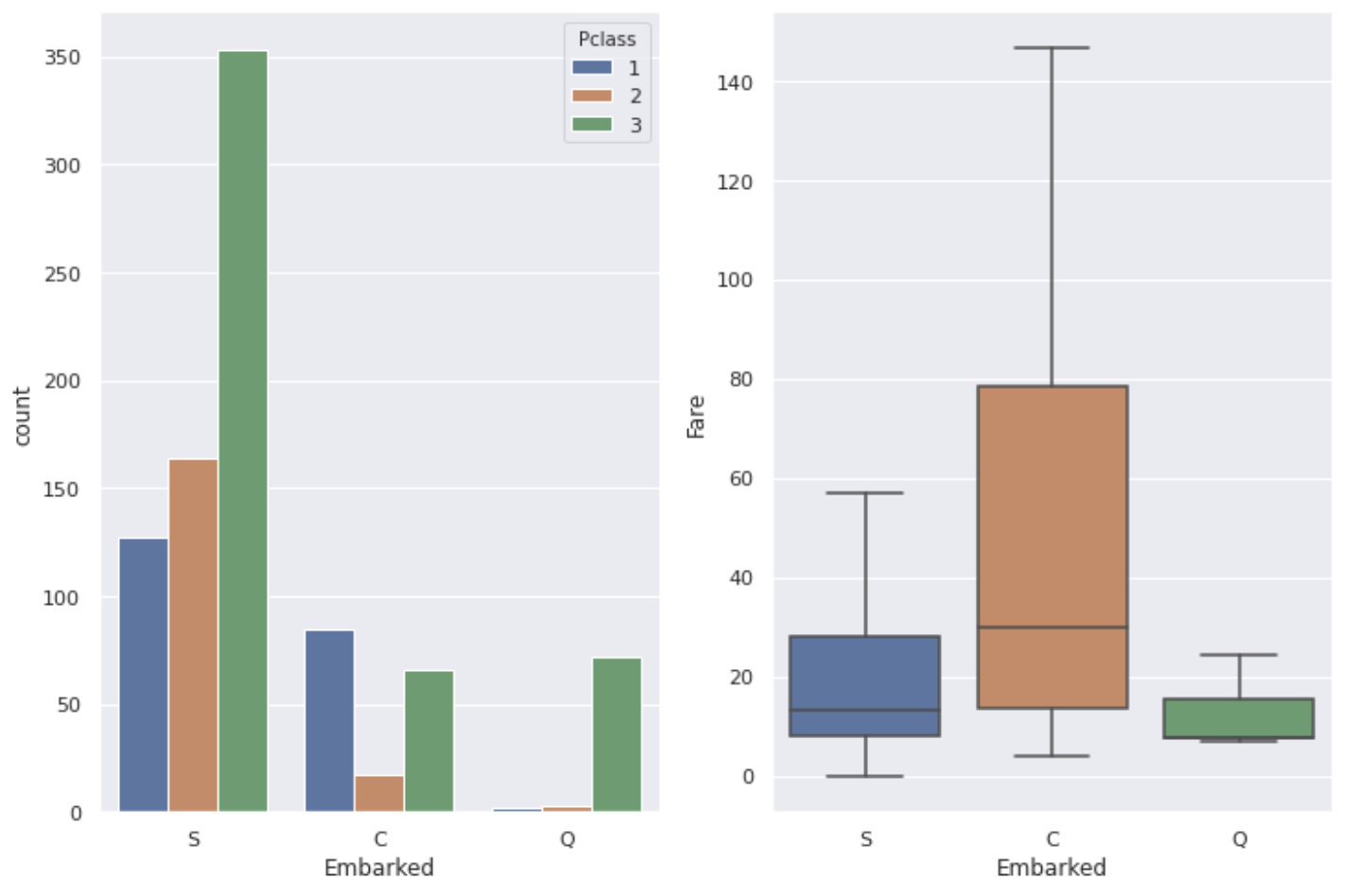 Es scheint, dass die Klasse und der Beruf der dort lebenden Menschen je nach Gebiet unterschiedlich sind, so dass es je nach Hafen Unterschiede gibt, wie in der obigen Grafik dargestellt.
Es scheint, dass die Klasse und der Beruf der dort lebenden Menschen je nach Gebiet unterschiedlich sind, so dass es je nach Hafen Unterschiede gibt, wie in der obigen Grafik dargestellt.
Wenn man das Ganze betrachtet, scheint es, dass es ziemlich viele Leute gibt, die aus dem Hafen von S (South Ampton) eingestiegen sind. Es kann gesagt werden, dass der Grund, warum die Überlebensrate am Hafen von C hoch war, darin besteht, dass das Verhältnis von ** P-Klasse: 1 Personen hoch ist und der Tarif auch relativ hoch ist **.
Die meisten Leute, die aus dem Hafen von Q (Queenstown) eingestiegen sind, haben die P-Klasse: 3, daher scheint die Überlebensrate die niedrigste zu sein, aber in Wirklichkeit ist die Überlebensrate im Hafen von S die niedrigste. Es gibt nicht so viele Unterschiede zwischen S und Q, aber es gibt auch einen Unterschied in der Anzahl der Daten. Der Grund, warum die Überlebensrate von Personen, die vom Hafen von S aus einsteigen, am niedrigsten ist, ist einfach ** "Es gibt viele Personen der Klasse P: 3". Es scheint, dass ich nur ** sagen kann.
- Cabin Da das Verhältnis der fehlenden Werte bis zu 77% beträgt, ist es schwierig, es als Merkmalsgröße für das Vorhersagemodell zu verwenden, aber ich werde untersuchen, ob mit den aufgezeichneten Daten etwas erhalten werden kann.
An dieser Stelle befand sich eine Zeichnung des Titanic-Schiffes.
Plans détaillés du Titanic
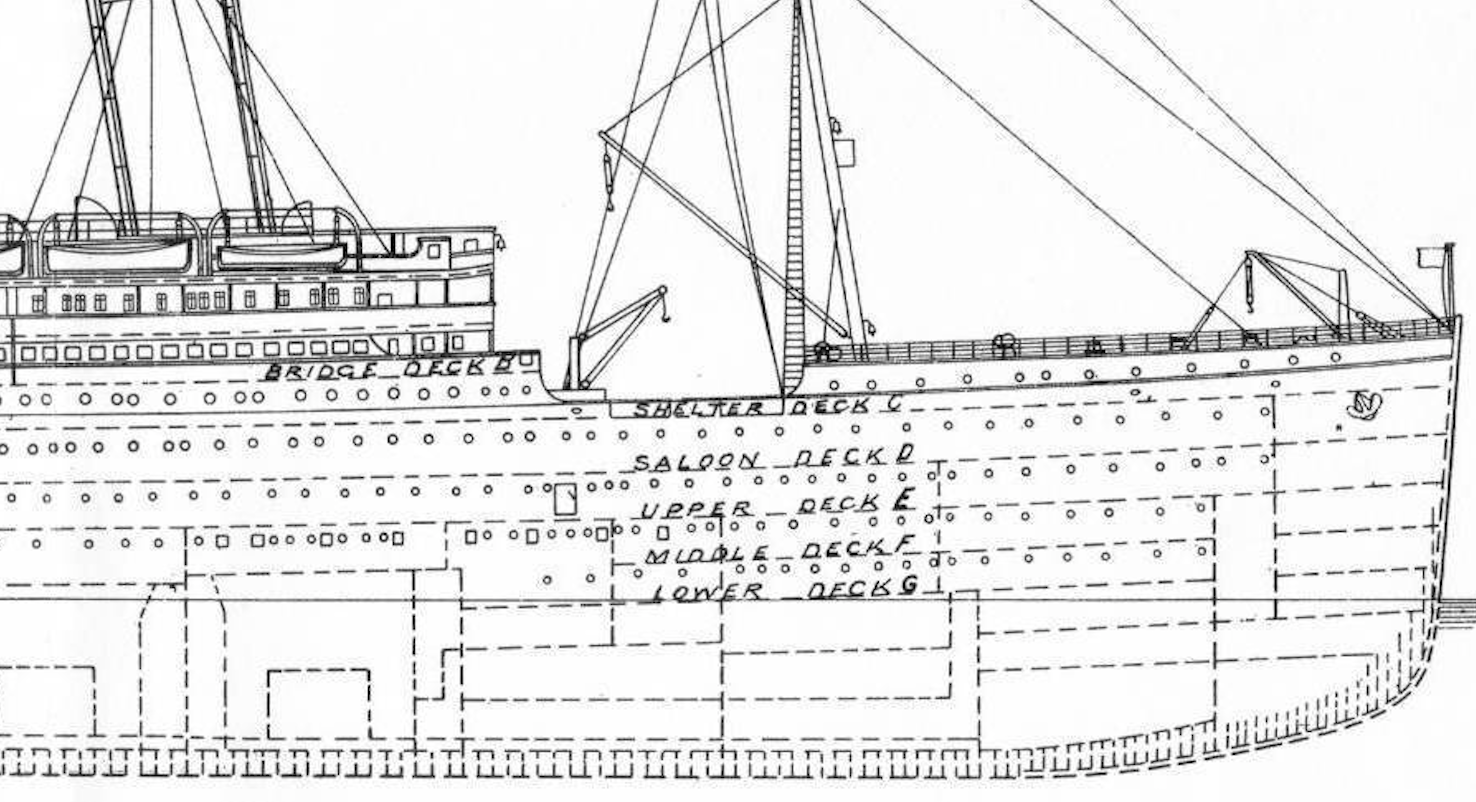 Die Gästezimmer sind als "B96" geschrieben und das erste Alphabet gibt die Hierarchie der Gästezimmer an.
Es gibt A- bis G- und T-Alphabete, A ist die oberste Etage des Schiffes (Luxuszimmer) und G ist die unterste Etage (gewöhnlicher Raum).
** Wenn man bedenkt, dass das Rettungsboot auf dem Oberdeck platziert ist ** und ** die Überschwemmung des Schiffes von unten beginnt **, ist die Überlebensrate der Person in Raum A, die dem Oberdeck am nächsten liegt Es sieht teuer aus **.
Mal sehen, was mit den tatsächlichen Daten passiert.
Die Gästezimmer sind als "B96" geschrieben und das erste Alphabet gibt die Hierarchie der Gästezimmer an.
Es gibt A- bis G- und T-Alphabete, A ist die oberste Etage des Schiffes (Luxuszimmer) und G ist die unterste Etage (gewöhnlicher Raum).
** Wenn man bedenkt, dass das Rettungsboot auf dem Oberdeck platziert ist ** und ** die Überschwemmung des Schiffes von unten beginnt **, ist die Überlebensrate der Person in Raum A, die dem Oberdeck am nächsten liegt Es sieht teuer aus **.
Mal sehen, was mit den tatsächlichen Daten passiert.
#Ich habe nur das Kabinenalphabet geschrieben'Cabin_alpha'Erstellen Sie eine Spalte von
#n ist die fehlende Wertezeile
data['Cabin_alpha'] = data['Cabin'].map(lambda x:str(x)[0])
data_cabin=data.sort_values('Cabin_alpha')
plt.figure(figsize=(12,8))
sns.barplot(x='Cabin_alpha', y='Survived', data=data_cabin)
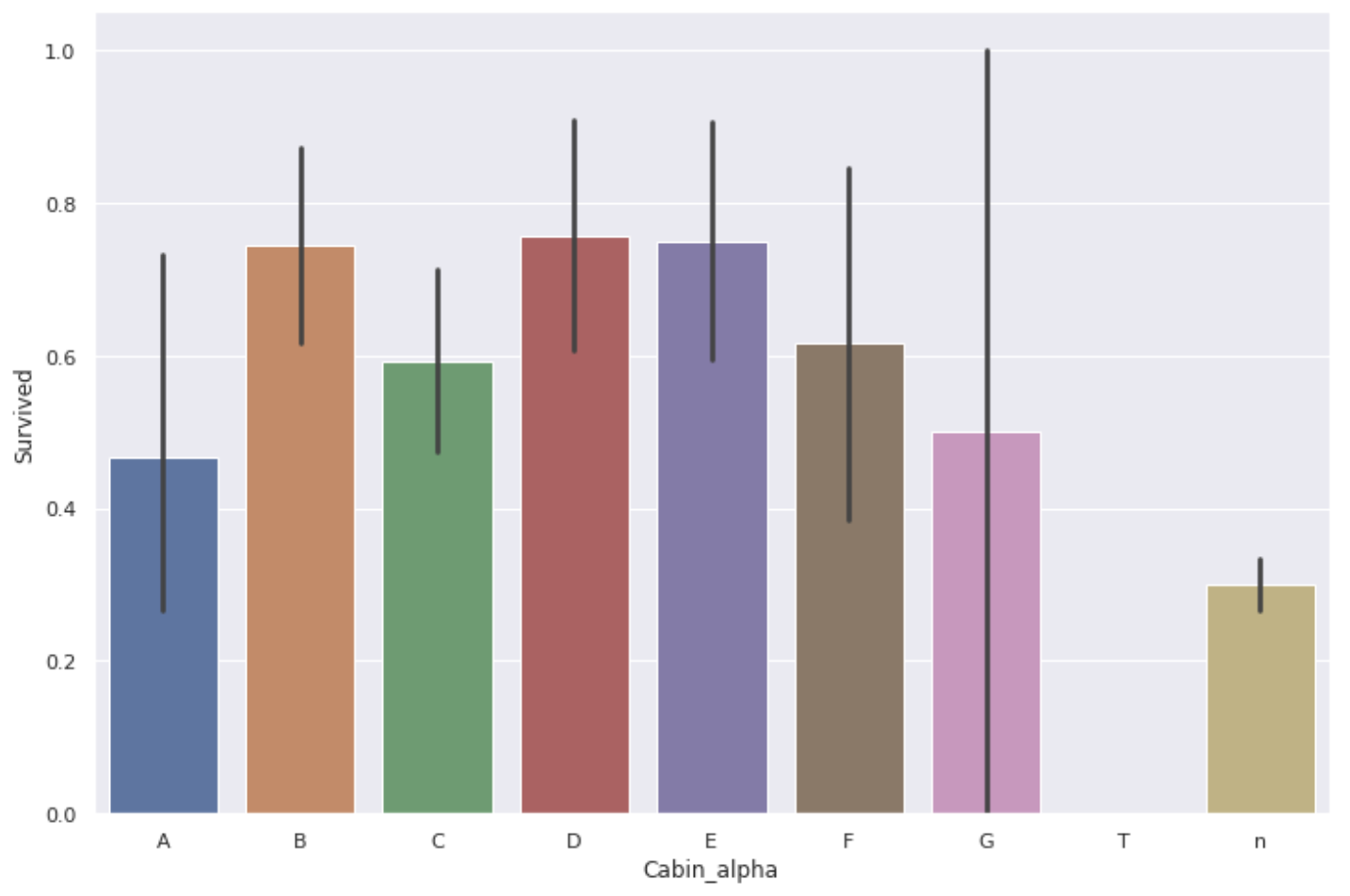 Entgegen den Erwartungen war die Überlebensrate von A's Zimmer nicht sehr hoch.
Die folgende Tabelle zeigt die Gesamtzahl der Daten.
Entgegen den Erwartungen war die Überlebensrate von A's Zimmer nicht sehr hoch.
Die folgende Tabelle zeigt die Gesamtzahl der Daten.
data['Survived'].groupby(data['Cabin_alpha']).agg(['mean', 'count'])
| mean | count | |
|---|---|---|
| Cabin_alpha | ||
| A | 0.466667 | 15 |
| B | 0.744681 | 47 |
| C | 0.593220 | 59 |
| D | 0.757576 | 33 |
| E | 0.750000 | 32 |
| F | 0.615385 | 13 |
| G | 0.500000 | 4 |
| T | 0.000000 | 1 |
| n | 0.299854 | 687 |
Die Datenmenge für B und C mag immer noch besser sein, aber die Datenmenge für A und G ist recht gering, so dass nicht gesagt werden kann, dass es je nach Etage des Gästezimmers einen Unterschied in der Überlebensrate gab **.
Ebenso wie beim Ticket gab es eine Person mit derselben Zimmernummer, daher dachte ich, dass "das Zimmer das gleiche ist" → "Verpflegung mit Freunden und Familie" → "Die Überlebensrate wird unterschiedlich sein", abhängig davon, ob die Zimmernummern doppelt vorhanden sind Wir haben die Überlebensrate von jedem berechnet.
data['Cabin_count'] = data.groupby('Cabin')['PassengerId'].transform('count')
data.groupby('Cabin_count')['Survived'].mean()
| Cabin_count | Überlebensrate |
|---|---|
| 1 | 0.574257 |
| 2 | 0.776316 |
| 3 | 0.733333 |
| 4 | 0.666667 |
Als ich es sah, war die Überlebensrate der Person, die alleine im Raum war, etwas niedrig ... ich konnte es nicht bekommen. Immerhin ist die Anzahl der Daten zu gering, um ein klares Ergebnis zu erzielen.
Im Gegenteil, die Kabinensäule kann abgeschnitten werden, wenn sie die Vorhersage stört oder zu Überlernen führt.
Zusammenfassung
Dieses Mal habe ich versucht, die Daten hauptsächlich in Bezug auf die Beziehung zu Survived zu analysieren, um die Daten zu finden, die als Merkmalsgröße für das Vorhersagemodell verwendet werden können. Wir haben festgestellt, dass die Merkmale, die wahrscheinlich signifikant mit der Überlebensrate zusammenhängen, ** P-Klasse, Tarif, Anzahl der Familienmitglieder (Family_size), doppelte Tickets (Ticket_count), Geschlecht und Alter ** sind.
Das nächste Mal möchte ich die fehlenden Werte in den Zugdaten und Testdaten ausgleichen und den Datenrahmen für das Vorhersagemodell vervollständigen.
Wenn Sie Meinungen oder Vorschläge haben, würden wir uns freuen, wenn Sie einen Kommentar abgeben könnten.
Recommended Posts