Verwenden wir die offenen Daten von "Mamebus" in Python
Die Abteilung für Stadtplanung und Verkehrspolitik der Stadt Kusatsu wandelt den Gemeindebus "Mame Bus" der Stadt Kusatsu in offene Daten um. http://www.city.kusatsu.shiga.jp/kurashi/kotsudorokasen/mamebus/opendata.html
Hier werde ich die Daten dieses "Mame Bus" behandeln. Der Zweck besteht darin, automatisch alle Daten herunterzuladen und eine Datenbank ordnungsgemäß zu erstellen, um die Busdaten im Web verfügbar zu machen. Zu diesem Zeitpunkt sollen Excel-Daten nicht nur unter Windows, sondern auch unter Linux analysiert werden.
Dies ermöglicht es, die neuesten Daten auf vielen Mietservern usw. (innerhalb bestimmter Änderungen) ohne menschliches Eingreifen automatisch zu verwenden.
Demo http://needtec.sakura.ne.jp/bus_data/kusatu.html

Github https://github.com/mima3/bus_data
Verwenden Sie den folgenden Befehl, um die Daten herunterzuladen und die Datenbank zu erstellen.
python import.py application.ini
Wenn die Daten aktualisiert werden, können Sie mit diesem Befehl immer noch die neuesten Daten abrufen. Es ist eine gute Idee, es regelmäßig mit cron zu betreiben.
Daten Beschreibung
Jede Zeile besteht aus den folgenden drei Konfigurationen.
| Name | Format | Erläuterung |
|---|---|---|
| Zeitplan | Excel | Es sind die Daten, die die Ankunftszeit jeder Bushaltestelle beschreiben. Die Ankunftszeit kann je nach Wochentag, Samstag und Tag variieren |
| Halt | csv | Haltの名前、読み、座標が格納されたCSVデータです。 Auf derselben Route können sich mehrere Daten im Uhrzeigersinn und gegen den Uhrzeigersinn befinden. |
| Straßenkarte | shape | Straßenkarteの形状を表したshapeファイルです。この測地系は「平面直角2000(6er Serie)Bitte beachte, dass. Auf derselben Route können sich mehrere Daten im Uhrzeigersinn und gegen den Uhrzeigersinn befinden. |
Bei der Arbeit mit Daten sind einige Dinge zu beachten.
Es gibt mehrere Bushaltestellen mit demselben Bushaltestellennamen.
Es gibt mehrere Bushaltestellen mit demselben Namen.
Schauen Sie sich zum Beispiel M04_stops_ccw.csv an. Am Nomura Athletic Park Exit gibt es zwei Linien. Die Ausfahrt Nomura Athletic Park unter 135.954709,35.023382 und die Ausfahrt Nomura Athletic Park unter 135.954445,35.023323.
Busse an derselben Position halten mehrmals auf derselben Route
Selbst wenn der Bus an derselben Position hält, kann er auf derselben Route mehrmals anhalten.
Schauen Sie sich zum Beispiel M04_stops_ccw.csv an. Der Westausgang der Kusatsu Station hält an der 1. und 37. Haltestelle.
Die Stoppreihenfolge ist in der zweiten Zeile der CSV aufgeführt.
Fluktuation der CSV- und Excel-Notation
Der Name der Bushaltestelle kann zwischen Excel und CSV unterschiedlich sein. Es gibt einige, die unterschiedliche Namen haben, z. B. Zeilenumbrüche und nicht nur Unterschiede in halber und voller Breite.
| csv | excel |
|---|---|
| Vor der Yamada Grundschule | Yamada Grundschule |
| Kinogawa Higashi | Kikawa Higashi |
| Nishi Shibukawa 1-chome | Nishi Shibukawa 1-chome |
| Nomura 8-chome | Nomura 8-chome |
| Vor der Shindo Junior High School | Shindo Junior High School |
Inkonsistente Art, Tage im Stundenplan auszudrücken
Normalerweise ist die Anordnung der Daten in Excel gleich, jedoch für jede Arbeitsmappe unterschiedlich.
Schauen Sie sich M01_stop_times.xlsx an.

In dieser Arbeitsmappe bestimmt das Vorhandensein oder Fehlen von "●", ob es sich um einen Samstag oder einen Wochentag handelt. Aber schauen wir uns eine andere M03_stop_times.xlsx an.
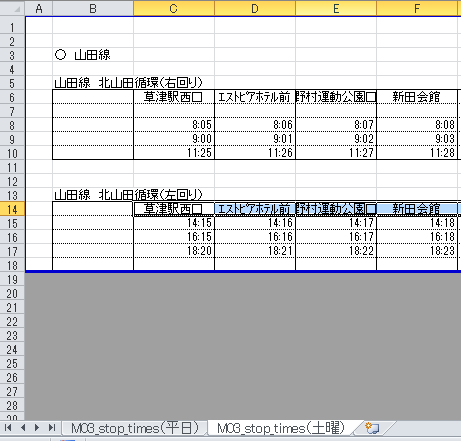
Hier werden die Tage für jedes Blatt aufgeteilt.
| Buchname | Wie man den Tag bestimmt |
|---|---|
| M01_stop_times.xlsx | Beurteilung durch ● |
| M02_stop_times.xlsx | Beurteilung durch ● |
| M03_stop_times.xlsx | Blatt gespalten |
| M04_stop_times.xlsx | Blatt gespalten |
| M05_stop_times.xlsx | Keine Erwähnung des Tages |
Wie Sie daraus ersehen können, ist es besser zu berücksichtigen, dass die Datenstartposition für jedes Buch unterschiedlich ist.
Leere Linie zwischen Name und Uhrzeit der Bushaltestelle
Da die Uhrzeit in der nächsten Zeile des Bushaltestellennamens eingegeben wird, möchten Sie möglicherweise von dort aus suchen und beurteilen, dass der Fahrplan abgelaufen ist, wenn alle Zeilen leer sind.
Dies kann jedoch nicht. Werfen wir einen Blick auf die Yamada-Linie (Kinogawa-Zirkulation: gegen den Uhrzeigersinn) von M04_stop_times.xlsx. Die Zeile nach dem Namen der Bushaltestelle ist vollständig leer und die Daten beginnen mit der nächsten Zeile.
Nicht skalierbare Datenplatzierung
Im Fall des folgenden Blattes ändert sich die Datenmenge einfach, selbst wenn die Anzahl der Busse zunimmt, sodass sich bei der Analyse von Excel nichts ändert.
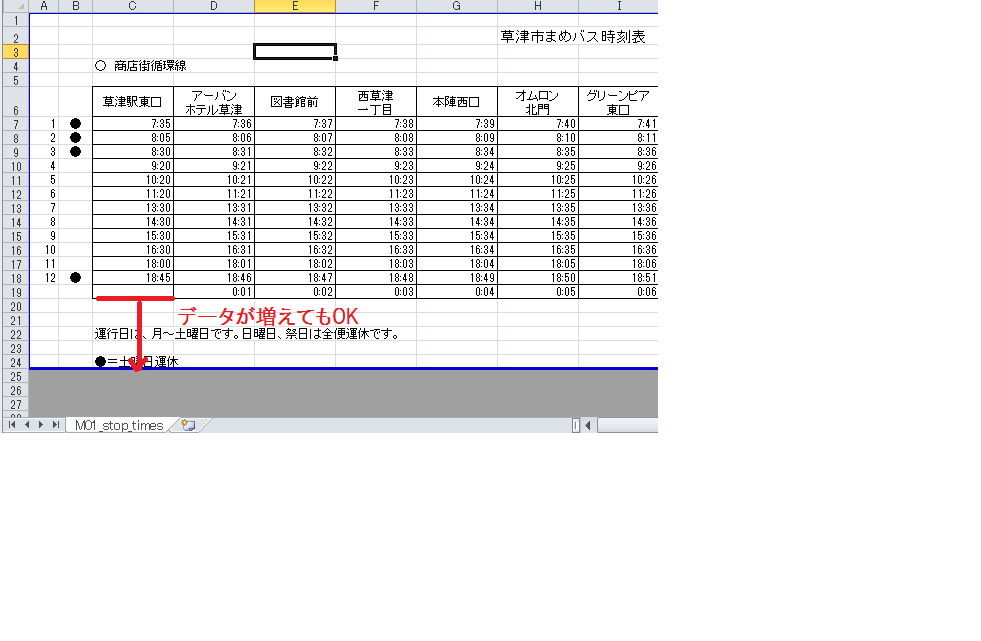
Aber bedenken Sie die nächste Zeile.

In diesem Beispiel verschiebt sich mit zunehmender Datenmenge auch die Datenstartposition unten, sodass die Verarbeitung geändert werden muss.
Beispiele, die von Python behandelt werden
Behandeln Sie Excel-Dateien
Verwenden Sie xlrd, um mit Excel in Python zu arbeiten. https://github.com/python-excel/xlrd
Einige Beispiele, die diese Bibliothek verwenden, werden bei Google veröffentlicht. Grundsätzlich ist es jedoch besser, sie anhand des offiziellen Beispielcodes zu erstellen.
https://github.com/python-excel/xlrd/blob/master/scripts/runxlrd.py
Die folgenden Implementierungsbeispiele sind beispielsweise häufig.
from xlrd import open_workbook
wb = open_workbook('test_err.xlsx')
for sh in wb.sheets():
for row in range(sh.nrows):
values = []
for col in range(sh.ncols):
v = sh.cell(row,col).value
if not isinstance(v, basestring):
v = str(v)
v = v + ':' + str(sh.cell(row,col).ctype)
values.append(v)
print ','.join(values)
Der obige Code funktioniert gut mit XLS-Erweiterungen und xlsx ohne Zusammenführen von Zellen. Ein Fehler tritt jedoch auf, wenn Sie ein Blatt mit den folgenden Zellenzusammenführungen betreiben.
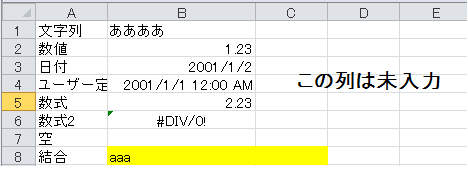
** Fehlerinhalt **
Traceback (most recent call last):
File "test2.py", line 7, in <module>
v = sh.cell(row,col).value
File "C:\Python27\lib\site-packages\xlrd-0.9.3-py2.7.egg\xlrd\sheet.py", line
399, in cell
self._cell_types[rowx][colx],
IndexError: array index out of range
Anscheinend ist die Anzahl der Spalten für jede Zeile unterschiedlich, und ich muss die Anzahl der Spalten für jede Zeile ermitteln. Sie können dieses Problem vermeiden, indem Sie die Anzahl der Spalten für jede Zeile mit row_len wie unten gezeigt abrufen.
from xlrd import open_workbook
wb = open_workbook('test_err.xlsx')
for sh in wb.sheets():
for row in range(sh.nrows):
values = []
for col in range(sh.row_len(row)):
v = sh.cell(row,col).value
if not isinstance(v, basestring):
v = str(v)
v = v + ':' + str(sh.cell(row,col).ctype)
values.append(v)
print ','.join(values)
Darüber hinaus ist die Datumsanzeigemethode auch in runxlrd.py implementiert, sodass Sie sie vorerst einmal lesen sollten.
So erfassen Sie Daten
Wie bereits erwähnt, gibt es Abschnitte, die Excel in Stimmung bringen. Daher ist es notwendig, flexibel mit jedem Abschnitt umzugehen. Daher habe ich die Methode zum Importieren von Daten in der JSON-Einstellungsdatei gespeichert und versucht, die Daten durch Betrachten zu importieren.
https://github.com/mima3/bus_data/blob/master/data/kusatu.json
Verarbeitungszweig nach dem Download
Dieses Mal werden komprimierte und unkomprimierte Daten gemischt. Daher wird die Verarbeitung nach dem Herunterladen durch Herunterladen der Einstellungsdatei beschrieben.
data/kusatu.json
"download" : {
"http://www.city.kusatsu.shiga.jp/kurashi/kotsudorokasen/mamebus/opendata.files/M01_stop_times.xlsx" : "save_local",
"http://www.city.kusatsu.shiga.jp/kurashi/kotsudorokasen/mamebus/opendata.files/M01_stops_ccw.csv" : "save_local",
"http://www.city.kusatsu.shiga.jp/kurashi/kotsudorokasen/mamebus/opendata.files/M01_shapes.zip" : "expand_zip",
save_local speichert auf der lokalen Festplatte. expand_zip führt den Versuch aus, nach dem Speichern zu entpacken.
Siehe unten für den tatsächlichen Code. https://github.com/mima3/bus_data/blob/master/downloader.py
Entspricht der Schwankung der CSV- und EXCEL-Notation
Entspricht Schwankungen in der CSV- und Excel-Notation.
Die Grundregeln lauten wie folgt. ・ Konvertieren Sie den Namen der Bushaltestelle gemäß der convert_rule der Einstellungsdatei ・ Zeilenumbrüche entfernen ・ Ändern Sie die halbe Breite in die volle Breite.
** Bushaltestellenname umwandeln **
data/kusatu.json
"convert_rule" : {
"Vor der Yamada Grundschule": "Yamada Grundschule",
"Kinogawa Higashi":"Kikawa Higashi",
"Nishi Shibukawa 1-chome": "Nishi Shibukawa 1-chome",
"Nomura 8-chome": "Nomura 8-chome",
"Vor der Shindo Junior High School": "Shindo Junior High School"
},
bus_data_parser.py
def convert_bus_stop_name(rule, bus_stops):
for bus_stop in bus_stops:
if bus_stop['stopName'] in rule:
bus_stop['stopName'] = rule[bus_stop['stopName']
** Zeilenumbrüche entfernen und halbe Breite in voller Breite machen **
bus_data_parser.py
def get_bus_timetable(wbname, sheetname, stop_offset_row, stop_offset_col, stopdirection, timetable_offset_row, timetable_offset_col, chk_func):
xls = xlsReader(wbname, sheetname)
stop_name_list = []
if stopdirection == DataDirection.row:
busdirection = DataDirection.col
else:
busdirection = DataDirection.row
xls.set_offset(stop_offset_row, stop_offset_col)
while True:
v = xls.get_cell()
if not v:
break
v = zenhan.h2z(v)
v = v.replace('\n', '')
stop_name_list.append(v)
xls.next_cell(stopdirection)
Zenhan wird für die Konvertierung in halber und voller Breite verwendet. https://pypi.python.org/pypi/zenhan
Beschreibung der Importregeln für CSV-, EXCEL- und Shape-Dateien
Geben Sie an, wie jede Datei wie folgt importiert werden soll.
"import_rule" : [
{
"operation_company" : "Stadt Kusatsu",
"line_name" : "Einkaufsstraße Verkehrslinie",
"shape" : "M01_shapes/M01.shp",
"srid" : 2448 ,
"timetables" : [
{
"route" : "Route1L",
"routeName" : "Einkaufsstraße Verkehrslinie",
"bus_stops" : "M01_stops_ccw.csv",
"weekday_timetable" : {
"workbook" : "M01_stop_times.xlsx",
"sheetname" : "M01_stop_times",
"stop_offset_row" : 6,
"stop_offset_col" : 3,
"timetable_offset_row" : 7,
"timetable_offset_col" : 3
},
"saturday_timetable" : {
"workbook" : "M01_stop_times.xlsx",
"sheetname" : "M01_stop_times",
"stop_offset_row" : 6,
"stop_offset_col" : 3,
"timetable_offset_row" : 7,
"timetable_offset_col" : 3,
"check_func" : "check_shoutengai_saturday"
},
"holyday_timetable" : {
}
}
]
}, //Abkürzung
{
"operation_company" : "Stadt Kusatsu",
"line_name" : "Yamada Line (Kitayamada Circulation)",
"shape" : "M03_shapes/M03.shp",
"srid" : 2448 ,
"timetables" : [
{
"route" : "Route3R",
"routeName" : "Kitayamada Zirkulationslinie im Uhrzeigersinn",
"bus_stops" : "M03_stops_cw.csv",
"weekday_timetable" : {
"workbook" : "M03_stop_times.xlsx",
"sheetname" : "M03_stop_Zeiten (Wochentage)",
"stop_offset_row" : 6,
"stop_offset_col" : 3,
"timetable_offset_row" : 7,
"timetable_offset_col" : 3
},
"saturday_timetable" : {
"workbook" : "M03_stop_times.xlsx",
"sheetname" : "M03_stop_Zeiten (Samstag)",
"stop_offset_row" : 6,
"stop_offset_col" : 3,
"timetable_offset_row" : 7,
"timetable_offset_col" : 3
},
"holyday_timetable" : {
}
},
{
"route" : "Route3L",
"routeName" : "Kitayamada Zirkulationslinie gegen den Uhrzeigersinn",
"bus_stops" : "M03_stops_ccw.csv",
"weekday_timetable" : {
"workbook" : "M03_stop_times.xlsx",
"sheetname" : "M03_stop_Zeiten (Wochentage)",
"stop_offset_row" : 14,
"stop_offset_col" : 3,
"timetable_offset_row" : 15,
"timetable_offset_col" : 3
},
"saturday_timetable" : {
"workbook" : "M03_stop_times.xlsx",
"sheetname" : "M03_stop_Zeiten (Samstag)",
"stop_offset_row" : 14,
"stop_offset_col" : 3,
"timetable_offset_row" : 15,
"timetable_offset_col" : 3
},
"holyday_timetable" : {
}
}
]
}, //Abkürzung
Bezogen auf die Formdatei sind "Form" und "srid". Beschreiben Sie den Namen der Formdatei in Form und das geodätische System in srid.
Bezogen auf die CSV-Datei ist "bus_stops". Beschreiben Sie den CSV-Dateinamen in bus_stops.
Excel-Dateien werden an Wochentagen, Samstagen und Feiertagen aufgelistet. Name der Arbeitsmappe in der Arbeitsmappe Blattname im Blattname stop_offset_row, die Startposition, an der der Name der Bushaltestelle in stop_offset_col geschrieben ist, Beschreiben Sie die Startposition, an der die Zeit in timetable_offset_row und timetable_offset_col beschrieben ist. check_func ist ein optionales Element, das die Rückruffunktion angibt, die jedes Mal ausgeführt werden soll, wenn eine Zeitplanzeile gelesen wird.
Hier wird der Wert einer bestimmten Spalte wie unten gezeigt überprüft. Wenn die Daten ungültig sind, wird False zurückgegeben und die Zeile wird ignoriert. Dies wird für das Urteil am Samstag verwendet.
import.py
class BusParserCallBack(object):
def check_shoutengai_saturday(self, workbook, sheet, busrow, buscol, item):
if sheet.cell(busrow - 1, 2 - 1).value:
return True
else:
return False
Umgang mit Formdateien
Für Python ist es eine gute Idee, pyshp zu verwenden. Bitte beachten Sie Folgendes.
** Versuchen Sie, in die Datenbank zu importieren, indem Sie ShapeFile der nationalen Landnummerninformationen mit Python bearbeiten ** http://qiita.com/mima_ita/items/e614a281807970427921
Umstellung des Vermessungssystems
Das Geografiesystem der Formdatei von Mamebus lautet "Plane right angle 2000 (6 system)", und wenn es sich um SRID handelt, ist es 2448. Dies muss in ein Weltgeographiesystem umgewandelt werden. Diese Konvertierung ist ziemlich ärgerlich, kann jedoch problemlos mit einer Datenbank durchgeführt werden, die Geometrie wie Spatia Lite verarbeitet.
Im Fall von Spatialite können Sie es zurückgeben, indem Sie die folgende SQL ausführen.
select AsText(Transform(GeomFromText('POINT(-4408.916645 -108767.765479)', 2448), 4326))
Der Python-Code sieht folgendermaßen aus:
bus_db.py
for timetable in timetables:
database_proxy.get_conn().execute(
"""
INSERT INTO RouteTable
(metaData_id, operationCompany, lineName, route, routeName, geometry)
VALUES(?, ?,?,?,?,Transform(GeometryFromText(?, ?),?))
""",
(
meta_id,
operation_company,
line_name,
timetable['route'],
timetable['routeName'],
routedict[timetable['route']], src_srid, SRID
)
)
Zusammenfassung
Auf diese Weise können Sie bei Verwendung der Python-Bibliothek die Daten von "Mamebus" ohne besondere Aufmerksamkeit verwenden.
Die Daten sind jedoch ziemlich eigenartig und nicht so strukturiert, dass sie eine maschinelle Analyse annehmen, sodass Sie dort Schwierigkeiten haben werden.
Wenn Sie den Umgang mit Daten mit einer Maschine vereinfachen und die Datenseite verbessern möchten, sind die folgenden Punkte meiner Meinung nach erforderlich. ・ Datenkonsistenz zwischen verschiedenen Dateien wie CSV und Excel ・ Vereinheitlichen Sie das Format, da die Verwendung von Excel unvermeidlich ist ・ Überlegen Sie, wann die Datenmenge zunimmt.
Recommended Posts