[PYTHON] Versuchen Sie, den Wechselkurs (FX) mit nicht tiefem maschinellem Lernen vorherzusagen
Maschinelles Lernen ist oft mit tiefem Lernen verbunden, aber es gibt viele andere. Es ist auch nicht so tief, weil es nicht gut ist. Versuchen wir also die Daten von vorheriger Artikel mit einem anderen maschinellen Lernen.
** Verwandte Serien **
- Versuchen Sie, den Wechselkurs (FX) mit dem 1. TensorFlow (Deep Learning) vorherzusagen ――Teil 2 Versuchen Sie, den Wechselkurs (FX) mit nicht tiefem maschinellem Lernen vorherzusagen
- CNN-Ausgabe zur Vorhersage des Wechselkurses (FX) mit dem 3. TensorFlow (Deep Learning)
TL;DR
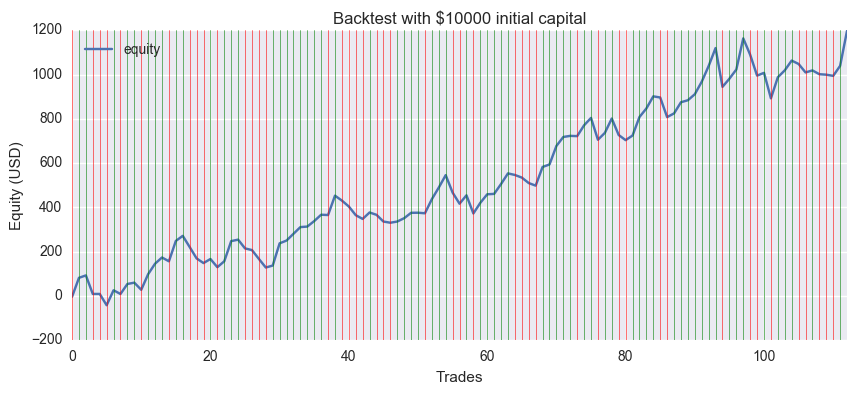 Ich habe ein Diagramm der Änderungen der Vermögenswerte erstellt. Es ist 12% Gewinn </ font> in ungefähr einem halben Jahr gewesen, aber es wird nicht immer funktionieren, da das Ergebnis nicht robust gegenüber den Lernbedingungen ist.
Ich habe ein Diagramm der Änderungen der Vermögenswerte erstellt. Es ist 12% Gewinn </ font> in ungefähr einem halben Jahr gewesen, aber es wird nicht immer funktionieren, da das Ergebnis nicht robust gegenüber den Lernbedingungen ist.
** Ich habe ein Notebook auf GitHub. ** **. Gabel und spielen. https://github.com/hayatoy/ml-forex-prediction
Scikit-learn Dies ist der erste Ort, an dem Sie mit Python maschinell lernen können. Wenn die Installation "pip" ist
pip install -U scikit-learn
Ich denke es ist okay.
Auswahl des Klassifikators
Sie können sie alle ausprobieren, aber ich vermute, dass zu linear gute Ergebnisse für verrauschte Daten liefert.
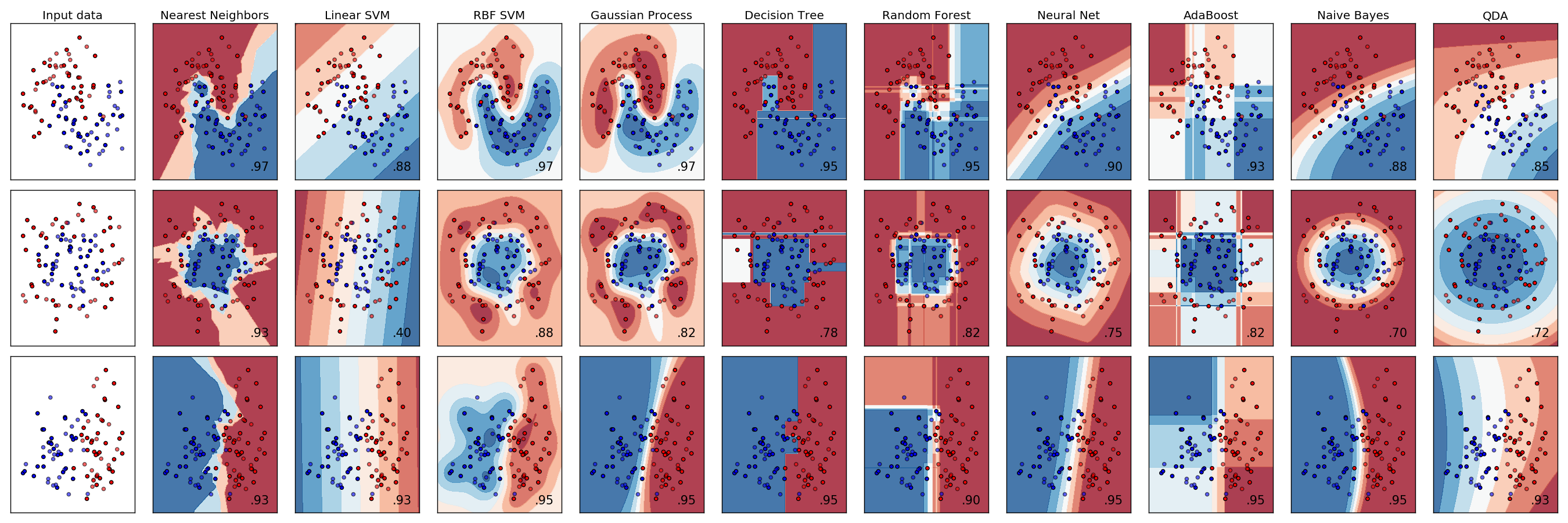 Ein Beispiel für eine Klassifizierung ist wie folgt [^ 1].
[^ 1]: Quelle: http://scikit-learn.org/stable/auto_examples/classification/plot_classifier_comparison.html
Ein Beispiel für eine Klassifizierung ist wie folgt [^ 1].
[^ 1]: Quelle: http://scikit-learn.org/stable/auto_examples/classification/plot_classifier_comparison.html
SVM (RBF), Naive Bayes Bereich sieht gut aus.
Datenverarbeitung
Es scheint, dass es mit der gleichen Form "passt", also werde ich es so verwenden, wie es ist. Als ich darüber nachdachte, wurde ich wütend, dass die Klasse immer noch 1hot-Vektor war. (Hattest du irgendwelche Optionen?) Es ist eine Konvertierung von 1hot-vector in binär, aber diesmal sind es 2 Klassen, so dass Sie anscheinend nur die Position zum Abrufen ändern können.
>> train_y
[[ 0. 1.]
[ 0. 1.]
[ 1. 0.]
[ 0. 1.]
[ 0. 1.]
[ 0. 1.]
[ 1. 0.]
[ 0. 1.]
[ 1. 0.]
[ 0. 1.]]
>> train_y[:,1]
[ 1. 1. 0. 1. 1. 1. 0. 1. 0. 1.]
Diese Methode kann nicht mit mehreren Klassen verwendet werden. Ich frage mich, ob es einen coolen Weg gibt.
Lass mich lernen
Nach wie vor werden 90% der ersten Hälfte für das Training und 10% der zweiten Hälfte für Tests verwendet. Unter "0,502118" ist schlechter als zufällig vorhergesagt.
Implementieren Sie vorerst fair mit den Standardparametern.
SVM (RBF)
from sklearn import svm
train_len = int(len(train_x)*0.9)
clf = svm.SVC(kernel='ref')
clf.fit(train_x[:train_len], train_y[:train_len,1])
clf.score(train_x[train_len:], train_y[train_len:,1])
Ergebnis: 0.49694435509810231 </ font>
Gradient Boosting
from sklearn.ensemble import GradientBoostingClassifier
clf = GradientBoostingClassifier()
clf.fit(train_x[:train_len], train_y[:train_len,1])
clf.score(train_x[train_len:], train_y[train_len:,1])
Ergebnis: 0.52331939530395621 </ font>
Random Forest
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier(random_state=0)
clf.fit(train_x[:train_len], train_y[:train_len,1])
clf.score(train_x[train_len:], train_y[train_len:,1])
Ergebnis: 0.49726600192988096 </ font>
Naive Bayes
from sklearn.naive_bayes import GaussianNB
clf = GaussianNB()
clf.fit(train_x[:train_len], train_y[:train_len,1])
clf.score(train_x[train_len:], train_y[train_len:,1])
Ergebnis: 0.50112576391122543 </ font>
Nearest Neighbors
from sklearn.neighbors import KNeighborsClassifier
clf = KNeighborsClassifier()
clf.fit(train_x[:train_len], train_y[:train_len,1])
clf.score(train_x[train_len:], train_y[train_len:,1])
Ergebnis: 0.49726600192988096 </ font>
QDA
from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis as QDA
clf = QDA()
clf.fit(train_x[:train_len], train_y[:train_len,1])
clf.score(train_x[train_len:], train_y[train_len:,1])
Ergebnis: 0.50981022836925061 </ font>
Zusammenfassung
| Rangfolge | Modell- | Accuracy |
|---|---|---|
| 1 | BiRNN(LSTM) | 0.528883 |
| 2 | Gradient Boosting | 0.523319 |
| 3 | QDA | 0.509810 |
| Prozentsatz vieler Klassen | 0.502118 | |
| 4 | Naive Bayes | 0.501126 |
| 5 | Random Forest | 0.497266 |
| 6 | Nearest Neighbors | 0.497266 |
| 7 | SVM (RBF) | 0.496944 |
Immerhin war das letzte LSTM der erste Platz. Der zweite Platz war Gradient Boosting, das auch in Kaggle beliebt ist. Was ist das? Ist SVM die niedrigste, obwohl die Parameter nicht angepasst wurden? Das sollte sein ... Ich werde bei einer anderen Gelegenheit versuchen, den optimalen Parameter mit "Grid Search" zu finden.
PnL berechnen (Gewinn & Verlust)
Nur weil die richtige Antwortrate schlecht ist, bedeutet dies nicht, dass der Gewinn oder Verlust schlecht sein wird. Selbst bei einer korrekten Rücklaufquote von 50% ist "Gewinn> Verlust" in Ordnung.
Diese Daten sagen voraus, ob der Schlusskurs für die nächste Periode steigen oder fallen wird.
Damit
(Nächster Schlusskurs - Aktueller Schlusskurs) * Lot-Provision
Wurde als Gewinn und Verlust berechnet.
(Tatsächlich wird vorausgesagt, wann der aktuelle Schlusskurs bestätigt wird, sodass Sie keine Position zum Schlusskurs einnehmen können. Funktioniert möglicherweise) </ font>
Github-Version der täglichen EUR / USD-Daten. Die grüne Linie bedeutet richtige Antwort und die rote Linie bedeutet falsche Antwort.
Das anfängliche Vermögen betrug 10.000 USD, die Transaktionseinheit 10.000 Währungen, die Provision (Spread) 0 und der endgültige Gewinn plus 1197 USD. Selbst wenn Sie den Spread auf durchschnittlich 2 Pips einstellen, liegt er immer noch bei 900 US-Dollar.
Es sieht auf den ersten Blick gut aus, aber ... Es scheint, dass das Modell und die Datenauswahl nicht gut sind, aber einfach gut passen, da eine Änderung der Trainingsperiode sie schnell ruiniert.
Ich habe ein Notizbuch auf GitHub, also probieren Sie es aus. https://github.com/hayatoy/ml-forex-prediction
Recommended Posts