[PYTHON] Vergleichen Sie die Implementierungsbeispiele für scikit-learn und pyclustering k-means
Einführung
Der De-facto-Standard für die Implementierung von maschinellem Lernen in Python ist Scikit-Learn, aber Pyclustering ist eine Option, da einige der juckenden Teile des Clusters nicht in Reichweite sind.
Pyclustering ist jedoch im Vergleich zu Scicit-Learn etwas schwierig zu verwenden. Daher werde ich die grundlegendsten Implementierungsbeispiele in k-means zusammenfassen, um daran zu erinnern, wie es verwendet wird.
Ausführungsbeispiel von K-means
Nutzungsdaten
Datendefinition
from sklearn.datasets import make_blobs
X, _ = make_blobs(n_features=2, centers=5, random_state=1)
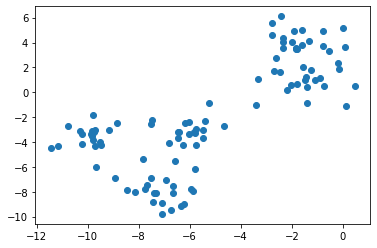
Streudiagramm
import matplotlib.pyplot as plt
plt.scatter(X[:, 0], X[:, 1])
scikit-learn
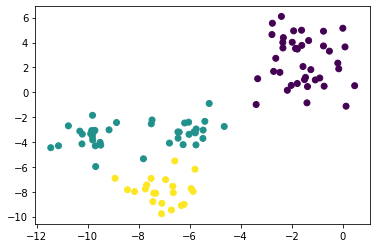
Die Implementierung von k-means mit scikit-learn ist wie folgt.
Die Methode zur Einstellung des Anfangswertes in scikit-learn kann mit der Option init eingestellt werden, und ha ist die Standardeinstellung.
Es ist k-means ++.
scikit-k in lernen-means
from sklearn.cluster import KMeans
sk_km = KMeans(n_clusters=3).fit(X)
plt.scatter(X[:, 0], X[:, 1], c=sk_km.labels_)
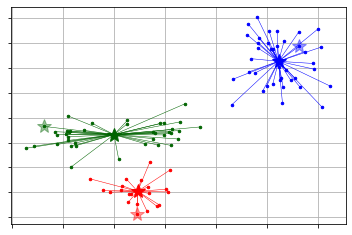
pyclustering
Die Implementierung von k-Mitteln unter Verwendung von Pyclustering ist wie folgt.
Im Gegensatz zu Scikit-Learn müssen die Anfangswerteinstellung und das nachfolgende Cluster-Lernen separat angegeben werden. Wenn Sie später die hier bereitgestellte Visualisierungsfunktion verwenden, werden die Informationen etwas umfangreicher.
from pyclustering.cluster import kmeans
from pyclustering.cluster.center_initializer import kmeans_plusplus_initializer
initial_centers = kmeans_plusplus_initializer(X, 3).initialize() # k-means++Anfangswerteinstellung mit
pc_km = kmeans.kmeans(X, initial_centers) #Definition der kmeans-Klasse
pc_km.process() #Ausführung des Lernens
_ = kmeans.kmeans_visualizer.show_clusters(X, pc_km.get_clusters(), pc_km.get_centers(), initial_centers=initial_centers) #Visualisierung
Die durch Pyclustering erhaltenen Cluster können mit den Methoden "Predict" und "Get_clusters" referenziert werden.
Predict gibt eine Bezeichnung für die Eingabedaten zurück, ähnlich wie bei Scicit-Learn.
get_clusters gibt den Index für die Daten zurück, die für das Training durch den Cluster verwendet werden. Dies ist nicht für den Umgang mit Pandas usw. geeignet, daher muss es separat verarbeitet werden. (Einfacher zu verwenden, vorherzusagen)
Abrufen der Clusternummer mithilfe von "Vorhersagen"(1)
labels = pc_km.predict(X)
get_Abrufen der Clusternummer mithilfe von Clustern
import numpy as np
clusters = pc_km.get_clusters()
labels = np.zeros((np.concatenate([np.array(x) for x in clusters]).size, ))
for i, label_index in enumerate(clusters):
labels[label_index] = i
Bestimmen der Anzahl der Cluster
scikit-learn
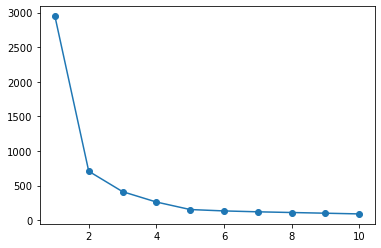
Die Ellbogenmethode beim Scikit-Lernen wird gezeigt.
Eine Silhouette-Analyse ist ebenfalls möglich, wird jedoch weggelassen, da die Implementierung wie Pyclustering kompliziert sein wird.
In beiden Fällen kann die Anzahl der Cluster nicht automatisch ermittelt werden und muss nach Bestätigung durch den Analysten ermittelt werden.
Ellbogenmethode
sse = list()
for i in range(1, 11):
km = KMeans(n_clusters=i).fit(X)
sse.append(km.inertia_)
plt.plot(range(1, 11), sse, 'o-')
pyclustering
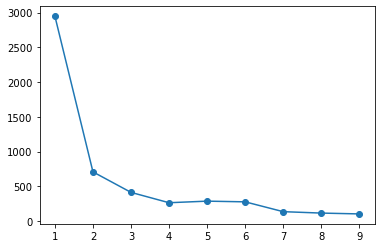
Im Fall von Pyclustering bestimmt die Ellbogenmethode sogar die Anzahl der Cluster. Was die Anzahl der Cluster betrifft, so scheint es, dass die Anzahl der Cluster, in denen die Summe der quadratischen Fehler im Cluster innerhalb des Suchbereichs stark reduziert ist, übernommen wird.
Ellbogenmethode
from pyclustering.cluster.elbow import elbow
kmin, kmax = 1, 10 #Zu suchender Wertebereich
elb = elbow(X, kmin=kmin, kmax=kmax) #Der Suchbereich ist kmin~kmax-Beachten Sie bis zu 1
elb.process()
elb.get_amount() #Sie können die Anzahl der Cluster sehen
plt.plot(range(kmin, kmax), elb.get_wce())
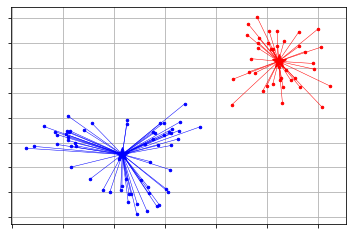
Da Pyclustering x-means und g-means unterstützt, können Sie es auch verwenden.
x-means
from pyclustering.cluster import xmeans
from pyclustering.cluster.kmeans import kmeans_visualizer
initial_centers = xmeans.kmeans_plusplus_initializer(X, 2).initialize() # k=Suche mit 2 oder mehr
xm = xmeans.xmeans(X, initial_centers=initial_centers, )
xm.process()
_ = kmeans_visualizer.show_clusters(X, xm.get_clusters(), xm.get_centers())
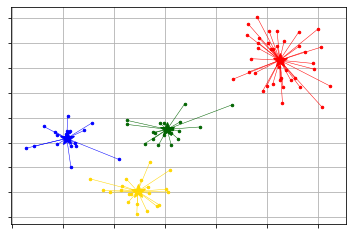
g-means
from pyclustering.cluster import gmeans
from pyclustering.cluster.kmeans import kmeans_visualizer
initial_centers = gmeans.kmeans_plusplus_initializer(X, 2).initialize()
gm = gmeans.gmeans(X, initial_centers=initial_centers, )
gm.process()
_ = kmeans_visualizer.show_clusters(X, gm.get_clusters(), gm.get_centers())
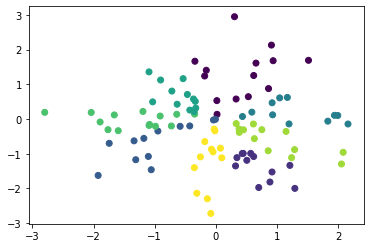
Vorteile von Pyclustering gegenüber Scikit-Learn
Scikit-Learn ist die beste Wahl für niedrige Schwellenwerte, aber Pyclustering ist überlegen, wenn Sie den Clustering-Algorithmus optimieren möchten.
Viele Algorithmen, die Pyclustering unterstützen, werden in erster Linie unterstützt, und der Verarbeitungsinhalt kann detailliert definiert werden. Beispielsweise kann die Entfernungsdefinition von euklidischer Entfernung zu Manhattan-Entfernung oder benutzerdefiniertem Entfernungsindex geändert werden.
Das Folgende ist ein Beispiel für die Durchführung von Clusterphosphor im Kosinusabstand.
- Wenn Sie dies nur mit Kosinusabstand tun, ist Sphärecluster einfacher
Kosinusabstand k-means
import numpy as np
from pyclustering.cluster import kmeans
from pyclustering.cluster.center_initializer import kmeans_plusplus_initializer
from pyclustering.utils.metric import distance_metric, type_metric
X = np.random.normal(size=(100, 2))
def cosine_distance(x1, x2):
if len(x1.shape) == 1:
return 1 - np.dot(x1, x2) / (np.linalg.norm(x1) * np.linalg.norm(x2))
else:
return 1 - np.sum(np.multiply(x1, x2), axis=1) / (np.linalg.norm(x1, axis=1) * np.linalg.norm(x2, axis=1))
initial_centers = kmeans_plusplus_initializer(X, 8).initialize()
pc_km = kmeans.kmeans(X, initial_centers, metric=distance_metric(type_metric.USER_DEFINED, func=cosine_distance))
pc_km.process()
plt.scatter(X[:, 0], X[:, 1], c=pc_km.predict(X))
Referenz
- Wickeln Sie einen Teil der Pyclustering-Mittel wie sklearn ein
- So finden Sie die optimale Anzahl von Clustern für k-means
- Selecting the number of clusters with silhouette analysis on KMeans clustering — scikit-learn 0.22.2 documentation
- pyclustering.cluster.elbow.elbow Class Reference
- Clustering G-bedeutet, dass die Anzahl der Cluster automatisch bestimmt wird
Recommended Posts