Eine Geschichte, die es einfach macht, den Wohnbereich mit Elasticsearch und Python abzuschätzen
Überblick
Durch die Registrierung der Standortinformationen des Aktionsverlaufs in Elasticsearch werde ich darüber sprechen, wie diese auf nette Weise verwendet und auch auf nette Weise visualisiert werden können.
Vorausgesetztes Wissen

Ich werde dieses Mal die elastische Suche verwenden, daher werde ich sie kurz vorstellen. Elasticsearch ist eine der Volltextsuchmaschinen, die häufig mit Apache Solr verglichen werden. Es ist schemafrei und alle Ein- und Ausgänge sind REST & JSON. Es ist auch in Java implementiert.
- Für Details Einführung und Funktionen von Elasticsearch
Die Installation ist entweder mit Yum oder Brew einfach. Bitte überprüfen Sie entsprechend der Umgebung, die Sie verwenden möchten. Übrigens ist elasticsearch-head, ein GUI-Plug-In für Elasticsearch, praktisch, daher ist es eine gute Idee, es auch einzuschließen.
Elasticsearch-Einstellungen
Legen Sie nach dem Start von Elasticsearch den zu verwendenden Index fest (wie eine Tabelle in der Datenbank). Erstellen Sie zu diesem Zweck zunächst eine Indexzuordnungsmethode mit json. Dieses Mal wird davon ausgegangen, dass ein Protokoll des folgenden Datensatzes vorhanden ist.
sample_log
{
"id":1,
"uuid":"7ef82126c32c55f7272d5ca5dd5e40c6",
"time":"2015-12-03T04:21:01.641Z",
"lat":35.658546,
"lng":139.729281,
"accuracy":47.126048
}
Stellen Sie den Typ für jedes Feld so ein, dass ein solcher Datensatz gut zugeordnet werden kann. Dieses Mal habe ich das Mapping wie folgt eingestellt. Es ist ein Bild, dass die Zuordnung des Dateityps namens Geo festgelegt wird.
geo_mapping.json
{
"geo" : {
"properties" : {
"id" : {
"type" : "integer"
},
"uuid" : {
"type" : "string",
"index" : "not_analyzed"
},
"time" : {
"type" : "date",
"format" : "date_time"
},
"location" : {
"type" : "geo_point"
},
"accuracy" : {
"type" : "double"
}
}
}
}
Um es ein wenig zu erklären, wird das uuid-Feld auf "not_analyzed" gesetzt, da es sich um einen eindeutigen Wert handelt und Sie ihn nicht morphologisch analysieren möchten. Diesmal ist auch die Art des Standortfeldes wichtig. geo_point ist ein von Elasticsearch bereitgestellter Typ, und Längen- und Breitengrad werden als Satz registriert. Sie können es verwenden, indem Sie. Durch Festlegen des Typs dieses Felds können Sie bequem suchen. Dazu später mehr.
Nachdem Sie die Zuordnungseinstellungen erstellt haben, erstellen Sie damit den Index. Der Indexname lautet diesmal `` `test_geo```. Wenn Sie die folgende Locke werfen, während Elasticsearch ausgeführt wird, ist die Erstellung abgeschlossen.
Index erstellen
curl -XPOST 'localhost:9200/test_geo' -d @geo_mapping.json
Datenregistrierung
Angenommen, Sie haben die Daten als Protokolldatei, registrieren Sie die Daten in dem Index, der aus der Protokolldatei erstellt wurde. Diesmal gibt es einen offiziellen Python-Client. Verwenden wir ihn also.
--Offiziell: [elasticsearch-py] (https://www.elastic.co/guide/en/elasticsearch/client/python-api/current/index.html)
Es ist einfach mit pip zu installieren.
Installation
pip install elasticsearch
Das damit zu registrierende Programm lautet wie folgt.
regist_es.py
import json
import sys
from elasticsearch import Elasticsearch
es = Elasticsearch()
index = "test_geo"
doc_type = "geo"
f = open('var/logs.json', 'r')
_line = f.readline()
while _line:
data = json.loads(_line)
_line = f.readline()
f.close()
for value in data:
lat = value['lat']
lon = value['lng']
del value['lat']
del value['lng']
value.update({
"location" : {
"lat" : lat,
"lon" : lon
}
})
es.index(index=index, doc_type=doc_type, body=value, id=value['id'])
Der zu beachtende Punkt ist, dass `lat``` und` lon zu `` location kombiniert werden, um es für `` `geo_point``` geeignet zu machen ..
Wenn Sie dieses Programm ausführen, werden die Informationen zum Aktionsverlauf in logs.json in Elasticsearch registriert. Es ist sehr leicht.
Visualisiert mit Kibana
Nachdem die Daten registriert wurden, ist es Zeit zu kochen oder zu backen. Kibana ist ein offizielles Visualisierungstool, das die in Elasticsearch registrierten Daten visualisiert. Kibana4 ist ab sofort erhältlich, daher halte ich es für eine gute Idee, die neueste Version zu erwerben. Sobald Sie es erhalten haben, führen Sie einfach `` `. / Bin / kibana``` aus und der HTTP-Server startet an Port 5601. Detaillierte Einstellungsmethode usw.. Nachdem Sie es tatsächlich gestartet haben, können Sie das Dashboard festlegen, indem Sie mit einem geeigneten Browser darauf zugreifen. Wenn Sie damit herumspielen, können Sie ganz einfach eine Heatmap wie die folgende erstellen.
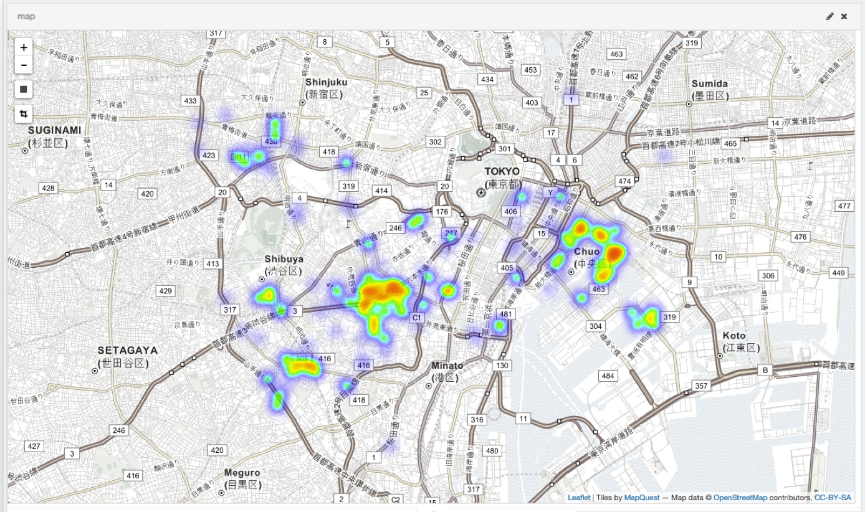

Schätzung der Wohnfläche
Da ich die Daten mit viel Aufwand registriert habe, werde ich versuchen, sie zu verwenden. Diesmal in diesem Dokument (Informationsempfehlungssystem unter Verwendung von Standortinformationen für mobile Endgeräte) Ich werde versuchen, den Wohnbereich abzuschätzen. Da die Standortinformationen bei `` `geo_type``` registriert sind, kann die folgende Abfrage wie das Erfassen von Daten innerhalb weniger Kilometer von einem bestimmten Standort ausgelöst werden.
python
query = {
"from":0,
"query": {
"filtered" : {
"query" : {
"simple_query_string" : {
"query" : uuid,
"fields" : ["uuid"],
}
},
"filter" : {
"geo_distance" : {
"distance" : 10 + 'km',
"geo.location" : {
"lat" : lat,
"lon" : lon
}
}
}
}
}
}
Die Ergebnisse der Wohnflächenschätzung unter Verwendung dieser sind wie folgt.
Beispielergebnis
Stage1
35.653945 , 139.716692
Radius(km): 5.90
Stage2
35.647367 , 139.709346
Radius(km): 1.61
Bei Verwendung des Schwerpunkts
35.691165 , 139.709840
Radius(km): 8.22
Mittag: (104)
35.696822 , 139.708228
Radius(km): 9.61
Nacht: (97)
35.685100 , 139.711568
Radius(km): 6.77
Nächste Station(Mittag):Higashi Shinjuku
Nächste Station(Nacht):Shinjuku Gyoenmae
Impressionen
Elasticsearch ist sehr einfach einzurichten und zu verwenden. Elasticsearch ist unglaublich. Kibana ist unglaublich. Darüber hinaus scheint es ein neues Produkt zu geben (Beats). Dies hängt von der Datenmenge ab, es ist jedoch zweckmäßig, sich vorerst bei Elasticsearch zu registrieren. Protokolle können automatisch bei fluentd registriert werden, sodass Sie anscheinend verschiedene Dinge tun können, indem Sie sie kombinieren.
_ Schwer zu schreibende Artikel ... _
Recommended Posts