[PYTHON] Schätzen Sie die Wahrscheinlichkeit, dass eine Münze mit MCMC erscheint
Schätzen Sie die Wahrscheinlichkeit, dass eine Münze mit MCMC erscheint
Überblick
Für das Studium von MCMC. Als einfachstes Beispiel habe ich versucht, die posteriore Verteilung von Parametern im Bernoulli-Prozess mithilfe von MCMC und Beta-Verteilung zu ermitteln.
MCMC-Übersicht
MCMC-Methode (Markov Chain Monte Carlo) in der Bayes'schen Statistik Ist eine Methode zum Ermitteln der posterioren Verteilung unter Verwendung von Zufallszahlen.
Die hintere Verteilung verwendet den Satz von Bayes
Posteriore Verteilung = (Wahrscheinlichkeit * vorherige Verteilung) / (Wahrscheinlichkeit, Daten zu erhalten)
Kann erhalten werden von. Das Problem hierbei ist, dass die Wahrscheinlichkeit p (D), mit der die Nennerdaten auf der rechten Seite erhalten werden können, durch Integrieren und Eliminieren unter Verwendung des Parameters $ \ theta $ erhalten werden kann. Mit zunehmender Anzahl der Dimensionen des Parameters müssen jedoch mehrere Mehrfachintegrationen durchgeführt werden. Es ist möglich, einen ungefähren integrierten Wert unter Verwendung der statischen Monte-Carlo-Methode zu erhalten, aber die Genauigkeit nimmt mit zunehmender Anzahl von Dimensionen ab. Daher gab MCMC die Berechnung der Wahrscheinlichkeit des Erhaltens von Daten auf und schätzte die hintere Verteilung nur aus der Wahrscheinlichkeit und der vorherigen Verteilung.
Mit MCMC können Sie eine Stichprobe erhalten, die proportional zum Wert der Funktion ist. Wenn daher die Wahrscheinlichkeit * der vorherigen Verteilung von MCMC abgetastet und normalisiert wird, so dass der integrierte Wert 1 wird, wird dies die hintere Verteilung.
Dieses Mal finden wir die Wahrscheinlichkeitsdichtefunktion, mit der die Münze aus den Daten hervorgeht, die durch mehrmaliges Werfen der Münze erhalten wurden. Dies ist der einfachste Fall für das Studium.
Haftung
Lassen Sie die Wahrscheinlichkeit, dass Münzen als $ \ mu $ erscheinen Angenommen, Cointos erhält in einem unabhängigen Versuch eine {0,1} Menge D.
Zu diesem Zeitpunkt ist die Wahrscheinlichkeit
Vorherige Verteilung
Die vorherige Verteilung nimmt einen einheitlichen Wert an, da sie keine vorherigen Informationen über die Münze enthält. Sei p ($ \ mu $) = 1.
Ex-post-Verteilung
Verwenden Sie MCMC
Die Abtastung wird durchgeführt, indem eine vorbestimmte Anzahl von Malen gemäß dem folgenden Verfahren wiederholt wird.
- Wählen Sie den Anfangswert des Parameters $ \ mu $
- Verschieben Sie $ \ mu $ nach dem Zufallsprinzip um einen kleinen Betrag, um $ \ mu_ {new} $ zu erhalten
- Wenn (Wahrscheinlichkeit * vorherige Verteilung) infolge des Verschiebens groß wird, aktualisieren Sie $ \ mu $ für den verschobenen Wert auf $ \ mu_ {new} $ → gehen Sie zu 2.
- (Haftung*Vorherige Verteilung)Wenn wird kleiner(P(D|
\mu_{new} )P(\mu_{new} )/(P(D|\mu )P(\mu )Mit einer Wahrscheinlichkeit von\mu Update → 2.Was
Das Histogramm der erhaltenen Probe wird integriert und auf 1 normalisiert, um die posteriore Verteilung zu erhalten.
Analytisch finden
Da es sich bei diesem Modell um einen Bernoulli-Prozess handelt, wird unter der Annahme, dass die Beta-Verteilung eine vorherige Verteilung ist, Die posteriore Verteilung kann einfach durch Aktualisieren der Beta-Verteilungsparameter erhalten werden.
Sei m die Häufigkeit, mit der die Vorderseite der Münze erscheint, l die Häufigkeit, mit der die Münze erscheint, und seien a und b vorgegebene Parameter
$p(\mu|m,l,a,b) = beta(m+a,l+b) $
Wird sein. Wenn die vorherige Verteilung eine informationslose vorherige Verteilung ist, setzen Sie a = b = 1.
Programm
Ich habe es in Python geschrieben. Ich denke, es wird funktionieren, wenn Anakonda enthalten ist. Es ist überhaupt nicht schnell, weil es die Lesbarkeit betont.
# coding:utf-8
from scipy.stats import beta
import matplotlib.pyplot as plt
import numpy as np
def priorDistribution(mu):
if 0 < mu < 1:
return 1
else:
return 10 ** -9
def logLikelihood(mu, D):
if 0 < mu < 1:
return np.sum(D * np.log(mu) + (1 - D) * np.log(1 - mu))
else:
return -np.inf
np.random.seed(0)
sample = 0.5
sample_list = []
burnin_ratio = 0.1
N = 10
# make data
D = np.array([1, 0, 1, 1, 0, 1, 0, 1, 0, 0])
l = logLikelihood(sample, D) + np.log(priorDistribution(sample))
# Start MCMC
for i in range(10 ** 6):
# make candidate sample
sample_candidate = np.random.normal(sample, 10 ** -2)
l_new = logLikelihood(sample_candidate, D) + \
np.log(priorDistribution(sample_candidate))
# decide accept
if min(1, np.exp(l_new - l)) > np.random.random():
sample = sample_candidate
l = l_new
sample_list.append(sample)
sample_list = np.array(sample_list)
sample_list = sample_list[int(burnin_ratio * N):]
# calc beta
x = np.linspace(0, 1, 1000)
y = beta.pdf(x, sum(D) + 1, N - sum(D) + 1)
plt.plot(x, y, linewidth=3)
plt.hist(sample_list, normed=True, bins=100)
plt.show()
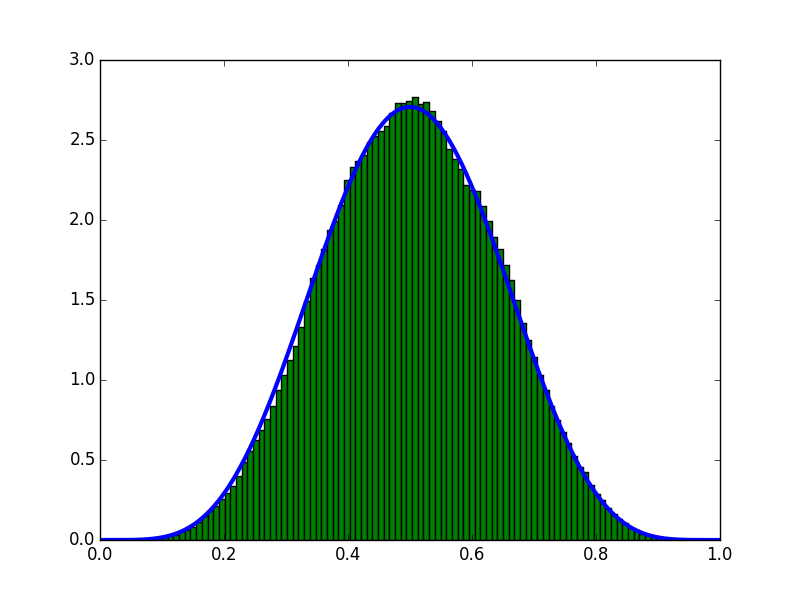
Ausführungsergebnis
Geschätzt unter der Bedingung, dass 10 Proben (5 vorne und 5 hinten) erhalten wurden.
Die blaue Linie ist der analytisch erhaltene Graph, und das Histogramm ist der von MCMC erhaltene Graph.
Wenn Sie sich das Diagramm ansehen, können Sie sehen, dass es gut geschätzt wird.
Zusammenfassung
Dieses Mal fand ich die Parameter der Bernoulli-Verteilung durch Handschrift von Python und Verwendung von MCMC, was eine sehr ineffiziente Methode ist. Es war eine Problemstellung, die den Vorteil von MCMC ohne vorherige Informationsverteilung und eine Variable mit einem Definitionsbereich von [0,1] nicht erhalten konnte. Wenn jedoch die Wahrscheinlichkeit (das Modell) definiert werden kann, kann die hintere Verteilung auf einen Personal Computer übertragen werden. Ich konnte mir vorstellen, dass ich es bekommen könnte.
Wenn Sie MCMC tatsächlich verwenden, ist es eine gute Idee, eine optimierte Bibliothek wie Stan oder PyMC zu verwenden.
Wenn Sie mit verschiedenen früheren Verteilungen und Parametern herumspielen, können Sie möglicherweise die einzigartigen Eigenschaften der Bayes'schen Schätzung verstehen. Je größer die Anzahl der beobachteten Daten ist, desto kleiner ist die Breite der Verteilung und desto geringer ist der Effekt der vorherigen Verteilung.
Verweise
Eine Einführung in die statistische Modellierung für die Datenanalyse http://hosho.ees.hokudai.ac.jp/~kubo/stat/2013/ou3/kubostat2013ou3.pdf http://tjo.hatenablog.com/entry/2014/02/08/173324
Recommended Posts