Dies ist eine Ausbildung zum Datenwissenschaftler mit Python.
Lassen Sie uns zum Schluss Pandas machen, einen der drei heiligen Schätze.
Pandas ist Pythons leistungsstärkstes Datenanalysepaket.
Dies ist sehr praktisch, da Sie mit Excel alles tun können, was Sie können. (Sie können Dinge tun, die Excel nicht kann)
Es passt gut zu Numpy und Matplotlib und kann nahtlos verwendet werden.
Ich denke, es ist am besten, das unten beschriebene IPython-Notizbuch zu verwenden, um Python-Programme mit Pandas auszuführen.
** PREV ** → [Python] Weg zur Schlange (5) Spiel mit Matplotlib
** WEITER ** → Anwendung von Pandas (so bald wie möglich)
Es visualisiert DataFrames und Grafiken auf wundervolle Weise. tolle.
Pandas Datenstruktur
Pandas hat drei Datenstrukturen.
- Eindimensionales Array: Serie
- Zweidimensionales Array: DataFrame
- Dreidimensionales Array: Panel
Lassen Sie uns diese aus Numpys Array generieren.
Serienbeispiel (1D)
Python
import numpy as np
import pandas as pd
Python
# Series
a1 = np.arange(2)
idx = pd.Index(['A', 'B'], name = 'index')
series = pd.Series(a1, index=idx)
series
index
A 0
B 1
dtype: int64
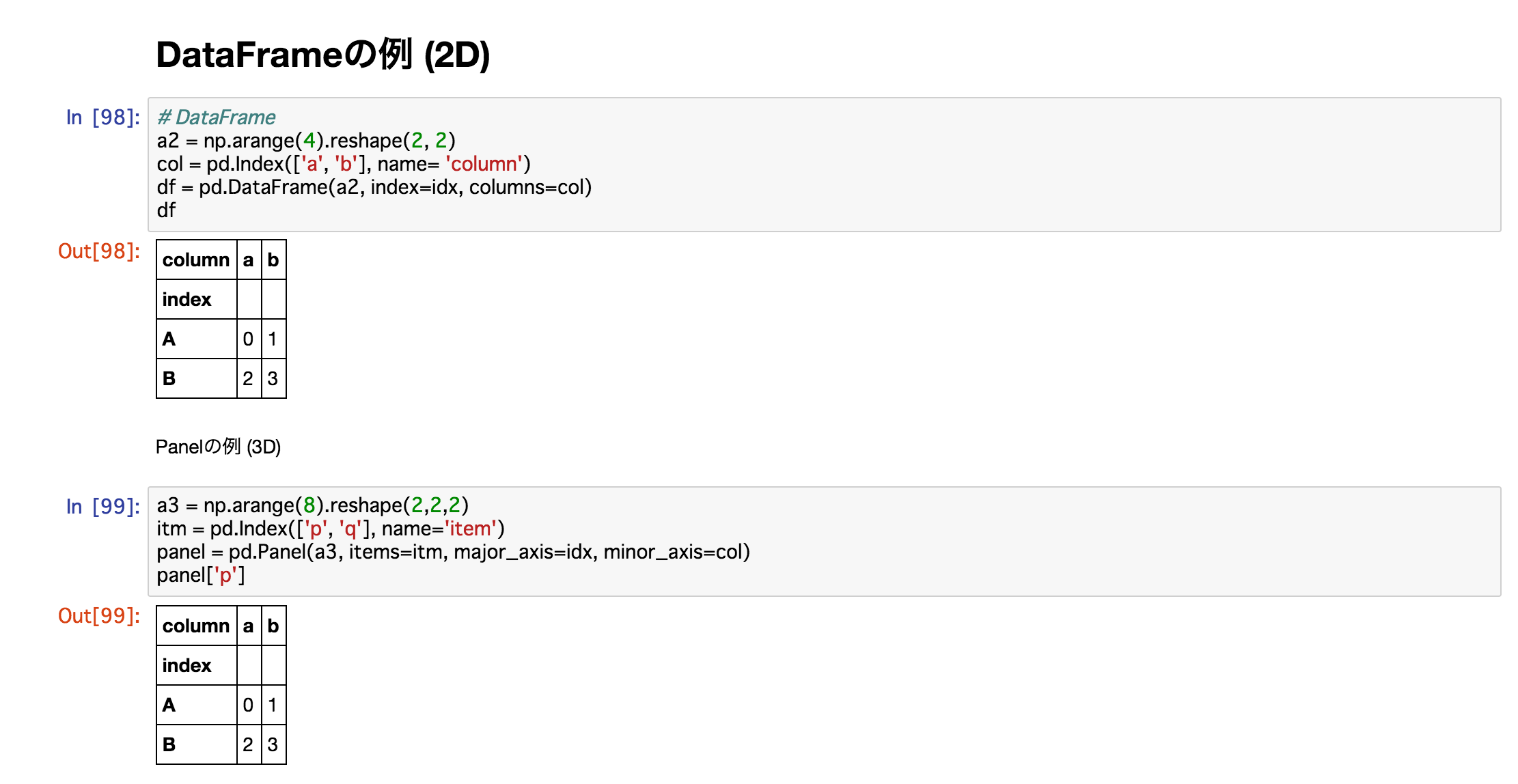
DataFrame-Beispiel (2D)
Python
# DataFrame
a2 = np.arange(4).reshape(2, 2)
col = pd.Index(['a', 'b'], name= 'column')
df = pd.DataFrame(a2, index=idx, columns=col)
df
| column |
a |
b |
| index |
|
|
| A |
0 |
1 |
| B |
2 |
3 |
Panel Beispiel (3D)
Python
a3 = np.arange(8).reshape(2,2,2)
itm = pd.Index(['p', 'q'], name='item')
panel = pd.Panel(a3, items=itm, major_axis=idx, minor_axis=col)
panel['p']
| column |
a |
b |
| index |
|
|
| A |
0 |
1 |
| B |
2 |
3 |
Python
panel['q']
| column |
a |
b |
| index |
|
|
| A |
4 |
5 |
| B |
6 |
7 |
Beispiel einer Serie mit Doppelindex (effektiv 2D)
Python
a1=np.arange(4)
idx = pd.MultiIndex.from_product([['A','B'],['a','b']], names=('i','j'))
series2 = pd.Series(a1, index=idx)
series2
#Ab, selbst wenn die Vielzahl der Achsen 3 oder mehr beträgt_Produkt kann verwendet werden.
# pd.MultiIndex.from_product([['A', 'B'],['a', 'b'],['1', '2']], names=('i', 'j', 'k'))
i j
A a 0
b 1
B a 2
b 3
dtype: int64
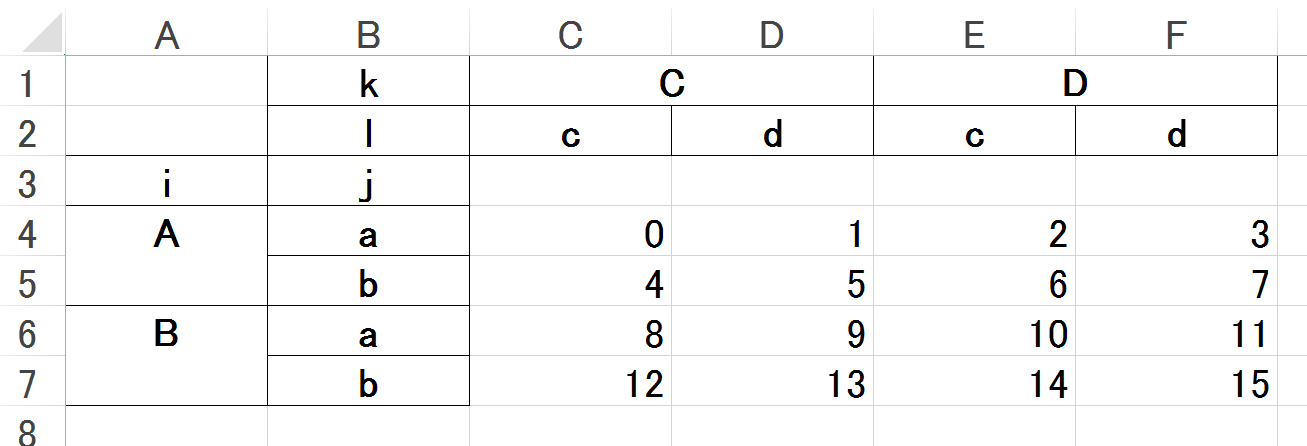
Beispiel eines DataFrame mit Doppelindex (effektiv 4D)
Python
a2 = np.arange(16) .reshape(4,4)
idx = pd.MultiIndex.from_product( [['A','B'],['a','b']], names=('i','j'))
col = pd.MultiIndex.from_product( [['C','D'],['c','d']], names=('k','l'))
df = pd.DataFrame(a2, index=idx, columns=col)
df
|
k |
C |
D |
|
l |
c |
d |
c |
d |
| i |
j |
|
|
|
|
| A |
a |
0 |
1 |
2 |
3 |
| b |
4 |
5 |
6 |
7 |
| B |
a |
8 |
9 |
10 |
11 |
| b |
12 |
13 |
14 |
15 |
Obwohl diesmal weggelassen, kann Panel auf die gleiche Weise auch mehrere Indizes haben.
Zugriff auf Daten (Indizierung)
Der große Unterschied zwischen Pandas und Numpy besteht darin, dass das Indexkonzept von Numpy bei Pandas ausgefeilter ist.
Vergleichen wir das vorherige zweidimensionale Array mit Numpy und Pandas DataFrame.
Python
a2 = np.arange(4).reshape(2, 2)
a2
array([[0, 1],
[2, 3]])
Python
idx = pd.Index(['A', 'B'], name='index')
col = pd.Index(['a', 'b'], name='column')
df = pd.DataFrame(a2, index=idx, columns=col)
df
| column |
a |
b |
| index |
|
|
| A |
0 |
1 |
| B |
2 |
3 |
Die Zeilen sind mit A und B und die Spalten mit a bzw. b gekennzeichnet, die Pandas als Index verwenden können.
Dies wird als ** label-based index ** bezeichnet.
Andererseits wird der in Numpy verwendete Index von Ganzzahlen ab 0 als ** positionsbasierter Index ** bezeichnet.
Beide sind in Pandas verfügbar.
Python
a2[1, 1]
3
Python
df.ix[1, 1]
3
Python
df.ix['B', 'b']
3
Da ** Label-basierter Index ** der Schlüssel des Diktats und ** Positions-basierter Index ** der Index der Liste ist, kann davon ausgegangen werden, dass Pandas sowohl Diktat- als auch Listeneigenschaften hat. Ich kann es schaffen
Natürlich sind Slice-, Fancy-Indizierung und Boolesche Indizierung ebenso möglich wie Numpy.
slice
Python
df = pd.DataFrame( np.arange(16).reshape(4, 4), index=list('ABCD'),columns=list('abcd'))
df
|
a |
b |
c |
d |
| A |
0 |
1 |
2 |
3 |
| B |
4 |
5 |
6 |
7 |
| C |
8 |
9 |
10 |
11 |
| D |
12 |
13 |
14 |
15 |
Python
#Erste Zeile und höher,Weniger als 3. Zeile
df.ix[1:3]
|
a |
b |
c |
d |
| B |
4 |
5 |
6 |
7 |
| C |
8 |
9 |
10 |
11 |
Python
#Zeile A und höher,Zeile C und darunter
# label-Für basierten Index nicht weniger als
df.ix['A' : 'C']
|
a |
b |
c |
d |
| A |
0 |
1 |
2 |
3 |
| B |
4 |
5 |
6 |
7 |
| C |
8 |
9 |
10 |
11 |
fancy indexing
Python
#Geben Sie mehrere Zeilen an
df.ix[['A', 'B', 'D']]
|
a |
b |
c |
d |
| A |
0 |
1 |
2 |
3 |
| B |
4 |
5 |
6 |
7 |
| D |
12 |
13 |
14 |
15 |
Python
#Geben Sie mehrere Spalten an
df[[ 'b', 'd']]
|
b |
d |
| A |
1 |
3 |
| B |
5 |
7 |
| C |
9 |
11 |
| D |
13 |
15 |
boolean indexing
Python
#Siehe Zeile, die wahr ist
df.ix[[True, False, True]]
|
a |
b |
c |
d |
| A |
0 |
1 |
2 |
3 |
| C |
8 |
9 |
10 |
11 |
Python
#Siehe Spalte True
df.ix[:,[True, False, True]]
|
a |
c |
| A |
0 |
2 |
| B |
4 |
6 |
| C |
8 |
10 |
| D |
12 |
14 |
Python
#Siehe die Zeile, in der der doppelte a-Wert größer als der c-Wert ist
df.ix[df['a']*2 > df['c']]
|
a |
b |
c |
d |
| B |
4 |
5 |
6 |
7 |
| C |
8 |
9 |
10 |
11 |
| D |
12 |
13 |
14 |
15 |
Achsen- und Indexmanipulation
Einführung in das Austauschen, Verschieben, Umbenennen von Indizes, Sortieren von Indizes usw., die für die Verwendung von Pandas wichtig sind.
Achsen tauschen
Python
a2 = np.arange(4) .reshape(2, 2)
idx = pd.Index(['A', 'B'], name='index')
col = pd.Index(['a', 'b'], name='column')
df = pd.DataFrame(a2, index=idx,columns=col)
df
| column |
a |
b |
| index |
|
|
| A |
0 |
1 |
| B |
2 |
3 |
Python
#Achse 0(Linie)Und die erste Achse(Säule)Ersetzen
df.swapaxes(0, 1)
| index |
A |
B |
| column |
|
|
| a |
0 |
2 |
| b |
1 |
3 |
Python
#Inversion für 2D(T)Auch wenn es das gleiche ist
df.T # transpose()Abkürzung für
| index |
A |
B |
| column |
|
|
| a |
0 |
2 |
| b |
1 |
3 |
Achsenbewegung (Stapeln / Entstapeln)
Python
#Die Spalte wurde zur Zeilenseite verschoben
df.stack()
index column
A a 0
b 1
B a 2
b 3
dtype: int64
Python
#Zeile wird zur Spaltenseite verschoben
df.unstack()
column index
a A 0
B 2
b A 1
B 3
dtype: int64
Python
#stack()Und entstapeln()Handelt es sich um die umgekehrte Operation. Wenn Sie diese beiden Operationen wiederholen, wird zum Original zurückgekehrt
df.stack().unstack()
| column |
a |
b |
| index |
|
|
| A |
0 |
1 |
| B |
2 |
3 |
Wenn die Zeile zur Spaltenseite verschoben wird, wird die Spalte durch einen Doppelindex dargestellt.
Wenn Sie einen (nicht gemultiplexten) DataFrame stapeln () oder entstapeln (), ist die Ausgabe für beide Serien.
Achsen tauschen
Python
a2 = np.arange(64).reshape(8,8)
idx = pd.MultiIndex.from_product( [['A','B'],['C','D'],['E','F']],names=list('ijk'))
col = pd.MultiIndex.from_product([['a','b'],['c','d'],['e','f']],names=list('xyz'))
df = pd.DataFrame(a2, index=idx,columns=col)
df
|
|
x |
a |
b |
|
|
y |
c |
d |
c |
d |
|
|
z |
e |
f |
e |
f |
e |
f |
e |
f |
| i |
j |
k |
|
|
|
|
|
|
|
|
| A |
C |
E |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
| F |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
| D |
E |
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
| F |
24 |
25 |
26 |
27 |
28 |
29 |
30 |
31 |
| B |
C |
E |
32 |
33 |
34 |
35 |
36 |
37 |
38 |
39 |
| F |
40 |
41 |
42 |
43 |
44 |
45 |
46 |
47 |
| D |
E |
48 |
49 |
50 |
51 |
52 |
53 |
54 |
55 |
| F |
56 |
57 |
58 |
59 |
60 |
61 |
62 |
63 |
Dies ist ein Beispiel, bei dem jede Achse 3 Ebenen (3 Ebenen) hat, Swapaxes () jedoch alle Ebenen vollständig ersetzt.
Python
df.swapaxes(0,1)
|
|
i |
A |
B |
|
|
j |
C |
D |
C |
D |
|
|
k |
E |
F |
E |
F |
E |
F |
E |
F |
| x |
y |
z |
|
|
|
|
|
|
|
|
| a |
c |
e |
0 |
8 |
16 |
24 |
32 |
40 |
48 |
56 |
| f |
1 |
9 |
17 |
25 |
33 |
41 |
49 |
57 |
| d |
e |
2 |
10 |
18 |
26 |
34 |
42 |
50 |
58 |
| f |
3 |
11 |
19 |
27 |
35 |
43 |
51 |
59 |
| b |
c |
e |
4 |
12 |
20 |
28 |
36 |
44 |
52 |
60 |
| f |
5 |
13 |
21 |
29 |
37 |
45 |
53 |
61 |
| d |
e |
6 |
14 |
22 |
30 |
38 |
46 |
54 |
62 |
| f |
7 |
15 |
23 |
31 |
39 |
47 |
55 |
63 |
Mehrere Achsen tauschen (swaplevel / reorder_levels)
Python
#Achse 0(Linie)Von der 0. Schicht(i)Und die zweite Ebene(z)Tauschen
df.reorder_levels([2, 1, 0])
# swaplevel(0, 2)Oder Swaplevel('i', 'z')Aber das gleiche
|
|
x |
a |
b |
|
|
y |
c |
d |
c |
d |
|
|
z |
e |
f |
e |
f |
e |
f |
e |
f |
| k |
j |
i |
|
|
|
|
|
|
|
|
| E |
C |
A |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
| F |
C |
A |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
| E |
D |
A |
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
| F |
D |
A |
24 |
25 |
26 |
27 |
28 |
29 |
30 |
31 |
| E |
C |
B |
32 |
33 |
34 |
35 |
36 |
37 |
38 |
39 |
| F |
C |
B |
40 |
41 |
42 |
43 |
44 |
45 |
46 |
47 |
| E |
D |
B |
48 |
49 |
50 |
51 |
52 |
53 |
54 |
55 |
| F |
D |
B |
56 |
57 |
58 |
59 |
60 |
61 |
62 |
63 |
Python
#1. Achse(Säule)Von der 0. Schicht(x)Und die erste Ebene(y)Tauschen
df.reorder_levels([1,0,2],axis=1)
# swaplevel(0, 1, axis=1)Oder Swaplevel('i', 'j', axis=1)Aber das gleiche
|
|
y |
c |
d |
c |
d |
|
|
x |
a |
a |
b |
b |
|
|
z |
e |
f |
e |
f |
e |
f |
e |
f |
| i |
j |
k |
|
|
|
|
|
|
|
|
| A |
C |
E |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
| F |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
| D |
E |
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
| F |
24 |
25 |
26 |
27 |
28 |
29 |
30 |
31 |
| B |
C |
E |
32 |
33 |
34 |
35 |
36 |
37 |
38 |
39 |
| F |
40 |
41 |
42 |
43 |
44 |
45 |
46 |
47 |
| D |
E |
48 |
49 |
50 |
51 |
52 |
53 |
54 |
55 |
| F |
56 |
57 |
58 |
59 |
60 |
61 |
62 |
63 |
Mehrachsenbewegung (Stapeln / Entstapeln)
stack () verschiebt die untere Ebene der Spaltenachse zur unteren Ebene der Zeilenachse.
Python
df.stack()
|
|
|
x |
a |
b |
|
|
|
y |
c |
d |
c |
d |
| i |
j |
k |
z |
|
|
|
|
| A |
C |
E |
e |
0 |
2 |
4 |
6 |
| f |
1 |
3 |
5 |
7 |
| F |
e |
8 |
10 |
12 |
14 |
| f |
9 |
11 |
13 |
15 |
| D |
E |
e |
16 |
18 |
20 |
22 |
| f |
17 |
19 |
21 |
23 |
| F |
e |
24 |
26 |
28 |
30 |
| f |
25 |
27 |
29 |
31 |
| B |
C |
E |
e |
32 |
34 |
36 |
38 |
| f |
33 |
35 |
37 |
39 |
| F |
e |
40 |
42 |
44 |
46 |
| f |
41 |
43 |
45 |
47 |
| D |
E |
e |
48 |
50 |
52 |
54 |
| f |
49 |
51 |
53 |
55 |
| F |
e |
56 |
58 |
60 |
62 |
| f |
57 |
59 |
61 |
63 |
unstack () verschiebt die untere Ebene der Zeilenachse auf die untere Ebene der Spaltenachse.
Python
df.unstack()
|
x |
a |
b |
|
y |
c |
d |
c |
d |
|
z |
e |
f |
e |
f |
e |
f |
e |
f |
|
k |
E |
F |
E |
F |
E |
F |
E |
F |
E |
F |
E |
F |
E |
F |
E |
F |
| i |
j |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| A |
C |
0 |
8 |
1 |
9 |
2 |
10 |
3 |
11 |
4 |
12 |
5 |
13 |
6 |
14 |
7 |
15 |
| D |
16 |
24 |
17 |
25 |
18 |
26 |
19 |
27 |
20 |
28 |
21 |
29 |
22 |
30 |
23 |
31 |
| B |
C |
32 |
40 |
33 |
41 |
34 |
42 |
35 |
43 |
36 |
44 |
37 |
45 |
38 |
46 |
39 |
47 |
| D |
48 |
56 |
49 |
57 |
50 |
58 |
51 |
59 |
52 |
60 |
53 |
61 |
54 |
62 |
55 |
63 |
Index umbenennen
Python
df = pd.DataFrame( [[90, 50], [60, 80]], index=['t', 'h'],columns=['m', 'e'])
df
Python
df.index.name='Name'
df.columns.name='Gegenstand'
df.rename(index=dict(t='Taro', h='Hanako'), columns=dict(m='Mathematik', e='Englisch'))
| Themen
| Mathematik
| Englisch
|
| Name
| |
|
| Taro
| 90 |
50 |
| Hanako
| 60 |
80 |
Nach Index sortieren
Python
df = pd.DataFrame (np.arange(9).reshape(3,3), index=['B','A','C'], columns=['c','b','a'])
df
|
c |
b |
a |
| B |
0 |
1 |
2 |
| A |
3 |
4 |
5 |
| C |
6 |
7 |
8 |
Python
#Zeilen nach Zeilenindex sortieren
df.sort_index(axis=0)
|
c |
b |
a |
| A |
3 |
4 |
5 |
| B |
0 |
1 |
2 |
| C |
6 |
7 |
8 |
Python
#Spalten nach Spaltenindex sortieren
df.sort_index(axis=0).sort_index(axis=1)
|
a |
b |
c |
| A |
5 |
4 |
3 |
| B |
2 |
1 |
0 |
| C |
8 |
7 |
6 |
Datenkonvertierung
Seriendatenkonvertierung
Python
series=pd.Series([2, 3], index=list('ab'))
series
a 2
b 3
dtype: int64
Python
#Quadrieren Sie jeden Wert der Serie
series ** 2
a 4
b 9
dtype: int64
Python
#Sie können auch Funktionen und Diktate auf der Karte übergeben
series.map(lambda x: x**2)
# series.map( {x:x**2 for x in range(3) })
a 4
b 9
dtype: int64
DataFrame-Datenkonvertierung
Python
df = pd.DataFrame( [[2, 3], [4, 5]], index=list('AB'),columns=list('ab'))
df
Python
#Ähnlich wie bei der Serie
df ** 2
# df.map(lambda x: x**2)
Python
#Funktion(Series to scalar)Auf jede Spalte anwenden
#Eine Dimension tiefer ist das Ergebnis Serie
df.apply(lambda c: c['A']*c['B'], axis=0)
a 8
b 15
dtype: int64
Python
#Funktion(Series to Series)Auf jede Zeile anwenden
#Das Ergebnis ist ein DataFrame
df.apply(lambda r: pd.Series(dict(a=r['a']+r['b'], b=r['a']*r['b'])), axis=1)
Konzentrieren und verschmelzen
Mit Pandas können Sie mehrere Serien und DataFrames verketten und kombinieren.
Serie concat (concat)
Selbst wenn doppelte Indizes vorhanden sind, werden diese unverändert kombiniert.
Python
ser1=pd.Series([1,2], index=list('ab'))
ser2=pd.Series([3,4], index=list('bc'))
pd.concat([ser1, ser2])
a 1
b 2
b 3
c 4
dtype: int64
Python
#Wenn Sie den Index eindeutig machen, entfernen Sie doppelte Duplikate
dif_idx = ser2.index.difference(ser1.index)
pd.concat([ser1, ser2[list(dif_idx)]])
a 1
b 2
c 4
dtype: int64
DataFrame concat (concat)
Python
df1 = pd.DataFrame([[1, 2], [3, 4]], index=list('AB'),columns=list('ab'))
df2 = pd.DataFrame([[5, 6], [7, 8]], index=list('CD'),columns=list('ab'))
df3 = pd.DataFrame([[5, 6], [7, 8]], index=list('AB'),columns=list('cd'))
Python
df1
Python
df2
Python
df3
Python
#0. Achse(Linie)In Richtung stapeln
pd.concat([df1, df2], axis=0)
|
a |
b |
| A |
1 |
2 |
| B |
3 |
4 |
| C |
5 |
6 |
| D |
7 |
8 |
Python
#1. Achse(Säule)In Richtung stapeln
pd.concat([df1, df3], axis=1)
|
a |
b |
c |
d |
| A |
1 |
2 |
5 |
6 |
| B |
3 |
4 |
7 |
8 |
DataFrame-Zusammenführung
Python
df1.index.name = df3.index.name = 'A'
df10 = df1.reset_index()
df30 = df3.reset_index()
Python
df10
Python
df30
Python
#Schließen Sie sich Spalte A an
pd.merge(df10, df30, on='A')
|
A |
a |
b |
c |
d |
| 0 |
A |
1 |
2 |
5 |
6 |
| 1 |
B |
3 |
4 |
7 |
8 |
Ein erhält den Spaltennamen, der für den Join verwendet werden soll.
Es können mehrere Spezifikationen angegeben werden. In diesem Fall werden sie in der Liste angegeben.
Wenn nicht angegeben, wird der gemeinsame Spaltenname der beiden DataFrames übernommen.
Im obigen Beispiel lautet der allgemeine Spaltenname nur A, sodass er weggelassen werden kann.
Beachten Sie, dass die Indexspalte beim Zusammenführen ignoriert wird.
Eingabe und Ausgabe verschiedener Dateiformate
Pandas können verschiedene Formate eingeben und ausgeben.
Python
a2 = np.arange(16) .reshape(4,4)
idx = pd.MultiIndex.from_product( [['A','B'],['a','b']], names=('i','j'))
col = pd.MultiIndex.from_product( [['C','D'],['c','d']], names=('k','l'))
df = pd.DataFrame(a2, index=idx, columns=col)
df
|
k |
C |
D |
|
l |
c |
d |
c |
d |
| i |
j |
|
|
|
|
| A |
a |
0 |
1 |
2 |
3 |
| b |
4 |
5 |
6 |
7 |
| B |
a |
8 |
9 |
10 |
11 |
| b |
12 |
13 |
14 |
15 |
Exportdatei
Python
#Ausgabe in HTML-Datei
df.to_html('a2.html')

Python
#Ausgabe in eine Excel-Datei(Benötigt openpyxl)
df.to_excel('a2.xlsx')
Datei lesen
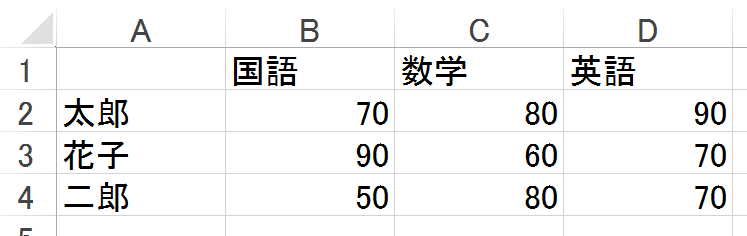
Python
xl = pd.ExcelFile('test.xlsx')
#Blatt angeben
df = xl.parse('Sheet1')
df
|
Japanisch
| Mathematik
| Englisch
|
| Taro
| 70 |
80 |
90 |
| Hanako
| 90 |
60 |
70 |
| Jiro
| 50 |
80 |
70 |
Erstellen eines Diagramms
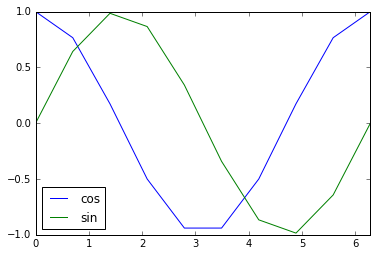
Pandas funktioniert hervorragend mit Matplotlib und erleichtert das Erstellen von Diagrammen aus DataFrames.
Python
%matplotlib inline
x = np.linspace(0, 2*np.pi, 10)
df = pd.DataFrame(dict(sin=np.sin(x), cos=np.cos(x)), index=x)
df
|
cos |
sin |
| 0.000000 |
1.000000 |
0.000000e+00 |
| 0.698132 |
0.766044 |
6.427876e-01 |
| 1.396263 |
0.173648 |
9.848078e-01 |
| 2.094395 |
-0.500000 |
8.660254e-01 |
| 2.792527 |
-0.939693 |
3.420201e-01 |
| 3.490659 |
-0.939693 |
-3.420201e-01 |
| 4.188790 |
-0.500000 |
-8.660254e-01 |
| 4.886922 |
0.173648 |
-9.848078e-01 |
| 5.585054 |
0.766044 |
-6.427876e-01 |
| 6.283185 |
1.000000 |
-2.449294e-16 |
Python
#Grafikausgabe
df.plot()