Python-Anwendung: Datenverarbeitung # 3: Datenformat
Protocol Buffers
Was sind Protokollpuffer?
Verarbeiten Sie die Daten, indem Sie im Voraus einen Nachrichtentyp definieren. Der Nachrichtentyp ist wie eine Klasse ohne Methoden. Dieses Mal werde ich vorstellen, wie der Nachrichtentyp mit der Sprache proto2 definiert wird. Der Ablauf der Datenverarbeitung ist wie folgt.
Definieren Sie den Nachrichtentyp mit 1, proto2 2, Kompilieren Sie die Datei, in der der Nachrichtentyp definiert ist 3, schreiben Sie Daten in Python
Nachrichtentyp definieren ①
Definieren wir zunächst den Nachrichtentyp. Dieses Mal definieren wir einen Nachrichtentyp, der die Familienstruktur darstellt. Wir geben jeder Person Informationen zu "Name", "Alter" und "Beziehung". Siehe den Quellcode unten.
//Semikolon am Ende jeder Zeile(;)Ich werde anziehen.
syntax = "proto2";
/*Top-Syntax= "proto2";Ist wie ein Signal zur Verwendung von Proto2.
Derzeit gibt es auch proto3, aber dieses Mal werden wir proto2 verwenden.*/
message Person{
/*
Es definiert eine Person, die die Informationen jedes Familienmitglieds darstellt.
Nachricht ist wie eine Python-Klasse.
*/
//Kommentar 1:Nur eine Zeile
/*
Kommentar
Teil 2:Wird verwendet, wenn mehrere Zeilen vorhanden sind
*/
required string name = 1; //Vollständiger Name
/*
Zeichenfolgenname gibt an, dass dem Namen eine Zeichenfolge zugewiesen wird. Dieses Paar wird als Feld bezeichnet.
Seitwärts= 1;Es ist geworden. Dieser wird als Tag bezeichnet.
Tags werden bei der Ausgabe von Daten im Binärformat verwendet
Es ist eine Marke, um zu unterscheiden, welche Daten welche sind.
*/
required int32 age = 2; //Alter
/*
Die Feld-Tags im selben Nest müssen unterschiedlich sein.
Es ist auch wünschenswert, eine Zahl zwischen 1 und 15 anzugeben, um Speicherplatz zu sparen.
*/
enum Relationship{
FATHER = 0; //Vater
MOTHER = 1; //Mutter
SON = 2; //Sohn
DAUGHTER = 3; //Tochter
GRANDFATHER = 4; //Großvater
GRANDMOTHER = 5; //Oma
}
required Relationship relationship = 4; //Beziehung
}
In proto2 ist es erforderlich, dem erforderlichen Element das erforderliche Element hinzuzufügen (in proto3 wird es abgeschafft). Bitte beachten Sie.
Nachrichtentyp definieren ②
syntax = "proto2";
message Person{
required string name = 1; //Vollständiger Name
required int32 age = 2; //Alter
enum Relationship{
//Definieren Sie einen neuen Typ mit enum Relationship
/*Es gibt VATER und MUTTER in der Aufzählung
Der durch enum definierte Typ nimmt einen dieser Werte an.
Relationship relationship = 4;Definiert in
Beziehung ist
Es kann VATER, MUTTER, SUMME, TOCHTER, GROSSVATER oder GROSSMUTTER sein.
*/
FATHER = 0; //Vater
MOTHER = 1; //Mutter
SON = 2; //Sohn
DAUGHTER = 3; //Tochter
GRANDFATHER = 4; //Großvater
GRANDMOTHER = 5; //Oma
}
required Relationship relationship = 4; //Beziehung
/*
Relationship relationship = 4;Obwohl es so ist
Bitte beachten Sie, dass diese 4 ein Tag ist und sich nicht auf GRAND FATHER bezieht.
Alle Zahlen, die in der Definition der Beziehung erscheinen, sind ebenfalls Tags.
Beachten Sie, dass die Tags in der Aufzählung bei 0 beginnen.
*/
}
Beziehungsbeziehung = 4;
Bitte beachten Sie, dass diese 4 ein Tag ist und sich nicht auf GRAND FATHER bezieht. Außerdem sind alle Zahlen, die in der Definition der Beziehung erscheinen, Tags. Beachten Sie, dass die Tags in der Aufzählung bei 0 beginnen.
Nachrichtentyp definieren ③
Definieren Sie schließlich die Familie. Wiederholen sollte ein listähnliches Bild haben. Dies bedeutet, dass 0 oder mehr Personentypdaten vorhanden sind.
syntax = "proto2";
message Person{
required string name = 1; //Vollständiger Name
required int32 age = 2; //Alter
enum Relationship{
FATHER = 0; //Vater
MOTHER = 1; //Mutter
SON = 2; //Sohn
DAUGHTER = 3; //Tochter
GRANDFATHER = 4; //Großvater
GRANDMOTHER = 5; //Oma
}
required Relationship relationship = 4; //Beziehung
}
message Family{
repeated Person person = 1;
}
Dies vervollständigt die Definition von Familie. Um dies in Python zu handhaben, müssen Sie es in Python neu schreiben. Dies erfolgt mit folgendem Befehl:
%%bash
protoc --python_out={Pfad zum Verzeichnis zum Speichern der kompilierten Datei(Relativer Pfad zur zu kompilierenden Datei)} {Pfad der zu kompilierenden Datei}
Diesmal befindet sich die Familie direkt im Datenverzeichnis.Es wird angenommen, dass es eine Datei namens proto gibt. Führen Sie den folgenden Befehl aus.
%%bash
protoc --python_out=./ ./4080_data_handling_data/family.proto
Dann Familie_pb2.Sie haben eine Datei namens py. Bitte achten Sie darauf, diese Datei nicht zu bearbeiten(Wenn Sie es versehentlich bearbeiten und speichern, führen Sie den obigen Befehl erneut aus.)。
%% bash wird als magischer Befehl zum Ausführen von Befehlen auf Jupyter Notebook bezeichnet. Nicht erforderlich, außer für Jupyter Notebook.
(Wenn Sie in der lokalen Umgebung von Windows ausgeführt werden, verwenden Sie protoc.exe --python_out = ./ ./4080_data_handling_data / family.proto.)
Schreiben Sie Daten in Python
Ich werde die Daten in Python schreiben.
import sys
sys.path.append('./4080_data_handling_data')
family_pb2 = __import__('family_pb2')
#Familientyp-Dateninstanz
family = family_pb2.Family()
family_name = ["Bob", "Mary", "James", "Lisa", "David", "Maria"]
family_age = [34, 29, 5, 3, 67, 66]
# family_rel = [i for i in range(6)]Vielleicht
family_rel = [family_pb2.Person.FATHER, family_pb2.Person.MOTHER, family_pb2.Person.SON,
family_pb2.Person.DAUGHTER, family_pb2.Person.GRANDFATHER, family_pb2.Person.GRANDMOTHER]
for i in range(6):
#wiederholt ist wie ein Array
#Fügen Sie ein neues Element hinzu
person = family.person.add()
#Ersatzname, Alter, Beziehung
person.name = family_name[i]
person.age = family_age[i]
person.relationship = family_rel[i]
print(family)
Deklarieren Sie zunächst eine Instanz vom Typ Family mit family = family_pb2.Family (). Die Familie hatte eine wiederholte Person. Das ist wie eine Liste Wenn Sie ein Element hinzufügen möchten, schreiben Sie etwas wie family.person.add (). Durch Ersetzen der durch enum definierten wird der Elementname oder das Tag von enum zugewiesen
hdf5
hdf5 ist das von keras verwendete Datenformat. Wenn Sie beispielsweise das trainierte Modell speichern möchten, wird es im HDF5-Format ausgegeben. Ein Hauptmerkmal von hdf5 ist, dass die hierarchische Struktur in einer Datei vervollständigt werden kann.
Erstellen Sie beispielsweise ein Verzeichnis namens Kochen. Erstellen Sie Verzeichnisse mit den Namen Japanisch, Westlich und Chinesisch Darüber hinaus besteht jede Methode darin, Grillgeschirr, gekochtes Geschirr usw. zuzubereiten.
Erstellen Sie ein hierarchisches Verzeichnis wie einen Baum.
Erstellen einer Datei im HDF5-Format
Beim Umgang mit Daten im HDF5-Format in Python wird eine Bibliothek mit den Namen h5py und Pandas verwendet. Lassen Sie uns die Daten tatsächlich erstellen und in einer Datei speichern. Nehmen wir als Beispiel die Bevölkerung der Präfektur A.
import h5py
import numpy as np
import os
np.random.seed(0)
#Betrachten Sie Stadt X, Stadt Y und Stadt Z in Präfektur A.
#Angenommen, X-Stadt hat 1 bis 3 Chome, Y-Stadt hat 1 bis 5 Chome und Z-Stadt hat nur 1 Chome.
#Definition der Bevölkerung in jeder Stadt
population_of_X = np.random.randint(50, high=200, size=3)
population_of_Y = np.random.randint(50, high=200, size=5)
population_of_Z = np.random.randint(50, high=200, size=1)
#Listen Sie die Bevölkerung auf
population = [population_of_X, population_of_Y, population_of_Z]
#Löschen Sie die Datei, falls sie bereits vorhanden ist
if os.path.isfile('./4080_data_handling_data/population.hdf5'):
os.remove('./4080_data_handling_data/population.hdf5')
#Datei öffnen
hdf_file = h5py.File('./4080_data_handling_data/population.hdf5')
# 'A'Erstellen Sie eine Gruppe mit dem Namen(Bedeutung der Präfektur A.)
prefecture = hdf_file.create_group('A')
for i in range(3):
#Zum Beispiel A./X/1 ist ein Bild von 1-chome, X Stadt, einer Präfektur
#Bild des Einfügens von Daten in eine Datei mit dem Namen 1 im X-Verzeichnis im A-Verzeichnis
for j in range(len(population[i])):
city = hdf_file.create_dataset('A/' + ['X', 'Y', 'Z'][i] + '/' + str(j + 1), data=population[i][j])
#Schreiben
hdf_file.flush()
#schließen
hdf_file.close()
Lesen des HDF5-Formats
Versuchen Sie, die Datei zu lesen. Der Elementzugriff entspricht dem Bild einer Liste.
import pandas as pd
import h5py
import numpy as np
#Pfad der Datei, die Sie öffnen möchten
path = './4080_data_handling_data/population.hdf5'
#Datei öffnen
# 'r'Bedeutet Lesemodus
population_data = h5py.File(path, 'r')
for prefecture in population_data.keys():
for city in population_data[prefecture].keys():
for i in population_data[prefecture][city].keys():
print(prefecture + 'Präfektur' + city + 'Stadt' + i + 'Chome: ',
int(population_data[prefecture][city][i].value))
#schließen
population_data.close()
TFRecord
Über TF Record
TFRecord ist das von TensorFlow verwendete Datenformat. Der Grund, warum TFRecord empfohlen wird, besteht darin, die Daten einmal in diesem Format zu speichern. Dies liegt daran, dass die Kosten für maschinelles Lernen möglicherweise niedriger sind.
Außerdem ist TFRecord in proto3 implementiert. Hier sehen wir uns den Prozess der Konvertierung der Daten in das TFRecord-Format und der Ausgabe in eine Datei an.
Konvertieren Sie das Bild in das TFRecord-Format und geben Sie es in eine externe Datei aus ①
Ich werde Ihnen zeigen, wie Sie ein Bild laden und in das TFRecord-Format konvertieren. Hier werden wir die Vorbereitung übernehmen, bevor wir in die Datei schreiben.
import numpy as np
import tensorflow as tf
from PIL import Image
#Bild laden
image = Image.open('./4080_data_handling_data/hdf5_explain.png')
#Definition der zu exportierenden Daten
# tf.train.Verwenden Sie eine Klasse namens Example
# tf.train.Von der Klasse namens Features"Zusammenhaltend"
#Jeder tf.train.Feature-Element ist Bytes
#Diesmal Bild, label, height,Breite als Daten übernehmen
my_Example = tf.train.Example(features=tf.train.Features(feature={
'image': tf.train.Feature(bytes_list=tf.train.BytesList(value=[image.tobytes()])),
'label': tf.train.Feature(bytes_list=tf.train.BytesList(value=[np.ndarray([1000]).tobytes()])),
'height': tf.train.Feature(bytes_list=tf.train.BytesList(value=[np.ndarray([image.height]).tobytes()])),
'width': tf.train.Feature(bytes_list=tf.train.BytesList(value=[np.ndarray([image.width]).tobytes()])),
}))
Es ist etwas kompliziert, aber schauen wir uns die Definition von my_Example an.
tf.train.BytesList Dies ist eine Klasse. Durch Setzen von value = [hoge] wird eine Instanz mit hoge als Daten erstellt. Beachten Sie, dass hoge Bytes ist. Diesmal ist der Hoge
- image.tobytes()
- np.ndarray([1000]).tobytes()
- np.ndarray([image.height]).tobytes()
- np.ndarray([image.width]).tobytes()
Es gibt vier.
Erstellen Sie eine Instanz der Klasse tf.train.Feature
Weisen Sie jeder Instanz von tf.train.Features einen Schlüssel zu Erstellen Sie eine Instanz von dict. Der Schlüssel ist diesmal
- image
- label
- height
- width
Es gibt vier. Verwenden des aus diesen vier tf.train.Features generierten Diktats Erstellen Sie eine Instanz von tf.train.Features.
Erstellen Sie eine Instanz von tf.train.Example
Wird aus einer Instanz der Klasse tf.train.Feature generiert
Diese Instanz ist my_Example, mit der in die Datei geschrieben wird.
Sie können drei Arten von Schreibformaten verwenden: int64, float und bytes. Dieses Mal werden Bytes gemäß dem Quellcode verwendet.
Die Erklärung der vier tf.train.Features Bild ist das Bild selbst label ist eine Markierung des Bildes und eine beliebige Zahl (diesmal 1000) Höhe und Breite sind die Höhe bzw. Breite des Bildes.
Hier werden wir die Elemente einbeziehen, die wir zu finden versuchen. In diesem Fall gibt es beispielsweise nur ein Bild, sodass kein Etikett erforderlich ist. Es kann jedoch notwendig werden, wenn die Anzahl der Bilder zunimmt. Es kann besser sein, andere Informationen wie den Namen des Bildes anzugeben. Wenn das Bild ausreicht, ist das Bild allein in Ordnung.

Konvertieren Sie das Bild in das TFRecord-Format und geben Sie es in eine externe Datei aus ②
Schreiben Sie dann die generierte Instanz der Klasse tf.train.Example in die Datei
import numpy as np
import tensorflow as tf
from PIL import Image
#Bild laden
image = Image.open('./4080_data_handling_data/hdf5_explain.png')
#Definition der zu exportierenden Daten
# tf.train.Verwenden Sie eine Klasse namens Example
# tf.train.Von der Klasse namens Features"Zusammenhaltend"
#Jeder tf.train.Feature-Element ist Bytes
#Diesmal Bild, label, height,Breite als Daten übernehmen
my_Example = tf.train.Example(features=tf.train.Features(feature={
'image': tf.train.Feature(bytes_list=tf.train.BytesList(value=[image.tobytes()])),
'label': tf.train.Feature(bytes_list=tf.train.BytesList(value=[np.ndarray([1000]).tobytes()])),
'height': tf.train.Feature(bytes_list=tf.train.BytesList(value=[np.ndarray([image.height]).tobytes()])),
'width': tf.train.Feature(bytes_list=tf.train.BytesList(value=[np.ndarray([image.width]).tobytes()])),
}))
#Erstellen Sie ein TFRecordWriter-Objekt, um eine Datei im TFRecoder-Format zu exportieren
fp = tf.python_io.TFRecordWriter('./4080_data_handling_data/sample.tfrecord')
#Beispielobjekt serialisiert und geschrieben
fp.write(my_Example.SerializePartialToString())
#schließen
fp.close()
fp = tf.python_io.TFRecordWriter ('./4080_data_handling_data/sample.tfrecord') Stellen Sie sich das als offenes ('. / 4080_data_handling_data / sample.tfrecord', 'w') TFRecord vor.
fp.write() #Dies wird tatsächlich in die Datei schreiben.
SerializePartialToString() #Jetzt müssen Sie es in eine Byte-Zeichenfolge konvertieren und als Argument übergeben.
fp.close() #Dies schließt die Datei und Sie sind fertig.
Daten mit variabler Länge verarbeiten
Als nächstes werde ich den Umgang mit Daten variabler Länge vorstellen. Eine variable Länge ist eine Liste, deren Länge buchstäblich geändert werden kann.
Die Python-Liste hat grundsätzlich eine variable Länge Einige können nur eine vorbestimmte Datenmenge enthalten, und diese werden als feste Längen bezeichnet.
①tf.train.Beispiel ist eine feste Länge.
②tf.train.Verwenden Sie eine Klasse namens SequenceExample, um Daten variabler Länge zu generieren.
```
```python
import numpy as np
import tensorflow as tf
from PIL import Image
#Instanzgenerierung
my_Example = tf.train.SequenceExample()
#Datenzeichenfolge
greeting = ["Hello", ", ", "World", "!!"]
fruits = ["apple", "banana", "grape"]
for item in {"greeting": greeting, "fruits": fruits}.items():
for word in item[1]:
# my_Feature im Beispiel_von Listen, Funktion_Als Schlüssel zur Liste"word"Element hinzufügen mit
words_list = my_Example.feature_lists.feature_list[item[0]].feature.add()
# word_Bytes in der Liste_Verweis auf Wert in Liste
new_word = words_list.bytes_list.value
# utf-Codieren Sie auf 8 und fügen Sie Elemente hinzu
new_word.append(word.encode('utf-8'))
print(my_Example)
```
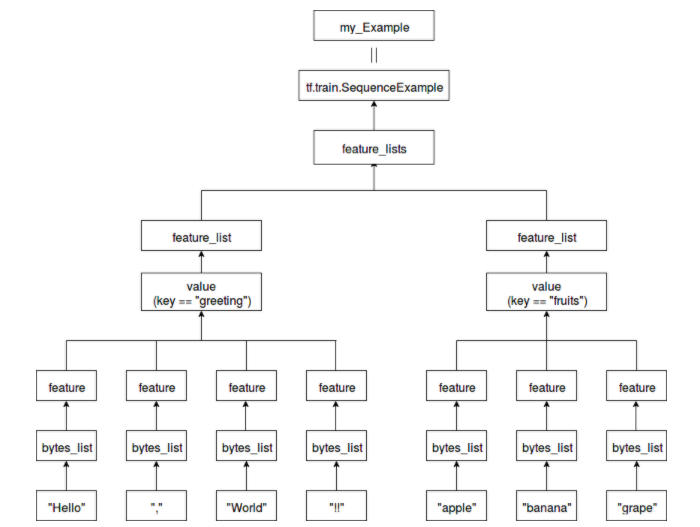
"Hallo", "!!" und "Apfel" sind Teil von bytes_list.
Sie können bytes_list auch mehrere Elemente hinzufügen.
Geben Sie für die Funktion eine der Optionen bytes_list, float_list oder int64_list an.
Dieses Mal wird bytes_list angegeben.
Eine Sammlung von Funktionen ist feature_list.
feature_lists hat eine Zeichenfolge als Schlüssel und feature_list als Wert.
"Gruß" als Schlüssel für "Hallo Welt !!"
"Früchte" wird als Schlüssel für "Apfel, Banane, Traube" angegeben.
Eine Klasse mit feature_lists, die diese zusammenfasst, ist tf.train.SequenceExample
my_Example ist diese Instanz.
Recommended Posts