Finden Sie die kumulative Verteilungsfunktion durch Sortieren (Python-Version)
Dieser Artikel ist eine Neufassung von Kumulative Verteilungsfunktion durch Sortieren berechnen, die in Ruby in Python geschrieben wurde.
Einführung
Wenn Sie die Wahrscheinlichkeitsdichtefunktion (PDF) einer bestimmten Wahrscheinlichkeitsvariablen kennen möchten, verwenden Sie ein Histogramm für naiv, aber es erfordert Versuch und Irrtum, den Behälter zu schneiden, und es sind eine beträchtliche Anzahl von Messungen erforderlich, um ein sauberes Diagramm zu erhalten. Es ist mühsam zu werden. In einem solchen Fall ist es einfacher, die kumulative Verteilungsfunktion (CDF) anstelle der Wahrscheinlichkeitsdichtefunktion zu betrachten, und es ist einfacher, sie mit einer einzelnen Sortierung zu finden. Im Folgenden werden die Unterschiede zwischen den Zufallszahlen vorgestellt, die der Normalverteilung folgen, wenn sie in PDF und in CDF angezeigt werden. Der Vorgang wurde von Google Colab bestätigt.
Holen Sie sich die Wahrscheinlichkeitsdichtefunktion im Histogramm
Lassen Sie uns zunächst sehen, wie die Wahrscheinlichkeitsdichtefunktion aus dem Histogramm erhalten wird. Importieren Sie alle Bibliotheken, die Sie später benötigen.
import random
import matplotlib.pyplot as plt
import numpy as np
from math import pi, exp, sqrt
from scipy.optimize import curve_fit
from scipy.special import erf
Generieren Sie 1000 Zufallszahlen, die einer Gaußschen Verteilung mit einem Durchschnitt von 1 und einer Varianz von 1 folgen.
N = 1000
d = []
for _ in range(N):
d.append(random.gauss(1, 1))
Wenn ich es zeichne, sieht es so aus.
plt.plot(d)
plt.show()
Es sieht so aus, als würde es um 1 schwanken.
Lassen Sie uns ein Histogramm erstellen und die Wahrscheinlichkeitsdichtefunktion ermitteln. Sie können es auch mit matplotlib.pyplot.hist finden, aber ich benutze numpy.histogram als Hobby, um Werte zu erhalten.
hy, bins = np.histogram(d)
hx = bins[:-1] + np.diff(bins)/2
hy = hy / N
plt.plot(hx,hy)
plt.show()
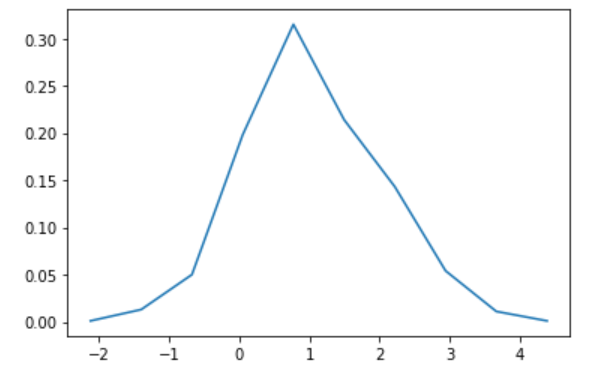
Es sieht aus wie eine Gaußsche Distribution, ist aber ziemlich verrückt.
Nehmen wir nun an, dass dieses Histogramm eine Gaußsche Verteilung hat, und ermitteln Sie den Mittelwert und die Standardabweichung. Verwenden Sie scipy.optimize.curve_fit.
Definieren Sie zunächst die für die Anpassung verwendete Funktion.
def mygauss(x, m, s):
return 1.0/sqrt(2.0*pi*s**2) * np.exp(-(x-m)**2/(2.0*s**2))
Beachten Sie, dass Sie "np.exp" anstelle von "exp" verwenden müssen, da das NumPy-Array an "x" übergeben wird. Wenn Sie diese Funktion und Daten an scipy.optimize.curve_fit übergeben, werden ein Array von Schätzungen und eine Kovarianzmatrix zurückgegeben. Zeigen wir sie also an.
v, s = curve_fit(mygauss, hx, hy)
print(f"mu = {v[0]} +- {sqrt(s[0][0])}")
print(f"sigma = {v[1]} +- {sqrt(s[1][1])}")
Da die diagonalen Komponenten der Kovarianzmatrix Dispersionen sind, werden die Quadratwurzeln als Fehler angezeigt. Das Ergebnis ist jedes Mal anders, aber es sieht zum Beispiel so aus.
mu = 0.9778044193329654 +- 0.16595607115412642
sigma = 1.259695311989267 +- 0.13571713273726863
Während die wahren Werte beide 1 sind, beträgt der durchschnittliche geschätzte Wert 0,98 + -0,17 und die Standardabweichung 1,3 + -0,1, was kein großer Unterschied ist, aber nicht gut.
Holen Sie sich die kumulative Verteilungsfunktion durch Sortieren
Die kumulative Verteilungsfunktion $ F (x) $ ist die Wahrscheinlichkeit, dass der Wert einer bestimmten Wahrscheinlichkeitsvariablen $ X $ kleiner als $ x $ ist, d. H.
Ist. Angenommen, wenn $ N $ von unabhängigen Daten erhalten wird, ist der $ k $ -te Wert $ x $, indem sie in aufsteigender Reihenfolge angeordnet werden. Dann kann die Wahrscheinlichkeit, dass die Wahrscheinlichkeitsvariable $ X $ kleiner als $ x $ ist, als $ k / N $ geschätzt werden. Aus dem Obigen kann die kumulative Verteilungsfunktion erhalten werden, indem das erhaltene Array von $ N $ Wahrscheinlichkeitsvariablen sortiert und die $ k $ -ten Daten auf der x-Achse und $ k / N $ auf der y-Achse aufgetragen werden. Mal sehen.
sx = sorted(d)
sy = [i/N for i in range(N)]
plt.plot(sx, sy)
plt.show()
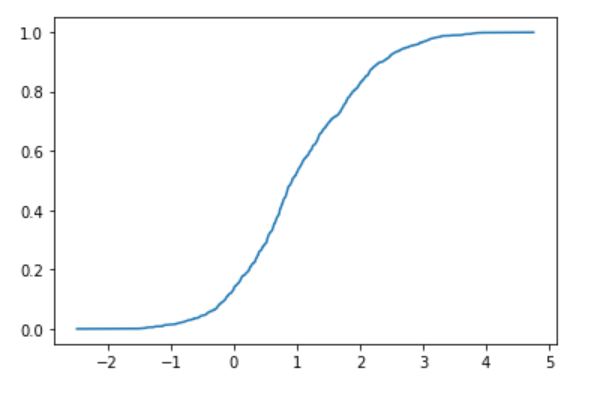
Eine relativ schöne Fehlerfunktion wurde erhalten. Stellen Sie sich dies nach wie vor als Fehlerfunktion vor und ermitteln Sie den Mittelwert und die Varianz durch Anpassen. Bereiten Sie zunächst die Fehlerfunktion für die Anpassung vor. Beachten Sie, dass die Definition der Fehlerfunktion in der Welt schwierig ist. Sie müssen also 1 addieren und durch 2 teilen oder das Argument durch √2 teilen.
def myerf(x, m, s):
return (erf((x-m)/(sqrt(2.0)*s))+1.0)*0.5
Lass es uns passen.
v, s = curve_fit(myerf, sx, sy)
print(f"mu = {v[0]} +- {sqrt(s[0][0])}")
print(f"sigma = {v[1]} +- {sqrt(s[1][1])}")
Das Ergebnis sieht so aus.
mu = 1.00378752698032 +- 0.0018097681998120645
sigma = 0.975197323266848 +- 0.0031393908850607445
Der Durchschnitt liegt bei 1,004 + -0,002 und die Standardabweichung bei 0,974 + -0,003, was trotz der Verwendung genau derselben Daten eine erhebliche Verbesserung darstellt.
Zusammenfassung
Um die Verteilung stochastischer Variablen zu sehen, habe ich vorgestellt, wie man die Wahrscheinlichkeitsdichtefunktion mithilfe eines Histogramms erhält und wie man die kumulative Verteilungsfunktion sortiert und sieht. Das Histogramm erfordert viel Versuch und Irrtum beim Schneiden des Behälters, aber es ist einfach, die kumulative Verteilungsfunktion durch Sortieren zu erkennen, da keine Parameter erforderlich sind. Selbst wenn Sie eine Wahrscheinlichkeitsdichtefunktion wünschen, können Sie bessere Daten erhalten, indem Sie die kumulative Verteilungsfunktion einmal finden, dann die Mittelwertbildung verschieben und numerisch differenzieren.
Außerdem ist die kumulative Verteilungsfunktion beim Schätzen der Parameter der ursprünglichen Verteilung genauer. Dies ist intuitiv im interessierenden Bereich (z. B. in der Nähe des Mittelwerts), wenn das Histogramm verwendet wird, kann nur die Anzahl der Daten im Bin verwendet werden, aber im Fall der kumulativen Verteilungsfunktion können ungefähr $ N / 2 $ Daten verwendet werden. Ich denke, es kann verwendet werden, aber ich bin nicht so sicher, also fragen Sie einen Fachmann in der Nähe.
Recommended Posts