Générer de fausses données de table avec GAN
Aperçu
Essayez CTGAN, l'un des GAN pour les données de tableau, par rapport à l'ensemble de données du revenu du recensement pour générer de fausses données de tableau. Entraînez XGBoost avec les données générées et vérifiez leur précision par rapport aux données d'origine.
CTGAN Le GAN est connu comme une technologie capable de générer de fausses images réalistes, mais la recherche sur le GAN pour les données non images progresse également. Voici le code publié dans le GAN correspondant aux données de table.
- MedGAN [arXiv:1703.06490][GitHub]
- TableGAN [arXiv:1806.03384][GitHub]
- TGAN [arXiv:1811.11264][GitHub]
- CTGAN [arXiv:1907.00503][GitHub]
Comme son nom l'indique, MedGAN est un modèle développé avec des données médicales à l'esprit et ne prend en charge que les données de catégorie. (Il existe également un modèle pour les images médicales du même nom.) TableGAN et TGAN sont des modèles développés indépendamment en même temps, et les deux prennent en charge des tableaux contenant à la fois des données de catégorie et des données numériques. Dans les articles japonais
TGAN est introduit dans. Cette fois, je vais essayer CTGAN (Conditional Tabular GAN), qui est une version mise à jour de TGAN.
CTGAN est facile à installer avec pip.
pip install ctgan
Préparation des données
Utilisez un ensemble de données appelé Census Income comme données de tableau. Cet ensemble de données sert à prédire si votre revenu annuel dépassera 50 000 USD à partir d'informations personnelles telles que le sexe, l'âge, les antécédents scolaires et la race. Les données peuvent être téléchargées à partir du lien ci-dessus, mais comme elles sont incluses dans CTGAN en tant que données de démonstration, elles peuvent être lues comme suit.
import numpy as np
import pandas as pd
from ctgan import load_demo
df0 = load_demo()
print(df0.shape)
# (32561, 15)
Pour une raison quelconque, les données lues de cette manière contiennent un espace demi-largeur au début de l'élément de catégorie. Peu importe si un espace demi-largeur est inclus dans le montant à envoyer à CTGAN et XGBoost, mais ce sera un obstacle lors de l'analyse des données, alors supprimez-le pour le moment.
for col in df0.select_dtypes(exclude=np.number).columns:
df0[col] = df0[col].str.replace(' ', '')
Les premières lignes s'affichent comme suit.
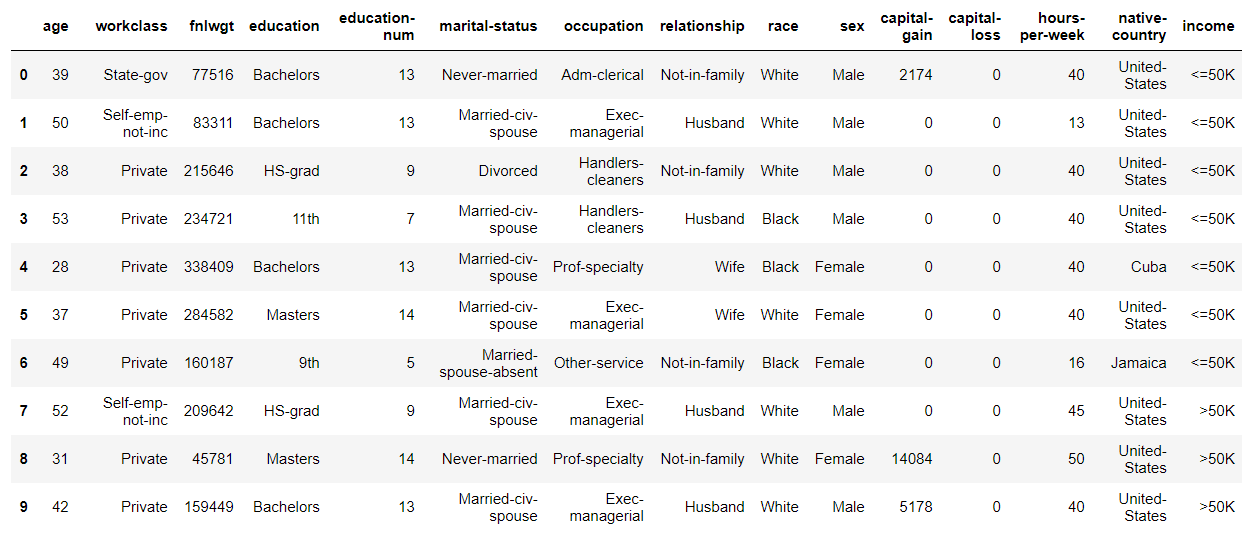 Vous pouvez voir qu'il se compose d'une colonne de variables catégorielles et d'une colonne d'entiers.
Parmi ces colonnes, les suivantes sont exclues.
'fnlwgt': ressemble à un numéro d'identification
'education-num': correspondance individuelle avec 'education'
'capital-gain': la plupart des lignes contiennent 0
`` perte en capital '': comme ci-dessus
Vous pouvez voir qu'il se compose d'une colonne de variables catégorielles et d'une colonne d'entiers.
Parmi ces colonnes, les suivantes sont exclues.
'fnlwgt': ressemble à un numéro d'identification
'education-num': correspondance individuelle avec 'education'
'capital-gain': la plupart des lignes contiennent 0
`` perte en capital '': comme ci-dessus
df0.drop(['fnlwgt', 'education-num', 'capital-gain', 'capital-loss'],
axis=1, inplace=True)
À propos, cet ensemble de données n'inclut pas les valeurs manquantes, et il y a un «?» À l'endroit qui semble avoir été une valeur manquante à l'origine. Cette fois, laissez le «?» Tel quel et poursuivez le traitement.
Ensuite, divisez l'ensemble de données en formation et test. Les données de formation seront utilisées à la fois pour la formation CTGAN et la formation XGBoost.
df0_train, df_test = train_test_split(df0,
test_size=0.2,
random_state=0,
stratify=df0['income'])
print(len(df0_train)) # 26048
print(len(df_test)) # 6513
Préparez une autre petite donnée d'entraînement.
df1_train, _ = train_test_split(df0_train,
test_size=0.9,
random_state=0,
stratify=df0_train['income'])
print(len(df1_train)) # 2604
Génération de données
Tout d'abord, formons CTGAN en utilisant les données d'entraînement plus grandes df0_train. Lors de la formation, il est nécessaire de spécifier le nom de colonne de la variable de catégorie.
discrete_columns = [
'workclass',
'education',
'marital-status',
'occupation',
'relationship',
'race',
'sex',
'native-country',
'income'
]
L'apprentissage peut être facilement effectué comme suit. Les données d'entrée correspondent à pandas.DataFrame et numpy.ndarray.
from ctgan import CTGANSynthesizer
ctgan0 = CTGANSynthesizer()
ctgan0.fit(df0_train, discrete_columns)
L'apprentissage fonctionne à 300 époques avec les paramètres par défaut.
Générez des données lorsque la formation est terminée. Les données générées seront au même format que les données d'entrée, donc dans ce cas, pandas.DataFrame sera retourné. Le nombre d'échantillons (nombre de lignes) de données à générer peut être défini librement. Peu importe combien vous en faites, c'est gratuit, alors franchissons le pas et faisons 1 million de lignes.
n_samples = 1000000
df0_syn = ctgan0.sample(n_samples)
print(df0_syn.shape)
# (1000000, 11)
Les premières lignes des données générées ressemblent à ceci:
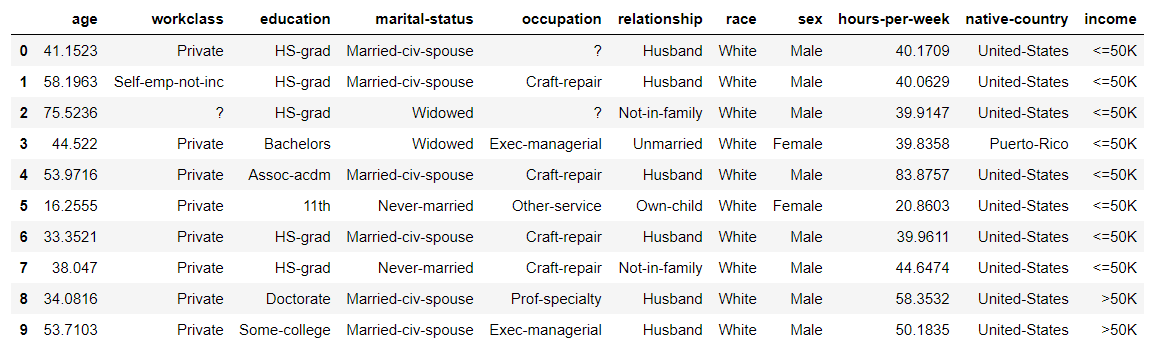 Les données numériques sont à l'origine considérées comme une virgule flottante même s'il s'agit d'un entier, et les données sont créées, vous devez donc les convertir vous-même en entier après la génération.
Les données numériques sont à l'origine considérées comme une virgule flottante même s'il s'agit d'un entier, et les données sont créées, vous devez donc les convertir vous-même en entier après la génération.
for col in ['age', 'hours-per-week']:
df0_syn[col] = df0_syn[col].astype(int)
À propos, dans l'article original de TGAN de l'ancienne version de CTGAN, nous avons calculé la corrélation entre les éléments de données et examiné à quel point les données générées sont similaires aux données d'origine. Cependant, comparons simplement la distribution de l'élément cible «revenu» avec les données d'origine et les données générées.
print("original data")
print(df0_train['income'].value_counts(normalize=True))
# <=50K 0.759175
# >50K 0.240825
print("synthetic data")
print(df0_syn['income'].value_counts(normalize=True))
# <=50K 0.822426
# >50K 0.177574
À l'origine, il s'agissait de données non uniformes avec une petite proportion de plus de 50K, mais dans les données générées, la proportion de plus de 50K est devenue encore plus petite. Cela signifie-t-il que la distribution des données originales n'a pas été formée avec autant de précision? Quoi qu'il en soit, vérifions la qualité des données générées en entraînant XGBoost.
Apprentissage XGBoost ①
Évaluons à quel point les données générées sont similaires aux données d'origine en entraînant XGBoost à l'aide des données générées et en les comparant au cas où les données d'origine sont utilisées. De plus, en mélangeant les données générées avec les données originales et en les entraînant, nous essaierons d'améliorer la précision du modèle par rapport au cas des données originales seules.
Commencez par effectuer un prétraitement des données. Cette fois, nous allons simplement convertir la variable de catégorie en une valeur numérique (encodage d'étiquette).
Il peut y avoir de rares variables qui n'apparaissent pas dans de petits blocs de données tels que df_test après la division, alors utilisez d'abord le bloc de données d'origine df0 pour créer un dictionnaire contenant une liste de chaque variable de catégorie. Créez-le et appliquez-le à chaque bloc de données à l'aide du codeur d'étiquettes scikit-learn.
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
category_dict = {}
for col in discrete_columns:
category_dict[col] = df0[col].unique()
def preprocessing(df, category_dict):
df_ = df.copy()
for k, v in category_dict.items():
le.fit(v)
df_[k] = le.transform(df_[k])
y = df_['income']
X = df_.drop('income', axis=1)
return X, y
Appliquez la fonction créée ci-dessus à chaque bloc de données.
X0_train, y0_train = preprocessing(df0_train, category_dict)
print(X0_train.shape, y0_train.shape)
# (26048, 10) (26048,)
X_test, y_test = preprocessing(df_test, category_dict)
print(X_test.shape, y_test.shape)
# (6513, 10) (6513,)
X0_syn, y0_syn = preprocessing(df0_syn, category_dict)
print(X0_syn.shape, y0_syn.shape)
# (1000000, 10) (1000000,)
Entraînez XGBoost et préparez une fonction pour générer l'évaluation de la précision des données de test. Les hyper paramètres de XGBoost sont déterminés par une recherche de grille en utilisant toutes les données «df0».
def learn_predict(X, y, X_test, y_test):
xgb = XGBClassifier(learning_rate=0.1, max_depth=7, min_child_weight=4)
xgb.fit(X, y)
predictions = xgb.predict_proba(X_test)
auc = roc_auc_score(y_test, predictions[:, 1])
bool_pediction = (predictions[:, 1] >= 0.5).astype(int)
acc = accuracy_score(y_test, bool_pediction)
precision = precision_score(y_test, bool_pediction)
recall = recall_score(y_test, bool_pediction)
f1 = f1_score(y_test, bool_pediction)
print("AUC: {:.3f}".format(auc))
print("Accuracy {:.3f}".format(acc))
print("Precision: {:.3f}".format(precision))
print("Recall: {:.3f}".format(recall))
print("f1: {:.3f}".format(f1))
print("Confusion matrix:")
print(confusion_matrix(y_test, bool_pediction))
return (auc, acc, precision, recall, f1)
Precision, Recall, f1 sont pour les cibles avec des revenus supérieurs à 50K.
Tout d'abord, examinons les résultats de l'apprentissage avec les données d'entraînement d'origine (26048 cas). L'évaluation de la précision utilise toujours les données de test d'origine (6 513 cas) divisées en premier.
ac0 = learn_predict(X0_train, y0_train, X_test, y_test)
# AUC: 0.888
# Accuracy: 0.838
# Precision: 0.699
# Recall 0.578
# f1: 0.632
# Confusion matrix:
# [[4554 391]
# [ 662 906]]
Nous comparerons ce résultat avec le résultat en utilisant les données générées comme référence.
Lorsque vous utilisez les données générées, apprenez en modifiant le nombre d'échantillons et voyez comment la précision change en fonction du nombre d'échantillons.
n_samples = [1000, 3000, 10000, 30000, 100000, 300000, 1000000]
auc_list0 = []
acc_list0 = []
precision_list0 = []
recall_list0 = []
f1_list0 = []
for n in n_samples:
print("==" * 12)
print(" # of samples: ", n)
print("==" * 12)
ac = learn_predict(X0_syn[:n], y0_syn[:n], X_test, y_test)
print()
auc_list0.append(ac[0])
acc_list0.append(ac[1])
precision_list0.append(ac[2])
recall_list0.append(ac[3])
f1_list0.append(ac[4])
Le tableau ci-dessous montre les résultats.
| # of samples | 1K | 3K | 10K | 30K | 100K | 300K | 1M | Original |
|---|---|---|---|---|---|---|---|---|
| AUC | 0.825 | 0.858 | 0.857 | 0.868 | 0.873 | 0.875 | 0.876 | 0.888 |
| Accuracy | 0.795 | 0.816 | 0.816 | 0.822 | 0.821 | 0.823 | 0.822 | 0.838 |
| Precision | 0.650 | 0.682 | 0.703 | 0.729 | 0.720 | 0.723 | 0.717 | 0.699 |
| Recall | 0.327 | 0.440 | 0.407 | 0.417 | 0.423 | 0.430 | 0.429 | 0.578 |
| f1 | 0.435 | 0.539 | 0.515 | 0.531 | 0.533 | 0.540 | 0.537 | 0.632 |
Bien que le comportement ne soit pas complètement monotone, tout indice de précision a tendance à augmenter en précision à mesure que le nombre d'échantillons augmente. Cependant, à l'exception de la précision, le résultat du nombre maximal d'échantillons est également inférieur à la valeur des données d'origine. Puisque l'évaluation de la précision est effectuée sur les données de test séparées des données d'origine, ce résultat suggère que la distribution des données générées ne correspond pas complètement aux données d'origine. En ce qui concerne la précision, plus le nombre d'échantillons des données générées est élevé, meilleure est la précision que les données d'origine, mais cela est lié au fait que le rapport du nombre d'échantillons sur 50K est plus petit dans les données générées que dans les données d'origine. Je pense que c'est.
Le graphique ci-dessous montre les résultats de l'ASC, de la précision et de f1. L'axe horizontal montre le nombre d'échantillons de données générées sous forme de valeur logarithmique. La ligne en pointillé rouge est le résultat des données de base d'origine et le cercle bleu est le résultat des données générées. Le triangle vert sera décrit plus loin. En regardant ces graphiques, on peut voir que la précision a tendance à augmenter à mesure que le nombre d'échantillons des données générées augmente, mais elle atteint un certain niveau et n'atteint pas le résultat des données d'origine.
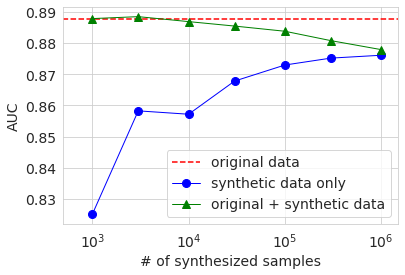
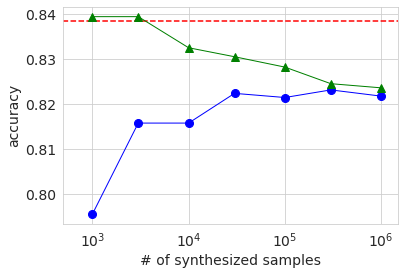
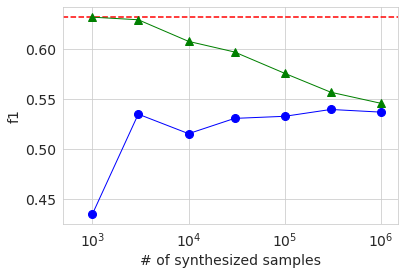
Ensuite, entraînons-nous en mélangeant les données générées avec les données d'origine. Cette fois également, nous modifions le nombre de données générées.
n_samples = [1000, 3000, 10000, 30000, 100000, 300000, 1000000]
auc_list0a = []
acc_list0a = []
precision_list0a = []
recall_list0a = []
f1_list0a = []
for n in n_samples:
X = pd.concat([X0_train, X0_syn[:n]])
y = pd.concat([y0_train, y0_syn[:n]])
print("==" * 12)
print(" # of samples: ", n)
print("==" * 12)
ac = learn_predict(X, y, X_test, y_test)
print()
auc_list0a.append(ac[0])
acc_list0a.append(ac[1])
precision_list0a.append(ac[2])
recall_list0a.append(ac[3])
f1_list0a.append(ac[4])
Les résultats sont indiqués dans le graphique ci-dessus avec des triangles verts. Lorsque le nombre d'échantillons de données générées est de plusieurs milliers, ce qui est à peu près le même que le nombre de données d'origine, les différentes exactitudes sont à peu près identiques ou légèrement supérieures à la ligne de base des données d'origine uniquement. Cependant, même si elle dépasse, la différence est très faible et il ne peut être déterminé à partir de cette expérience s'il s'agit d'une différence significative. Si vous augmentez le nombre d'échantillons de données générées, le ratio des données d'origine dans les données diminuera, de sorte que la précision diminuera, et vous pouvez voir qu'il se rapproche progressivement de la précision lors de l'apprentissage uniquement avec les données générées.
Apprentissage XGBoost ②
En passant, je pense que c'est lorsque le nombre de données pouvant être utilisées pour la formation est faible que vous souhaitez gonfler les données en utilisant de fausses données dans des situations pratiques. En supposant une telle situation, faisons le même calcul en utilisant les petites données d'entraînement df1_train préparées en premier. Le nombre de lignes dans «df1_train» est 2604, soit 1/10 de «df0_train».
Le code est le même que précédemment, donc je vais l'omettre, mais j'ai entraîné CTGAN, généré 1 million de lignes de données df1_syn et entraîné XGBoost.
Premièrement, les résultats de l'apprentissage en utilisant seulement 2604 données de base originales sont les suivants.
ac1 = learn_predict(X1_train, y1_train, X_test, y_test)
# AUC: 0.867
# Accuracy: 0.821
# Precision: 0.659
# Recall 0.534
# f1: 0.590
# [[4512 433]
# [ 730 838]]
Après tout, la précision est réduite dans son ensemble car le nombre de données est réduit.
Ensuite, le résultat de l'entraînement utilisant les données générées est affiché dans le même graphique qu'auparavant.
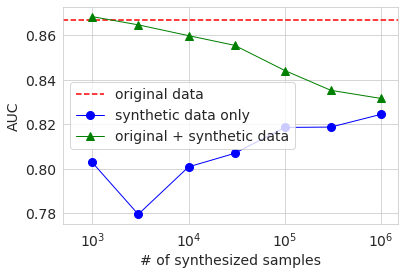
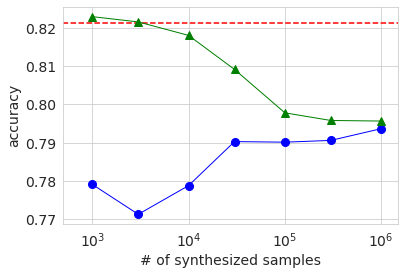
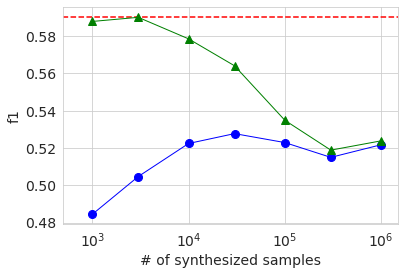
Les tendances comportementales générales sont les mêmes que celles des grands ensembles de données. La raison pour laquelle l'AUC et la précision lors de l'utilisation uniquement des données générées (cercle bleu) sont plus faibles lorsque le nombre d'échantillons est de 3000 que lorsqu'il est de 1000 est probablement parce que la qualité des données générées varie considérablement en raison de la petite quantité de données d'origine. J'imagine. Dans tous les cas, la précision n'était pas significativement améliorée par rapport au cas de l'utilisation uniquement des données d'origine, même si les données générées ont été ajoutées et apprises de la même manière qu'auparavant.
en conclusion
J'espérais que le GAN pourrait être utilisé pour gonfler les données afin d'améliorer la précision du modèle, mais cette expérience n'a pas fonctionné. Cependant, le résultat de l'utilisation uniquement des données générées n'est pas si inférieur au cas de l'utilisation uniquement des données d'origine, donc si les données d'origine ne peuvent pas être gérées librement en raison de problèmes de confidentialité ou de sécurité de l'information, de fausses données sont générées à la place. Il peut y avoir des façons de l'utiliser, comme l'utiliser pour.
Recommended Posts