Organisez les données séparées par dossier avec Python
En 3 lignes
- Obtenez la liste des dossiers
glob.glob. - Exécuter le traitement pour chaque dossier (si nécessaire)
subprocess.Popen - Utilisez
pandaspour combiner les fichiers texte de sortie de chaque dossier dansDataFrameet organiser les données.
Obtenez une liste de noms de dossier
Version standard (OK dans l'environnement standard)
import os
dir = [d for d in os.listdir(".") if os.path.isdir(d)]
Une manière plus cool (les expressions régulières peuvent être utilisées)
Windows
import glob
dir = glob.glob(os.path.join("*",""))
Mac
dir = glob.glob("*/")
Exemple d'utilisation d'expression régulière
Exemple de recherche de dossiers case01, case02, ...
dir = glob.glob(os.path.join("case*",""))
Si vous souhaitez obtenir uniquement le fichier texte (.txt).
dir = glob.glob("*.txt")
Exécuter le programme de traitement pour chaque dossier
import shutil
import subprocess
for f in dir:
# copy files from local folder to target folder
cp_files=["Addup_win.py","y.input"]
for fi in cp_files:
shutil.copy(fi,f)
# remove files at target folder
rm_files=['y.out','out.tsv']
for fi in rm_files:
if os.path.exists(os.path.join(f,fi)):
os.remove(os.path.join(f,fi))
subprocess.Popen(["python","Addup_win.py"],cwd=f)
Traitez les données texte organisées par dossier avec les pandas
Les données sont au format tabulation (.tsv), en supposant les colonnes d'index et les colonnes de données de gauche.
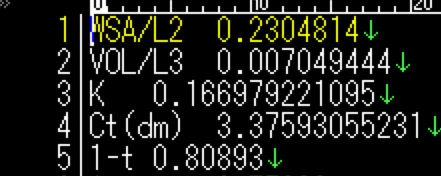
La lecture des données peut être gérée par try: car le programme de traitement ci-dessus peut échouer. Le dossier d'erreur doit être généré. Il est pratique de préparer l'index en traitant ultérieurement le nom du dossier.
import pandas as pd
dfs=pd.DataFrame()
for f in dir:
# case01\\ => case01
index_name = os.path.split(f)[0]
# Error handle
try:
# Data structure {col.0 : index, col.1 : Data}
df = pd.read_csv(os.path.join(f,"out.tsv"),sep='\t',header=None,index_col=0)
dfs[index_name]=df.iloc[:,0]
except:
print("Error in {0}".foramt(index_name))
# make index
dfs.index = df.index
Vérifions les données. (Pourquoi il y a une ligne "0", mais je m'en fiche car elle disparaîtra plus tard)
dfs.head()
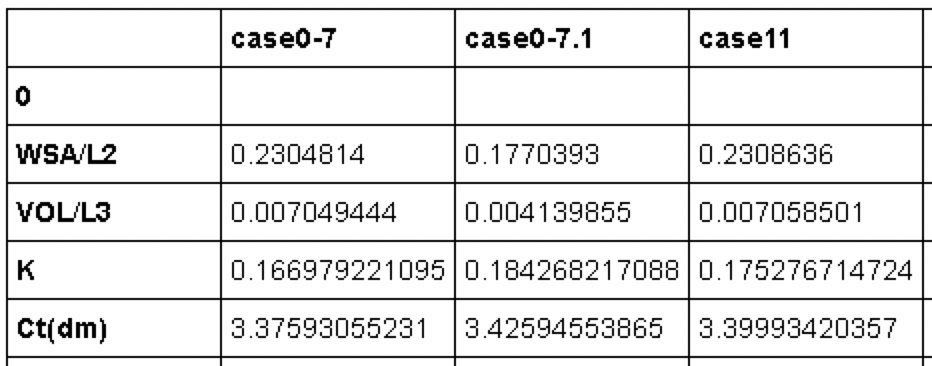
Quelque chose fait avec les pandas
Tout d'abord, il est plus facile à gérer en permutant les lignes et les colonnes.
dfsT = dfs.T
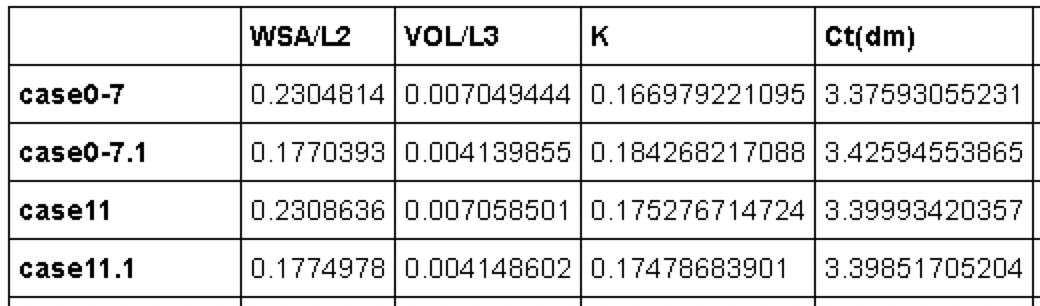
Premièrement, le traitement des données manquantes (NaN).
dfsT = dfsT.dropna()
De manière appropriée d'ici.
Par exemple, utilisez un index sophistiqué pour traiter les données conditionnelles. (Ici, un exemple dans lequel la colonne WSA / L2 génère des données de 0,2 ou plus)
dfsT_select = dfsT[dfsT["WSA/L2"] > 0.2]
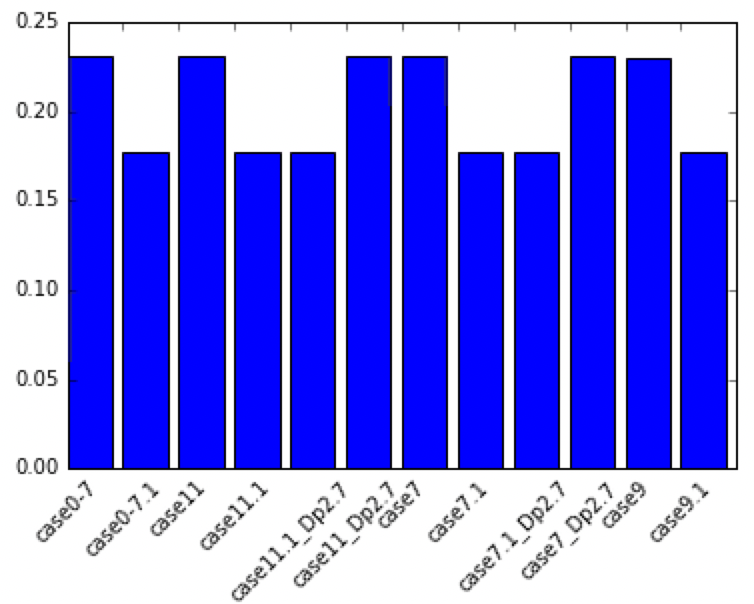
Visualisation avec matplotlib
import matplotlib.pyplot as plt
plt.bar(range(len(dfsT)),dfsT["WSA/L2"], \
tick_label=dfsT.index)
plt.show()
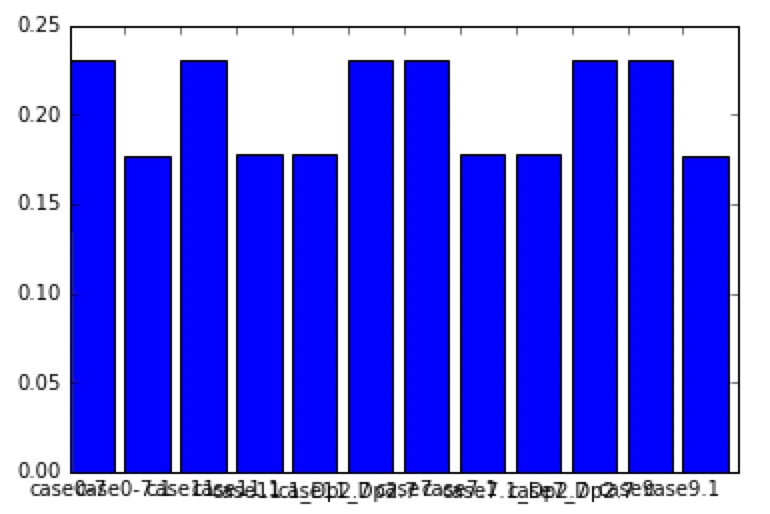
Réglage de l'axe horizontal
fig, ax = plt.subplots()
ax.bar(range(len(dfsT)),dfsT["WSA/L2"], \
tick_label=dfsT.index)
labels = ax.get_xticklabels()
plt.setp(labels, rotation=45, fontsize=10);
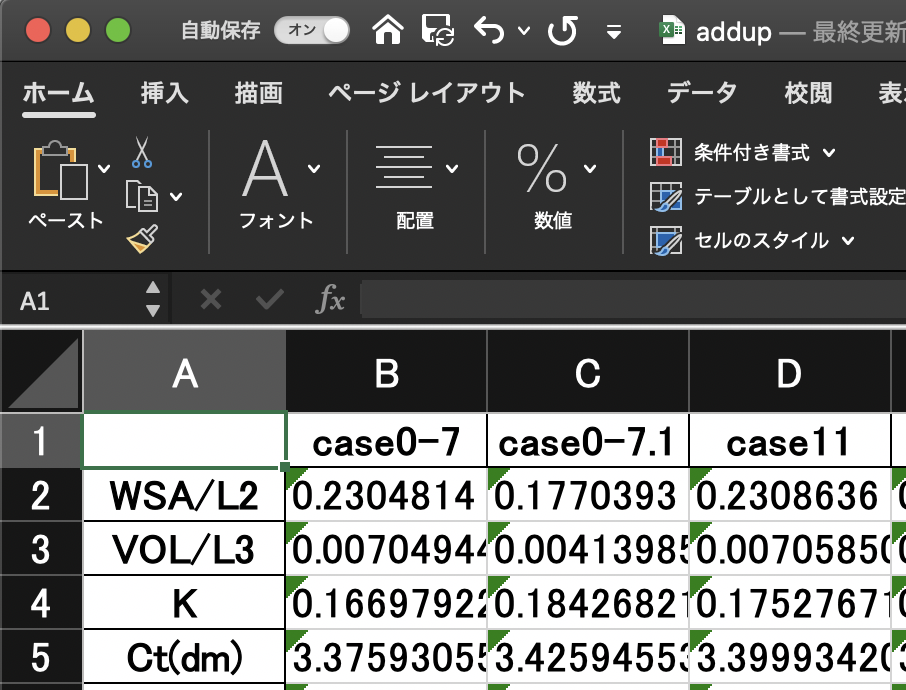
Utilisation dans Excel (sortie)
Beaucoup de gens me demandent d'utiliser Excel pour les données, je vais donc vous les donner.
dfs.to_excel("addup.xlsx")
Si le format de texte est acceptable, par exemple:
dfs.to_csv("addup.tsv",sep='\t')
Recommended Posts