[PYTHON] J'ai essayé de mettre en œuvre le chapeau de regroupement de Harry Potter avec CNN
Contexte
J'entends souvent ce genre de conversation. "Tu ressembles vraiment à Serpentard." "N'est-ce pas comme Gryffondor?" "Qu'est-ce qu'un huffle puff?" Il y a certainement des choses qui peuvent être comprises. Je pense avoir dit dans le travail que le regroupement des dortoirs dans Harry Potter est important en premier lieu, mais si l'esprit affecte le corps, les caractéristiques du regroupement ressortent également au visage. N'est-ce pas? Si c'est le cas, il devrait y avoir un montant de fonction pour chaque dortoir sur le visage! Bon apprentissage! Motivation telle que. Ce qui suit est une prévision de regroupement subjective personnelle.


Et il n'y a pas d'intention malveillante.
Environnement d'exécution
- Mac OS X 10.10.5 (Yosemite)
- Python 2.7.13_0
- Chainer 1.20.0.1_0
- Open CV 3.2.0_0 (+contrib+java+python27+qt4+vtk)
Objectif
Lorsqu'une image du visage d'une personne est entrée, un réseau neuronal de regroupement est construit qui renvoie en tant que sortie le dortoir du résultat du regroupement de visages. Puisqu'il existe quatre types de dortoirs, Gryffondor, Raven Claw, Poufsouffle et Serpentard, le réseau neuronal est un classificateur à quatre classes. Le schéma conceptuel de l'ensemble du réseau neuronal de regroupement à construire est présenté ci-dessous.

Dans la section suivante, nous nous concentrerons sur la création de jeux de données et la configuration du modèle de réseau neuronal lors de la formation.
Méthode
Comme mentionné à cet effet, cette section décrit la création de l'ensemble de données et la configuration du modèle de réseau neuronal.
Création de l'ensemble de données
Un ensemble de données a été créé à l'aide du précédent script Python de collection d'images pour créer un ensemble de données utilisé pour l'apprentissage automatique. Collectez les noms des personnages et des acteurs appartenant à chaque dortoir sous forme de requête. Enfin, il était manuellement jugé et stocké dans le répertoire de chaque dortoir s'il s'agissait de l'image du personnage correspondant. Voici quelques exemples de collections pour chaque dortoir.

La taille de l'image était de 100 x 100 pixels et le nombre d'images dans chaque dortoir était de 50, pour un total de 200 images. Evidemment, il y a beaucoup d'Occidentaux, et il y a beaucoup de biais selon les personnages. Surtout Raven Claw et Huffle Puff ne se sont pas rassemblés du tout ... trop peu ... Vingt feuilles sélectionnées au hasard ont été utilisées comme données de test pour l'apprentissage.
Configuration du modèle
Puisque les tâches sont classées en 4 classes, j'ai pensé qu'il n'était pas nécessaire d'augmenter autant l'échelle, mais j'ai fait référence à certains Alexnet. La configuration du modèle est illustrée ci-dessous.
model.py
class Model(Chain):
def __init__(self):
super(Model, self).__init__(
conv1=L.Convolution2D(3, 128, 7, stride=1),
bn2=L.BatchNormalization(128),
conv3=L.Convolution2D(128, 256, 5, stride=1),
bn4=L.BatchNormalization(256),
conv5=L.Convolution2D(256, 384, 3, stride=1),
bn6=L.BatchNormalization(384),
fc7=L.Linear(6144, 8192),
fc8=L.Linear(8192, 1024),
fc9=L.Linear(1024, 4),
)
def __call__(self, x, train=True):
h = F.max_pooling_2d(self.bn2(F.relu(self.conv1(x))), 3, stride=3)
h = F.max_pooling_2d(self.bn4(F.relu(self.conv3(h))), 3, stride=3)
h = F.max_pooling_2d(self.bn6(F.relu(self.conv5(h))), 2, stride=2)
h = F.dropout(F.relu(self.fc7(h)), train=train)
h = F.dropout(F.relu(self.fc8(h)), train=train)
y = self.fc9(h)
return y
class Classifier(Chain):
def __init__(self, predictor):
super(Classifier, self).__init__(predictor=predictor)
self.train = True
def __call__(self, x, t, train=True):
y = self.predictor(x, train)
self.loss = F.softmax_cross_entropy(y, t)
self.acc = F.accuracy(y, t)
return self.loss
Les résultats de la formation utilisant l'ensemble de données et le modèle ci-dessus seront décrits dans la section suivante.
résultat
Cette section décrit la transition d'apprentissage de l'apprenant et le résultat du réseau neuronal de regroupement implémenté.
Modèle de transition d'apprentissage
Il existe au total 200 ensembles de données, dont 180 sont des données d'apprentissage et 20 sont des données de test. La transition du taux d'erreur (taux de précision 1) de l'apprentissage et du test lorsque le nombre d'époques est de 100 est indiquée ci-dessous.

Puisque le test_error le plus bas était de 0,15, on peut dire que ce modèle a montré une précision de 85% dans la classification en 4 classes.
Regroupement du résultat de l'exécution du réseau neuronal
Le résultat lorsqu'une image réelle est entrée dans le réseau neuronal de regroupement incorporant le modèle entraîné est affiché.


Je ne connais pas la réponse, mais pour le moment, j'ai pu confirmer la sortie souhaitée pour l'entrée! Comme prévu, Hiroshi Abe a été regroupé en Gryffondor et Ariyoshi en Serpentard, tandis que Gacky et Becky étaient regroupés exactement de la manière opposée. Mais Serpentard Gacky n'est pas mal non plus. Je veux être victime d'intimidation. C'est un peu amusant, alors j'ai cherché une image qui puisse juger un grand nombre de personnes à la fois et je l'ai saisie.
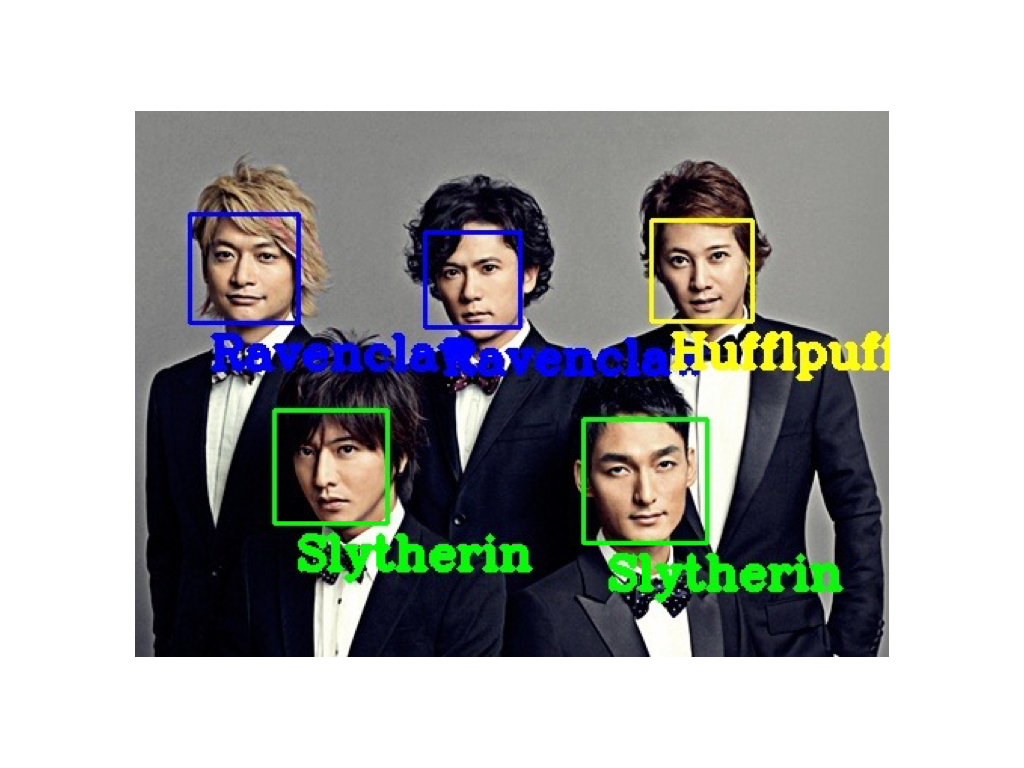
Quand je suis entré dans l'ancien groupe national d'idols SMAP (Sports Music Assemble People), j'ai obtenu ce résultat. Même un grand nombre de personnes peuvent y aller en même temps! De plus, le résultat est assez convaincant! Lol J'ai joué avec, mais c'est amusant parce que je n'ai pas à assumer la responsabilité de l'exactitude parce que la réponse n'est pas la réponse en premier lieu. Voici quelques façons simples de jouer.
comment jouer
Code source pour regrouper les réseaux de neurones: GitHub De plus, le modèle entraîné cette fois-ci est placé dans ici. En guise d'utilisation simple, vous pouvez jouer en plaçant le modèle appris que vous avez déposé dans le répertoire cloné et en exécutant la commande suivante. Notez également que la partie reconnaissance faciale utilise [haarcascade] d'OpenCV (https://github.com/opencv/opencv/tree/master/data/haarcascades), alors créez un répertoire haarcascade. Il est nécessaire de placer un modèle formé à la reconnaissance faciale (tel que haarcascade_frontalface_default.xml) directement en dessous. Vous pouvez réécrire le chemin qui fait référence au modèle dans votre code.
$ python main.py -i ImagePath -m ./LearnedModel.model -p 1
De plus, comme point à noter lors de la lecture, si la première reconnaissance faciale est réussie, le résultat du regroupement sera étiqueté pour chaque visage, vous devez donc faire attention à saisir une image du visage qui se prend dans la reconnaissance faciale d'OpenCV. Cela ne devient pas. La précision de la reconnaissance faciale dépend également du modèle formé, vous devez donc essayer diverses choses sans abandonner même si vous faites une erreur une fois.
Considération
Le nombre de données d'apprentissage affecte grandement les résultats d'apprentissage, mais cette fois, les acteurs de chaque dortoir apparaissant dans le film étaient trop biaisés, nous n'avons donc pas pu recueillir un nombre satisfaisant. Même dans ce cas, le fait que le taux de réponse correcte atteigne 85% peut signifier que nous avons saisi certaines caractéristiques de chaque dortoir. En termes de nombre d'échantillons humains, il n'est pas étrange que le même visage soit inclus dans la validation, il semble donc qu'environ 85% sera tenu pour acquis ... De plus, bien qu'AlexNet ait cette fois été utilisé comme référence pour la configuration du modèle, l'image d'entrée est supposée être 100 x 100, nous avons donc décidé qu'il n'était pas nécessaire de créer le modèle avec un degré de liberté aussi élevé, nous avons donc réduit la couche de pliage. De plus, les performances de généralisation peuvent s'être améliorées si le noyau a rendu les couches 7x7 et 5x5 un peu plus profondes. Je n'ai pas réglé si sérieusement, donc je peux encore m'attendre à une amélioration de la précision si je fais une recherche aléatoire.
Ariyoshi était en quelque sorte satisfait de Serpentard. Au fait, j'étais Gryffondor. Je l'ai fait.
Recommended Posts