[PYTHON] J'ai essayé de mettre en œuvre la gestion des processus statistiques multivariés (MSPC)
- Articles envoyés par des data scientists de l'industrie manufacturière
- Cette fois, nous avons mis en place et organisé des méthodes de détection d'anomalies utilisables dans l'industrie manufacturière.
introduction
Récemment, je pense que les efforts qui utilisent l'apprentissage automatique ont commencé à augmenter, même dans l'industrie manufacturière. Cette fois, nous avons organisé la gestion des processus statistiques multivariés (MSPC) utilisée dans le projet de détection des anomalies.
Qu'est-ce que la détection d'anomalies dans l'industrie manufacturière?
Dans l'industrie manufacturière, il existe le terme de maintenance préventive. La maintenance préventive fait référence aux méthodes de maintenance qui empêchent les pannes, les dysfonctionnements et la dégradation des performances des équipements mécaniques sur la ligne de production, et sont effectuées dans le but d'empêcher l'équipement de se casser et la chaîne de production de s'arrêter. De plus, il existe également une détection d'anomalie de fonctionnement pour empêcher la production de produits anormaux d'un fonctionnement normal.
La méthode de détection des anomalies (MSPC) introduite cette fois est une méthode qui peut être utilisée pour les deux.
Qu'est-ce que la gestion des processus statistiques multivariés (MSPC)?
Lorsqu'elles sont utilisées avec MSPC, les données utilisées ne sont que des données normales pour la formation. Généralement, lors de la classification par apprentissage automatique, etc., il est facile de penser qu'une classification appropriée ne peut être effectuée que si des échantillons du même niveau de données normales et de données anormales sont collectés, mais dans le domaine réel, il n'y a presque pas de données anormales et c'est normal. Il y a beaucoup de données seulement. (En fait, puisque cela signifie "données anormales = panne d'équipement", ce sont les données lorsque la production de l'usine est arrêtée. Il est naturel qu'il y ait peu de telles données. Par conséquent, sur le site de fabrication, nous nous concentrerons sur la maintenance préventive. Nous l'avons mis en place et nous menons des activités de conservation à un niveau légèrement excessif.)
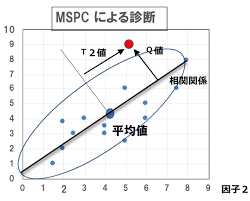
L'idée de base de la détection d'anomalies est de définir une zone dans laquelle des données normales existent dans un espace multidimensionnel, et lors de l'observation de données qui s'écartent de cette zone, elles sont considérées comme une anomalie. Par conséquent, il est possible de construire un modèle de détection d'anomalies en apprenant uniquement les données normales.
Ensuite, nous expliquerons comment définir la limite de gestion, qui est la frontière entre l'état normal et l'état anormal. C'est un peu offensant, mais il existe généralement une sorte de relation (corrélation) entre les variables, et il est nécessaire de saisir la relation entre les variables pour déterminer correctement la zone contenant des données normales. En d'autres termes, il est nécessaire de préparer une ellipse pour deux variables et une super ellipse pour n variables. MCPC utilise l'analyse en composantes principales (ACP) pour calculer la distance de Maharanobis comme méthode de considération des relations entre les variables. MSPC est une méthode qui utilise PCA pour créer une super-ellipse, définir une limite de gestion et déterminer si les données s'en écartent.
MSPC utilise PCA pour normaliser la dispersion de chaque composant principal à 1, et ne standardise pas tous les composants principaux à la dispersion 1 lors du calcul de la distance Maharanobis. Calculez la distance par rapport à l'origine en ne standardisant que les principales composantes principales de la dispersion 1. Le carré de cette distance est appelé la statistique T ^ 2 $ de $ Hotelling. D'autre part, la composante principale non majeure est appelée la statistique Q (erreur de prédiction au carré) et est définie par le carré de la distance (erreur de prédiction) du sous-espace couvert par la composante principale principale.
Résumé de MSPC
La procédure du MSPC est organisée ci-dessous.
- Obtenez des données normales
- Utilisez PCA pour les données normales
- Déterminer le nombre de composants principaux principaux
- Le composant principal principal calcule la statistique $ T ^ 2 $ et les autres composants principaux calculent la statistique $ Q $.
- Définissez des limites de gestion pour les statistiques $ T ^ 2 $ et les statistiques $ Q $
Implémentation MSPC
Cette fois, nous avons préparé les données (nombre d'échantillons de données: 2 756, nombre de colonnes: 90) pour le test. Nous avons utilisé 1 000 données normales et les 1 756 restantes comme données d'évaluation pour voir à quel point elles s'écartaient de l'état normal.
Le code python est ci-dessous.
#Importer les bibliothèques requises
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
%matplotlib inline
from sklearn.preprocessing import StandardScaler
from scipy import stats
from sklearn.neighbors.kde import KernelDensity
from sklearn.decomposition import PCA
df = pd.read_csv('test_data.csv', encoding='shift_jis', header=1, index_col=0)
df.head()
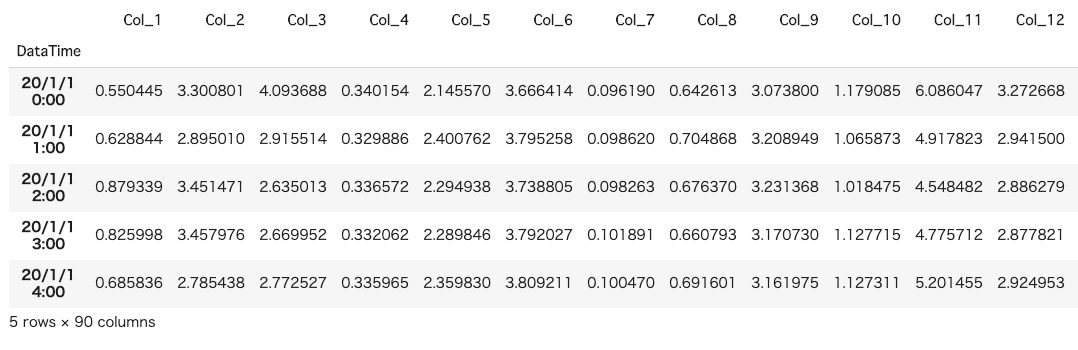
Les données d'entrée ressemblent à celles ci-dessus. Cette fois, nous mettons des nombres aléatoires dans chaque colonne.
Ensuite, nous diviserons les données d'entraînement et les données d'évaluation et les normaliserons.
#Point de partage
split_point = 1000
#Divisé en données d'entraînement (train) et données d'évaluation (test)
train_df = df.iloc[:(split_point-1),]
test_df = df.iloc[split_point:,]
#Standardiser les données
sc = StandardScaler()
sc.fit(train_df)
train_df_std = sc.transform(train_df)
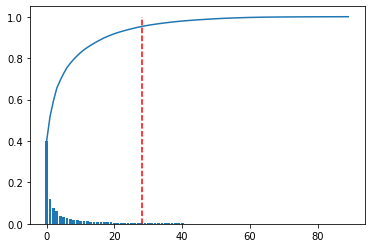
Ensuite, nous effectuerons une analyse en composantes principales pour déterminer les principales composantes principales. Cette fois, la composante principale était la partie où le taux de cotisation cumulatif atteignait 95%.
# PCA
pca = PCA()
pca.fit(train_df_std)
#Graphique de contribution cumulée
plt.figure()
variance = pca.explained_variance_ratio_
variance_total = np.zeros(np.shape(variance)[0])
plt.bar(range(np.shape(variance)[0]), variance)
for i in range(np.shape(variance)[0]):
variance_total[i] = np.sum(variance[0:i+1])
plt.plot(variance_total)
NumOfScore = np.min(np.where(variance_total>0.95))
x1=[NumOfScore,NumOfScore]
y1=[0,1]
plt.plot(x1,y1,ls="--", color = "r")
pca = PCA(n_components = NumOfScore)
pca.fit(train_df_std)
Ensuite, trouvez la statistique Q.
#Statistiques Q
scores = pca.transform(train_df_std)
residuals = pca.inverse_transform(scores)-train_df_std
dist = np.sqrt(np.sum(np.power(residuals,2),axis=1))/(np.shape(train_df_std)[1])
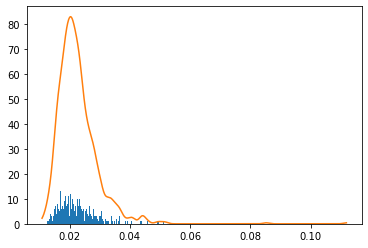
Puisque nous devons définir la limite de contrôle à partir des données normales, nous définissons la limite de contrôle en utilisant l'estimation de la densité du noyau.
#Limite de contrôle (estimation de la densité du noyau)
cr = 0.99
X = dist.reshape(np.shape(dist)[0],1)
bw= (np.max(X)-np.min(X))/100
kde = KernelDensity(kernel='gaussian', bandwidth=bw).fit(X)
X_plot = np.linspace(np.min(X), np.max(X), 1000)[:, np.newaxis]
log_dens = kde.score_samples(X_plot)
plt.figure()
plt.hist(X, bins=X_plot[:,0])
plt.plot(X_plot[:,0],np.exp(log_dens))
prob = np.exp(log_dens) / np.sum(np.exp(log_dens))
calprob = np.zeros(np.shape(prob)[0])
calprob[0] = prob[0]
for i in range(1,np.shape(prob)[0]):
calprob[i]=calprob[i-1]+prob[i]
cl = X_plot[np.min(np.where(calprob>cr))]
Ensuite, vérifiez si les données de test ne sortent pas de la zone de données normale.
#Standardiser les données
test_df_std = sc.transform(test_df)
# Test Data
newscores = pca.transform(test_df_std)
newresiduals = pca.inverse_transform(newscores)-test_df_std
newdist = np.sqrt(np.sum(np.power(newresiduals,2),axis=1))/(np.shape(test_df_std)[1])
Enfin, définissez les limites de contrôle calculées par les statistiques Q (y compris les données d'apprentissage et de test) et l'estimation de la densité du noyau.
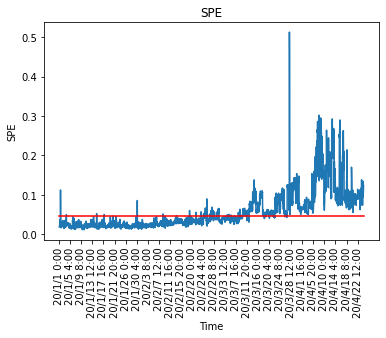
#Graphique des statistiques Q
SPE = np.r_[dist,newdist]
plt.figure()
x = range(0,np.shape(df.index)[0],100)
NewTimeIndices = np.array(df.index[x])
x2 = [0, np.shape(SPE)[0]]
y2 = [cl,cl]
plt.title('SPE')
plt.plot(SPE)
plt.xticks(x,NewTimeIndices,rotation='vertical')
plt.plot(x2,y2,ls="-", color = "r")
#plt.ylim([0,1])
plt.xlabel("Time")
plt.ylabel("SPE")
# contribution plot
plt.figure()
total_residuals= np.r_[residuals,newresiduals]
CspeTimeseries = np.power(total_residuals,2)
cspe_summary=np.zeros([np.shape(CspeTimeseries)[0],10])
En fait, le tracé de contribution est calculé à partir d'ici, et lorsque la limite de contrôle est dépassée, la variable explicative affecte et devient anormale est calculée. Vous pouvez également gérer le diagramme de gestion $ T ^ 2 $ de la même manière, et vérifier quelles variables explicatives affectent le dépassement de la limite de gestion.
En utilisant MSPC, il est possible de surveiller les données du capteur avec 90 variables avec deux diagrammes de gestion, et il est possible d'identifier quel capteur est anormal lorsque l'alarme retentit, donc la charge de surveillance sur le site de fabrication Va aussi tomber. Il est également possible d'utiliser la PCA du noyau au lieu de la PCA si les relations entre les variables ne sont pas linéaires.
enfin
Merci d'avoir lu jusqu'au bout. Cette fois, nous avons implémenté la méthode de détection d'anomalies (MSPC) requise sur le site de fabrication. Dans le domaine réel, il existe de nombreux facteurs de réglage tels que la méthode par défaut de l'état normal et le réglage de la limite de gestion, mais je pense qu'il est préférable de définir tout en opérant sur le terrain.
Si vous avez une demande de correction, nous vous serions reconnaissants de bien vouloir nous contacter.
Recommended Posts