[PYTHON] J'ai essayé de déplacer Faster R-CNN rapidement avec pytorch
introduction
Notez que j'ai eu beaucoup de problèmes car il y avait peu d'articles exécutant Faster R-CNN avec un ensemble de données approprié.
Puisque c'est mon premier message, je pense qu'il y a des choses qui ne peuvent pas être atteintes, mais si vous avez des erreurs, veuillez le signaler.
Remarques
- Cet article concerne les ** ensembles de données au format PSCAL VOC **. J'ai converti l'ensemble de données appelé BDD100K au format Pascal VOC et formé, donc l'étiquette de classe est celle de BDD100K.
code
Tout le code va à github. (Si vous copiez et collez tout le code ci-dessous et faites correspondre le nom de la classe à l'ensemble de données, cela devrait fonctionner)
importer
Croustillant
import numpy as np
import pandas as pd
from PIL import Image
from glob import glob
import xml.etree.ElementTree as ET
import torch
import torchvision
from torchvision import transforms
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
dataloader.py
#Emplacement des données
xml_paths_train=glob("##########/*.xml")
xml_paths_val=glob("###########/*.xml")
image_dir_train="#############"
image_dir_val="##############"
Les deux premières lignes sont l'emplacement du fichier xml Les deux lignes sont l'emplacement de l'image
Lire les données
dataloader.py
class xml2list(object):
def __init__(self, classes):
self.classes = classes
def __call__(self, xml_path):
ret = []
xml = ET.parse(xml_path).getroot()
for size in xml.iter("size"):
width = float(size.find("width").text)
height = float(size.find("height").text)
for obj in xml.iter("object"):
difficult = int(obj.find("difficult").text)
if difficult == 1:
continue
bndbox = [width, height]
name = obj.find("name").text.lower().strip()
bbox = obj.find("bndbox")
pts = ["xmin", "ymin", "xmax", "ymax"]
for pt in pts:
cur_pixel = float(bbox.find(pt).text)
bndbox.append(cur_pixel)
label_idx = self.classes.index(name)
bndbox.append(label_idx)
ret += [bndbox]
return np.array(ret) # [width, height, xmin, ymin, xamx, ymax, label_idx]
Chargement des annotations
Pour les classes, saisissez ** la classe de données utilisée **.
dataloader.py
#Chargement d'une annotation de train
xml_paths=xml_paths_train
classes = [###################################]
transform_anno = xml2list(classes)
df = pd.DataFrame(columns=["image_id", "width", "height", "xmin", "ymin", "xmax", "ymax", "class"])
for path in xml_paths:
#image_id = path.split("/")[-1].split(".")[0]
image_id = path.split("\\")[-1].split(".")[0]
bboxs = transform_anno(path)
for bbox in bboxs:
tmp = pd.Series(bbox, index=["width", "height", "xmin", "ymin", "xmax", "ymax", "class"])
tmp["image_id"] = image_id
df = df.append(tmp, ignore_index=True)
df = df.sort_values(by="image_id", ascending=True)
#Lecture de la val anotation
xml_paths=xml_paths_val
classes = [#######################]
transform_anno = xml2list(classes)
df_val = pd.DataFrame(columns=["image_id", "width", "height", "xmin", "ymin", "xmax", "ymax", "class"])
for path in xml_paths:
#image_id = path.split("/")[-1].split(".")[0]
image_id = path.split("\\")[-1].split(".")[0]
bboxs = transform_anno(path)
for bbox in bboxs:
tmp = pd.Series(bbox, index=["width", "height", "xmin", "ymin", "xmax", "ymax", "class"])
tmp["image_id"] = image_id
df_val = df_val.append(tmp, ignore_index=True)
df_val = df_val.sort_values(by="image_id", ascending=True)
Chargement des images
dataloader.py
#Chargement des images
#Le chien a besoin d'une classe d'arrière-plan (0),1 étiquette de départ pour chat
df["class"] = df["class"] + 1
class MyDataset(torch.utils.data.Dataset):
def __init__(self, df, image_dir):
super().__init__()
self.image_ids = df["image_id"].unique()
self.df = df
self.image_dir = image_dir
def __getitem__(self, index):
transform = transforms.Compose([
transforms.ToTensor()
])
#Chargement de l'image d'entrée
image_id = self.image_ids[index]
image = Image.open(f"{self.image_dir}/{image_id}.jpg ")
image = transform(image)
#Lecture des données d'annotation
records = self.df[self.df["image_id"] == image_id]
boxes = torch.tensor(records[["xmin", "ymin", "xmax", "ymax"]].values, dtype=torch.float32)
area = (boxes[:, 3] - boxes[:, 1]) * (boxes[:, 2] - boxes[:, 0])
area = torch.as_tensor(area, dtype=torch.float32)
labels = torch.tensor(records["class"].values, dtype=torch.int64)
iscrowd = torch.zeros((records.shape[0], ), dtype=torch.int64)
target = {}
target["boxes"] = boxes
target["labels"]= labels
target["image_id"] = torch.tensor([index])
target["area"] = area
target["iscrowd"] = iscrowd
return image, target, image_id
def __len__(self):
return self.image_ids.shape[0]
image_dir1=image_dir_train
dataset = MyDataset(df, image_dir1)
image_dir2=image_dir_val
dataset_val = MyDataset(df_val, image_dir2)
Créer un DataLoader
dataloader.py
#Chargement des données
torch.manual_seed(2020)
train=dataset
val=dataset_val
def collate_fn(batch):
return tuple(zip(*batch))
train_dataloader = torch.utils.data.DataLoader(train, batch_size=1, shuffle=True, collate_fn=collate_fn)
val_dataloader = torch.utils.data.DataLoader(val, batch_size=2, shuffle=False, collate_fn=collate_fn)
Le batch_size est petit car la mémoire du GPU a débordé immédiatement lorsque je l'ai tourné.
Définition du modèle
Si vous souhaitez améliorer la précision même avec un petit nombre d'apprentissage, nous vous recommandons ** model1.py **. Je veux juste jouer avec le modèle dans une certaine mesure! Veuillez utiliser ** model2.py **. (Model2 n'a presque pas d'article de commentaire, et je m'inquiétais pour toujours parce que le code source du tutoriel de torchvision était erroné.)
*** Attention, num_classes ne fonctionnera que si le nombre de classes que vous souhaitez classer est +1. (+1 parce que l'arrière-plan est également soumis à une classification) **
model1 utilise normalement un modèle entraîné avec resnet50 comme backbone
model1.py
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=False)####True
##Remarque: nombre de classes + 1
num_classes = (len(classes)) + 1
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
model2 ressemble à ceci (il y a un bug dans le tutoriel ...)
model2.py
import torchvision
from torchvision.models.detection import FasterRCNN
from torchvision.models.detection.rpn import AnchorGenerator
backbone = torchvision.models.mobilenet_v2(pretrained=True).features
backbone.out_channels = 1280
anchor_generator = AnchorGenerator(sizes=((32, 64, 128, 256, 512),),
aspect_ratios=((0.5, 1.0, 2.0),))
#Lorsque le didacticiel est compressé, une erreur est renvoyée ici.([0]À['0']Si vous le définissez sur)
'''
roi_pooler = torchvision.ops.MultiScaleRoIAlign(featmap_names=[0],
output_size=7,
sampling_ratio=2)
'''
#Par défaut
roi_pooler =torchvision.ops.MultiScaleRoIAlign(
featmap_names=['0','1','2','3'],
output_size=7,
sampling_ratio=2)
# put the pieces together inside a FasterRCNN model
model = FasterRCNN(backbone,
num_classes=(len(classes)) + 1,###Mise en garde
rpn_anchor_generator=anchor_generator)
#box_roi_pool=roi_pooler)
La fonction FasterRCNN a divers arguments et vous pouvez jouer un peu avec le modèle. Pour plus d'informations ici
Apprentissage
La différenciation automatique est merveilleuse
train.py
##Apprentissage
params = [p for p in model.parameters() if p.requires_grad]
optimizer = torch.optim.SGD(params, lr=0.005, momentum=0.9, weight_decay=0.0005)
num_epochs = 5
#Effacer le cache du GPU
import torch
torch.cuda.empty_cache()
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
##model.cuda()
model.train()#Passer en mode d'apprentissage
for epoch in range(num_epochs):
for i, batch in enumerate(train_dataloader):
images, targets, image_ids = batch#####batch est l'image et les cibles du mini-batch,image_Contient des identifiants
images = list(image.to(device) for image in images)
targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
##Image et cible (sol) en mode apprentissage-vérité)
##La valeur de retour est dict[tensor]Il y a une perte là-dedans. (Perte de RPN et RCNN)
loss_dict= model(images, targets)
losses = sum(loss for loss in loss_dict.values())
loss_value = losses.item()
optimizer.zero_grad()
losses.backward()
optimizer.step()
if (i+1) % 20 == 0:
print(f"epoch #{epoch+1} Iteration #{i+1} loss: {loss_value}")
Voir les résultats
Remarque: saisissez ici le libellé des données d'utilisation conformément à l'exemple de saisie de la catégorie.
test.py
#Voir les résultats
def show(val_dataloader):
import matplotlib.pyplot as plt
from PIL import ImageDraw, ImageFont
from PIL import Image
#Effacer le cache du GPU
import torch
torch.cuda.empty_cache()
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
#device = torch.device('cpu')
model.to(device)
model.eval()#Vers le mode inférence
images, targets, image_ids = next(iter(val_dataloader))
images = list(img.to(device) for img in images)
#Renvoie une prédiction lors de l'inférence
'''
- boxes (FloatTensor[N, 4]): the predicted boxes in [x1, y1, x2, y2] format, with values of x
between 0 and W and values of y between 0 and H
- labels (Int64Tensor[N]): the predicted labels for each image
- scores (Tensor[N]): the scores or each prediction
'''
outputs = model(images)
for i, image in enumerate(images):
image = image.permute(1, 2, 0).cpu().numpy()
image = Image.fromarray((image * 255).astype(np.uint8))
boxes = outputs[i]["boxes"].data.cpu().numpy()
scores = outputs[i]["scores"].data.cpu().numpy()
labels = outputs[i]["labels"].data.cpu().numpy()
category={0: 'background',##################}
#Exemple d'entrée de catégorie
#category={0: 'background',1:'person', 2:'traffic light',3: 'train',4: 'traffic sign', 5:'rider', 6:'car', 7:'bike',8: 'motor', 9:'truck', 10:'bus'}
boxes = boxes[scores >= 0.5].astype(np.int32)
scores = scores[scores >= 0.5]
image_id = image_ids[i]
for i, box in enumerate(boxes):
draw = ImageDraw.Draw(image)
label = category[labels[i]]
draw.rectangle([(box[0], box[1]), (box[2], box[3])], outline="red", width=3)
#Affichage de l'étiquette
from PIL import Image, ImageDraw, ImageFont
#fnt = ImageFont.truetype('/content/mplus-1c-black.ttf', 20)
fnt = ImageFont.truetype("arial.ttf", 10)#40
text_w, text_h = fnt.getsize(label)
draw.rectangle([box[0], box[1], box[0]+text_w, box[1]+text_h], fill="red")
draw.text((box[0], box[1]), label, font=fnt, fill='white')
#Pour quand vous souhaitez enregistrer une image
#image.save(f"resample_test{str(i)}.png ")
fig, ax = plt.subplots(1, 1)
ax.imshow(np.array(image))
plt.show()
show(val_dataloader)
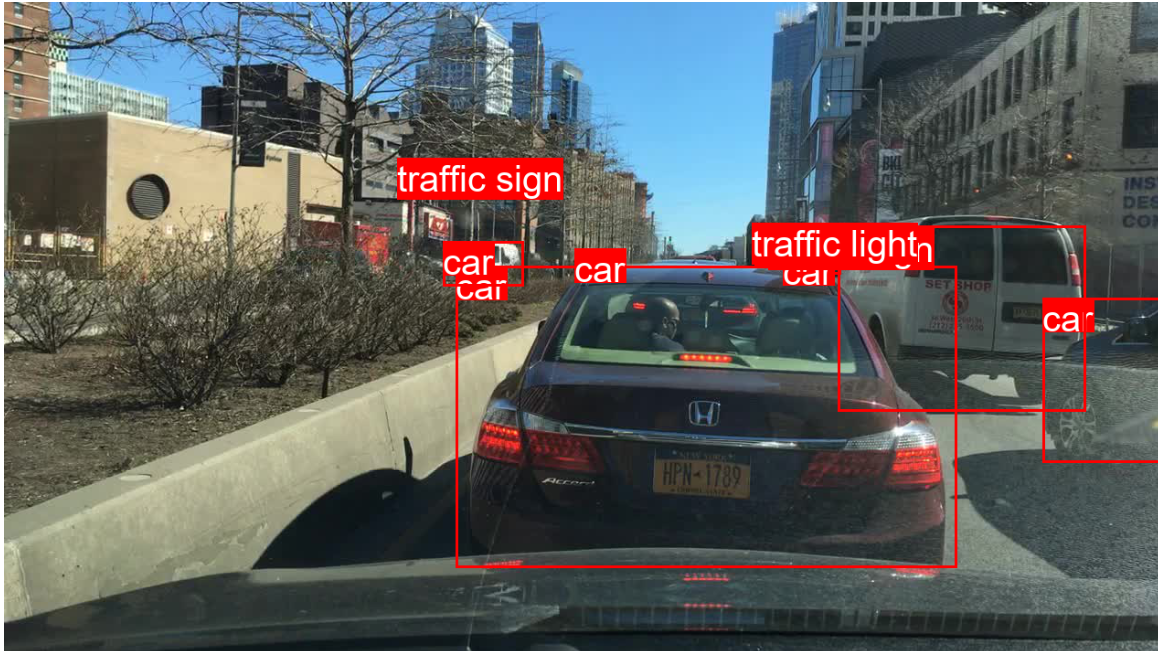
Il devrait être affiché comme ceci
finalement
«J'ai écrit un article pour la première fois. C'est presque comme simplement coller le code source, mais j'espère que vous pourrez vous y référer. ――Je voudrais essayer un commentaire papier
Les références
- http://maruo51.com/2020/06/06/faster-rcnn_dogcat/
--Cliquez ici pour accéder au didacticiel torchvision [https://colab.research.google.com/github/pytorch/vision/blob/temp-tutorial/tutorials/torchvision_finetuning_instance_segmentation.ipynb#scrollTo=UYDb7PBw55b-)
Recommended Posts