[PYTHON] Résumé des sources de données scikit-learn pouvant être utilisées lors de la rédaction d'articles d'analyse
introduction
Cet article utilise Python 2.7, numpy 1.11, scipy 0.17, scikit-learn 0.18, matplotlib 1.5. Il a été confirmé qu'il fonctionne sur le notebook jupyter. Sur la base des utilitaires de chargement de données, nous avons résumé les sources de données qui peuvent être rapidement préparées lors de la rédaction d'un article. Certaines spécifications ont changé entre la version 0.18 et les versions antérieures. Il sera mis à jour séquentiellement chaque fois que les données d'échantillon sont utilisées.
table des matières
-
loading dataset
- iris
- boston
- diabetes
- digits
- linnerud
-
Generating dataset
- blobs
- make_classification
-
Référence
-
Loading dataset Utilisez Lorder de Sklearn pour charger des échantillons de données pré-préparés. Utilitaires de chargement de données présente 5 données sous forme d'ensembles de données de jouets. Ceux-ci peuvent être acquis hors ligne car la quantité de données n'est pas importante (environ 100 échantillons). [Cet article](http://pythondatascience.plavox.info/scikit-learn/scikit-learn%E3%81%AB%E4%BB%98%E5%B1%9E%E3%81%97%E3% 81% A6% E3% 81% 84% E3% 82% 8B% E3% 83% 87% E3% 83% BC% E3% 82% BF% E3% 82% BB% E3% 83% 83% E3% 83% Comme il a été résumé en détail dans 88 /), je ne présenterai que brièvement les données.
1.1. iris Obtenez des données d'iris de base avec un objet bunch. (Il peut être obtenu en combinant les données et l'étiquette en définissant load_iris (return_X_y = True) à partir de ver0.18) Utilisé pour les problèmes de classification.
load_iris.py
from sklearn.datasets import load_iris
data = load_iris()
print data.target_names
print data.target[:10]
print data.data[:10]
Lors de l'exécution, trois noms d'étiquettes, des étiquettes de données et des paramètres à quatre dimensions sont obtenus. La taille est de 50 échantillons pour chaque étiquette. Exemple d'exécution:
['setosa' 'versicolor' 'virginica']
[0 0 0 0 0 0 0 0 0 0]
[[ 5.1 3.5 1.4 0.2]
[ 4.9 3. 1.4 0.2]
[ 4.7 3.2 1.3 0.2]
[ 4.6 3.1 1.5 0.2]
[ 5. 3.6 1.4 0.2]
[ 5.4 3.9 1.7 0.4]
[ 4.6 3.4 1.4 0.3]
[ 5. 3.4 1.5 0.2]
[ 4.4 2.9 1.4 0.2]
[ 4.9 3.1 1.5 0.1]]
1.2. boston Il s'agit d'un ensemble de données de 13 types d'informations sur la périphérie de Boston et les prix des logements par région. Il peut être utilisé pour des problèmes de régression.
| Le nombre d'échantillons | Nombre de dimensions | Fonctionnalité | étiquette |
|---|---|---|---|
| 506 | 13 | real x>0 | real 5<y<50 |
Description des paramètres (12)
- CRIM: nombre de crimes par habitant
- Pourcentage de zones résidentielles de plus de 25 000 pieds carrés
- INDUS: Pourcentage du commerce hors vente au détail
- CHAS: variable factice de Charles River (1: Autour de la rivière, 0: Autre)
- NOX: concentration de NOx
- RM: nombre moyen de chambres dans la résidence
- AGE: Pourcentage de propriétés construites avant 1940
- DIS: Distance de 5 établissements d'emploi de Boston (pondérée)
- RAD: accès facile à l'autoroute circulaire
- TAXE: Taux total de la taxe foncière par 10 000 $
- PTRATIO: ratio enfants-enseignants par ville
- B: Le rapport des noirs (Bk) dans chaque ville est exprimé par la formule suivante. 1000 (Bk - 0,63) ^ 2
- LSTAT: Pourcentage de la population exerçant des professions faiblement rémunérées (%)
La figure ci-dessous représente le taux de criminalité par personne artificielle et le prix du logement par région dans la banlieue de Boston.

1.3. diabetes Valeurs de test de 442 patients diabétiques et progression de la maladie un an plus tard. Utilisé pour les problèmes de régression.
| Le nombre d'échantillons | Nombre de dimensions | Fonctionnalité | étiquette |
|---|---|---|---|
| 442 | 10 | real -2>x>2 | int 25<y<346 |
1.4. digits Un nombre manuscrit de 10 caractères de 0 à 9 décomposé en 64 (8 x 8) pixels. Utilisé pour la reconnaissance d'image.
| Le nombre d'échantillons | Nombre de dimensions | Fonctionnalité | étiquette |
|---|---|---|---|
| 1.797 | 64 | int 0<x<16 | int 0<y<9 |
1.5. Linnerud Relation entre 3 caractéristiques physiologiques et 3 performances sportives mesurées dans un club de fitness pour 20 hommes adultes, créé par le Dr A. C. Linnerud de la North Carolina State University. Utilisé pour l'analyse multivariée.
| Le nombre d'échantillons | Nombre de dimensions |
|---|---|
| 20 | Variable explicative:3,Variable objective:3 |
Contenu des variables explicatives
Chins Situps Jumps
0 5 162 60
1 2 110 60
2 12 101 101
3 12 105 37
4 13 155 58
Contenu de la variable objective
Weight Waist Pulse
0 191 36 50
1 189 37 52
2 193 38 58
3 162 35 62
- Generating dataset Utilisez le générateur d'échantillons pour générer à chaque fois des données caractéristiques. Vous pouvez générer autant de données que vous le souhaitez avec des caractéristiques spécifiques.
2.1. blobs Génère des données qui ressemblent à un étalement central des taches. Vous pouvez sélectionner le nombre d'échantillons et le nombre de clusters dans n_samples et centres, respectivement. Vous pouvez définir le nombre d'étiquettes avec n_features.
make_blobs.py
from sklearn.datasets.samples_generator import make_blobs
X, y = make_blobs(n_samples=10, centers=3, n_features=2, random_state=0)
print(X.shape)
Exemple d'exécution:
array([[ 1.12031365, 5.75806083],
[ 1.7373078 , 4.42546234],
[ 2.36833522, 0.04356792],
[ 0.87305123, 4.71438583],
[-0.66246781, 2.17571724],
[ 0.74285061, 1.46351659],
[-4.07989383, 3.57150086],
[ 3.54934659, 0.6925054 ],
[ 2.49913075, 1.23133799],
[ 1.9263585 , 4.15243012]])
Sample génère 3 ensembles de données dans 2 classes faites.
(Avant la version 0.18, j'obtiens une erreur dans train_test_split)
2.2. make_classification Lorsque vous souhaitez traiter des problèmes de classification, vous pouvez générer des données multidimensionnelles et chaque étiquette. Il y avait une explication détaillée sur ce site. Fondamentalement, en ajustant n_features, n_classes et n_informative, il est possible de générer des données qui incluent des corrélations.
| Parameter name | Description | Default |
|---|---|---|
| n_features | Nombre de dimensions de données à générer | 20 |
| n_classes | Nombre d'étiquettes | 2 |
| n_informative | Nombre de distributions normales utilisées dans le processus de génération de données | 2 |
| n_cluster_per_class | Nombre de distributions normales dans chaque étiquette | 2 |
make_classification.py
from sklearn.datasets import make_classification
import matplotlib.pyplot as plt
%matplotlib inline
X1, Y1 = make_classification(n_samples=1000, n_features=2, n_redundant=0, n_informative=2,n_clusters_per_class=2, n_classes=2)
plt.scatter(X1[:, 0], X1[:, 1], marker='o', c=Y1)
Exemple d'exécution:
(Comme il est sélectionné au hasard parmi les fonctionnalités informatives et les fonctions Redundunt, le tracé change d'une exécution à l'autre.)

exemple scikit-learn
Il y avait un [exemple] facile à comprendre (http://scikit-learn.org/stable/auto_examples/datasets/plot_random_dataset.html#sphx-glr-auto-examples-datasets-plot-random-dataset-py). Veuillez également vous référer à.
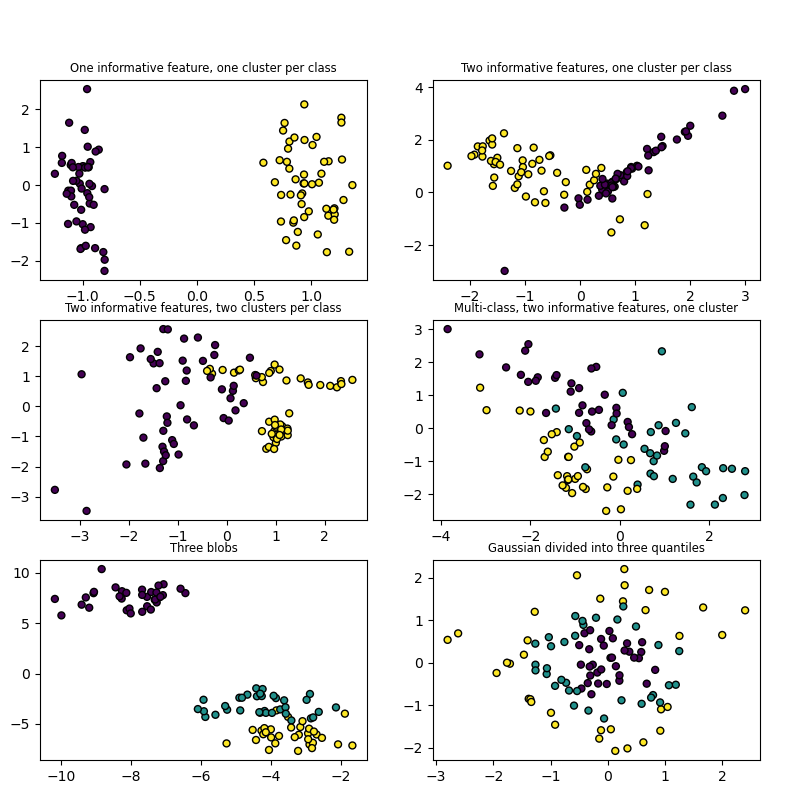
référence
Data loading utilities blobs make_classification Exemple de génération de données à l'aide de scikit-learn