[PYTHON] Essayez de prédire le taux de change (FX) avec un apprentissage automatique non approfondi
L'apprentissage automatique est souvent associé à l'apprentissage profond, mais il en existe bien d'autres. De plus, ce n'est pas si profond parce que ce n'est pas bon. Alors, essayons les données de article précédent avec un autre apprentissage automatique.
** Série connexe **
- Essayez de prédire le taux de change (FX) avec le 1er TensorFlow (Deep Learning) ――Partie 2 Essayez de prédire le taux de change (FX) avec un apprentissage automatique non approfondi
- édition CNN de la prévision du taux de change (FX) avec le 3e TensorFlow (apprentissage en profondeur)
TL;DR
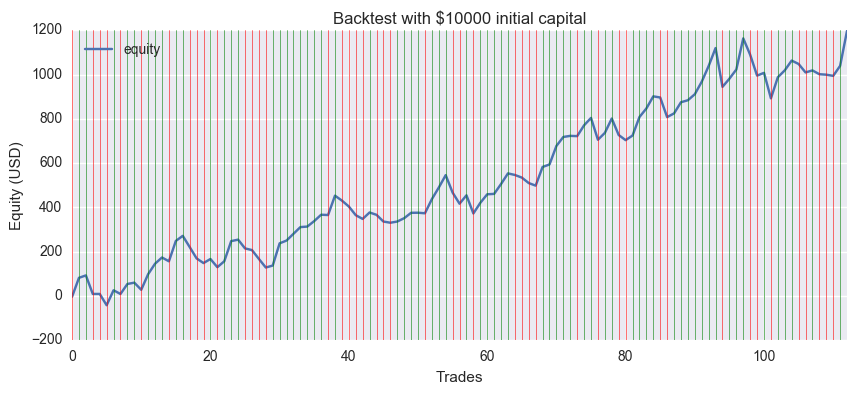 J'ai fait un graphique de l'évolution des actifs. Cela fait 12% de profit </ font> en environ six mois, mais cela ne fonctionnera pas toujours car le résultat n'est pas robuste aux conditions d'apprentissage.
J'ai fait un graphique de l'évolution des actifs. Cela fait 12% de profit </ font> en environ six mois, mais cela ne fonctionnera pas toujours car le résultat n'est pas robuste aux conditions d'apprentissage.
** J'ai un notebook sur GitHub. ** ** Fourchez et jouez. https://github.com/hayatoy/ml-forex-prediction
Scikit-learn
C'est le premier endroit pour faire du machine learning avec Python. Si l'installation est pip
pip install -U scikit-learn
Je pense que ça va.
Sélection du classificateur
Vous pouvez tous les essayer, mais j'espère que trop linéaire donnera de bons résultats pour les données bruyantes.
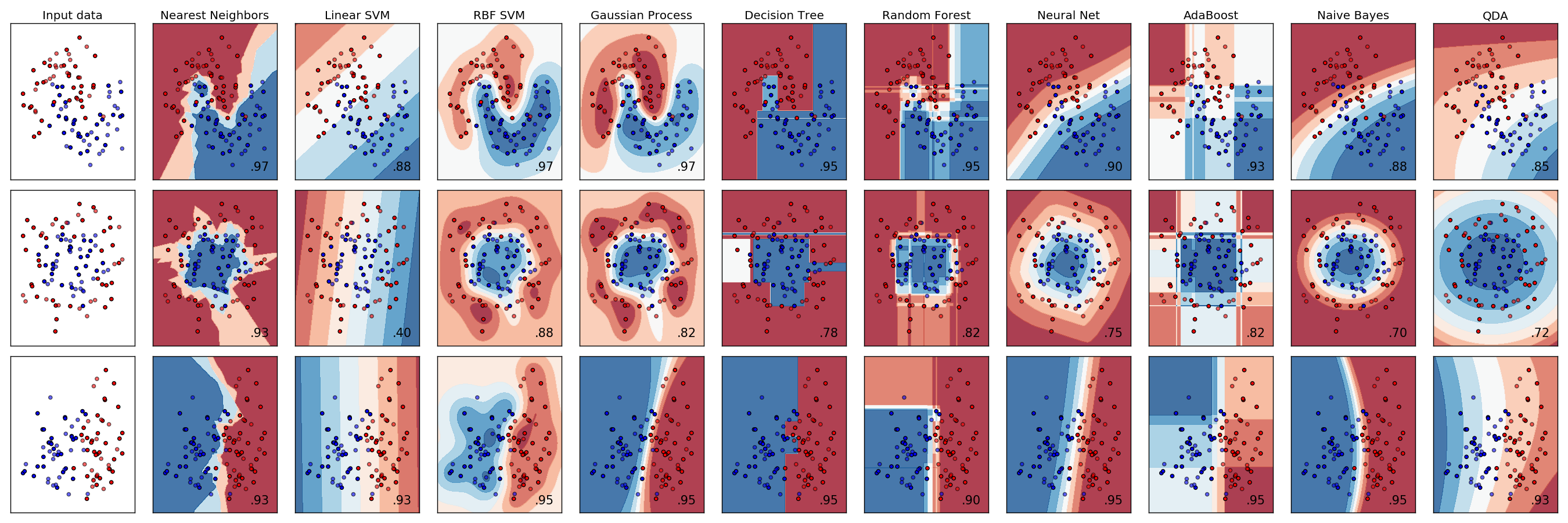 Un exemple de classification est comme ceci [^ 1].
[^ 1]: Source: http://scikit-learn.org/stable/auto_examples/classification/plot_classifier_comparison.html
Un exemple de classification est comme ceci [^ 1].
[^ 1]: Source: http://scikit-learn.org/stable/auto_examples/classification/plot_classifier_comparison.html
SVM (RBF), région de Naive Bayes a l'air bien.
Traitement de l'information
Il semble qu'il "s'adaptera" à la même forme, donc je vais l'utiliser tel quel. Quand j'y ai pensé, je me suis mis en colère parce que la classe était toujours un vecteur de tir. (Aviez-vous des options?) Il s'agit d'une conversion de 1hot-vector en binaire, mais cette fois, il s'agit de 2 classes, il semble donc que vous puissiez simplement changer l'emplacement à récupérer.
>> train_y
[[ 0. 1.]
[ 0. 1.]
[ 1. 0.]
[ 0. 1.]
[ 0. 1.]
[ 0. 1.]
[ 1. 0.]
[ 0. 1.]
[ 1. 0.]
[ 0. 1.]]
>> train_y[:,1]
[ 1. 1. 0. 1. 1. 1. 0. 1. 0. 1.]
Cette méthode ne peut pas être utilisée avec plusieurs classes. Je me demande s'il existe un moyen cool.
Laisse moi apprendre
Comme précédemment, 90% du premier semestre seront utilisés pour l'entraînement et 10% du second semestre seront utilisés pour les tests. En dessous de "0,502118", c'est pire qu'une prédiction aléatoire.
Pour le moment, implémentez équitablement les paramètres par défaut.
SVM (RBF)
from sklearn import svm
train_len = int(len(train_x)*0.9)
clf = svm.SVC(kernel='ref')
clf.fit(train_x[:train_len], train_y[:train_len,1])
clf.score(train_x[train_len:], train_y[train_len:,1])
Résultat: 0.49694435509810231 </ font>
Gradient Boosting
from sklearn.ensemble import GradientBoostingClassifier
clf = GradientBoostingClassifier()
clf.fit(train_x[:train_len], train_y[:train_len,1])
clf.score(train_x[train_len:], train_y[train_len:,1])
Résultat: 0,52331939530395621 </ font>
Random Forest
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier(random_state=0)
clf.fit(train_x[:train_len], train_y[:train_len,1])
clf.score(train_x[train_len:], train_y[train_len:,1])
Résultat: 0,49726600192988096 </ font>
Naive Bayes
from sklearn.naive_bayes import GaussianNB
clf = GaussianNB()
clf.fit(train_x[:train_len], train_y[:train_len,1])
clf.score(train_x[train_len:], train_y[train_len:,1])
Résultat: 0,50112576391122543 </ font>
Nearest Neighbors
from sklearn.neighbors import KNeighborsClassifier
clf = KNeighborsClassifier()
clf.fit(train_x[:train_len], train_y[:train_len,1])
clf.score(train_x[train_len:], train_y[train_len:,1])
Résultat: 0,49726600192988096 </ font>
QDA
from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis as QDA
clf = QDA()
clf.fit(train_x[:train_len], train_y[:train_len,1])
clf.score(train_x[train_len:], train_y[train_len:,1])
Résultat: 0,50981022836925061 </ font>
Résumé
| Classement | modèle | Accuracy |
|---|---|---|
| 1 | BiRNN(LSTM) | 0.528883 |
| 2 | Gradient Boosting | 0.523319 |
| 3 | QDA | 0.509810 |
| Pourcentage de nombreuses classes | 0.502118 | |
| 4 | Naive Bayes | 0.501126 |
| 5 | Random Forest | 0.497266 |
| 6 | Nearest Neighbors | 0.497266 |
| 7 | SVM (RBF) | 0.496944 |
Après tout, le dernier LSTM était la première place. La deuxième place était le Gradient Boosting, qui est également populaire à Kaggle.
Qu'est-ce que c'est? SVM est-il le plus bas, même si les paramètres n'ont pas été ajustés? Cela devrait être ... J'essaierai de trouver le paramètre optimal avec Grid Search à une autre occasion.
Calculer PnL (Profit & Loss)
Ce n'est pas parce que le taux de réponse correct est mauvais que le profit ou la perte sera mauvais. Même avec un taux de réponse correct de 50%, «profit> perte» est très bien.
Ces données prédit si le cours de clôture de la prochaine période augmentera ou baissera.
Alors
(Prochain cours de clôture-Cours de clôture actuel) * Lot-Commission
A été calculé en tant que profit et perte.
(En fait, il est prédit lorsque le cours de clôture actuel est confirmé, vous ne pouvez donc pas prendre position au cours de clôture. Peut fonctionner) </ font>
github version des données quotidiennes EUR / USD. La ligne verte signifie une réponse correcte et la ligne rouge signifie une réponse incorrecte.
Les actifs initiaux étaient de 10 000 $, l'unité de transaction était de 10 000 devises, la commission (spread) était de 0 et le bénéfice final était de plus de 1197 $. Même si vous définissez le spread à une moyenne de 2 pips, il est toujours d'environ 900 $.
Cela a l'air bien à première vue, mais ... Il semble que le modèle et la sélection des données ne soient pas bons, mais qu'ils s'intègrent parfaitement, car changer la période de formation la ruine rapidement.
J'ai un notebook sur GitHub, alors essayez-le. https://github.com/hayatoy/ml-forex-prediction
Recommended Posts