[PYTHON] Predict short-lived works of Weekly Shonen Jump by machine learning (Part 1: Data analysis)
1.First of all
Weekly Shonen Jump (hereinafter referred to as Jump) is the best-selling manga magazine in Japan [^ circulation]. Needless to say, I'm a big fan.
The serialization meeting of the jump editorial department is very severe. In the fiction manga "Bakuman." depicting the struggle of a jump writer, the editorial department [Every issue reader survey](https://ja.wikipedia.org/wiki/%E9%80%B1%E5%88%8A%E5%B0%91%E5%B9%B4%E3%82%B8 % E3% 83% A3% E3% 83% B3% E3% 83% 97 # .E3.82.A2.E3.83.B3.E3.82.B1.E3.83.BC.E3.83.88.E8. Based on 87.B3.E4.B8.8A.E4.B8.BB.E7.BE.A9), the popularity of each manga is evaluated, and the order of publication and the discontinued work are decided [^] Publication order]. It is not uncommon for the serialization to be discontinued within 10 weeks of the start of the serialization (about one book). It's a very tough world.
In this article, we use machine learning to predict short-lived works (works that finish within 10 weeks). ** The ultimate goal is to predict the discontinued work before the jump editorial department, and if the favorite work is dangerous, issue a questionnaire to avoid the discontinuation ** [^ Jump]. Since we cannot know the result of the reader questionnaire, we input the history of the publication order and output whether it is a short-lived work Multilayer Perceptron [^ [Multilayer] is implemented in TensorFlow. For learning, use Web API and Agency for Cultural Affairs Media Art Database, The tableware information for about 46 years is used.
This article will be divided into two parts. The first part (this time) will acquire and analyze data, and the second part (next time) will learn and test the data. The figure below is a part of the analysis result of the first part.

[^ Number of circulation]: According to a survey by the Japan Magazine Association. From October 1, 2015 to September 30, 2016 Number of comic magazines for boys published, Comics for men Magazine circulation, Comic magazine circulation for girls /data_002/w5.html#001), Number of comic magazines for women.
[^ Publication order]: During the work, the publication order and discontinued works were decided mainly based on the results of the reader questionnaire. According to the following article, the Jump editorial department seems to have denied this, saying, "We do not necessarily consider only the results of the reader survey." "Jump" editorial department denies rumors of questionnaire supreme principle ... Readers are complicated
[^ Multi-layer]: Scheduled. We will consider another method depending on the performance.
[^ Jump]: As mentioned above, in reality, the jump editorial department decides the discontinued work in consideration of various factors. I hope you understand this article as a delusion of a jump fan.
2. Environment
In [ʻanaconda](https://www.continuum.io/Downloads), create the following virtual environment comic`.
conda create -n comic python=3.5
source activate comic
conda install pandas matplotlib jupyter notebook scipy scikit-learn seaborn scrapy
pip install tensorflow
The yml file is here. Tensorflow and scikit-learn are included because they will be needed in the second part. .. Also, since pairplot () is used for visualization, seaborn Is inserted.
3. Data acquisition
3.1 Source
Japan Media Arts Database, jump table for about 46 years (November 3, 1969 issue-July 25, 2016 issue) Is open to the public [^ currently].
[^ Present]: As of April 4, 2017.


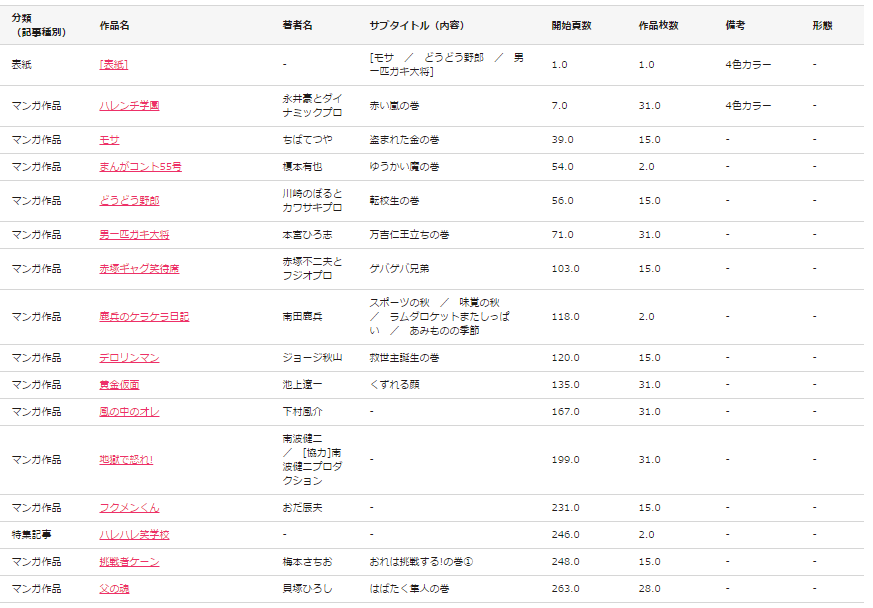
The figure above is an example of investigating the table of contents of the November 3, 1969 issue of Jump. In the following, the table of contents information will be extracted using the Web API introduced in the comment section.
3.2 Web API
** In order to minimize the burden on the Agency for Cultural Affairs server, process processed data from my github as much as possible. Please obtain it **. The notebook is here, so I hope you can use it.
Use Agency for Cultural Affairs Media Art Database Manga Field WebAPI to obtain the data required for analysis. For the use of web API using python3, refer to Until accessing the web API that returns json with Python3 and outputting the result. Thank you.
import
import json
import urllib.request
from time import sleep
Obtaining magazine volume search results
Use the following function search_magazine () to search for Weekly Shonen Jump magazine volume information. The unique ID obtained by this function will be required for "Getting magazine volume information" in the next section.
def search_magazine(key='JUMPrgl', n_pages=25):
"""
Magazines that include the key in the "unique ID", "magazine volume ID" or "magazine code",
n_This is a function to get pages.
"""
url = 'https://mediaarts-db.bunka.go.jp/mg/api/v1/results_magazines?id=' + \
key + '&page='
magazines = []
for i in range(1, n_pages):
response = urllib.request.urlopen(url + str(i))
content = json.loads(response.read().decode('utf8'))
magazines.extend(content['results'])
return magazines
In the Web API, you can specify "unique ID", "magazine volume ID", and "magazine code" with ʻid, and the search page number (100 items per page, default is 1) with page. Since Weekly Shonen Jump includes JUMPrgl in the" magazine volume ID ", specify ʻid = JUMPrgl. Also, since the search results for Weekly Shonen Jump are 24 pages (2320) in total, it is necessary to specify 1 to 24 in order for page. For details, please refer to Web API Specifications.
Since the URL of the Media Art Database of the Cultural Agency was changed from March 31, 2017, the request URL (https://mediaarts-db.bunka.go.jp/webapi_proto_documents.pdf) described in Web API Specifications The new URL (https://mediaarts-db.bunka.go.jp/mg/api/v1/results_magazines) instead of https://mediaarts-db.jp/mg/api/v1/results_magazines) Please note that you need to use.
Acquisition of magazine volume information
The following function ʻextract_data ()extracts the required table of contents information, andsave_data ()` saves the table of contents information.
def extract_data(content):
"""
It is a function to get the table of contents information included in the content.
- year:Year of issue
- no:Number of issues
- title:Title of work
- author:Author
- color:Whether it is color or not
- pages:Number of pages posted
- start_page:Start page of the work
- best:Publication order counted from the beginning
- worst:Posting order counted from the end of the book
"""
#Only manga works are extracted.
comics = [comic for comic in content['contents']
if comic['category']=='Manga works']
data = []
year = int(content['basics']['date_indication'][:4])
#Exception handling is required because the number of issues may not be listed.
try:
no = int(content['basics']['number_indication'])
except ValueError:
no = content['basics']['number_indication']
for comic in comics:
title= comic['work']
if not title:
continue
#Exception handling is required because some works do not have the number of pages listed.
#There is no particular reason, but unlisted works will be processed as 10 pages.
try:
pages = int(comic['work_pages'])
except ValueError:
pages = 10
#To support works such as "Inumarudashi" that are published in multiple episodes a week
#If the title is already included in the data, do not register it as a new datum.
#Only the number of existing datum pages will be added.
if len(data) > 0 and title in [datum['title'] for datum in data]:
data[[datum['title'] for datum in
data].index(title)]['pages'] += pages
else:
data.append({
'year': year,
'no': no,
'title': comic['work'],
'author': comic['author'],
'subtitle': comic['subtitle'],
'color': int('Color' in comic['note']),
'pages': int(comic['work_pages']),
'start_pages': int(comic['start_page'])
})
#In order to exclude the mini-manga of the project, datums with a total of 5 pages or less are excluded from the list.
filterd_data = [datum for datum in data if datum['pages'] > 5]
for n, datum in enumerate(filterd_data):
datum['best'] = n + 1
datum['worst'] = len(filterd_data) - n
return filterd_data
It's a muddy story, but I had a hard time handling some gag manga. For example, "Inumarudashi" is basically two episodes a week. Although it was posted, each story is described in a separate line in the database. Since it is necessary to consider these as one work, if the title of the comic is in the data, it is not added to the data as another datum, and theof the existingdatum`` We are processing to add pages`. Also, for example, "Pyu to Blow! Jaguar" is being serialized regardless of its popularity (it was actually insanely interesting). Was always published at the end of the magazine. I was worried about whether to exclude this as an outlier, but in the end I decided to leave it.
def save_data(magazines, offset=0, file_name='data/wj-api.json'):
"""
For all magazines included in magazines, from the beginning to the volume after offset
Get table of contents information and file_It is a function to save in name.
"""
url = 'https://mediaarts-db.bunka.go.jp/mg/api/v1/magazine?id='
#First line of file
if offset == 0:
with open(file_name, 'w') as f:
f.write('[\n')
with open(file_name, 'a') as f:
#Hit the Web API for each magazine in magazines.
for m, magazine in enumerate(magazines[offset:]):
response = urllib.request.urlopen(url + str(magazine['id']),
timeout=30)
content = json.loads(response.read().decode('utf8'))
#The above function extract_data()Then, extract the necessary information.
comics = extract_data(content)
print('{0:4d}/{1}: Extracted data from {2}'.\
format(m + offset, len(magazines), url + str(magazine['id'])))
#For each comic in comics, file_Save the information in name.
for n, comic in enumerate(comics):
#For the first comic of magazine other than the beginning of the file,
#First',\n'Added.
if m + offset > 0 and n == 0:
f.write(',\n')
json.dump(comic, f, ensure_ascii=False)
#Except for the last comic',\n'Added.
if not n == len(comics) - 1:
f.write(',\n')
print('{0:9}: Saved data to {1}'.format(' ', file_name))
#Be sure to pause to reduce the load on the server.
sleep(3)
#Last line of file
with open(file_name, 'a') as f:
f.write(']')
In order to flexibly deal with timeouts, the table of contents information is not processed in a batch, but is forcibly processed sequentially. Also, please note that it is paused with sleep () so as not to put a load on the server.
Also here, the request URL (https://mediaarts-db.jp/mg/api/v1" described in [Web API specifications](https://mediaarts-db.bunka.go.jp/webapi_proto_documents.pdf) Please note that you need to use the new URL (https://mediaarts-db.bunka.go.jp/mg/api/v1/magazine) instead of / magazine).
Run
Use the above function to get the table of contents information from Web API and save it in data / wj-api.json.
magazines = search_magazine()
save_data(magazines)
# 0/2320: Extracted data from https://mediaarts-db.bunka.go.jp/mg/api/v1/magazine?id=323270
# : Saved data to data/wj-api.json
# 1/2320: Extracted data from https://mediaarts-db.bunka.go.jp/mg/api/v1/magazine?id=323269
# : Saved data to data/wj-api.json
# ...
# 447/2320: Extracted data from https://mediaarts-db.bunka.go.jp/mg/api/v1/magazine?id=322833
# : Saved data to data/wj-api.json
#---------------------------------------------------------------------------
#gaierror Traceback (most recent call last)
#/home/anaconda3/envs/comic/lib/python3.5/urllib/request.py in do_open(self, http_class, req, **http_conn_args)
# 1253 try:
#-> 1254 h.request(req.get_method(), req.selector, req.data, headers)
# 1255 except OSError as err: # timeout error
If it times out, use ʻoffsetto restart it. For example, if the timeout occurs at447/2320, execute save_data (offset = 448) `.
save_data(magazines, offset=448)
# 448/2320: Extracted data from https://mediaarts-db.bunka.go.jp/mg/api/v1/magazine?id=322832
# : Saved data to data/wj-api.json
# 449/2320: Extracted data from https://mediaarts-db.bunka.go.jp/mg/api/v1/magazine?id=322831
# : Saved data to data/wj-api.json
#...
3.3 (Reference) Scraping
Due to my lack of research, I used to get table of contents data by web scraping until I pointed out in the comment section. For your reference, the settings at that time are described, but please use the Web API in Chapter 3.2 as much as possible.
This time, we will use Scrapy, which is a typical framework. For more information on Scrapy, see the reference section at the end of this article. First, create the project comic for this article with the following command.
scrapy startproject comic
This should create a directory like the one below (Official Tutorial).
comic/
scrapy.cfg # deploy configuration file
comic/ # project's Python module, you'll import your code from here
__init__.py
items.py # project items definition file
pipelines.py # project pipelines file
settings.py # project settings file
spiders/ # a directory where you'll later put your spiders
__init__.py
Place the following comic_spider.py in comic / spiders.
comic_spider.py
# -*- coding: utf-8 -*-
import scrapy
class WjSpider(scrapy.Spider):
"""
start_A spider that recursively extracts the following table of contents information starting from urls.
Start here_urls are registered in the Japan Media Arts Database
This is the oldest information on the table of contents of Weekly Shonen Jump (November 3, 1969 issue).
- year:Year of issue
- no:Number of issues
- title:Title of work
- author:Author
- color:Whether it is color or not
- pages:Number of pages posted
- start_page:Start page of the work
- best:Publication order counted from the beginning
- worst:Posting order counted from the end of the book
"""
name = 'wj'
start_urls = [
'http://mediaarts-db.bunka.go.jp/mg/magazines/323270'
]
n_page = 0
def parse(self, response):
"""The main body of spider."""
year = int(response.css('section.block tr td::text').extract()[3][:4])
try:
no = int(response.css('section.block tr td::text').extract()[8])
except ValueError:
no = response.css('section.block tr td::text').extract()[8]
#Only manga works are extracted.
comics = [comic for comic in response.css('table.infoTbl2 tr')
if len(comic.css('td::text')) > 0
and comic.css('td::text')[0].extract() == 'Manga works']
data = []
for comic in comics:
title = comic.css('a::text').extract_first()
if not title:
continue
#Exception handling is required because some works do not have the number of pages listed.
#There is no particular reason, but unlisted works will be processed as 10 pages.
try:
pages = float(comic.css('td::text')[6].extract())
except ValueError:
pages = 10
#To support works such as "Inumarudashi" that are published in multiple episodes a week
#If the title is already included in the data, do not register it as a new datum.
#Only the number of existing datum pages will be added.
if len(data) > 0 and title in [datum['title'] for datum in data]:
data[[datum['title'] for datum in
data].index(title)]['pages'] += pages
else:
data.append({
'year': year,
'no': no,
'title': comic.css('a::text').extract_first(),
'author': comic.css('td::text')[3].extract(),
'subtitle': comic.css('td::text')[4].extract(),
'color': comic.css('td::text')[7].extract().count('Color'),
'pages': pages,
'start_page': float(comic.css('td::text')[5].extract())})
#In order to exclude the mini-manga of the project, datums with a total of 5 pages or less are excluded from the list.
filtered_data = [datum for datum in data if datum['pages'] > 5]
for n, datum in enumerate(filtered_data):
datum['best'] = n + 1
datum['worst'] = len(filtered_data) - n
yield datum
#Acquires the information of the next issue recursively.
next_page = response.css('li.nxt a::attr(href)').extract_first()
if next_page is not None:
next_page = response.urljoin(next_page)
yield scrapy.Request(next_page, callback=self.parse)
You must set DOWNLOAD_DELAY in ** settings.py ** to avoid overloading the server (it was commented out by default). Also, I want to spit out data in Japanese, so set FEED_EXPORT_ENCODING to ʻutf-8`.
settings.py
### -----Abbreviation-----
DOWNLOAD_DELAY = 3
FEED_EXPORT_ENCODING = 'utf-8'
### -----Abbreviation-----
Execute the following to get the data.
scrapy crawl wj -o wj.json
4. Data analysis
Actually, you can play a lot with just wj-api.json [^ separate article]. The notebook is here, so I hope you can use it. In the following, we will proceed on the assumption that wj-api.json exists under the data directory.
[^ Separate article]: I enjoyed playing more than I expected, so I made it into two parts.
4.1 Preparation
I want to display the title of each work in Japanese, so set it referring to Draw Japanese with matplotlib on Ubuntu. If you are using other than Ubuntu, please take appropriate action.
import json
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
sns.set(style='ticks')
import matplotlib
from matplotlib.font_manager import FontProperties
font_path = '/usr/share/fonts/truetype/takao-gothic/TakaoPGothic.ttf'
font_prop = FontProperties(fname=font_path)
matplotlib.rcParams['font.family'] = font_prop.get_name()
4.2 ComicAnalyzer
For wj-api.json analysis, define the following class ComicAnalyzer.
ComicAnalyzer
class ComicAnalyzer():
"""This class reads and manages the table of contents information of manga magazines."""
def __init__(self, data_path='data/wj-api.json', min_week=7, short_week=10):
"""
At initialization, data_In path.Extract the table of contents information from the json file.
- self.data:List type that holds all table of contents information
- self.all_titles:List type that holds all work name information
- self.serialized_titles: min_List type that holds all the titles of works serialized over week
- self.last_year:Numeric type that holds the year of the latest table of contents information
- self.last_no:Numeric type that holds the number of the latest table of contents information
- self.end_titles: self.serialized_Of the titles, self.last_year and
self.last_List type that holds all the titles of works completed by no
- self.short_end_titles: self.end_Of the titles, short_week within a week
List type that holds the titles of works that have been serialized
- self.long_end_titles: self.end_Of the titles, short_week+For more than a week
List type that holds the titles of works that have been serialized
"""
self.data = self.read_data(data_path)
self.all_titles = self.collect_all_titles()
self.serialized_titles = self.drop_short_titles(self.all_titles, min_week)
self.last_year = self.find_last_year(self.serialized_titles[-100:])
self.last_no = self.find_last_no(self.serialized_titles[-100:], self.last_year)
self.end_titles = self.drop_continued_titles(
self.serialized_titles, self.last_year, self.last_no)
self.short_end_titles = self.drop_long_titles(
self.end_titles, short_week)
self.long_end_titles = self.drop_short_titles(
self.end_titles, short_week + 1)
def read_data(self, data_path):
""" data_Reads the json file in path and returns a list of all the table of contents information."""
with open(data_path, 'r', encoding='utf-8') as f:
data = json.load(f)
return data
def collect_all_titles(self):
""" self.Returns a list of all work names extracted from data."""
titles = []
for comic in self.data:
if comic['title'] not in titles:
titles.append(comic['title'])
return titles
def extract_item(self, title='ONE PIECE', item='worst'):
""" self.Returns a list of all title items extracted from data."""
return [comic[item] for comic in self.data if comic['title'] == title]
def drop_short_titles(self, titles, min_week):
"""Of the titles, min_week Returns a list of titles serialized for more than a week."""
return [title for title in titles
if len(self.extract_item(title)) >= min_week]
def drop_long_titles(self, titles, max_week):
"""Of the titles, max_week Returns a list of titles that have been completed within a week."""
return [title for title in titles
if len(self.extract_item(title)) <= max_week]
def find_last_year(self, titles):
"""Returns the latest year of the magazines in which titles are published."""
return max([self.extract_item(title, 'year')[-1]
for title in titles])
def find_last_no(self, titles, year):
"""Returns the latest issue of the year magazine in which titles were published."""
return max([self.extract_item(title, 'no')[-1]
for title in titles
if self.extract_item(title, 'year')[-1] == year])
def drop_continued_titles(self, titles, year, no):
"""Among titles, returns a list of titles that have been serialized by the no issue of the year."""
end_titles = []
for title in titles:
last_year = self.extract_item(title, 'year')[-1]
if last_year < year:
end_titles.append(title)
elif last_year == year:
if self.extract_item(title, 'no')[-1] < no:
end_titles.append(title)
return end_titles
def search_title(self, key, titles):
"""Returns a list of titles including key in titles."""
return [title for title in titles if key in title]
Since it is a process that is quite difficult to understand, it supplements the operation at the time of initialization (__init __ ()).
self.all_titlesliterally holds all titles. However,self.all_titlesclearly contains one-shot works and planned works.- Therefore, the works serialized above
min_weekare extracted asself.serialized_titles. However,self.serialized_titlescontains the works being serialized at the time of the latest table of contents information, and the serialization duration is inaccurate. For example, "Kimetsu no Yaiba" Is a popular work that is still being serialized, but the serialization ended in 21 weeks. It looks like a work. - Therefore, only the works whose serialization has been completed (probably) at the time of the latest table of contents information in the database are extracted as
self.end_titles.self.end_titlesis the whole set in this analysis. - Of the
self.end_titles, the works that finished within 10 weeks are extracted asself.short_end_titles, and the works that continued for 11 weeks or more are extracted asself.long_end_titles.
4.3 Analysis
Now, let's play with ComicAnalyzer.
wj = ComicAnalyzer()
First, let's plot the order of publication (worst) of the latest 10 short-lived works up to the first 10 weeks. The larger the value, the more it was posted near the beginning of the book.
for title in wj.short_end_titles[-10:]:
plt.plot(wj.extract_item(title)[:50], label=title[:6])
plt.xlabel('Week')
plt.ylabel('Worst')
plt.ylim(0,22)
plt.legend()

It contains projects (business trip work [^ Gag Manga Biyori]) such as "Gag Manga Biyori". I'm dissatisfied, but there is no way to exclude it from the table of contents information alone. that? "Saiki Kusuo" was serialized for more than 10 weeks ...? In this case, use search_title ().
[^ Gag Manga Biyori]: Should be serialized in Jump Square ([wikipedia](https://ja.wikipedia.org/wiki/%E3%82%AE%E3%83%A3%E3%82%] B0% E3% 83% 9E% E3% 83% B3% E3% 82% AC% E6% 97% A5% E5% 92% 8C)). As of April 18, 2017, the table of contents information of Jump Square has not been registered in the database yet.
wj.search_title('Saiki', wj.all_titles)
# ['Supernatural power person Saiki Kusuo's Ψ difficulty', 'Saiki Kusuo's Ψ difficulty']
len(wj.extract_item('Supernatural power person Saiki Kusuo's Ψ difficulty'))
# 7
wj.extract_item('Supernatural power person Saiki Kusuo's Ψ difficulty', 'year'), \
wj.extract_item('Supernatural power person Saiki Kusuo's Ψ difficulty', 'no')
# ([2011, 2011, 2011, 2011, 2011, 2011, 2011], [22, 27, 29, 33, 42, 43, 50])
len(wj.extract_item('Saiki Kusuo's Ψ difficulty'))
# 201
Apparently, in "Supernatural power person Saiki Kusuo's Ψ difficulty" After reading and posting 7 times on a trial basis, "[Saiki Kusuo's Ψ Difficulty](https://mediaarts-db.bunka.go.jp/mg/magazine_works/1071?ids%5B%5D=1071&ids%5B%5D] = 1566) ”seems to have started ([wikipedia](https://ja.wikipedia.org/wiki/%E6%96%89%E6%9C%A8%E6%A5%A0%E9%" 9B% 84% E3% 81% AE% CE% A8% E9% 9B% A3)). Next, we will display the order of publication of the first 10 episodes of recent hits (arbitrary).
target_titles = ['ONE PIECE', 'NARUTO-Naruto-', 'BLEACH', 'HUNTER×HUNTER']
for title in target_titles:
plt.plot(wj.extract_item(title)[:10], label=title[:6])
plt.xlabel('Week')
plt.ylabel('Worst')
plt.ylim(0,22)
plt.legend()

Although it is not directly related to this article, I was personally interested in it, so I will look at the order of publication up to 50 episodes.
target_titles = ['ONE PIECE', 'NARUTO-Naruto-', 'BLEACH', 'HUNTER×HUNTER']
for title in target_titles:
plt.plot(wj.extract_item(title)[:100], label=title[:6])
plt.xlabel('Week')
plt.ylabel('Worst')
plt.ylim(0,22)
plt.legend()
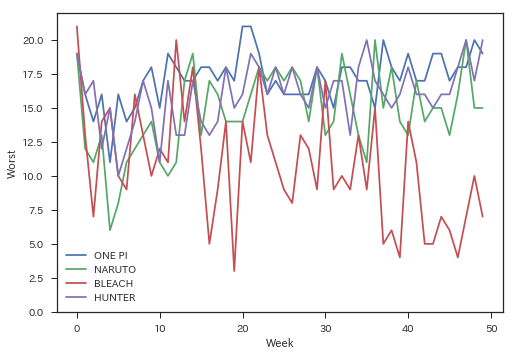
I expected it to some extent, but it's still amazing. By the way, if you look at the order of publication while getting the title of each story using ʻextract_item ()`, manga lovers can grin.
wj.extract_item('ONE PIECE', 'subtitle')[:10]
#['1.ROMANCE DAWN-Dawn of Adventure-',
# 'Episode 2!!the man"Straw Hat Luffy"',
# 'Episode 3"Pirate hunting Zoro"Appearance',
# 'Episode 4 Colonel of the Navy"Axe Morgan"',
# 'Episode 5"Pirate King and Great Swordsman"',
# 'Episode 6"1st person"',
# 'Episode 7"friend"',
# 'Episode 8"Nami appeared"',
# 'Episode 9"Devilish woman"',
# 'Episode 10"A case of a bar"']
I took a detour too much. Let's do correlation analysis with pairplot () of seaborn. Here, I will plot the posting order from the 2nd week to the 6th week for the time being. I missed the first week because most of the works will appear at the beginning of the first week. Since multiple points overlap at the same coordinates and it is very difficult to see, add random noise for convenience to improve the appearance.
end_data = pd.DataFrame(
[[wj.extract_item(title)[1] + np.random.randn() * .3,
wj.extract_item(title)[2] + np.random.randn() * .3,
wj.extract_item(title)[3] + np.random.randn() * .3,
wj.extract_item(title)[4] + np.random.randn() * .3,
wj.extract_item(title)[5] + np.random.randn() * .3,
'Short-lived work' if title in wj.short_end_titles else 'Continuation work']
for title in wj.end_titles])
end_data.columns = ["Worst (week2)", "Worst (week3)", "Worst (week4)",
"Worst (week5)", "Worst (week6)", "Type"]
sns.pairplot(end_data, hue="Type", palette="husl")
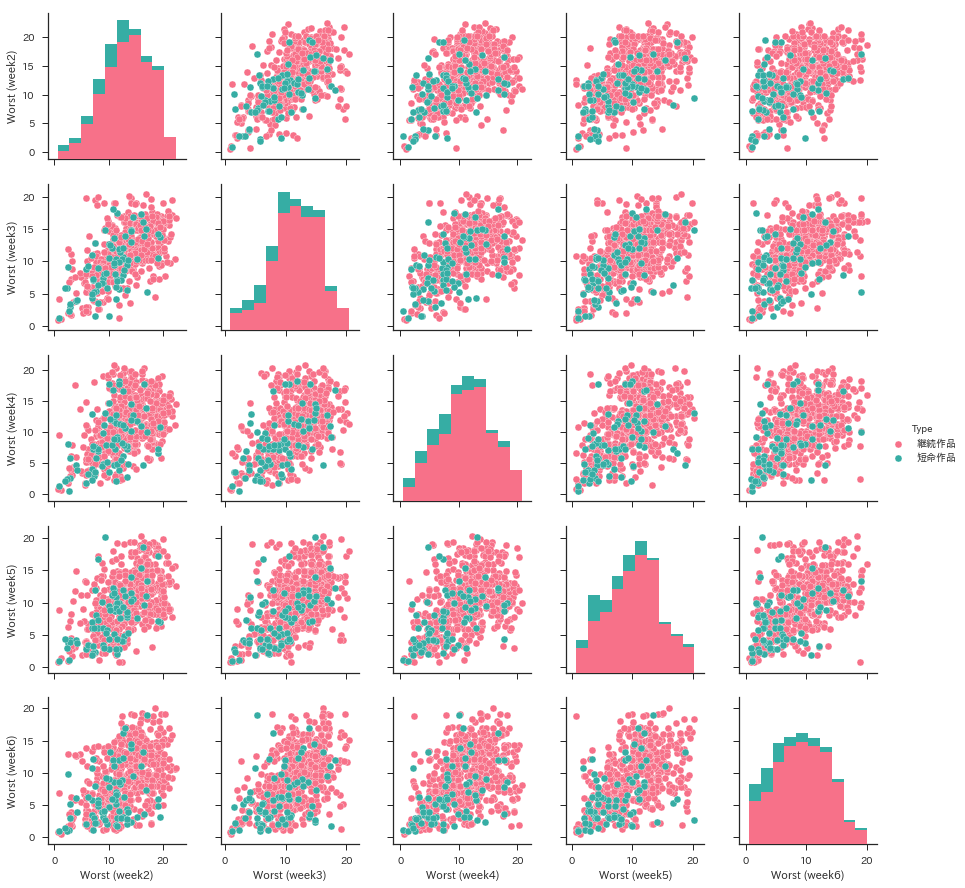
Pink is a work that lasted for more than 11 weeks, and green is a short-lived work that ended within 10 weeks. I thought it would be more divided, but it seems to be difficult to separate. Probably, I feel that projects such as "Gag Manga Biyori" and experimental one-shot works such as "Supernatural Powers Kusuo Saiki's Ψ Difficulty" are noisy. You can distinguish it from the continuity of the published issue, but that makes it indistinguishable from the suspended work ... It's annoying. For the time being, I will try machine learning with this data as it is.
5. Conclusion
I made something like this when I realized that I was escapist. The next time will be the actual production, so I hope you enjoy it. Thank you for reading for me until the end!
References
In creating this article, I referred to the following. Thank you very much! : bow:
- Bakuman. : This is a manga artist manga serialized in Weekly Shonen Jump. It was interesting to hear a fairly raw story such as the manuscript fee.
- Until accessing the web API that returns json with Python 3 and outputting the result: Let me refer to how to use the web API using python3. We received.
- Introduction to Scrapy (1): It was neat and organized and was very helpful.
- Scrapy Tutorial: After moving my hands, I somehow understood how to use it.
- Draw Japanese with matplotlib on Ubuntu: I used this as a reference when displaying the title of the work in Japanese.
Recommended Posts