[PYTHON] Recurrent Neural Networks: An Introduction to RNN
Recurrent Neural Networks (RNNs) have been highly successful in the field of natural language processing and are currently one of the hottest algorithms. However, I think there are only a limited number of books that explain how RNNs actually work and build, ahead of their popularity. This post focused on that part and was written with my friend Denny (author of the WildML blog).
Now I would like to explain the RNN-based language model. The language model has two uses. The first is to score how likely it is that a sentence will actually appear. This score is a criterion for grammatical and semantic correctness. Such models are used, for example, in machine translation. Second, the language model can generate new text (by the way, I personally think it's a cooler use). Also, although it is in English, Andrew Karpathy's Blog explains and develops a word-level RNN language model, so it takes time. If you have one, please read it.
The reader assumes that the rudimentary things about neural networks are suppressed. If not, [Let's build a neural network with Python without using a library](http://blog.moji.ai/2015/12/python% e3% 81% a7% e3% 83% a9 % e3% 82% a4% e3% 83% 96% e3% 83% a9% e3% 83% aa% e3% 83% bc% e3% 82% 92% e4% bd% bf% e3% 82% 8f% e3 % 81% 9a% e3% 81% ab% e3% 80% 81% e3% 83% 8b% e3% 83% a5% e3% 83% bc% e3% 83% a9% e3% 83% ab% e3% 83 Please read% 8d% e3% 83% 83% e3% 83% 88 /). This post explains and builds a non-recursive network model.
What is RNN (Recurrent Neural Network)?
The advantage of RNNs is that you can use continuous information such as sentences. The traditional idea of neural networks is not so, assuming that the input data (and the output data) are independent of each other. But this assumption is often not valid. For example, if you want to predict the next word, you should know what the previous word was, right? R of RNN means Reccurent, and you can do the same work for each continuous element without being influenced by the previous calculation. In other words, RNNs have the memory to remember previously calculated information. Theoretically, RNNs can use very long textual information. However, when I actually implement it, I can only remember the information about a few steps ago (I will dig deeper into this matter below). Now, let's take a look at a general RNN in the chart below.
 A recurrent neural network and the unfolding in time of the computation involved in its forward computation. Source: Nature
A recurrent neural network and the unfolding in time of the computation involved in its forward computation. Source: Nature
The chart above expands inside the RNN. Deploying simply means writing an ordered network. For example, if you have a sentence consisting of 5 words, the expanded network will be a 5-layer neural network with 1 layer and 1 word. The formula for calculating the RNN is as follows.
$ x_t $ is the input for the $ t $ step. For example, $ x_1 $ is a vector associated with the following words: $ s_t $ is a hidden element during the $ t $ step. This is the memory of the network. $ s_t $ is calculated based on the previous hidden element. And the input at this step is $ s_t = f (U x_x + W s_ {t-1}) $. $ f $ functions include tanh and ReLU Non-linear type of is common. The $ s_ {-1} $ needed to calculate the first hidden element usually starts at 0. $ o_t $ is the output at the $ t $ step. For example, if you want to predict the following words, $ o_t $ is a vector of prediction probabilities ($ o_t = softmax (V s_t) $).
What RNN can do
RNN is already in the field of natural language processing and has many success stories. Now that we have a little understanding of RNNs, we will introduce one of the most used RNNs, LSTM. LSTMs are better at learning distant step relationships than RNNs. However, don't worry, the LSTM basically has the same algorithm structure as the RNN to be built this time. The only difference is the way the hidden elements are calculated. We plan to cover LSTM in the future, so if you are interested, please register for the e-mail newsletter.
Language model and sentence generation
The language model can use the previous word to predict the probability of the next word appearing in a series of words. It is used for machine translation because it can measure how often sentences appear. Another good thing about being able to predict the next word is that you can get a Generative model that can generate new sentences by sampling from the output probabilities. Therefore, it is possible to generate various things depending on the training data. In the language model, the input data is a continuous sequence of words. And the output will be a sequence of predicted words. When training the network, we want the output of the $ t $ step to be the following words, so we set $ o_t = x_ {t + 1} $.
Although it will be in English, the following is a reference for papers on language models and text generation.
- Recurrent neural network based language model
- Extensions of Recurrent neural network based language model
- Generating Text with Recurrent Neural Networks
Machine translation
Machine translation is similar to a language model in that it takes sentences in the source language (eg Japanese) as input. And the output is, for example, an English sentence. The difference from the language model is that the output data starts processing after reading the complete input data. Therefore, the first word of the translated sentence requires complete input sentence information.
 RNN for Machine Translation. Image Source: http://cs224d.stanford.edu/lectures/CS224d-Lecture8.pdf
RNN for Machine Translation. Image Source: http://cs224d.stanford.edu/lectures/CS224d-Lecture8.pdf
Although it is in English, the following is a reference for papers on machine translation.
- A Recursive Recurrent Neural Network for Statistical Machine Translation
- Sequence to Sequence Learning with Neural Networks
- Joint Language and Translation Modeling with Recurrent Neural Networks
Speech recognition
Using a continuous acoustic signal from a sound wave as an input, a continuous voice segment is probabilistically predicted.
Although it will be in English, the following are some references for speech recognition papers.
Image summary generation
You can use Convolutional Neural Networks and RNNs to generate an overview of unlabeled images. As you can see from the image below, it is possible to generate a summary with a fairly high probability.
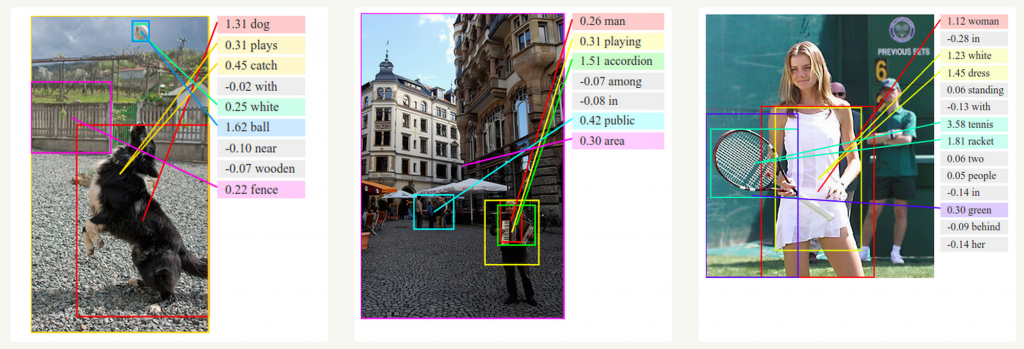
Deep Visual-Semantic Alignments for Generating Image Descriptions. Source: http://cs.stanford.edu/people/karpathy/deepimagesent/
Train RNN
Learning an RNN is similar to training a traditional neural network, but for RNNs we use a slightly different backpropagation algorithm. Since the RNN parameters are used in every step on the network, the step-by-step gradient uses the calculation of the previous step as well as the calculation of the current step. For example, to calculate the gradient of $ t = 4 $, we need to go back 3 steps and add the gradients. This is called Backpropagation Through Time (BPTT). If you don't understand what it means, don't worry. I will write the details in a later post. For now, keep in mind that RNNs trained using BPTT are more difficult to train the farther they are. An algorithm like LSTM (a type of RNN) has been developed to solve this problem.
Application of RNN
Recent researcher development efforts have led to the emergence of more sophisticated RNN models that can eliminate the shortcomings of traditional RNNs. I'll explain that in a future post, but in this post I'll give you a brief introduction.
Bidirectional RNN With Bidirectional RNNs, the output of $ t $ is not calculated based only on the immediately preceding element, but also on the following elements. For example, when predicting words that do not appear in the previous part, the probability should be calculated including the latter words. So think of a Bidirectional RNN as an overlap of two RNNs. The output is calculated from two hidden elements.

Deep (Bidirectional) RNN Deep RNNs are similar to Bidirectional RNNs, except that they have multiple layers per step. If you try to implement it, you will get higher learning ability (although you still need a lot of learning data).
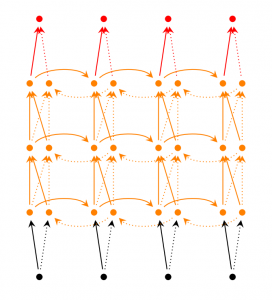
LSTM network
As I mentioned a bit, the LSTM network is one of the most popular RNNs these days. LSTMs have basically the same structure as RNNs, but lead different functions to compute hidden elements. The LSTM Memory is called a Cell and can be thought of as a black box with the previous element $ h_ {t-1} $ and the current element $ x_t $ as inputs. Inside the black box, select the Cell to store in Memory. Then combine the previous element, the current element, and the input. As a result, it is possible to successfully extract the relationships between words that are far apart. LSTM is a little difficult to understand, but if you are interested, it is in English, but the explanation of here is easy to understand, so please refer to it. please look.
Recommended Posts