Recent Ability of Image Recognition-MS State-of-the-art Research Results Using Computer Vision API with Python
Recently, I was able to understand how to use the Computer Vision API by touching it, and I was surprised at the higher performance than expected, so I decided to summarize it. After introducing what the Computer Vision API is, why it's amazing, and how powerful it can be when you actually use it, I'd like to show you the code. Through this article, I learned that you can easily use such a powerful image recognition function by writing a few lines of code, and I hope you will give it a try.
What is the Computer Vision API in the first place?
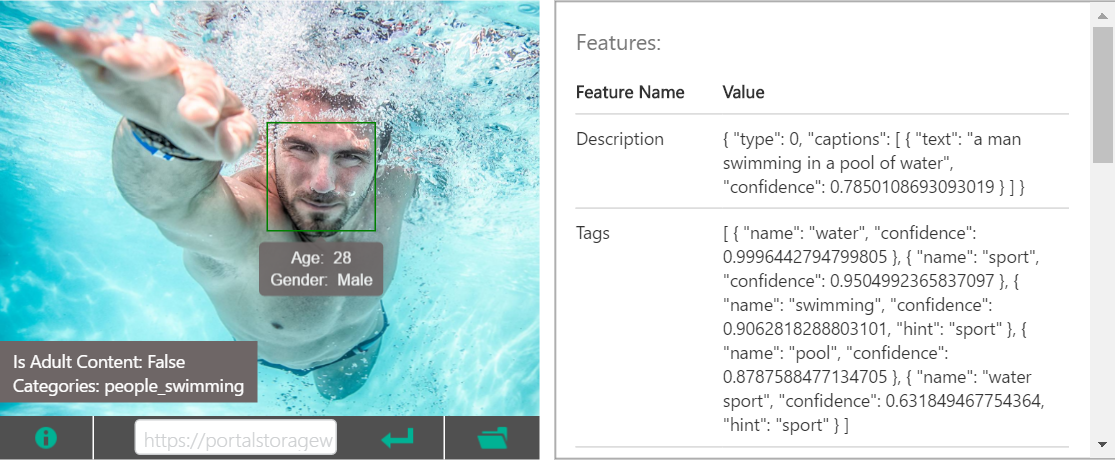
Microsoft's API service that throws an image in REST and returns the result of analyzing the image in JSON format. It not only recognizes the object in the image and outputs the tag, but also outputs the state and situation of the object on the image as a tag with verbs and adjectives. (ex. water, sport, swimming, man) Furthermore, based on them, it will add a plausible caption to the image in one sentence. (ex. a man swimming in a pool of water)
 (See Official Page)
(See Official Page)
Behind the scenes, a state-of-the-art image recognition engine that incorporates the latest research results of Microsoft Research is running, which is open to the general public.
Ability of Microsoft Research playing an active part in the back of Computer Vision API
Even though it's cutting-edge, I'm wondering how strong Microsoft Research is in this area in the first place. In the field of image recognition, there is a project called ImageNet that publishes a huge amount of images and accompanying annotations as an open dataset. There is a competition called Large Scale Visual Recognition Challenge sponsored by that, which competes for image recognition accuracy of a large amount of image data. At the latest competition (ILSVRC 2015), MSRA (Microsoft Research Asia) is ranked first in many tasks while research departments such as Google and research teams from top overseas universities are all competing.
 (Quoted from ILSVRC2015 Results)
(Quoted from ILSVRC2015 Results)
Since I was in a laboratory close to this field when I was a student, I had a vague image that MS often published "strong papers", but I am glad that I could know the specific situation by examining this time. At the end of this article, I also cite a related paper used for the Computer Vision API, but when I look at it, the latest research results are usually used, so I am convinced that it is amazing.
How accurate is it?
Let's actually throw your own image and see the analysis result. This time, I would like to introduce the ** caption generation function ** and ** tag generation function **, which I personally found to be particularly useful and interesting among the image recognition functions of the Computer Vision API. For studying, this time I created a simple web service that raises the image and displays the analysis result and deployed it on Azure. (I'd like to upload the code to Git and summarize it next time) Below are screenshots and impressions.
First of all ** Photographs of coffee and pound cake taken at the cafe **

One piece of cake and one cup of coffee were the correct answer. Looking at the tags, I was surprised to find a table, chocolate, and even eaten, which indicates that I was about to eat.
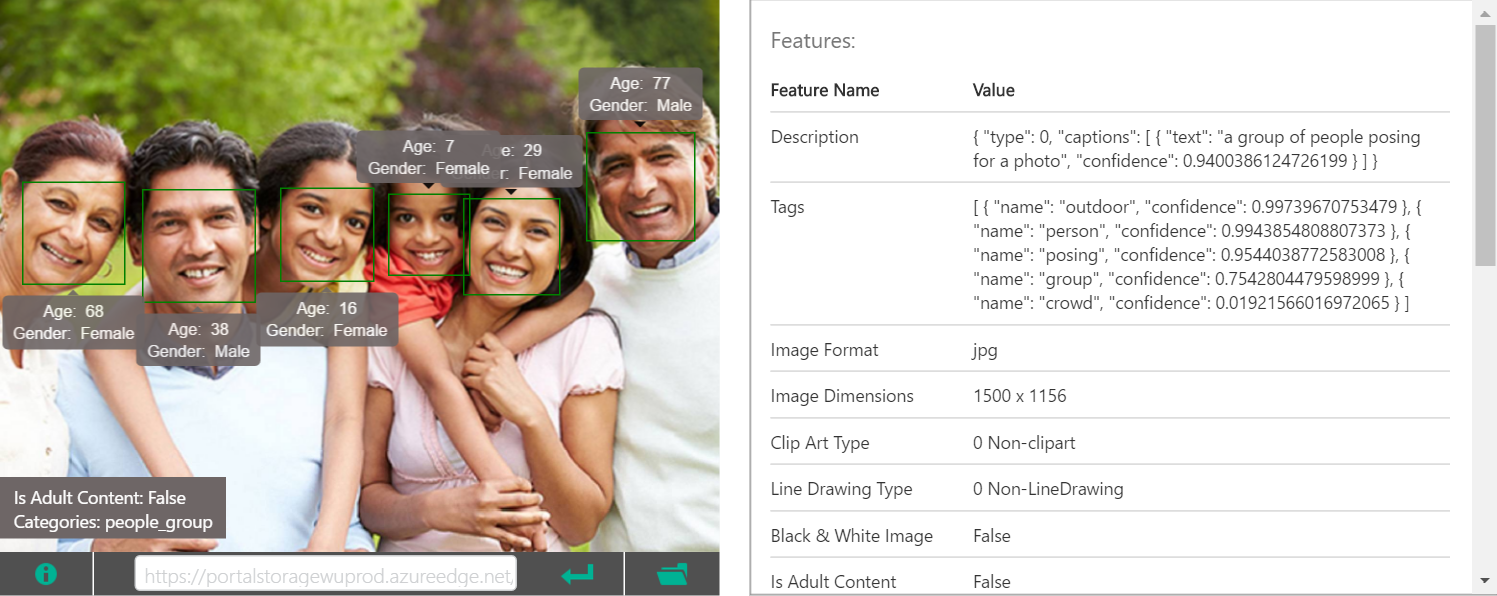
Next is ** a casual photo taken while traveling **

Looking at the generated captions, I was once again brilliantly told that the car was parked in front of the church. I was impressed that the positional relationship of the objects in the image was expressed in the caption.
Using the tags output in this way, it seems easy to implement adding image search functions to apps and web services and grouping them. Also, if there are a large number of images in the Web service, it may be interesting to analyze and rank them by the total number of tags, which will give new insights.
How do you implement it?
I would like to show you what kind of code and how much code can achieve this. I wrote it in Python2 system. Implementation samples of Python3 series and C #, Java, JavaScript, Objective-C, PHP, Ruby can be found at the bottom of here. ..
ComputerVision API usage part
import httplib
import urllib
image_url = ''
headers = {
# Request headers
'Content-Type': 'application/json',
# 'Content-Type': 'application/octet-stream',
'Ocp-Apim-Subscription-Key': 'Your key',
}
params = urllib.urlencode({
# Request parameters
'visualFeatures': 'Description',
# 'visualFeatures': 'Categories,Tags, Description, Faces, ImageType, Color, Adult',
# 'details': 'Celebrities'
})
conn = httplib.HTTPSConnection('api.projectoxford.ai')
body = """{'url': '%s'}""" % (image_url)
conn.request("POST", "/vision/v1.0/analyze?%s" % params, body, headers)
response = conn.getresponse()
caption_data = response.read()
conn.close()
In the above example, the image URL is thrown, but It is also possible to throw image data directly. Switching is possible by changing the value of Content-Type in headers.
'Content-Type': 'application/json'When giving an image URL
'Content-Type': 'application/octet-stream'When giving image data directly
So, if you want to throw data directly, specify octet-stream and The following part
body = """{'url': '%s'}""" % (image_url)
conn.request("POST", "/vision/v1.0/analyze?%s" % params, body, headers)
Can be changed to the following.
file_name = ''
img = open(file_name, 'rb').read()
conn.request("POST", "/vision/v1.0/analyze?%s" % params, img, headers)
In params, specify the desired analysis result with parameters. At this stage, the following seven values can be specified for visualFeatures.
- Categories
- Tags
- Description
- Faces
- ImageType
- Color
- Adult
(For details, refer to Request parameters in here) The above example of analyzing my photo is the result of specifying only Description (caption generation function and tag generation function) for visualFeatures.
If all are specified in visualFeatrues, the following JSON will be returned. Let's see the result when using the image used on the official page. You can also check the degree of conviction for each tag, whether it is an adult image, the position of the face of the person reflected, gender and age, etc.
| Analytical image |
|---|
 |
JSON returned
{
"categories": [
{
"name": "people_swimming",
"score": 0.98046875
}
],
"adult": {
"isAdultContent": false,
"isRacyContent": false,
"adultScore": 0.14750830829143524,
"racyScore": 0.12601403892040253
},
"tags": [
{
"name": "water",
"confidence": 0.99964427947998047
},
{
"name": "sport",
"confidence": 0.95049923658370972
},
{
"name": "swimming",
"confidence": 0.90628182888031006,
"hint": "sport"
},
{
"name": "pool",
"confidence": 0.87875884771347046
},
{
"name": "water sport",
"confidence": 0.631849467754364,
"hint": "sport"
}
],
"description": {
"tags": [
"water",
"sport",
"swimming",
"pool",
"man",
"riding",
"blue",
"top",
"ocean",
"young",
"wave",
"bird",
"game",
"large",
"standing",
"body",
"frisbee",
"board",
"playing"
],
"captions": [
{
"text": "a man swimming in a pool of water",
"confidence": 0.78501081244404836
}
]
},
"requestId": "your request Id",
"metadata": {
"width": 1500,
"height": 1155,
"format": "Jpeg"
},
"faces": [
{
"age": 29,
"gender": "Male",
"faceRectangle": {
"left": 748,
"top": 336,
"width": 304,
"height": 304
}
}
],
"color": {
"dominantColorForeground": "Grey",
"dominantColorBackground": "White",
"dominantColors": [
"White"
],
"accentColor": "19A4B2",
"isBWImg": false
},
"imageType": {
"clipArtType": 0,
"lineDrawingType": 0
}
}
Basically, the returned tags are general purpose (ex. Dogs, not poodles), but celebrities can even be personally identified. If you want to turn that feature on, go to details in params
'details' : 'Celebrities'
If you specify, the analysis result will be included in JSON. The celebrity judgment seems to be able to identify about 200,000 people, and when asked by other people who touched it, it seems that it also supports Demon Kogure! (How old is the age ...?)
How do I get started?
A Subscription Key is required to use Cognitive Services. Free trial is available here Please register. You will need to log in with your Microsoft Account. Specify the Subscription Key obtained by registering with Ocp-Apim-Subscription-Key on the sample code. There is also a paid plan, so if you want to use it firmly instead of trying it out, please see the following ** Usage plan ** item.
If you want to try something out before writing your own code, take a look at the Official Commentary Page (https://www.microsoft.com/cognitive-services/en-us/computer-vision-api). When you receive it, you can select the prepared image or upload your own image and check it, so it is recommended.
If you have a lot of opinions and ideas, such as trying to use it and doing more here, Give your apps a human side (Feedback sharing page referenced by the Computer Vision API development team). It's nice to be able to deliver user-side opinions directly to the development team in this way. Each improvement idea can be voted on, and once the votes are collected, it will be ranked higher, making it easier to attract attention. Let's use it together and improve it!
Usage plan (2016/8/5 postscript)
Starting today, ** Standard plan ** has been added to the previous trial plan Free! There is no SLA or support as the entire Cognitive Services is still in preview stage, I think you can consider it for business use as well.
| Plan | Description | Price |
|---|---|---|
| Free | 5,000 transactions per month | Free |
| Standard | 10 transactions per second | $ 1.50 per 1000 transactions |
You can set up a Standard Plan account directly from here. If you do not have a Microsoft Azure Subscription, you will need a Microsoft Azure Subscription to use the Standard Plan. Please try the free trial account for ¥ 20.500.
Also, if there is a way to use this API that has a business impact, please let me know in the comments or personally. I'm very interested in it personally! Lol
Reference (The research behind Computer Vision API)
Finally, I would like to introduce the research results that are used behind the Computer Vision API that I pulled from the official page. (Reference Official URL) The first paper is the one adopted at CVPR 2015, isn't it? Since CVPR is a top conference in international computer vision conferences, it can be said that it is a fairly high quality and high level research. I think it is very interesting with unprecedented speed that the cutting-edge research that was just announced a year ago is being developed as a service that can be used to the general public.
-
Hao Fang, Saurabh Gupta, Forrest Iandola, Rupesh Srivastava, Li Deng, Piotr Dollar, Jianfeng Gao, Xiaodong He, Margaret Mitchell, John Platt, Lawrence Zitnick, and Geoffrey Zweig, From Captions to Visual Concepts and Back,CVPR,June2015(won1stPrizeattheCOCOImageCaptioningChallenge2015)
-
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep Residual Learning for Image Recognition.arXiv(wonbothImageNetandMSCOCOcompetitions2015)
-
Yandong Guo, Lei Zhang, Yuxiao Hu, Xiaodong He, Jianfeng Gao, MS-Celeb-1M: Challenge of Recognizing One Million Celebrities in the Real World, IS&T International Symposium on Electronic Imaging, 2016
-
Xiao Zhang,Lei Zhang, Xin-Jing Wang, Heung-Yeung Shum, Finding Celebrities in Billions of Web Images, accepted by IEEE Transaction on Multimedia, 2012
Reference 2 (Positioning of Computer Vision API in MS)
The Computer Vision API (https://www.microsoft.com/cognitive-services/en-us/computer-vision-api) is Microsoft's Cognitive Services (https://www.microsoft.com/cognitive). -services /), one of the cloud-based API services It is an API that belongs to the Vision category out of the following 5 categories.
- Vision
- Speech
- Language
- Knowledge
- Search
The APIs in the Vision category are as follows.
- ** Computer Vision ** (This time)
- Emotion (estimate the emotions of people in images and videos)
- Face (estimate the age and gender of the person in the image)
- Video (Video image stabilization, face tracking, motion detection, create short video thumbnails from video)
The Computer Vision API provides the following features, including image recognition.
- ** Image recognition ** (This time)
- OCR (extracts characters on the image as text)
- Create an image thumbnail of the specified size centered on the gaze point (ROI) on the image (It seems to be useful when you want to prepare images of different sizes for smartphones and PCs)
Recommended Posts