[PYTHON] Gibt es ein Geheimnis in der Häufigkeit der Umfangszahlen?
【Überblick】
Ich habe die Häufigkeit der Zahlen überprüft, die im Umfangsverhältnis erscheinen. Ich habe auch die Anzahl der Napiers überprüft. Das Ziel liegt hinter dem Dezimalpunkt.
[Vorbereitung]
- Beziehen Sie den API-Schlüssel von Plotly, um die Python-Bibliothek Plotly zu verwenden. (Nicht erforderlich, wenn Sie kein Diagramm zeichnen) ・ Kreisverhältnis und Anzahl der Napiers Kopieren Sie die Zahl nach dem Dezimalpunkt von /e.5mil) in den Text. (Beachten Sie, dass die Anzahl der Napiers mit 0 gefüllt ist, da die erste Zeile eine andere Ziffer als die anderen Zeilen hat.)
[Ordnerstruktur]
|---scripts | --- pi.py (Überprüfen Sie die Häufigkeit der Umfangsverhältniszahlen.) | --- pi_graph.py (Erstellen Sie ein Balkendiagramm des Umfangsverhältnisses) | --- pi.txt (Umfangsverhältnis nach dem Dezimalpunkt) | --- e.py (Überprüfen Sie die Häufigkeit der Napier-Nummern) | --- e_graph.py (Balkendiagramm der Napier-Nummer erstellen) | --- e.txt (Anzahl der Napier nach dem Dezimalpunkt)
[Programm und Ergebnisse]
Anzeige des Diagramms https://plot.ly/~ユーザ名/0/#plot Sie können es sehen, indem Sie darauf zugreifen.
pi.py
# -*- coding: utf-8 -*-
zero = 0
one = 0
two = 0
three = 0
four = 0
five = 0
six = 0
seven = 0
eight = 0
nine = 0
for line in open('pi.txt', 'r'):
for i in xrange(100):
if(line[i] == '0'):
zero += 1
elif(line[i] == '1'):
one += 1
elif(line[i] == '2'):
two += 1
elif(line[i] == '3'):
three += 1
elif(line[i] == '4'):
four += 1
elif(line[i] == '5'):
five += 1
elif(line[i] == '6'):
six += 1
elif(line[i] == '7'):
seven += 1
elif(line[i] == '8'):
eight += 1
elif(line[i] == '9'):
nine += 1
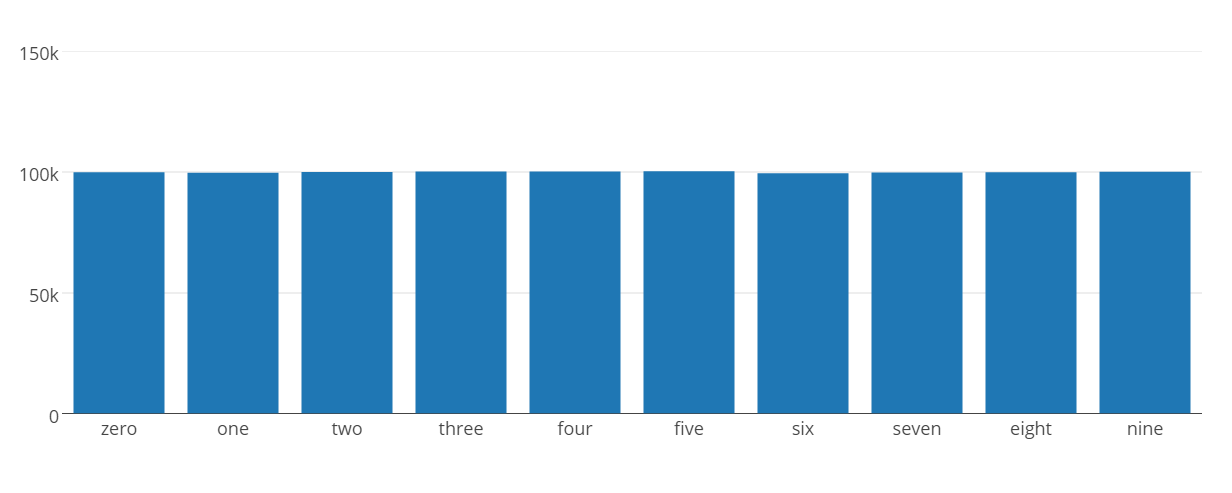
print zero #99959
print one #99758
print two #100026
print three #100229
print four #100230
print five #100359
print six #99548
print seven #99800
print eight #99985
print nine #100106
e.py
# -*- coding: utf-8 -*-
zero = -3 #Ich habe die erste Zeile des Textes mit 3 0s gefüllt und sie daher reduziert.
one = 0
two = 0
three = 0
four = 0
five = 0
six = 0
seven = 0
eight = 0
nine = 0
for line in open('e.txt', 'r'):
for i in xrange(60):
if(line[i] == '0'):
zero += 1
elif(line[i] == '1'):
one += 1
elif(line[i] == '2'):
two += 1
elif(line[i] == '3'):
three += 1
elif(line[i] == '4'):
four += 1
elif(line[i] == '5'):
five += 1
elif(line[i] == '6'):
six += 1
elif(line[i] == '7'):
seven += 1
elif(line[i] == '8'):
eight += 1
elif(line[i] == '9'):
nine += 1
print zero #498642
print one #500511
print two #499302
print three #501715
print four #500420
print five #500489
print six #499875
print seven #500015
print eight #499078
print nine #500290
pi_graph.py
# -*- coding: utf-8 -*-
import plotly
import plotly.plotly as py
import plotly.graph_objs as go
plotly.tools.set_credentials_file(username='Nutzername', api_key='API-Schlüssel')
data = [go.Bar(
x=['zero', 'one', 'two', 'three', 'four', 'five', 'six', 'seven', 'eight', 'nine'],
y=[99959, 99758, 100026, 100229, 100230, 100359, 99548, 99800, 99985, 100106]
)]
py.iplot(data, filename='basic-bar')
e_graph.py
# -*- coding: utf-8 -*-
import plotly
import plotly.plotly as py
import plotly.graph_objs as go
plotly.tools.set_credentials_file(username='Nutzername', api_key='API-Schlüssel')
data = [go.Bar(
x=['zero', 'one', 'two', 'three', 'four', 'five', 'six', 'seven', 'eight', 'nine'],
y=[498642, 500511, 499302, 501715, 500420, 500489, 499875, 500015, 499078, 500290]
)]
py.iplot(data, filename='basic-bar')
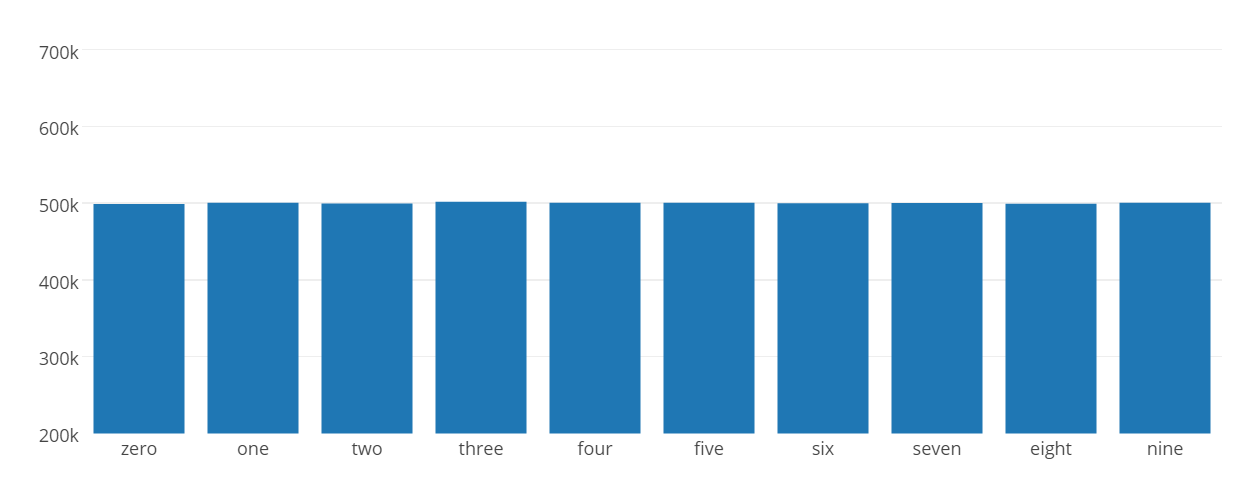
[Diskussion]
Es scheint, dass das Umfangsverhältnis und die Anzahl der Napier-Zahlen auf derselben Frequenz erscheinen ... Gibt es einen mathematischen Satz, der bereits mit derselben Häufigkeit erscheint? (Wenn Sie es wissen, lassen Sie es mich bitte in den Kommentaren wissen)
[Referenzseite]
https://plot.ly/python/bar-charts/