[PYTHON] [Satzklassifikation] Ich habe verschiedene Pooling-Methoden von Convolutional Neural Networks ausprobiert
Einführung
Bei der Satzklassifizierung wird Max-Pooling häufig für Convolutional Neural Networks (CNN) verwendet, aber ich habe mich gefragt, ob andere Pooling-Methoden nutzlos wären.
Daten
- Quellcode
- Implementiert mit Chainer.
- Datensatz
- Ich benutze Stanford Sentiment Treebank (SST). -Sie können es unter [hier] herunterladen (https://nlp.stanford.edu/sentiment/). --Wortverteilter Ausdruck
- Ich verwende das trainierte Modell von word2vec (GoogleNews-vectors-negative300.bin.gz). Sie können es unter [hier] herunterladen (https://code.google.com/archive/p/word2vec/).
Was ist Satzklassifikation?
Die Aufgabe, eine Anweisungsbezeichnung zuzuweisen. Zum Beispiel hat im obigen SST jeder Satz positive und negative Bezeichnungen.
[positiv]Sie hat eine gute Persönlichkeit und vor allem einen guten Stil.
[Negativ]Die Animation dieser Saison ist schlecht.
SST ist auf Englisch, aber das japanische Beispiel sieht so aus. Neben positiven Negativen gibt es auch Datensätze, mit denen Themen wie Sport und Politik behandelt werden können.
Netzwerkmodell
Basierend auf Convolutional Neural Networks for Satzklassifikation [Kim, 2014]. Auf dem Gebiet der Verarbeitung natürlicher Sprache wird dieses Papier häufig zitiert, wenn es um CNN geht.

Pooling-Schicht
Der Teil Max-Over-Time-Pooling (Max-Pooling) in der obigen Abbildung ist die Pooling-Ebene. Diesmal die Geschichte hier. Zusätzlich zum maximalen Pooling kann CNN auch ein durchschnittliches Pooling verwenden. Beim maximalen Pooling wird der größte Wert aus der Feature-Map abgerufen, während beim durchschnittlichen Pooling der Durchschnitt der Feature-Map-Werte abgerufen wird. Dieses Dokument hat bereits berichtet, dass das maximale Pooling in einigen Datensätzen eine höhere Genauigkeitsrate für die Textklassifizierung aufweist als das durchschnittliche Pooling.
Polsterung
Dann ist maximales Pooling in Ordnung, aber Bei der Verarbeitung natürlicher Sprache sind die Längen der Eingabesätze jedoch nicht gleich, so dass ein Prozess namens Auffüllen erforderlich ist, um die Längen der Eingabesätze einheitlich zu machen. Genau genommen wird daher die Satzlänge nicht gemittelt, sondern die maximale Satzlänge der Eingabe wird gemittelt. (Vielleicht ist das oben vorgestellte Papier auch ...) In diesem Fall habe ich mich gefragt, ob die durchschnittliche Pooling-Version nicht die Version ist, die die Feature-Map-Länge (maximale Satzlänge) gemittelt hat, sondern die Version, die die Satzlänge gemittelt hat.
(Beispiel.)

↑ Das Ergebnis der Faltung \
Code (Netzwerkteil)
cnn_average.py
class CNN_average(Chain):
def __init__(self, vocab_size, embedding_size, input_channel, output_channel_1, output_channel_2, output_channel_3, k1size, k2size, k3size, pooling_units, output_size=args.classtype, train=True):
super(CNN_average, self).__init__(
w2e = L.EmbedID(vocab_size, embedding_size),
conv1 = L.Convolution2D(input_channel, output_channel_1, (k1size, embedding_size)),
conv2 = L.Convolution2D(input_channel, output_channel_2, (k2size, embedding_size)),
conv3 = L.Convolution2D(input_channel, output_channel_3, (k3size, embedding_size)),
l1 = L.Linear(pooling_units, output_size),
)
self.output_size = output_size
self.train = train
self.embedding_size = embedding_size
self.ignore_label = 0
self.w2e.W.data[self.ignore_label] = 0
self.w2e.W.data[1] = 0 #Nicht-Charakter
self.input_channel = input_channel
def initialize_embeddings(self, word2id):
#w_vector = word2vec.Word2Vec.load_word2vec_format('./vector/glove.840B.300d.txt', binary=False) # GloVe
w_vector = word2vec.Word2Vec.load_word2vec_format('./vector/GoogleNews-vectors-negative300.bin', binary=True) # word2vec
for word, id in sorted(word2id.items(), key=lambda x:x[1])[1:]:
if word in w_vector:
self.w2e.W.data[id] = w_vector[word]
else:
self.w2e.W.data[id] = np.reshape(np.random.uniform(-0.25,0.25,self.embedding_size),(self.embedding_size,))
def __call__(self, x):
h_list = list()
ox = copy.copy(x)
if args.gpu != -1:
ox.to_gpu()
b = x.shape[0]
emp_array = xp.array([len(xp.where(x[i].data != 0)[0]) for i in range(b)], dtype=xp.float32).reshape(b,1,1,1)
x = xp.array(x.data)
x = F.tanh(self.w2e(x))
b, max_len, w = x.shape # batch_size, max_len, embedding_size
x = F.reshape(x, (b, self.input_channel, max_len, w))
c1 = self.conv1(x)
b, outputC, fixed_len, _ = c1.shape
tf = self.set_tfs(ox, b, outputC, fixed_len) # true&flase
h1 = self.average_pooling(F.relu(c1), b, outputC, fixed_len, tf, emp_array)
h1 = F.reshape(h1, (b, outputC))
h_list.append(h1)
c2 = self.conv2(x)
b, outputC, fixed_len, _ = c2.shape
tf = self.set_tfs(ox, b, outputC, fixed_len) # true&flase
h2 = self.average_pooling(F.relu(c2), b, outputC, fixed_len, tf, emp_array)
h2 = F.reshape(h2, (b, outputC))
h_list.append(h2)
c3 = self.conv3(x)
b, outputC, fixed_len, _ = c3.shape
tf = self.set_tfs(ox, b, outputC, fixed_len) # true&flase
h3 = self.average_pooling(F.relu(c3), b, outputC, fixed_len, tf, emp_array)
h3 = F.reshape(h3, (b, outputC))
h_list.append(h3)
h4 = F.concat(h_list)
y = self.l1(F.dropout(h4, train=self.train))
return y
def set_tfs(self, x, b, outputC, fixed_len):
TF = Variable(x[:,:fixed_len].data != 0, volatile='auto')
TF = F.reshape(TF, (b, 1, fixed_len, 1))
TF = F.broadcast_to(TF, (b, outputC, fixed_len, 1))
return TF
def average_pooling(self, c, b, outputC, fixed_len, tf, emp_array):
emp_array = F.broadcast_to(emp_array, (b, outputC, 1, 1))
masked_c = F.where(tf, c, Variable(xp.zeros((b, outputC, fixed_len, 1)).astype(xp.float32), volatile='auto'))
sum_c = F.sum(masked_c, axis=2)
p = F.reshape(sum_c, (b, outputC, 1, 1)) / emp_array
return p
Versuchsinhalt
Vergleichen Sie die folgenden vier Pooling-Methoden mit der Stanford Sentiment Treebank (SST) als Datensatz
- max pooling
- durchschnittliches Pooling (1 / max len) ← Derjenige, der den Durchschnitt mit der maximalen Satzlänge nimmt
- durchschnittliches Pooling (1 / gesendet len) ← Derjenige, der den Durchschnitt für jede Satzlänge nimmt --Attention Pooling ← Ich habe versucht, den Attention-Mechanismus für die Pooling-Ebene zu verwenden. Weitere Informationen hier
Versuchsergebnis
| pooling method | SST-2 | SST-5 |
|---|---|---|
| max | 86.3 (0.27) | 46.5 (1.13) |
| average (1/max len) | 84.6 (0.38) | 46.0 (0.69) |
| average (1/sent len) | 86.6 (0.51) | 47.3 (0.44) |
| attention | 86.0 (0.20) | 47.2 (0.37) |
Der Wert ist der Durchschnitt nach 5 Versuchen und der Wert in () ist die Standardabweichung. SST-5 ist eine Aufgabe, 5 Werte von sehr negativ, negativ, neutral, positiv und sehr positiv zu klassifizieren, und SST-2 ist eine Aufgabe, positiv und negativ ohne neutral zu klassifizieren.
maximales Pooling Es wackelt ziemlich stark, und das Ergebnis ist, dass das durchschnittliche Pooling, das durch die Satzlänge gemittelt wird, das beste ist. Das durchschnittliche Pooling, das den Durchschnitt mit der maximalen Satzlänge ergibt, ist sicherlich schwächer als das maximale Pooling. ..
Visualisieren Sie den Status der Feature-Map
[very positive] I admired this work a lot.
Ich habe versucht zu überprüfen, wie die Feature-Map von maximalem Pooling CNN und durchschnittlichem Pooling (1 / gesendet len) CNN für den Satz gelernt wird.
admired(Bewundern)Ein Wort, das die positive Bedeutung von ausdrückt und betonta lotIst der Punkt der Vorhersage.
Die Fenstergröße von CNN beträgt hier 3. Die Anzahl der Feature-Maps beträgt 100.
Erstens, maximales Pooling. .. .. Dieser Typ verwechselt diesen Satz mit "[positiv]" und sagt ihn voraus. Es tut mir Leid.

Da es sich um maximales Pooling handelt, wird danach der dunkelste Teil jeder Feature-Map extrahiert.
admired this workEs gibt viele Feature-Maps, aus denen der Teil extrahiert wird.
bewunderte diese Arbeit und viel. <PAD>Wird in einer separaten Feature-Map extrahiert.
Als nächstes durchschnittliches Pooling. .. .. Dieser Typ antwortet richtig "[sehr positiv]". Süßer Junge.
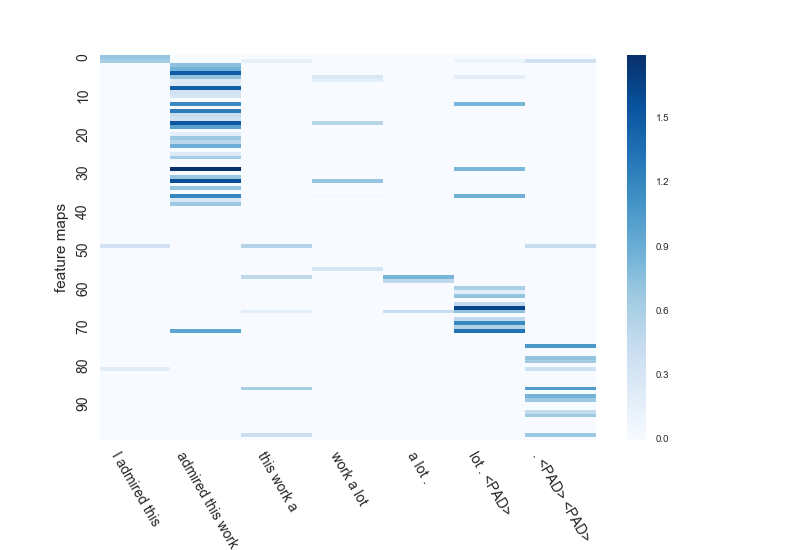
Da es sich um ein durchschnittliches Pooling handelt, können Sie neben dem dunkelsten Teil mehrere Dinge wie den zweiten und dritten berücksichtigen.
#### **`bewunderte diese Arbeit und viel. <PAD>Sie können auch eine Feature-Map anzeigen, die extrahiert wird.`**
``` <PAD>Sie können auch eine Feature-Map anzeigen, die extrahiert wird.
Es scheint, dass die Lernergebnisse selbst bei demselben CNN zwischen maximalem Pooling, bei dem nur der Maximalwert verwendet wird, und durchschnittlichem Pooling, bei dem alle Werte verwendet werden, um den Durchschnittswert zu erhalten, sehr unterschiedlich sind.
# Erwägung
Während Max Pooling nur ein Feature aus einer Feature-Map extrahieren kann
Durch durchschnittliches Pooling und Aufmerksamkeitspooling können mehrere Identitäten aus einer Feature-Map extrahiert werden.
Im obigen Beispiel ist es möglich, "bewundert" und "viel" zu betrachten, die gleichzeitig in einer Feature-Map ein wenig voneinander entfernt sind. Ich frage mich, ob das gut war. .. ..
# abschließend
In der Verarbeitung natürlicher Sprache wird häufig das maximale Pooling verwendet. Es stellte sich jedoch heraus, dass unerwartetes durchschnittliches Pooling auch verwendet werden kann, wenn es ordnungsgemäß durch die Satzlänge geteilt wird.
Tatsächlich denke ich, dass durchschnittliches Pooling intuitiv besser ist.
Die Berechnung dauert länger als max, aber es stört mich nicht, weil CNN selbst schnell ist. (Es war viel schneller als RNN mit LSTM.)
Wenn ich von nun an CNN mache, möchte ich gleichzeitig versuchen, durchschnittlich zu bündeln.
Recommended Posts