[PYTHON] Was ist xg boost (1) (für Anfänger)
Als Datenwissenschaftler möchte ich zurückblicken und organisieren, was ich nach Gamshala gekommen bin. Ich werde mich nicht mit tatsächlichen tatsächlichen Daten befassen, sondern aufschreiben, was ich gelernt habe, um Ausgabe zu erzeugen. Zunächst möchte ich mit xgboost umgehen, aber von Anfang an mit dem Lernen von Ensembles. (xgboost ist eine Art Ensemble-Lernen) Xgboost ist eine vielseitige Methode für Vorhersageaufgaben.
Was ist Ensemble-Lernen?
Wenn Sie ein Vorhersageproblem mit Daten lösen möchten, können Sie mehrere Lerngeräte kombinieren, um die Genauigkeit zu verbessern und ein Lerngerät zu erstellen.
Anstatt eines mit nur einem Lerngerät zu erstellen, können Sie basierend auf den Ergebnissen ein Lerngerät erstellen oder eine Kombination aus mehreren Lerngeräten erstellen, um die Genauigkeit zu erhöhen. Die Idee. Es kann grob in drei Typen eingeteilt werden. Grundkenntnisse davor.
Bias und Varianz
Bias: Durchschnitt der tatsächlichen und vorhergesagten Werte Varianz: Der Grad der Streuung der vorhergesagten Werte
④ ist ein Zustand mit guter Genauigkeit, da er eine geringe Vorspannung und eine geringe Varianz aufweist. ③ ist ein Zustand hoher Varianz. Das Modell ist wahrscheinlich übertrainiert. Vorhersagen, die neue Daten verwenden, sind in der Regel ungenau. ② ist ein Zustand mit hoher Vorspannung. Es besteht eine hohe Wahrscheinlichkeit, dass die Daten überhaupt nicht gelernt wurden.
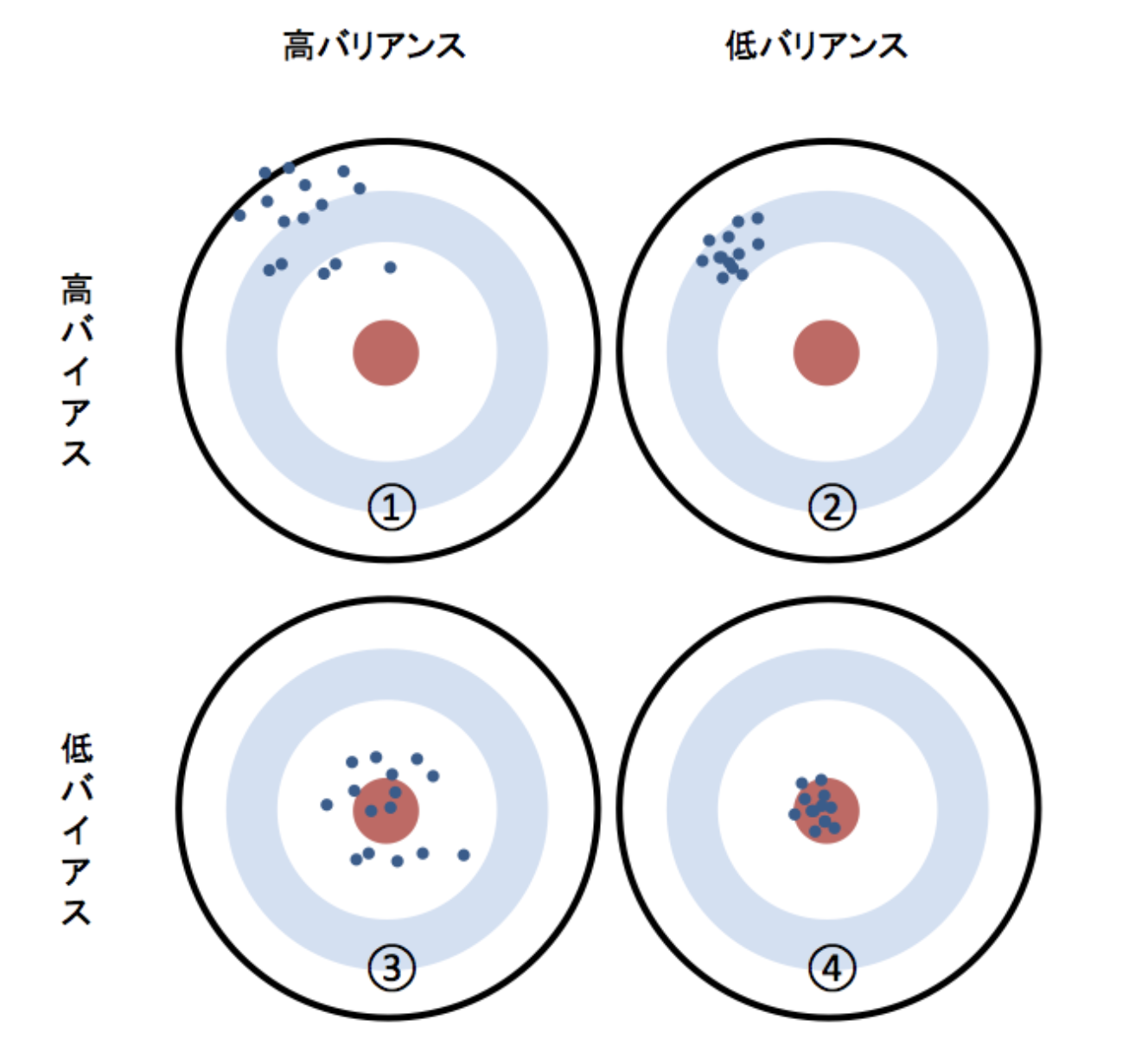 Die Abbildung ist sehr leicht zu verstehen, daher werde ich die Abbildung auf der Referenzseite ausleihen.
Die Abbildung ist sehr leicht zu verstehen, daher werde ich die Abbildung auf der Referenzseite ausleihen.
(https://www.codexa.net/what-is-ensemble-learning/)
Drei Methoden
Absacken
Im Allgemeinen hat es die Eigenschaft, die Varianz des Vorhersageergebnisses des Modells zu verringern. Beim Absacken werden die Trainingsdaten wiederhergestellt und unter Verwendung der Boost-Trap-Methode extrahiert, um dem Datensatz Diversität hinzuzufügen. Die Restaurationsextraktion ist eine Extraktionsmethode, bei der eine einmal extrahierte Probe erneut extrahiert wird.
Aggregieren Sie jedes Ergebnis, um einen Lernenden zu erstellen. Wenn es sich um eine Regression handelt, wird sie durch den Durchschnittswert bestimmt, und wenn es sich um eine Klassifizierung handelt, wird sie mit Stimmenmehrheit entschieden.
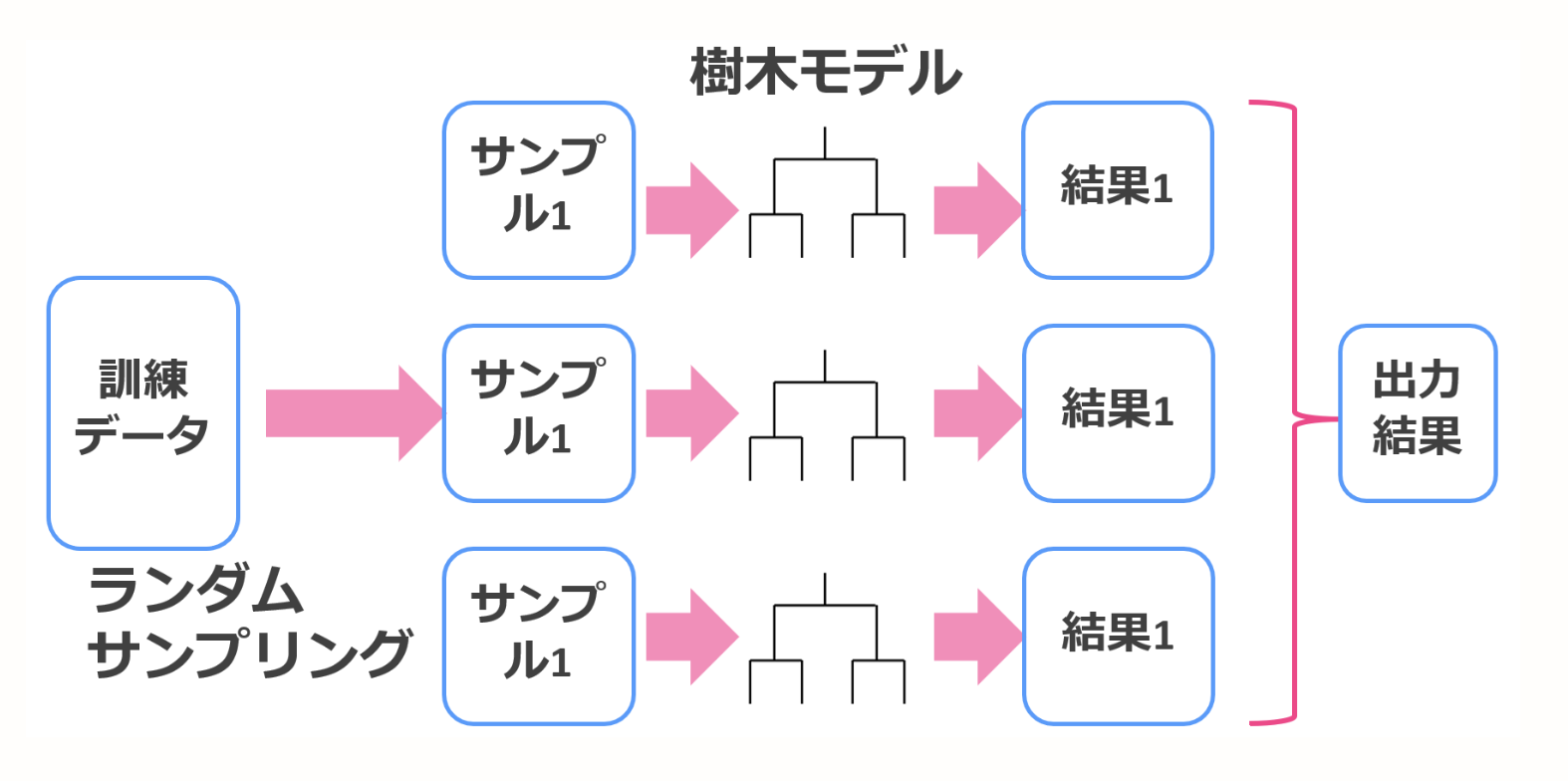 Die Abbildung ist sehr leicht zu verstehen, daher werde ich die Abbildung auf der Referenzseite ausleihen.
[Was ist Ensemble-Lernen? Unterschied zwischen Absacken und Boosten](https://toukei-lab.com/ensemble)
Die Abbildung ist sehr leicht zu verstehen, daher werde ich die Abbildung auf der Referenzseite ausleihen.
[Was ist Ensemble-Lernen? Unterschied zwischen Absacken und Boosten](https://toukei-lab.com/ensemble)
Erhöhen
Im Allgemeinen hat es die Eigenschaft, die Vorspannung in Bezug auf die Vorhersagegenauigkeit des Modells zu verringern. Durch Boosting wird zunächst das zugrunde liegende Modell trainiert, um eine Basislinie zu erstellen. Das als Basislinie verwendete Grundmodell wird viele Male iterativ verarbeitet, um die Genauigkeit zu verbessern. Konzentrieren Sie sich auf die falsche Vorhersage des Grundmodells und fügen Sie "Gewicht" hinzu, um das nächste Modell zu verbessern. Machen Sie ein Modell und machen Sie ein neues Modell mit Fehlern. Zum Schluss alles zusammenfügen. xgboost ist eine Implementierung, die dieses Boosting verwendet.
Das Lernen braucht Zeit, wahrscheinlich weil das erste Modell berücksichtigt wird.
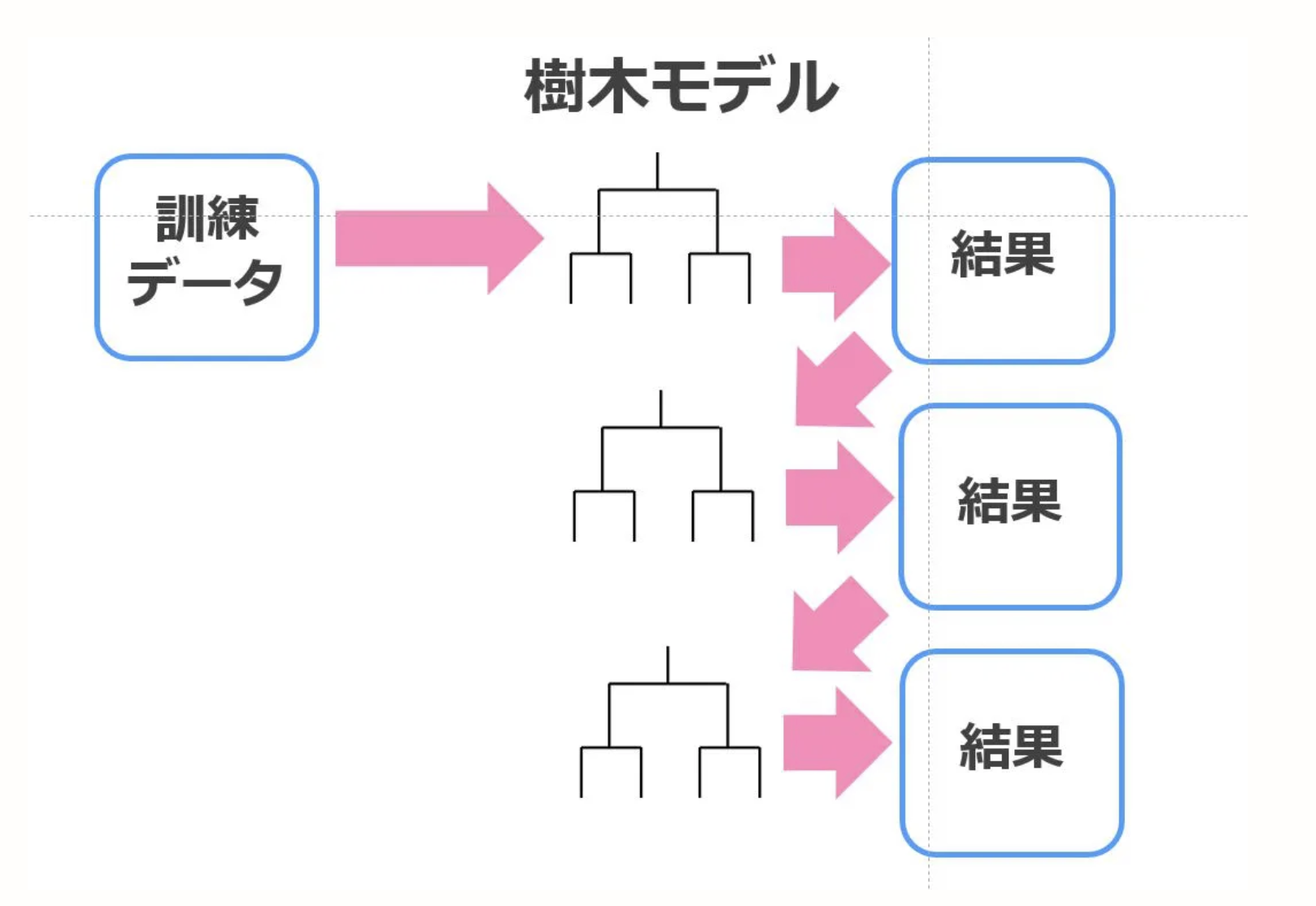 Die Abbildung ist sehr leicht zu verstehen, daher werde ich die Abbildung auf der Referenzseite ausleihen.
[Was ist Ensemble-Lernen? Unterschied zwischen Absacken und Boosten](https://toukei-lab.com/ensemble)
Die Abbildung ist sehr leicht zu verstehen, daher werde ich die Abbildung auf der Referenzseite ausleihen.
[Was ist Ensemble-Lernen? Unterschied zwischen Absacken und Boosten](https://toukei-lab.com/ensemble)
So stapeln Sie Modelle. Es scheint möglich zu sein, Voreingenommenheit und Varianz anzupassen und einzubeziehen ... Es war kompliziert, also werde ich es weglassen.
Gradientenverstärkung
Ein Modell, das lernt, indem es nach einer Richtung sucht, die den Verlust minimiert, wenn eine Funktion oder Verlustfunktion definiert wird.
Haben Sie ein Bild mit einer mathematischen Formel.
Verlustfunktion
Ein bestimmter Index (= Funktion) wird verwendet, um zu beurteilen, wie hoch der vorhergesagte Wert und der tatsächliche Wert sind und ob es einen Unterschied gibt. Verschieben Sie die Parameter des Modells so, dass der Index minimiert wird.
Die Verlustfunktion von XGBoost ist wie folgt.
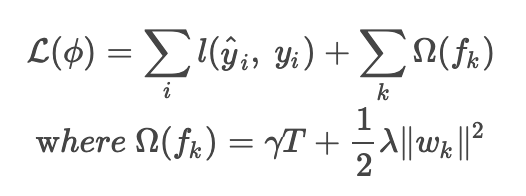 Die Summe der Fehler zwischen dem vorhergesagten Wert und dem Zielwert plus dem Regularisierungsterm.
Die Summe der Fehler zwischen dem vorhergesagten Wert und dem Zielwert plus dem Regularisierungsterm.
Die zweite Gleichung repräsentiert den Regularisierungsterm. Das Vorhandensein des Rückbaumgewichts w wird von w bei der Minimierung der Verlustfunktion berücksichtigt und verhindert ein Übertraining.
Die Erklärung jeder Variablen lautet wie folgt.

Funktionsoptimierung
Jetzt, da wir eine Verlustfunktion haben, müssen wir sie nur noch optimieren.
Wenn die obige Verlustfunktion durch w transformiert und differenziert wird
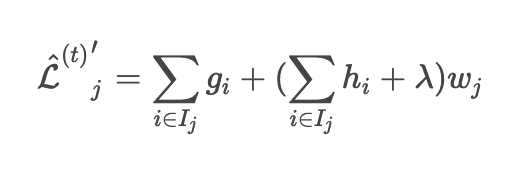 Wird sein.
Wird sein.
Wenn diese Gleichung 0 ist, minimiert w die Verlustfunktion. (Mathematikniveau der High School)
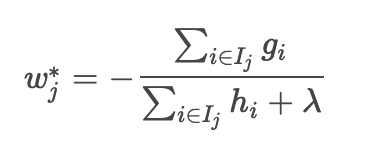 Wird sein.
Wird sein.
Wenn Sie dies in eine ungefähre Verlustfunktion einsetzen, erhalten Sie den minimalen Verlustwert.
Hier q die Struktur von XGBoost.  Dies ist die Formel, die xgboost auswertet.
Dies ist die Formel, die xgboost auswertet.
Bewegen Sie die Probe
Verwenden Sie einen Brustkrebs-Datensatz.
import xgboost as xgb
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
def main():
#Laden des Brustkrebs-Datensatzes
dataset = datasets.load_breast_cancer()
X, y = dataset.data, dataset.target
#Zum Lernen und Verifizieren aufgeteilt
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.3,
shuffle=True,
random_state=42,
stratify=y)
#Ändern Sie das Format des Datensatzes
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test, label=y_test)
#Parameter zum Lernen
xgb_params = {
#Binäre Klassifizierung
'objective': 'binary:logistic',
#Bewertungsindex
'eval_metric': 'logloss',
}
#Lerne mit xgboost
bst = xgb.train(xgb_params,
dtrain,
num_boost_round=100,
)
#Berechnet mit Verifizierungsdaten
y_pred_proba = bst.predict(dtest)
#Schwelle 0.5 bis 0,In 1 konvertieren
y_pred = np.where(y_pred_proba > 0.5, 1, 0)
#Siehe Genauigkeit
acc = accuracy_score(y_test, y_pred)
print('Accuracy:', acc)
if __name__ == '__main__':
main()
Ergebnis
acc: 0.96
Zusammenfassung
xgboost ist ein Modell, das ein Modell durch Boosten erstellt und lernt und Parameter mit Gradienteninformationen während des Lernens ermittelt und aktualisiert.
Referenz
Verwenden alle fortgeschrittenen maschinellen Lernenden es? !! Ich werde den Mechanismus des Ensemble-Lernens und drei Arten erklären Was ist Ensemble-Lernen? Unterschied zwischen Absacken und Boosten Erklärung des XGBoost-Algorithmus durch Lesen des Papiers
Recommended Posts