[PYTHON] Vorhersage kurzlebiger Arbeiten von Weekly Shonen Jump durch maschinelles Lernen (Teil 1: Datenanalyse)
1. Zuallererst
Weekly Shonen Jump (im Folgenden als Jump bezeichnet) ist das meistverkaufte Cartoon-Magazin in Japan [^ Auflage]. Unnötig zu sagen, ich bin ein großer Fan.
Das Serialisierungstreffen der Sprungredaktion ist sehr streng. In dem Fiction-Cartoon "Bakuman.", der den Kampf eines Sprungschreibers, der Redaktion, darstellt [Jede Ausgabe Leserumfrage](https://ja.wikipedia.org/wiki/%E9%80%B1%E5%88%8A%E5%B0%91%E5%B9%B4%E3%82%B8 % E3% 83% A3% E3% 83% B3% E3% 83% 97 # .E3.82.A2.E3.83.B3.E3.82.B1.E3.83.BC.E3.83.88.E8. Basierend auf 87.B3.E4.B8.8A.E4.B8.BB.E7.BE.A9) wird die Popularität jedes Mangas bewertet und die Reihenfolge der Veröffentlichung und die eingestellten Arbeiten werden festgelegt [^] Veröffentlichungsauftrag]. Es ist nicht ungewöhnlich, dass die Serialisierung innerhalb von 10 Wochen nach Beginn der Serialisierung abgebrochen wird (etwa ein Buch). Es ist eine sehr harte Welt.
In diesem Artikel verwenden wir maschinelles Lernen, um kurzlebige Arbeiten vorherzusagen (Arbeiten, die innerhalb von 10 Wochen abgeschlossen sein werden). ** Das ultimative Ziel ist es, die Arbeit vorherzusagen, die vor der Sprungredaktionsabteilung eingestellt werden soll. Wenn die Arbeit, die Sie mögen, gefährlich ist, stellen Sie einen Fragebogen aus, um die Unterbrechung zu vermeiden ** [^ Sprung]. Da wir das Ergebnis des Leserfragebogens nicht kennen, geben wir den Verlauf der Veröffentlichungsreihenfolge ein und geben aus, ob es sich um ein kurzlebiges Werk handelt Multilayer Perceptron [^ [Multilayer] ist in TensorFlow implementiert. Verwenden Sie zum Lernen die Web-API und die Media Arts Database der Kulturagentur. ), Die Geschirrinformationen für ca. 46 Jahre werden verwendet.
Dieser Artikel wird in zwei Teile unterteilt. Der erste Teil (dieses Mal) erfasst und analysiert die Daten, und der zweite Teil (das nächste Mal) lernt und testet die Daten. Die folgende Abbildung ist Teil des Analyseergebnisses des ersten Teils.

[^ Auflagenzahl]: Laut einer Umfrage der Japan Magazine Association. Vom 1. Oktober 2015 bis 30. September 2016 Anzahl der Exemplare von Comic-Magazinen für Jungen, Comics für Männer Zeitschriftenauflage, Comic-Zeitschriftenauflage für Mädchen /data_002/w5.html#001), Anzahl der Comic-Magazine für Frauen.
[^ Veröffentlichungsreihenfolge]: Während der Arbeit wurden die Veröffentlichungsreihenfolge und die eingestellten Arbeiten hauptsächlich auf der Grundlage der Ergebnisse des Leserfragebogens festgelegt. Laut dem folgenden Artikel scheint die Sprungredaktion dies bestritten zu haben und sagte: "Wir berücksichtigen nicht unbedingt nur die Ergebnisse der Leserumfrage." Die Redaktion "Jump" bestreitet Gerüchte über das oberste Prinzip des Fragebogens ... Leser sind kompliziert
[^ Mehrschichtig]: Geplant. Wir werden je nach Leistung eine andere Methode in Betracht ziehen.
[^ Sprung]: Wie oben erwähnt, entscheidet die Sprungredaktion in Wirklichkeit unter Berücksichtigung verschiedener Faktoren über die eingestellte Arbeit. Ich hoffe, Sie verstehen diesen Artikel als Täuschung eines Sprungfans.
2. Umwelt
Erstellen Sie die folgende virtuelle Umgebung "comic" mit "anaconda".
conda create -n comic python=3.5
source activate comic
conda install pandas matplotlib jupyter notebook scipy scikit-learn seaborn scrapy
pip install tensorflow
Die yml-Datei befindet sich hier. Tensorflow und scikit-learn sind enthalten, da sie im zweiten Teil benötigt werden. .. Da pairplot () für die Visualisierung verwendet wird, wird seaborn verwendet. ) Wird eingefügt.
3. Datenerfassung
3.1 Quelle
Kulturagentur Media Arts Database, Sprungtabelle für ungefähr 46 Jahre (3. November 1969 - 25. Juli 2016) Ist für die Öffentlichkeit zugänglich [^ derzeit].
[^ Present]: Stand 4. April 2017.


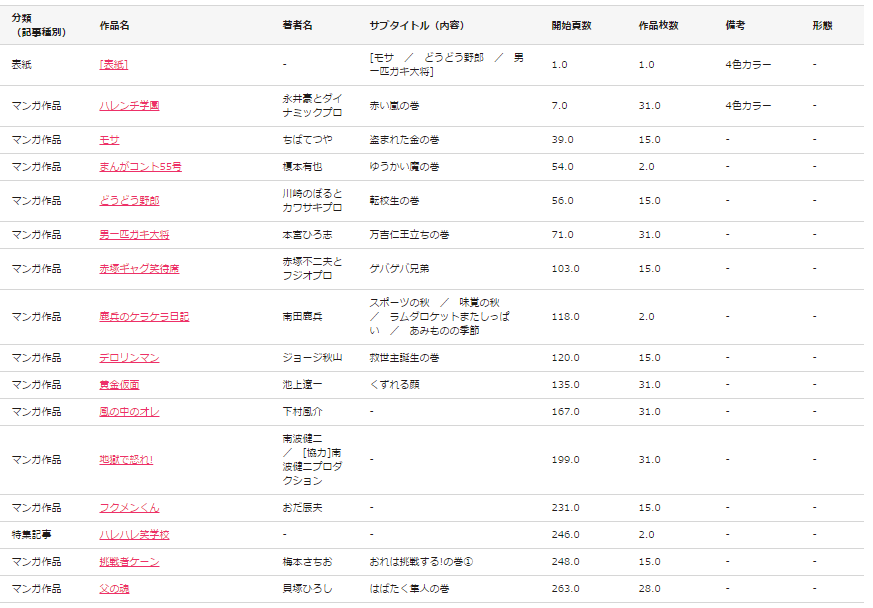
Die obige Abbildung ist ein Beispiel für die Untersuchung des Inhaltsverzeichnisses der Jump-Ausgabe vom 3. November 1969. Im Folgenden werden die Informationen zum Inhaltsverzeichnis mithilfe der im Kommentarbereich eingeführten Web-API extrahiert.
3.2 Web API
** Verarbeitete Daten von Mein Github so weit wie möglich, um die Belastung des Servers der Kulturagentur zu minimieren. Bitte besorgen Sie es **. Das Notizbuch ist hier, also hoffe ich, dass Sie es verwenden können.
Verwenden Sie Manga Field WebAPI der Kulturagentur der Kulturagentur für Medienkunst, um die für die Analyse erforderlichen Daten zu erhalten. Informationen zur Verwendung der Web-API mit python3 finden Sie unter Bis zum Zugriff auf die Web-API, die json mit Python3 zurückgibt und das Ergebnis ausgibt. Vielen Dank.
import
import json
import urllib.request
from time import sleep
Erhalten Sie Suchergebnisse für das Magazinvolumen
Verwenden Sie die folgende Funktion "search_magazine ()", um die Informationen zum Magazinvolumen von Weekly Shonen Jump zu durchsuchen. Die von dieser Funktion erhaltene eindeutige ID wird im nächsten Abschnitt für "Abrufen von Informationen zum Magazinvolumen" benötigt.
def search_magazine(key='JUMPrgl', n_pages=25):
"""
Zeitschriften, die den Schlüssel in der "eindeutigen ID", "Zeitschriftenvolumen-ID" oder "Zeitschriftencode" enthalten,
n_Es ist eine Funktion, um Seiten zu erhalten.
"""
url = 'https://mediaarts-db.bunka.go.jp/mg/api/v1/results_magazines?id=' + \
key + '&page='
magazines = []
for i in range(1, n_pages):
response = urllib.request.urlopen(url + str(i))
content = json.loads(response.read().decode('utf8'))
magazines.extend(content['results'])
return magazines
In der Web-API können Sie "eindeutige ID", "Magazin-Volume-ID" und "Magazin-Code" mit "ID" und die Suchseitennummer (100 Elemente pro Seite, Standard ist 1) mit "Seite" angeben. Da Weekly Shonen Jump "JUMPrgl" in der "Magazin-Volume-ID" enthält, geben Sie "id = JUMPrgl" an. Da die Suchergebnisse für Weekly Shonen Jump insgesamt 24 Seiten (2320 Ergebnisse) umfassen, müssen außerdem 1 bis 24 angegeben werden, um "Seite" zu erhalten. Weitere Informationen finden Sie unter Web-API-Spezifikationen.
Da die URL der Media Arts-Datenbank der Kulturagentur ab dem 31. März 2017 geändert wurde, wurde die Anforderungs-URL (https://mediaarts-db.bunka.go.jp/webapi_proto_documents.pdf) unter Web-API-Spezifikationen beschrieben Die neue URL (https: // mediaarts-db.bunka.go.jp / mg / api / v1 / results_magazines) anstelle von https: // mediaarts-db.jp / mg / api / v1 / results_magazines) Bitte beachten Sie, dass Sie verwenden müssen.
Erfassung von Informationen zum Zeitschriftenvolumen
Die folgende Funktion extract_data () extrahiert die erforderlichen Inhaltsverzeichnisinformationen und save_data () speichert die Inhaltsverzeichnisinformationen.
def extract_data(content):
"""
Dies ist eine Funktion, um die im Inhalt enthaltenen Indexinformationen abzurufen.
- year:Ausstellungsjahr
- no:Anzahl der Probleme
- title:Titel der Arbeit
- author:Autor
- color:Ob es Farbe ist oder nicht
- pages:Anzahl der geposteten Seiten
- start_page:Startseite der Arbeit
- best:Publikationsauftrag von Anfang an gezählt
- worst:Die Buchungsreihenfolge wird ab dem Ende des Buches gezählt
"""
#Es werden nur Manga-Werke extrahiert.
comics = [comic for comic in content['contents']
if comic['category']=='Manga Arbeit']
data = []
year = int(content['basics']['date_indication'][:4])
#Eine Ausnahmeverarbeitung ist erforderlich, da die Anzahl der Probleme möglicherweise nicht aufgeführt ist.
try:
no = int(content['basics']['number_indication'])
except ValueError:
no = content['basics']['number_indication']
for comic in comics:
title= comic['work']
if not title:
continue
#Eine Ausnahmebehandlung ist erforderlich, da bei einigen Werken nicht die Anzahl der aufgelisteten Seiten angegeben ist.
#Es gibt keinen besonderen Grund, aber nicht gelistete Werke werden als 10 Seiten verarbeitet.
try:
pages = int(comic['work_pages'])
except ValueError:
pages = 10
#Zur Unterstützung von Werken, die in mehreren Folgen pro Woche veröffentlicht werden, wie "Inumaru Dashi"
#Wenn der Titel bereits in den Daten enthalten ist, registrieren Sie ihn nicht als neues Datum.
#Es wird nur die Anzahl der vorhandenen Bezugsseiten hinzugefügt.
if len(data) > 0 and title in [datum['title'] for datum in data]:
data[[datum['title'] for datum in
data].index(title)]['pages'] += pages
else:
data.append({
'year': year,
'no': no,
'title': comic['work'],
'author': comic['author'],
'subtitle': comic['subtitle'],
'color': int('Farbe' in comic['note']),
'pages': int(comic['work_pages']),
'start_pages': int(comic['start_page'])
})
#Um den Mini-Manga des Projekts auszuschließen, werden Daten mit insgesamt 5 Seiten oder weniger von der Liste ausgeschlossen.
filterd_data = [datum for datum in data if datum['pages'] > 5]
for n, datum in enumerate(filterd_data):
datum['best'] = n + 1
datum['worst'] = len(filterd_data) - n
return filterd_data
Es ist eine schlammige Geschichte, aber es fiel mir schwer, mit einigen Gag-Cartoons umzugehen. Zum Beispiel ist "Inumaru Dashi" im Grunde zwei Folgen pro Woche. Obwohl es veröffentlicht wurde, wird jede Geschichte in einer separaten Zeile in der Datenbank beschrieben. Da es notwendig ist, diese als ein Werk zu betrachten, wird der "Titel" des "Comics", wenn er sich in den "Daten" befindet, nicht als ein anderes "Datum" und das vorhandene "Datum" zu den "Daten" hinzugefügt Wir bearbeiten, um Seiten hinzuzufügen. Außerdem wird beispielsweise "Pyu to Blow! Jaguar" unabhängig von seiner Beliebtheit serialisiert (es war tatsächlich wahnsinnig interessant). Wurde immer am Ende des Magazins veröffentlicht. Ich war besorgt darüber, ob ich dies als Ausreißer ausschließen sollte, aber am Ende entschied ich mich, es zu verlassen.
def save_data(magazines, offset=0, file_name='data/wj-api.json'):
"""
Für alle in Magazinen enthaltenen Magazine von Anfang bis zum Volumen nach dem Offset
Informationen zum Inhaltsverzeichnis und zur Datei abrufen_Es ist eine Funktion zum Speichern im Namen.
"""
url = 'https://mediaarts-db.bunka.go.jp/mg/api/v1/magazine?id='
#Erste Zeile der Datei
if offset == 0:
with open(file_name, 'w') as f:
f.write('[\n')
with open(file_name, 'a') as f:
#Klicken Sie auf die Web-API für jedes Magazin in Magazinen.
for m, magazine in enumerate(magazines[offset:]):
response = urllib.request.urlopen(url + str(magazine['id']),
timeout=30)
content = json.loads(response.read().decode('utf8'))
#Der obige Funktionsextrakt_data()Extrahieren Sie dann die erforderlichen Informationen.
comics = extract_data(content)
print('{0:4d}/{1}: Extracted data from {2}'.\
format(m + offset, len(magazines), url + str(magazine['id'])))
#Datei für jeden Comic in Comics_Speichern Sie die Informationen im Namen.
for n, comic in enumerate(comics):
#Für den ersten Comic des Magazins außer dem Anfang der Datei,
#Zuerst',\n'Hinzugefügt.
if m + offset > 0 and n == 0:
f.write(',\n')
json.dump(comic, f, ensure_ascii=False)
#Bis auf den letzten Comic',\n'Hinzugefügt.
if not n == len(comics) - 1:
f.write(',\n')
print('{0:9}: Saved data to {1}'.format(' ', file_name))
#Stellen Sie sicher, dass Sie eine Pause einlegen, um die Belastung des Servers zu verringern.
sleep(3)
#Letzte Zeile der Datei
with open(file_name, 'a') as f:
f.write(']')
Um Zeitüberschreitungen flexibel zu behandeln, werden die Inhaltsverzeichnisinformationen nicht in einem Stapel verarbeitet, sondern nacheinander zwangsweise verarbeitet. Beachten Sie außerdem, dass es mit "sleep ()" angehalten wird, um den Server nicht zu belasten.
Wieder die Anforderungs-URL (https://mediaarts-db.jp/mg/api/v1", beschrieben in [Web-API-Spezifikationen](https://mediaarts-db.bunka.go.jp/webapi_proto_documents.pdf) Bitte beachten Sie, dass Sie anstelle von / magazine die neue URL (https: // mediaarts-db.bunka.go.jp / mg / api / v1 / magazine`) verwenden müssen.
Lauf
Verwenden Sie die obige Funktion, um die Indexinformationen von der Web-API abzurufen und in data / wj-api.json zu speichern.
magazines = search_magazine()
save_data(magazines)
# 0/2320: Extracted data from https://mediaarts-db.bunka.go.jp/mg/api/v1/magazine?id=323270
# : Saved data to data/wj-api.json
# 1/2320: Extracted data from https://mediaarts-db.bunka.go.jp/mg/api/v1/magazine?id=323269
# : Saved data to data/wj-api.json
# ...
# 447/2320: Extracted data from https://mediaarts-db.bunka.go.jp/mg/api/v1/magazine?id=322833
# : Saved data to data/wj-api.json
#---------------------------------------------------------------------------
#gaierror Traceback (most recent call last)
#/home/anaconda3/envs/comic/lib/python3.5/urllib/request.py in do_open(self, http_class, req, **http_conn_args)
# 1253 try:
#-> 1254 h.request(req.get_method(), req.selector, req.data, headers)
# 1255 except OSError as err: # timeout error
Wenn das Zeitlimit überschritten wird, verwenden Sie "Offset", um es neu zu starten. Wenn das Timeout beispielsweise bei "447/2320" auftritt, führen Sie "save_data (offset = 448)" aus.
save_data(magazines, offset=448)
# 448/2320: Extracted data from https://mediaarts-db.bunka.go.jp/mg/api/v1/magazine?id=322832
# : Saved data to data/wj-api.json
# 449/2320: Extracted data from https://mediaarts-db.bunka.go.jp/mg/api/v1/magazine?id=322831
# : Saved data to data/wj-api.json
#...
3.3 (Referenz) Schaben
Aufgrund meiner mangelnden Recherche habe ich Geschirrdaten durch Web-Scraping erhalten, bis ich im Kommentarbereich darauf hingewiesen habe. Zu Ihrer Information werden die Einstellungen zu diesem Zeitpunkt beschrieben. Verwenden Sie jedoch so oft wie möglich die Web-API in Kapitel 3.2.
Dieses Mal verwenden wir Scrapy, ein typisches Framework. Weitere Informationen zu Scrapy finden Sie im Referenzabschnitt am Ende dieses Artikels. Erstellen Sie zunächst das Projekt "comic" für diesen Artikel mit dem folgenden Befehl.
scrapy startproject comic
Das folgende Verzeichnis sollte erstellt werden (Official Tutorial).
comic/
scrapy.cfg # deploy configuration file
comic/ # project's Python module, you'll import your code from here
__init__.py
items.py # project items definition file
pipelines.py # project pipelines file
settings.py # project settings file
spiders/ # a directory where you'll later put your spiders
__init__.py
Platziere die folgende comic_spider.py in comic / spiders.
comic_spider.py
# -*- coding: utf-8 -*-
import scrapy
class WjSpider(scrapy.Spider):
"""
start_Es ist eine Spinne, die rekursiv das folgende Inhaltsverzeichnis aus URLs extrahiert.
Fang hier an_urls ist in der Datenbank für Medienkunst der Agentur für kulturelle Angelegenheiten registriert
Dies ist die älteste Information auf der wöchentlichen Shonen Jump-Tabelle (Ausgabe vom 3. November 1969).
- year:Ausstellungsjahr
- no:Anzahl der Probleme
- title:Titel der Arbeit
- author:Autor
- color:Ob es Farbe ist oder nicht
- pages:Anzahl der geposteten Seiten
- start_page:Startseite der Arbeit
- best:Publikationsauftrag von Anfang an gezählt
- worst:Die Buchungsreihenfolge wird ab dem Ende des Buches gezählt
"""
name = 'wj'
start_urls = [
'http://mediaarts-db.bunka.go.jp/mg/magazines/323270'
]
n_page = 0
def parse(self, response):
"""Dies ist der Hauptkörper der Spinne."""
year = int(response.css('section.block tr td::text').extract()[3][:4])
try:
no = int(response.css('section.block tr td::text').extract()[8])
except ValueError:
no = response.css('section.block tr td::text').extract()[8]
#Es werden nur Manga-Werke extrahiert.
comics = [comic for comic in response.css('table.infoTbl2 tr')
if len(comic.css('td::text')) > 0
and comic.css('td::text')[0].extract() == 'Manga Arbeit']
data = []
for comic in comics:
title = comic.css('a::text').extract_first()
if not title:
continue
#Eine Ausnahmebehandlung ist erforderlich, da bei einigen Werken nicht die Anzahl der aufgelisteten Seiten angegeben ist.
#Es gibt keinen besonderen Grund, aber nicht gelistete Werke werden als 10 Seiten verarbeitet.
try:
pages = float(comic.css('td::text')[6].extract())
except ValueError:
pages = 10
#Zur Unterstützung von Werken, die in mehreren Folgen pro Woche veröffentlicht werden, wie "Inumaru Dashi"
#Wenn der Titel bereits in den Daten enthalten ist, registrieren Sie ihn nicht als neues Datum.
#Es wird nur die Anzahl der vorhandenen Bezugsseiten hinzugefügt.
if len(data) > 0 and title in [datum['title'] for datum in data]:
data[[datum['title'] for datum in
data].index(title)]['pages'] += pages
else:
data.append({
'year': year,
'no': no,
'title': comic.css('a::text').extract_first(),
'author': comic.css('td::text')[3].extract(),
'subtitle': comic.css('td::text')[4].extract(),
'color': comic.css('td::text')[7].extract().count('Farbe'),
'pages': pages,
'start_page': float(comic.css('td::text')[5].extract())})
#Um den Mini-Manga des Projekts auszuschließen, werden Daten mit insgesamt 5 Seiten oder weniger von der Liste ausgeschlossen.
filtered_data = [datum for datum in data if datum['pages'] > 5]
for n, datum in enumerate(filtered_data):
datum['best'] = n + 1
datum['worst'] = len(filtered_data) - n
yield datum
#Holen Sie sich die Informationen der nächsten Ausgabe rekursiv.
next_page = response.css('li.nxt a::attr(href)').extract_first()
if next_page is not None:
next_page = response.urljoin(next_page)
yield scrapy.Request(next_page, callback=self.parse)
** Stellen Sie sicher, dass DOWNLOAD_DELAY in ** settings.py festgelegt ist, um den Server nicht zu überlasten (standardmäßig auskommentiert). Außerdem möchte ich Daten auf Japanisch ausspucken, also setze FEED_EXPORT_ENCODING auf utf-8.
settings.py
### -----Abkürzung-----
DOWNLOAD_DELAY = 3
FEED_EXPORT_ENCODING = 'utf-8'
### -----Abkürzung-----
Führen Sie die folgenden Schritte aus, um die Daten abzurufen.
scrapy crawl wj -o wj.json
4. Datenanalyse
Eigentlich kann man mit nur wj-api.json [^ separater Artikel] viel spielen. Das Notizbuch ist hier, also hoffe ich, dass Sie es verwenden können. Im Folgenden gehen wir davon aus, dass wj-api.json im Verzeichnis data existiert.
[^ Separater Artikel]: Ich habe es mehr genossen, als ich erwartet hatte, also habe ich es in zwei Teile geteilt.
4.1 Vorbereitung
Ich möchte den Titel jeder Arbeit auf Japanisch anzeigen, also verweise auf Japanisch mit Matplotlib unter Ubuntu zeichnen. Wenn Sie ein anderes als Ubuntu verwenden, ergreifen Sie bitte die entsprechenden Maßnahmen.
import json
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
sns.set(style='ticks')
import matplotlib
from matplotlib.font_manager import FontProperties
font_path = '/usr/share/fonts/truetype/takao-gothic/TakaoPGothic.ttf'
font_prop = FontProperties(fname=font_path)
matplotlib.rcParams['font.family'] = font_prop.get_name()
4.2 ComicAnalyzer
Definieren Sie für die Analyse "wj-api.json" die folgende Klasse "ComicAnalyzer".
ComicAnalyzer
class ComicAnalyzer():
"""Diese Klasse liest und verwaltet die Kataloginformationen von Manga-Magazinen."""
def __init__(self, data_path='data/wj-api.json', min_week=7, short_week=10):
"""
Bei der Initialisierung Daten_Auf dem Weg.Extrahieren Sie die Inhaltsverzeichnisinformationen aus der JSON-Datei.
- self.data:Listentyp, der alle Tabelleninformationen enthält
- self.all_titles:Listentyp, der alle Informationen zum Arbeitsnamen enthält
- self.serialized_titles: min_Listentyp, der alle Titel von Werken enthält, die über die Woche serialisiert wurden
- self.last_year:Numerischer Typ, der das Jahr der neuesten Inhaltsverzeichnisinformationen enthält
- self.last_no:Numerischer Typ, der die Nummer der neuesten Inhaltsverzeichnisinformationen enthält
- self.end_titles: self.serialized_Von den Titeln selbst.last_Jahr und
self.last_Listentyp, der alle Titel von Werken enthält, die von Nr
- self.short_end_titles: self.end_Von den Titeln kurz_innerhalb einer Woche
Listentyp, der die Titel von Werken enthält, die serialisiert wurden
- self.long_end_titles: self.end_Von den Titeln kurz_week+Seit mehr als einer Woche
Listentyp, der die Titel von Werken enthält, die serialisiert wurden
"""
self.data = self.read_data(data_path)
self.all_titles = self.collect_all_titles()
self.serialized_titles = self.drop_short_titles(self.all_titles, min_week)
self.last_year = self.find_last_year(self.serialized_titles[-100:])
self.last_no = self.find_last_no(self.serialized_titles[-100:], self.last_year)
self.end_titles = self.drop_continued_titles(
self.serialized_titles, self.last_year, self.last_no)
self.short_end_titles = self.drop_long_titles(
self.end_titles, short_week)
self.long_end_titles = self.drop_short_titles(
self.end_titles, short_week + 1)
def read_data(self, data_path):
""" data_Liest die JSON-Datei im Pfad und gibt eine Liste aller Informationen zum Inhaltsverzeichnis zurück."""
with open(data_path, 'r', encoding='utf-8') as f:
data = json.load(f)
return data
def collect_all_titles(self):
""" self.Gibt eine Liste aller aus Daten extrahierten Arbeitstitel zurück."""
titles = []
for comic in self.data:
if comic['title'] not in titles:
titles.append(comic['title'])
return titles
def extract_item(self, title='ONE PIECE', item='worst'):
""" self.Gibt eine Liste aller aus Daten extrahierten Titelelemente zurück."""
return [comic[item] for comic in self.data if comic['title'] == title]
def drop_short_titles(self, titles, min_week):
"""Von den Titeln min_Woche Gibt eine Liste von Titeln zurück, die länger als eine Woche serialisiert wurden."""
return [title for title in titles
if len(self.extract_item(title)) >= min_week]
def drop_long_titles(self, titles, max_week):
"""Von den Titeln sind max_Woche Gibt eine Liste der Titel zurück, die innerhalb einer Woche abgeschlossen wurden."""
return [title for title in titles
if len(self.extract_item(title)) <= max_week]
def find_last_year(self, titles):
"""Gibt das letzte Jahr der Magazine zurück, in denen Titel veröffentlicht werden."""
return max([self.extract_item(title, 'year')[-1]
for title in titles])
def find_last_no(self, titles, year):
"""Gibt die neueste Ausgabe des Jahresmagazins zurück, in dem Titel veröffentlicht wurden."""
return max([self.extract_item(title, 'no')[-1]
for title in titles
if self.extract_item(title, 'year')[-1] == year])
def drop_continued_titles(self, titles, year, no):
"""Gibt unter den Titeln eine Liste der Titel zurück, die bis zur Ausgabe des Jahres serialisiert wurden."""
end_titles = []
for title in titles:
last_year = self.extract_item(title, 'year')[-1]
if last_year < year:
end_titles.append(title)
elif last_year == year:
if self.extract_item(title, 'no')[-1] < no:
end_titles.append(title)
return end_titles
def search_title(self, key, titles):
"""Gibt eine Liste mit Titeln einschließlich der Eingabe von Titeln zurück."""
return [title for title in titles if key in title]
Da es sich um einen Prozess handelt, der schwer zu verstehen ist, ergänzt er die Operation zum Zeitpunkt der Initialisierung (__init __ ()).
self.all_titlesenthält buchstäblich alle Titel.Self.all_titlesenthält jedoch eindeutig vorgelesene und geplante Arbeiten.- Daher werden die über "min_week" serialisierten Werke als "self.serialized_titles" extrahiert.
Self.serialized_titlesenthält jedoch Werke, die zum Zeitpunkt der neuesten Kataloginformationen serialisiert werden, und die Serialisierungsdauer ist ungenau. Beispiel: "Devil's Blade" Ist ein beliebtes Werk, das noch serialisiert wird, aber die Serialisierung endete in 21 Wochen. Es sieht aus wie eine Arbeit. - Daher werden nur die Werke, deren Serialisierung (wahrscheinlich) zum Zeitpunkt der letzten Indexinformationen in der Datenbank abgeschlossen wurde, als "self.end_titles" extrahiert.
self.end_titlesist die ganze Menge in dieser Analyse. - Von den "self.end_titles" werden die innerhalb von 10 Wochen abgeschlossenen Arbeiten als "self.short_end_titles" extrahiert, und die Arbeiten, die 11 Wochen oder länger fortgesetzt wurden, werden als "self.long_end_titles" extrahiert.
4.3 Analyse
Spielen wir jetzt mit "ComicAnalyzer".
wj = ComicAnalyzer()
Lassen Sie uns zunächst die Reihenfolge der Veröffentlichung (am schlechtesten) der letzten 10 kurzlebigen Werke bis zu den ersten 10 Wochen aufzeichnen. Je größer der Wert, desto mehr wurde er am Anfang des Buches veröffentlicht.
for title in wj.short_end_titles[-10:]:
plt.plot(wj.extract_item(title)[:50], label=title[:6])
plt.xlabel('Week')
plt.ylabel('Worst')
plt.ylim(0,22)
plt.legend()

Es enthält Projekte (Geschäftsreise Arbeit [^ Gag Manga Wetter]) wie "Gag Manga Wetter" Ich bin unzufrieden, aber es gibt keine Möglichkeit, es allein von den Geschirrinformationen auszuschließen. Das? "Saiki Kusuo" wurde mehr als 10 Wochen lang serialisiert ...? Verwenden Sie in diesem Fall search_title ().
[^ Gag Manga Weather]: Sollte in Jump Square serialisiert werden (wikipedia B0% E3% 83% 9E% E3% 83% B3% E3% 82% AC% E6% 97% A5% E5% 92% 8C)). Bis zum 18. April 2017 wurden die Indexinformationen von Jump Square noch nicht in der Datenbank registriert.
wj.search_title('Saiki', wj.all_titles)
# ['Super-Power-Person Kusuo Saikis Ψ Schwierigkeit', 'Saiki Kusuos Ψ Schwierigkeit']
len(wj.extract_item('Super-Power-Person Kusuo Saikis Ψ Schwierigkeit'))
# 7
wj.extract_item('Super-Power-Person Kusuo Saikis Ψ Schwierigkeit', 'year'), \
wj.extract_item('Super-Power-Person Kusuo Saikis Ψ Schwierigkeit', 'no')
# ([2011, 2011, 2011, 2011, 2011, 2011, 2011], [22, 27, 29, 33, 42, 43, 50])
len(wj.extract_item('Saiki Kusuos Ψ Schwierigkeit'))
# 201
Anscheinend in "Super Powered Person Saiki Kusuos Ψ Schwierigkeitsgrad" Nachdem Sie 7 Mal probeweise gelesen und gepostet haben, "[Saiki Kusuos Ψ Schwierigkeit](https://mediaarts-db.bunka.go.jp/mg/magazine_works/1071?ids%5B%5D=1071&ids%5B%5D] Es scheint, dass die Serialisierung von "= 1566)" begonnen hat (wikipedia 9B% 84% E3% 81% AE% CE% A8% E9% 9B% A3)). Als nächstes zeigen wir die Reihenfolge der Veröffentlichung der ersten 10 Folgen der letzten Hits (willkürlich).
target_titles = ['ONE PIECE', 'NARUTO-Naruto-', 'BLEACH', 'HUNTER×HUNTER']
for title in target_titles:
plt.plot(wj.extract_item(title)[:10], label=title[:6])
plt.xlabel('Week')
plt.ylabel('Worst')
plt.ylim(0,22)
plt.legend()

Obwohl es nicht direkt mit diesem Artikel zusammenhängt, war ich persönlich daran interessiert, daher werde ich mir die Reihenfolge der Veröffentlichung von bis zu 50 Folgen ansehen.
target_titles = ['ONE PIECE', 'NARUTO-Naruto-', 'BLEACH', 'HUNTER×HUNTER']
for title in target_titles:
plt.plot(wj.extract_item(title)[:100], label=title[:6])
plt.xlabel('Week')
plt.ylabel('Worst')
plt.ylim(0,22)
plt.legend()
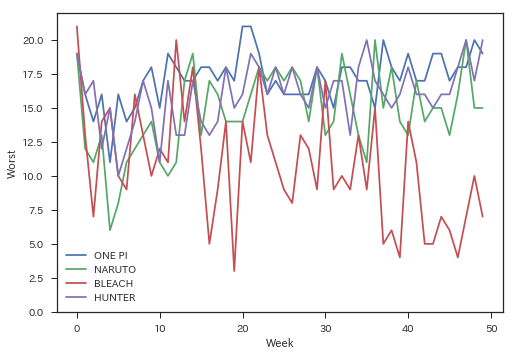
Ich habe es bis zu einem gewissen Grad erwartet, aber es ist immer noch erstaunlich. Übrigens, wenn Sie sich die Reihenfolge der Veröffentlichung ansehen, während Sie den Titel jeder Geschichte mit "extract_item ()" erhalten, können Manga-Liebhaber grinsen.
wj.extract_item('ONE PIECE', 'subtitle')[:10]
#['1.ROMANCE DAWN-Dawn of Adventure-',
# 'Episode 2!!der Mann"Strohhut Ruffy"',
# 'Folge 3"Zoro der Piratenjagd"Aussehen',
# 'Episode 4 Navy Captain"Axe Morgan"',
# 'Folge 5"Piratenkönig und großer Schwertkämpfer"',
# 'Folge 6"1. Person"',
# 'Folge 7"Freund"',
# 'Folge 8"Nami erschien"',
# 'Folge 9"Teuflische Frau"',
# 'Folge 10"Ein Fall von einer Bar"']
Ich habe zu viel Umweg gemacht. Lassen Sie uns eine Korrelationsanalyse mit pairplot () of seaborn durchführen. Hier werde ich vorerst den Buchungsauftrag von der 2. bis zur 6. Woche zeichnen. Ich habe die erste Woche verpasst, weil die meisten Werke zu Beginn der ersten Woche veröffentlicht werden. Da sich mehrere Punkte an denselben Koordinaten überlappen und sehr schwer zu erkennen sind, wird zur Vereinfachung des Erscheinungsbilds zufälliges Rauschen hinzugefügt.
end_data = pd.DataFrame(
[[wj.extract_item(title)[1] + np.random.randn() * .3,
wj.extract_item(title)[2] + np.random.randn() * .3,
wj.extract_item(title)[3] + np.random.randn() * .3,
wj.extract_item(title)[4] + np.random.randn() * .3,
wj.extract_item(title)[5] + np.random.randn() * .3,
'Kurzlebige Arbeit' if title in wj.short_end_titles else 'Fortsetzung der Arbeit']
for title in wj.end_titles])
end_data.columns = ["Worst (week2)", "Worst (week3)", "Worst (week4)",
"Worst (week5)", "Worst (week6)", "Type"]
sns.pairplot(end_data, hue="Type", palette="husl")
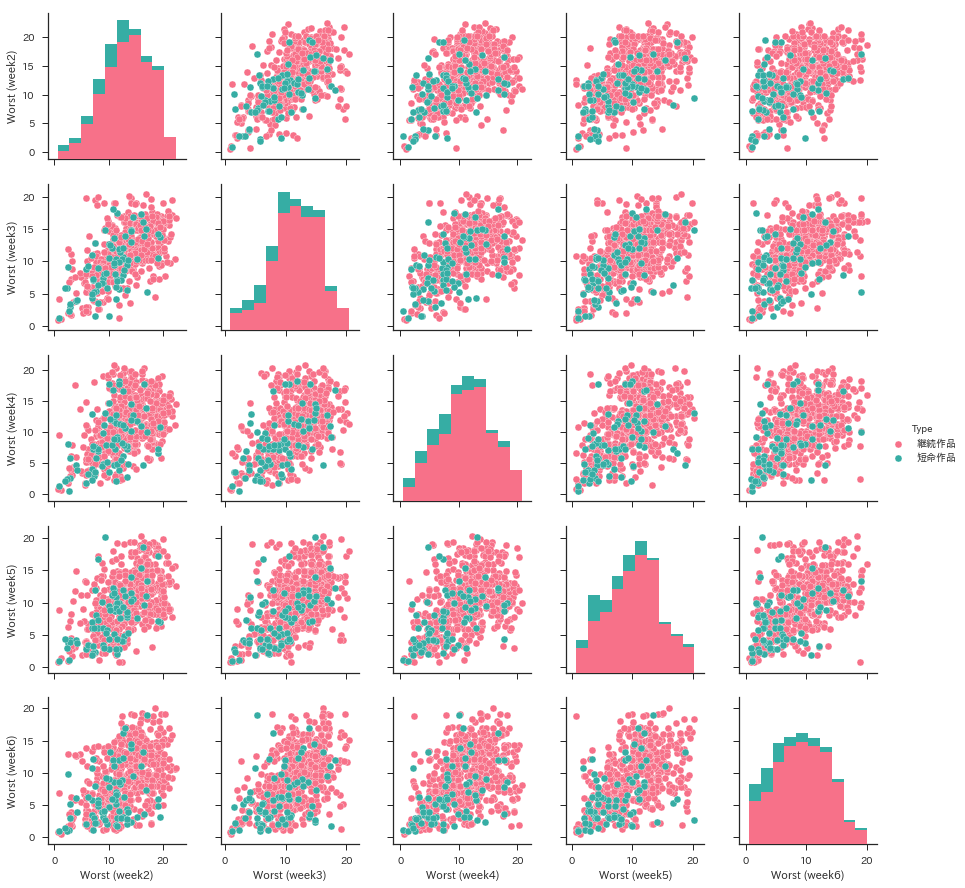
Pink ist eine Arbeit, die länger als 11 Wochen dauerte, und Green ist eine kurzlebige Arbeit, die innerhalb von 10 Wochen endete. Ich dachte, es wäre mehr geteilt, aber es scheint schwierig zu sein, es zu trennen. Wahrscheinlich habe ich das Gefühl, dass Projekte wie "Gag Manga Hiyori" und experimentelle Lesearbeiten wie "Super Powerful Kusuo Saikis Ψ Schwierigkeitsgrad" laut sind. Es ist in Ordnung, sich durch die Kontinuität der Themen zu unterscheiden, aber das macht es nicht von den suspendierten Werken zu unterscheiden ... Es ist nervig. Vorerst werde ich versuchen, mit diesen Daten so wie sie sind maschinell zu lernen.
5. Schlussfolgerung
Als ich merkte, dass ich der Realität entkommen war, machte ich so etwas. Das nächste Mal wird die eigentliche Produktion sein, also hoffe ich, dass es Ihnen gefällt. Danke, dass du bis zum Ende für mich gelesen hast!
Verweise
Bei der Erstellung dieses Artikels habe ich auf Folgendes verwiesen. Vielen Dank! : Bogen:
- Bakuman. : Dies ist ein Cartoonist-Cartoon, der in Weekly Shonen Jump serialisiert wurde. Es war interessant, eine ziemlich rohe Geschichte wie die Manuskriptgebühr zu hören.
- Bis zum Zugriff auf die Web-API, die mit Python 3 json zurückgibt, und zur Ausgabe des Ergebnisses: Lassen Sie mich auf die Verwendung der Web-API mit Python3 verweisen. Wir bekamen.
- Einführung in Scrapy (1): Es war ordentlich und organisiert und sehr hilfreich.
- Scrapy Tutorial: Nachdem ich meine Hände bewegt hatte, verstand ich irgendwie, wie man es benutzt.
- Japanisch mit matplotlib unter Ubuntu zeichnen: Ich habe dies als Referenz verwendet, wenn ich den Titel der Arbeit auf Japanisch angezeigt habe.
Recommended Posts