[PYTHON] Kalibrieren Sie das Modell mit PyCaret
Einführung
- Bei der Klassifizierung nach Binär ist es gut, den Schwellenwert zu bestimmen und Pos / Neg zu klassifizieren.
- Kann ich den Ausgabewert des Modells als die Wahrscheinlichkeit betrachten, positiv zu werden? Ist eine andere Sache.
- Wenn Sie die oben genannten Schritte ausführen möchten, müssen Sie je nach Modell möglicherweise eine Kalibrierung durchführen.
- Ich möchte diese Kalibrierung mit PyCaret durchführen.
Mach ein Modell
- Befolgen Sie das Tutorial von PyCaret, um wie gewohnt mit einem Entscheidungsbaum zu modellieren.
- Verwenden Sie den Diabetes-Datensatz als Datensatz.
Lade Daten
from pycaret.datasets import get_data
diabetes = get_data('diabetes')

Modellierung mit einem Entscheidungsbaum
- Ich möchte klassifizieren, also importiere pycaret.classification.
- Und Sie können modellieren, indem Sie dt (Entscheidungsbaum) in create_model angeben.
- Beobachten Sie das erstellte Modell mit evalutate_model.
#Klassifizierungspaket importieren
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
#Machen Sie einen Entscheidungsbaum
dt = create_model(estimator='dt')
#Visualisierung
evaluate_model(dt)
Überprüfen Sie vor der Kalibrierung die Kalibrierungskurve
- Klicken Sie auf die Schaltfläche unten, um die Kalibrierungskurve zu überprüfen.
- Die horizontale Achse hat das Bewertungsergebnis des Modells zusammengefasst und in der Reihenfolge des Werts angeordnet.
- Die vertikale Achse ist der Prozentsatz der positiven Daten, die bis zu diesem Bin angezeigt wurden.
- In einer idealen Situation (*)
- Positive Daten erscheinen in Bezug auf den Ausgabewert des Modells ausgewogen.
- Das Modell (blaue Linie) nähert sich der diagonalen Ideallinie (gestrichelte Linie)
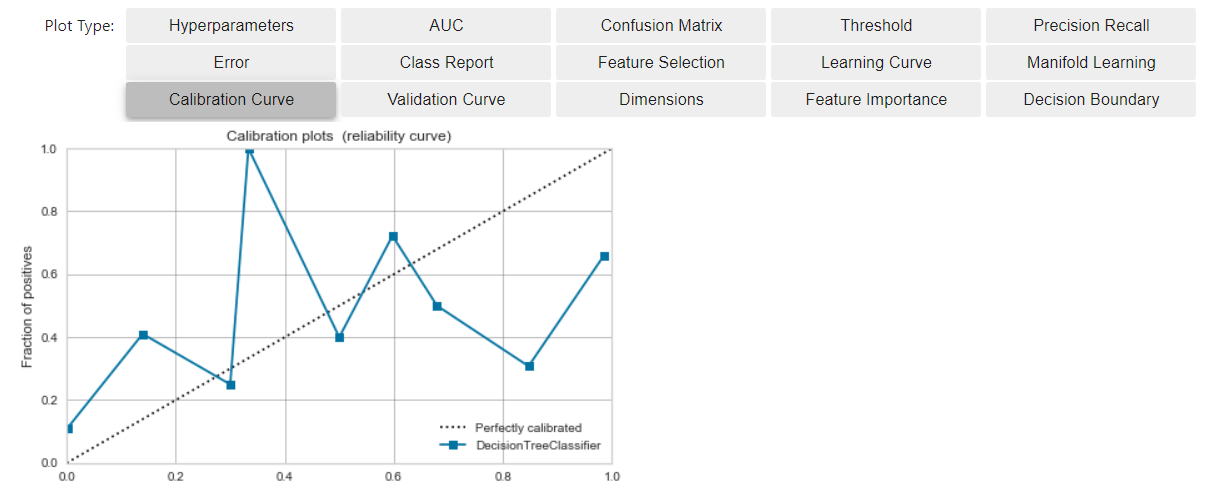
Kalibrieren Sie das Modell
- Die Kalibrierung ist die Arbeit, um das aktuelle Modell der oben beschriebenen Situation näher zu bringen (*). Durch Annäherung an die Situation von * * wird es einfacher, den Modellausgabewert als die Wahrscheinlichkeit zu betrachten, dass das Vorhersageergebnis positiv ist.
- Einfach zu implementieren, verwenden Sie kalibriertes_Modell.
#kalibrieren
calibrated_dt = calibrate_model(dt)
#Visualisieren
evaluate_model(calibrated_dt)
- Im Vergleich zur vorherigen Zeit liegt das Modell (blaue Linie) näher an der Ideallinie (gestrichelte Linie).
- Für das Bewertungsergebnis des Modells
- Wir konnten zu diesem Zeitpunkt einen linearen Anstieg der kumulativen Erscheinungsrate von Positiv erzielen (eine Situation nahe *).
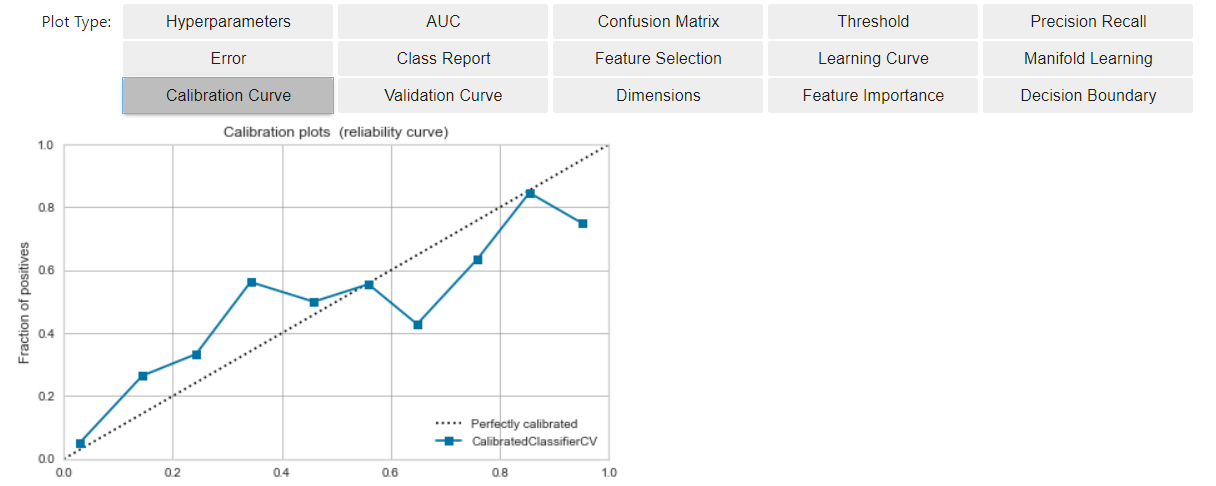
Was ist die Kalibrierung durchgeführt?

- Sie verwenden anscheinend sklearn.calibration.CalibratedClassifierCV.
- sklearn unterstützt sigmoid'und'isotonic 'als Kalibrierungsmethoden, aber Pycaret hat ein ähnliches Dokument.
Welches Modell muss kalibriert werden? "Ja?"
-
Da SVM den Spielraum maximiert, ist der Modellausgabewert auf 0,5 konzentriert und eine Kalibrierung erforderlich, da der Bereich um die Entscheidungsgrenze streng überprüft wird. Der Punkt ist [dieser Artikel](https://yukoishizaki.hatenablog.com/entry/2020/05/24/145155#:~:text=SVM%E3%81%AF%E3%83%9E%E3% 83% BC% E3% 82% B8% E3% 83% B3% E3% 82% 92% E6% 9C% 80% E5% A4% A7% E5% 8C% 96) Ist es?
-
Überlassen Sie die genaue Diskussion darüber, welches Modell kalibriert werden muss, den Experten. In diesem Artikel möchte ich vor und nach der Kalibrierung eine Kalibrierungskurve schreiben und die Trends beobachten.
-
Logistische Regression
-
Ursprünglich kann es als positive Wahrscheinlichkeit interpretiert werden, sodass es bereits vor der Kalibrierung ausgewogen ist.
-
Nach der Kalibrierung ändert sich nicht viel.
-
RBF-Kernel-SVM
-
Es ist heftig. Wie im obigen Artikel erwähnt, scheinen die Daten durch Maximierung der Marge nahe bei 0,5 zu liegen.
-
Die Kalibrierung verbessert sich nicht wesentlich und es scheint gefährlich, den Modellausgabewert als Wahrscheinlichkeit zu behandeln.
-
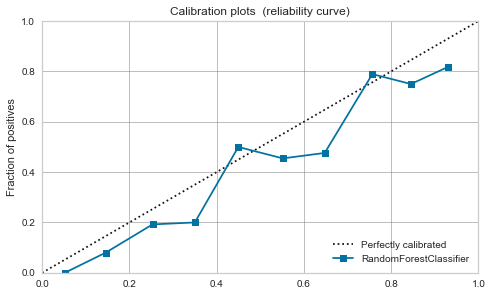
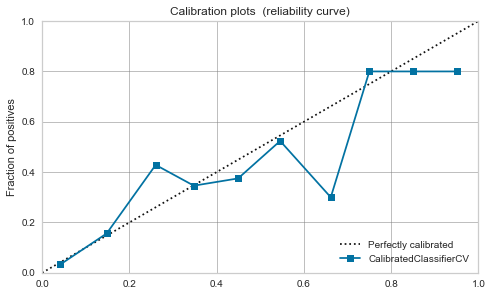
Zufälliger Wald
-
Die Balance scheint bereits vor der Kalibrierung bis zu einem gewissen Grad gut zu sein.
-
Dieses Mal ist aufgrund der Kalibrierung ein Peak um 0,7 aufgetreten.
-
XGBoost,LightGBM
-
Mäßig schon vor der Kalibrierung. Wenn Sie es kalibrieren, wird es sich ein wenig beruhigen.
| Algorithmus | Vor der Kalibrierung | Nach der Kalibrierung |
|---|---|---|
| Logistic Regression |
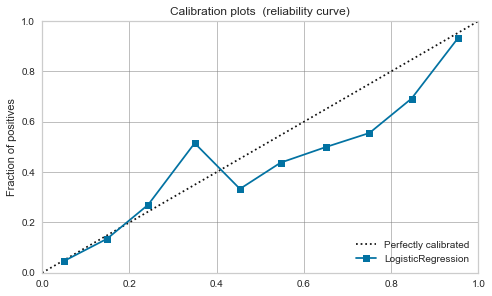 |
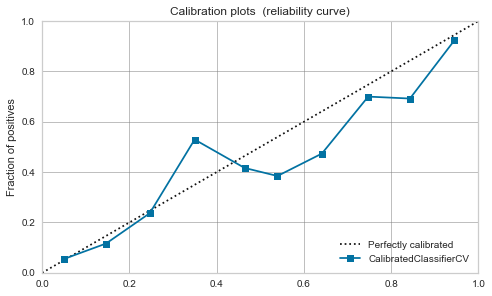 |
| RBF SVM | 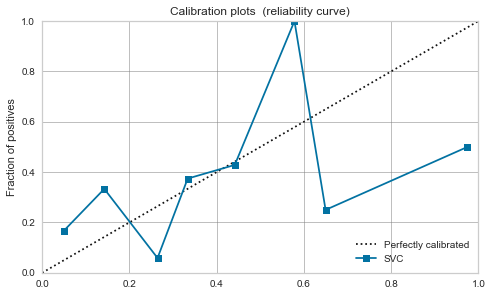 |
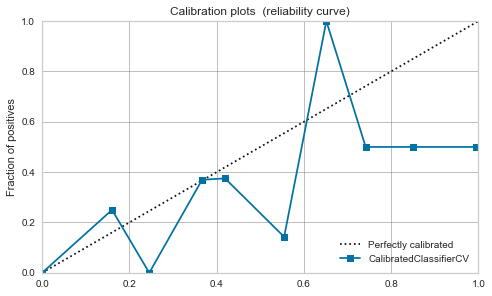 |
| Random Forest |
 |
 |
| XGBoost | 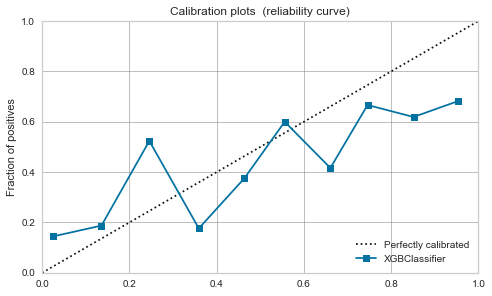 |
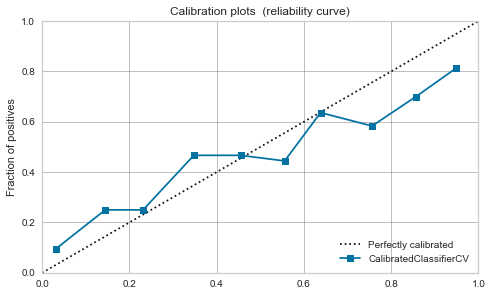 |
| LightGBM | 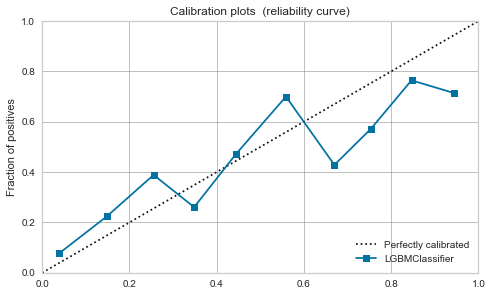 |
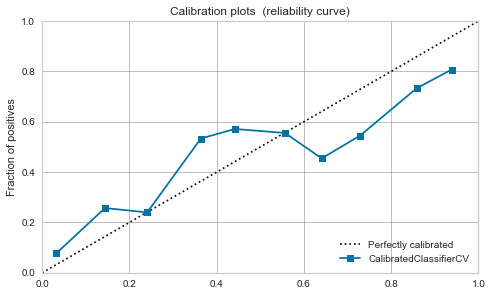 |
Schließlich
- Ich habe versucht, das Modell mit PyCaret zu kalibrieren.
- Wenn Sie den Modellausgabewert als positive Wahrscheinlichkeit betrachten möchten, müssen Sie die Kalibrierungskurve überprüfen.
- Selbst wenn kalibriert, können die inhärenten Eigenschaften des Algorithmus, wie die Maximierung der SVM-Marge, schwerwiegend sein.
- Einige Modelle, wie z. B. die logistische Regression, können ohne Kalibrierung leicht als Wahrscheinlichkeiten angesehen werden. Ich denke, es gibt einen Ansatz, um sie je nach Anwendung richtig zu verwenden.