[PYTHON] Dekodierung von Keras 'LSTM model.predict
Überblick
Ich habe Keras und Tensorflow verwendet, um die Gewichte meines neuronalen Netzwerks zu berechnen, aber es ist überraschend schwierig zu wissen, wie man es in realen Anwendungen (iPhone-Apps, Android-Apps, Javascript usw.) verwendet.
Wenn es sich um ein einfaches neuronales Netzwerk handelt, ist es einfach, aber da diesmal die in LSTM erlernten Gewichte verwendet werden mussten, habe ich den Inhalt von Predict of LSTM of Keras entschlüsselt.
Die gelernten Gewichte können mit model.get_weights () abgerufen werden, aber es werden keine Informationen zu diesem herausgebracht, selbst wenn ich es google.
Schließlich sind die von model.get_weights () abgerufenen Gewichte, wenn der Code geschrieben und zufällig ausprobiert wird
Erstens (Index 0): LSTM-Eingangsschichtgewichte für Eingänge, Eingangsgattergewichte, Ausgangsgattergewichte, Vergessengattergewichte
Zweitens (Index 1): Eingabegewicht der verborgenen Schicht, Eingangsgattergewicht, Ausgangsgattergewicht, Vergessengattergewicht
Drittens (Index 2): Vorspannung für Eingabeebene und versteckte Ebene
Viertens (Index 3): Gewicht für die Ausgabe der Ausgabeebene (Gewicht für die Ausgabe der verborgenen Ebene)
Fünftens (Index 4): Vorspannung zur Ausgabeschicht (Vorspannung zur Ausgabe der verborgenen Schicht)
Ich fand heraus.
Um dies herauszufinden, habe ich den Code geschrieben, der sich am Ende wie model.predict () verhält.
Ich hoffe, die offizielle Seite von Keras hat so etwas. .. .. ..
Ausgabe von get_weigts ()
Wenn weight = model.get_weights (), werden die folgenden Gewichte gespeichert.
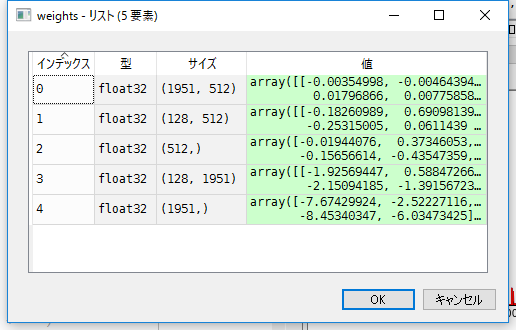
Die Zahl 1951 ist die Anzahl der Knoten in der Eingabeebene, daher gibt es kein Problem. In Index 3 128 ist auch die Anzahl der Knoten für verborgene Ebenen auf 128 festgelegt, sodass dies als Gewichtung für die Ausgabe der verborgenen Ebene angesehen werden kann. Das Problem war 512, was am verwirrendsten war.
Ich hatte plötzlich die Erwartung, dass vier Arten von "Gewichten für Eingaben, Gewichten für Eingabetoren, Gewichten für Ausgangstoren und Gewichten für Vergessenstore" gespeichert werden. Auf der offiziellen Seite von Keras gibt es jedoch eine Aussage, die LSTM verwendet (Langzeit- und Kurzzeitspeicher - Hochreiter 1997.). Apropos 1997, das Vergessenstor wurde nicht gewichtet. .. .. ?? Es scheint, dass das Vergessenstor 1999 geschaffen wurde. .. .. .. Das steht auch hier ...? http://kivantium.hateblo.jp/entry/2016/01/31/222050
Obwohl mich das verwirrte, dachte ich, wenn ich den Code in Solid schreibe, werden diese geklärt, also entschied ich mich, diesen Code zu schreiben, der sich genauso verhält wie model.predict.
Code zum Enträtseln von model.predict ()
Als Voraussetzung ist das Modell von LSTM, das zum Decodieren dieser Zeit verwendet wird, wie folgt. Beispielcode zum Generieren von Sätzen mit LSTM.
from __future__ import print_function
from keras.models import Sequential
from keras.layers import Dense, Activation
from keras.layers import LSTM
from keras.optimizers import RMSprop
from keras.utils.data_utils import get_file
import numpy as np
import random
import sys
from keras.models import model_from_json
import copy
import matplotlib.pyplot as plt
import math
#path = get_file('nietzsche.txt', origin='https://s3.amazonaws.com/text-datasets/nietzsche.txt')
text = open('hokkaido_x.txt', 'r', encoding='utf8').read().lower()
print('corpus length:', len(text))
chars = sorted(list(set(text)))
print('total chars:', len(chars))
char_indices = dict((c, i) for i, c in enumerate(chars))
indices_char = dict((i, c) for i, c in enumerate(chars))
# cut the text in semi-redundant sequences of maxlen characters
#maxlen = 40
maxlen = 3
step = 2
sentences = []
next_chars = []
for i in range(0, len(text) - maxlen, step):
sentences.append(text[i: i + maxlen])
next_chars.append(text[i + maxlen])
print('nb sequences:', len(sentences))
print('Vectorization...')
X = np.zeros((len(sentences), maxlen, len(chars)), dtype=np.bool)
y = np.zeros((len(sentences), len(chars)), dtype=np.bool)
for i, sentence in enumerate(sentences):
for t, char in enumerate(sentence):
X[i, t, char_indices[char]] = 1
y[i, char_indices[next_chars[i]]] = 1
# build the model: a single LSTM
print('Build model...')
model = Sequential()
model.add(LSTM(128, input_shape=(maxlen, len(chars)),activation='sigmoid',inner_activation='sigmoid'))
model.add(Dense(len(chars)))
model.add(Activation('softmax'))
optimizer = RMSprop(lr=0.01)
model.compile(loss='categorical_crossentropy', optimizer=optimizer)
def sample(preds, temperature=1.0):
# helper function to sample an index from a probability array
preds = np.asarray(preds).astype('float64')
preds = np.log(preds) / temperature
exp_preds = np.exp(preds)
preds = exp_preds / np.sum(exp_preds)
probas = np.random.multinomial(1, preds, 1)
return np.argmax(probas)
model.fit(X, y, batch_size=64, epochs=1)
diversity = 0.5
print()
generated = ''
sentence = "Godzilla"
# sentence = text[start_index: start_index + maxlen]
generated += sentence
# print('----- Generating with seed: "' + sentence + '"')
# sys.stdout.write(generated)
# for i in range(400):
x = np.zeros((1, maxlen, len(chars)))
for t, char in enumerate(sentence):
x[0, t, char_indices[char]] = 1.
preds = model.predict(x, verbose=0)[0]
plt.plot(preds,'r-')
plt.show()
Andererseits gibt der folgende Code den gleichen Wert wie "model.predict" aus. Ich habe es satt, für Aussagen zu schreiben, deshalb habe ich sie als c1, c2, c3 usw. beschrieben, aber diese Zahlen entsprechen dem Maximum des obigen Modells. Wenn Sie maxlen erhöhen möchten, können Sie eine Schleifenstruktur mit einem for-Dokument erstellen. Für den Code habe ich auf die folgende Seite verwiesen. http://blog.yusugomori.com/post/154208605320/javascript%E3%81%AB%E3%82%88%E3%82%8Bdeep-learning%E3%81%AE%E5%AE%9F%E8%A3%85long-short-term
print(preds)
weights = model.get_weights()
obj=weights
w1=obj[0]
w2=obj[1]
w3=obj[2]
w4=obj[3]
w5=obj[4]
hl = 128
def sigmoid(x):
return 1.0 / (1.0 + np.exp(-x))
def tanh(x):
return (np.exp(x)-np.exp(-x))/(np.exp(x)+np.exp(-x))
def activate(x):
x[0:hl] = sigmoid(x[0:hl]) #i
x[hl:hl*2] = sigmoid(x[hl:hl*2]) #a
x[hl*2:hl*3] = sigmoid(x[hl*2:hl*3]) #f
x[hl*3:hl*4] = sigmoid(x[hl*3:hl*4]) #o
return x
def cactivate(c):
return sigmoid(c)
x1 = np.array(x[0,0,:])
x2 = np.array(x[0,1,:])
x3 = np.array(x[0,2,:])
h1 = np.zeros(hl)
c1 = np.zeros(hl)
o1 = x1.dot(w1)+h1.dot(w2)+w3
o1 = activate(o1)
c1 = o1[0:hl]*o1[hl:hl*2] + o1[hl*2:hl*3]*c1
#c1 = o1[0:128]*o1[128:256] + c1
h2 = o1[hl*3:hl*4]*cactivate(c1)
#2 ..
o2 = x2.dot(w1)+h2.dot(w2)+w3
o2 = activate(o2)
c2 = o2[0:hl]*o2[hl:hl*2] + o2[hl*2:hl*3]*c1
#c2 = o2[0:128]*o2[128:256] + c1
h3 = o2[hl*3:hl*4]*cactivate(c2)
#3 ..
o3 = x3.dot(w1)+h3.dot(w2)+w3
o3 = activate(o3)
c3 = o3[0:hl]*o3[hl:hl*2] + o3[hl*2:hl*3]*c2
#c3 = o3[0:128]*o3[128:256] + c2
h4 = o3[hl*3:hl*4]*cactivate(c3)
y = h4.dot(w4)+w5
y = np.exp(y)/np.sum(np.exp(y))
plt.plot(y,'b-')
plt.show()
Als Ergebnis können Sie sehen, dass preds und y ähnliche Werte ausgeben.
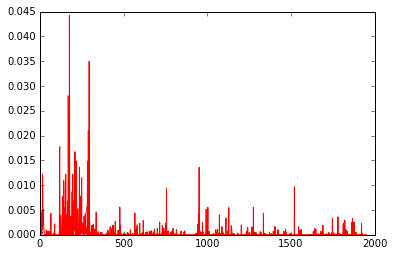 preds Plot Ergebnisse
preds Plot Ergebnisse
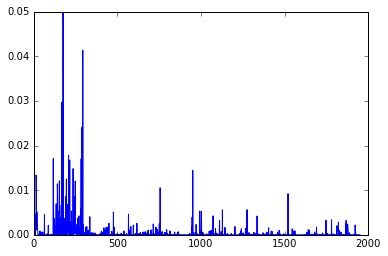 Plot-Ergebnis von y
Plot-Ergebnis von y
Übrigens verwendet der obige Code Sigmoid sowohl für die Aktivierungsfunktion als auch für die interne Zellenfunktion, aber aus irgendeinem Grund funktionierte es nicht mit tanh. Ich möchte aktualisieren, wenn es behoben ist.
Recommended Posts