[PYTHON] Ich habe versucht, Harry Potters Gruppierungshut mit CNN umzusetzen
Hintergrund
Ich höre oft solche Gespräche. „Du siehst wirklich aus wie Slytherin." „Ist es nicht wie Gryffindor?" Sicher gibt es einige Dinge, die verstanden werden können. Ich glaube, ich habe in der Arbeit gesagt, dass die Gruppierung von Schlafsälen in Harry Potter an erster Stelle wichtig ist, aber wenn der Geist den Körper beeinflusst, kommen die Eigenschaften der Gruppierung auch ins Gesicht. Ist es nicht? In diesem Fall sollte für jeden Schlafsaal im Gesicht ein Funktionsbetrag vorhanden sein! Gutes Lernen! Motivation wie. Das Folgende ist eine persönliche subjektive Gruppierungsprognose.


Und es gibt keine böswillige Absicht.
Ausführungsumgebung
- Mac OS X 10.10.5 (Yosemite)
- Python 2.7.13_0
- Chainer 1.20.0.1_0
- Open CV 3.2.0_0 (+contrib+java+python27+qt4+vtk)
Zweck
Wenn ein Bild eingegeben wird, das das Gesicht einer Person zeigt, wird ein neuronales Gruppennetz aufgebaut, das als Ausgabe zurückgibt, in welchem Schlafsaal sich das Ergebnis der Gesichtsgruppierung befindet. Da es vier Arten von Schlafsälen gibt, Gryffindor, Raven Claw, Hufflepuff und Slytherin, ist das neuronale Netz ein Klassifikator für vier Klassen. Das konzeptionelle Diagramm des gesamten zu konstruierenden gruppierenden neuronalen Netzes ist unten gezeigt.

Im nächsten Abschnitt konzentrieren wir uns auf die Erstellung von Datensätzen und die Konfiguration des neuronalen Netzmodells im Training.
Methode
Wie zu diesem Zweck erwähnt, beschreibt dieser Abschnitt die Erstellung von Datensätzen und die Konfiguration des neuronalen Netzmodells.
Datensatzerstellung
Ein Datensatz wurde mit dem vorherigen Python-Skript zur Bildersammlung zum Erstellen eines Datensatzes für maschinelles Lernen erstellt. Sammeln Sie die Charakternamen und Schauspielernamen, die zu jedem Schlafsaal gehören, als Abfrage. Schließlich wurde manuell beurteilt und im Verzeichnis jedes Schlafsaals gespeichert, ob es sich um das Bild des entsprechenden Zeichens handelte. Nachfolgend finden Sie einige Beispiele für Sammlungen für jeden Schlafsaal.

Die Bildgröße betrug 100 x 100 Pixel, und die Anzahl der Bilder in jedem Schlafsaal betrug 50, was insgesamt 200 Bildern entspricht. Offensichtlich gibt es viele Westler, und je nach Charakter gibt es große Vorurteile. Besonders Raven Claw und Huffle Puff haben sich überhaupt nicht versammelt ... zu wenig ... Zwanzig zufällig ausgewählte Blätter wurden als Testdaten zum Lernen verwendet.
Modellkonfiguration
Da die Aufgaben in 4 Klassen eingeteilt sind, dachte ich, dass es nicht notwendig ist, die Skala so stark zu erhöhen, aber ich bezog mich auf einige Alexnet. Die Modellkonfiguration ist unten dargestellt.
model.py
class Model(Chain):
def __init__(self):
super(Model, self).__init__(
conv1=L.Convolution2D(3, 128, 7, stride=1),
bn2=L.BatchNormalization(128),
conv3=L.Convolution2D(128, 256, 5, stride=1),
bn4=L.BatchNormalization(256),
conv5=L.Convolution2D(256, 384, 3, stride=1),
bn6=L.BatchNormalization(384),
fc7=L.Linear(6144, 8192),
fc8=L.Linear(8192, 1024),
fc9=L.Linear(1024, 4),
)
def __call__(self, x, train=True):
h = F.max_pooling_2d(self.bn2(F.relu(self.conv1(x))), 3, stride=3)
h = F.max_pooling_2d(self.bn4(F.relu(self.conv3(h))), 3, stride=3)
h = F.max_pooling_2d(self.bn6(F.relu(self.conv5(h))), 2, stride=2)
h = F.dropout(F.relu(self.fc7(h)), train=train)
h = F.dropout(F.relu(self.fc8(h)), train=train)
y = self.fc9(h)
return y
class Classifier(Chain):
def __init__(self, predictor):
super(Classifier, self).__init__(predictor=predictor)
self.train = True
def __call__(self, x, t, train=True):
y = self.predictor(x, train)
self.loss = F.softmax_cross_entropy(y, t)
self.acc = F.accuracy(y, t)
return self.loss
Die Ergebnisse des Trainings unter Verwendung des obigen Datensatzes und Modells werden im nächsten Abschnitt beschrieben.
Ergebnis
Dieser Abschnitt beschreibt den Lernübergang des Lernenden und das Ergebnis der implementierten Gruppierung des neuronalen Netzes.
Modell Lernübergang
Insgesamt gibt es 200 Datensätze, von denen 180 Trainingsdaten und 20 Testdaten sind. Der Übergang der Fehlerrate (1-Genauigkeitsrate) beim Lernen und Testen, wenn die Anzahl der Epochen 100 beträgt, ist unten gezeigt.

Da der niedrigste test_error 0,15 betrug, kann gesagt werden, dass dieses Modell in der 4-Klassen-Klassifizierung eine Genauigkeit von 85% aufwies.
Gruppierung des Ergebnisses der Ausführung des neuronalen Netzes
Das Ergebnis, wenn ein tatsächliches Bild in das gruppierende neuronale Netz eingegeben wird, das das trainierte Modell enthält, wird gezeigt.


Ich kenne die Antwort nicht, aber vorerst konnte ich die gewünschte Ausgabe für die Eingabe bestätigen! Wie erwartet wurde Hiroshi Abe in Gryffindor und Ariyoshi in Slytherin gruppiert, während Gacky und Becky genau umgekehrt gruppiert wurden. Aber Slytherin Gacky ist auch nicht schlecht. Ich möchte gemobbt werden. Es macht ein bisschen Spaß, also habe ich als nächstes nach einem Bild gesucht, das eine große Anzahl von Menschen gleichzeitig beurteilen kann, und es eingegeben.
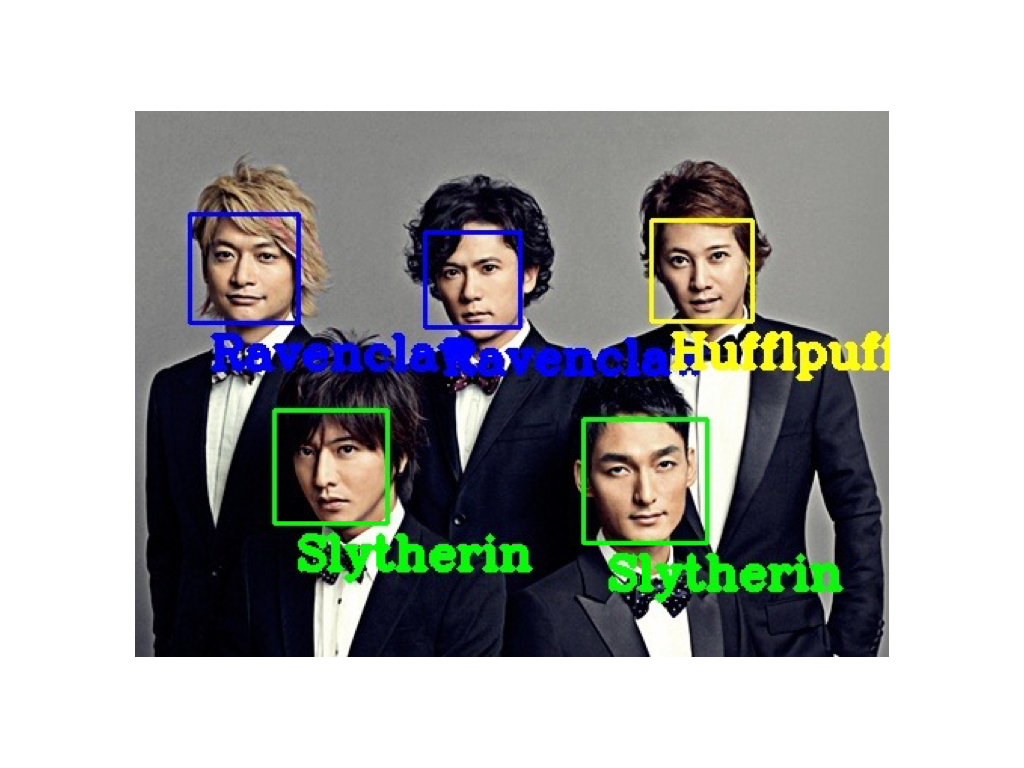
Als ich in die ehemalige nationale Idolgruppe SMAP (Sports Music Assemble People) eintrat, bekam ich dieses Ergebnis. Sogar eine große Anzahl von Menschen kann gleichzeitig gehen! Darüber hinaus ist das Ergebnis sehr überzeugend! Lol Ich habe damit herumgespielt, aber es macht Spaß, weil ich keine Verantwortung für die Genauigkeit übernehmen muss, weil die Antwort nicht die Antwort ist. Im Folgenden sind nur einige einfache Möglichkeiten zum Spielen aufgeführt.
Spielanleitung
Quellcode zum Gruppieren neuronaler Netze: GitHub Darüber hinaus befindet sich das diesmal trainierte Modell in hier. Als einfache Verwendung können Sie spielen, indem Sie das gelernte Modell, das Sie abgelegt haben, in das geklonte Verzeichnis legen und den folgenden Befehl ausführen. Beachten Sie auch, dass der Gesichtserkennungsteil das [haarcascade] von OpenCV (https://github.com/opencv/opencv/tree/master/data/haarcascades) verwendet. Erstellen Sie daher ein haarcascade-Verzeichnis. Es ist erforderlich, ein für die Gesichtserkennung geschultes Modell (z. B. haarcascade_frontalface_default.xml) direkt darunter zu platzieren. Sie können den Pfad, der auf das Modell verweist, in Ihrem Code neu schreiben.
$ python main.py -i ImagePath -m ./LearnedModel.model -p 1
Wenn beim Spielen die erste Gesichtserkennung erfolgreich ist, wird das Gruppierungsergebnis für jedes Gesicht gekennzeichnet. Sie müssen daher darauf achten, ein Bild des Gesichts einzugeben, das bei der Gesichtserkennung von OpenCV erfasst wird. Es wird nicht. Die Genauigkeit der Gesichtserkennung hängt auch vom trainierten Modell ab. Sie sollten daher verschiedene Dinge ausprobieren, ohne aufzugeben, auch wenn Sie einmal einen Fehler gemacht haben.
Erwägung
Die Anzahl der Lerndaten hat großen Einfluss auf die Lernergebnisse, aber diesmal waren die Schauspieler in jedem Schlafsaal, die im Film zu sehen waren, zu voreingenommen, sodass wir keine zufriedenstellende Anzahl sammeln konnten. Trotzdem kann die Tatsache, dass die richtige Antwortrate bis zu 85% beträgt, bedeuten, dass wir einige Merkmale jedes Schlafsaals erfasst haben. In Bezug auf die Anzahl menschlicher Proben ist es nicht verwunderlich, dass dasselbe Gesicht in die Validierung einbezogen wird. Es scheint also, dass etwa 85% als selbstverständlich angesehen werden ... Obwohl AlexNet diesmal als Referenz für die Modellkonfiguration verwendet wurde, wurde entschieden, dass das Modell nicht mit einem so hohen Freiheitsgrad erstellt werden muss, da das Eingabebild 100 x 100 angenommen wird, sodass die Anzahl der Faltungsschichten verringert wurde. Darüber hinaus könnte sich die Generalisierungsleistung verbessert haben, wenn der Kernel die 7x7- und 5x5-Schichten etwas tiefer gemacht hätte. Ich habe es nicht so sehr eingestellt, daher kann ich immer noch eine Verbesserung der Genauigkeit erwarten, wenn ich eine zufällige Suche durchführe.
Ariyoshi war irgendwie zufrieden mit Slytherin. Ich war übrigens Gryffindor. Ich habs gemacht.
Recommended Posts