[PYTHON] Ich habe versucht, Tundele mit Naive Bays zu beurteilen
Einführung
Dies ist eine Demo.
input=>Hey, was! ?? Ich bin überrascht ...
category: tsundere
input=>ich liebe dich Ich liebe dich so sehr.
category: not_tsundere
input=>...... Fass es nicht beiläufig an, dumm.
category: tsundere
input=>Person Liebe! Ich mag Menschen! Ich liebe dich!
category: not_tsundere
Gut ...
Was ich getan habe
Im Falle einer normalen Spam-Beurteilung
Der Computer wird darin geschult, sowohl Spam- als auch Nicht-Spam-Text zu lernen, um festzustellen, ob es sich bei dem neu eingegebenen Text um Spam handelt.
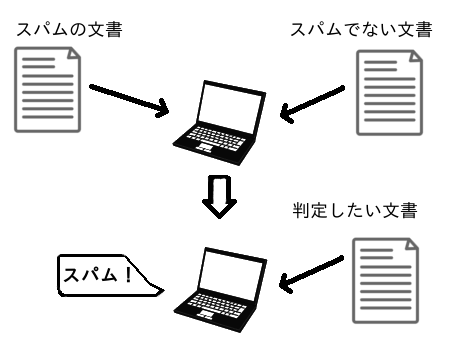 ...langweilig
...langweilig
Im Fall von Tundele Urteil
Trainiert den Computer, um Tundele-Text bzw. Nicht-Tundere-Text zu lernen und festzustellen, ob der neu eingegebene Text Tundere ist.
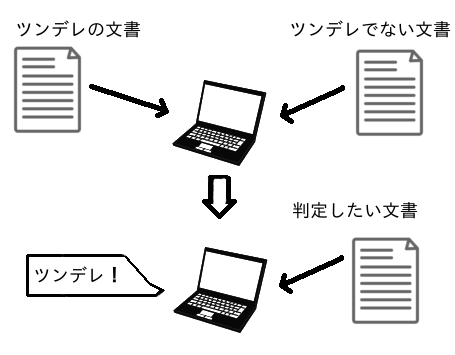
angenehm! !!
Vorbereitung der Daten
Natürlich werden zum Lernen Lerndaten benötigt. Ich muss irgendwie einen Text voller Tundelen vorbereiten. Diesmal habe ich Twitter verwendet, um die Daten zu sammeln. Wir erhalten Tweets von Konten wie "Tundele bot" und verwenden sie als Lerndaten.
Code
Der Code ist auf GitHub zu finden. Weitere Informationen zur Verwendung finden Sie unter LESEN. Ich habe den Code von Naive Bays aus Katryos Artikel verwendet.
Es erfordert Python-Twitter (das mit pip installiert werden kann), um zu funktionieren. Sie müssen auch den Schlüssel für die Twitter-Anwendung und die ID der Yahoo Morphological Analysis-Anwendung ausgeben. Sie können jeden unten bekommen.
https://dev.twitter.com/ https://e.developer.yahoo.co.jp/register
Bitte wählen Sie "Client Side", wenn Sie eine Yahoo-Anwendungs-ID eingeben. Fügen Sie jede ausgegebene ID in settings.cfg ein und geben Sie die entsprechenden Konten "true_accounts" und "ein Sie können es verwenden, indem Sie es auf "false_accounts" setzen.
Da pro Konto 200 Tweets erfasst und gelernt werden, dauert das Lernen umso länger, je mehr Konten Sie angeben. Bestimmen Sie die Anzahl der Konten, die Sie angeben möchten, indem Sie den Kompromiss zwischen Zeit und Genauigkeit betrachten.
Schließlich
Sie können Ihr eigenes Lerngerät erstellen, indem Sie verschiedene Daten trainieren. Zusätzlich zum Tundele-Urteil kann es interessant sein, das Yandere-Urteil und das ansehnliche Urteil zu versuchen.
Recommended Posts