[PYTHON] Ich habe versucht, ein multivariates statistisches Prozessmanagement (MSPC) zu implementieren.
- Artikel von Datenwissenschaftlern aus der Fertigungsindustrie
- Dieses Mal haben wir Anomalieerkennungsmethoden implementiert und organisiert, die in der Fertigungsindustrie eingesetzt werden können.
Einführung
In letzter Zeit haben die Anstrengungen, die maschinelles Lernen nutzen, sogar in der Fertigungsindustrie zugenommen. Dieses Mal haben wir das multivariate statistische Prozessmanagement (MSPC) organisiert, das im Anomalieerkennungsprojekt verwendet wird.
Was ist Anomalieerkennung in der Fertigungsindustrie?
In der Fertigungsindustrie gibt es den Begriff vorbeugende Wartung. Vorbeugende Wartung bezieht sich auf Wartungsmethoden, die mechanische Geräteausfälle, Fehlfunktionen und Leistungseinbußen in der Produktionslinie verhindern. Sie werden durchgeführt, um zu verhindern, dass Geräte brechen und die Produktionslinie stoppt. Darüber hinaus gibt es auch eine Erkennung von Betriebsstörungen, um die Produktion abnormaler Produkte vom normalen Betrieb abzuhalten.
Die diesmal eingeführte Anomalieerkennungsmethode (MSPC) kann für beide verwendet werden.
Was ist multivariates statistisches Prozessmanagement (MSPC)?
Bei Verwendung mit MSPC sind die verwendeten Daten nur normale Daten für das Training. Im Allgemeinen ist es bei der Klassifizierung durch maschinelles Lernen usw. leicht zu glauben, dass eine ordnungsgemäße Klassifizierung nur durchgeführt werden kann, wenn Proben mit dem gleichen Niveau an normalen Daten und abnormalen Daten gesammelt werden, aber im tatsächlichen Bereich gibt es fast keine abnormalen Daten und es ist normal. Es gibt nur viele Daten. (Da es sich um "abnormale Daten = Geräteausfall" handelt, handelt es sich um die Daten, wenn die Produktion der Fabrik eingestellt wird. Es ist natürlich, dass nur wenige solche Daten vorliegen. Daher konzentrieren wir uns am Produktionsstandort auf die vorbeugende Wartung. Wir haben es eingesetzt und führen Naturschutzmaßnahmen auf einem etwas übermäßigen Niveau durch.)
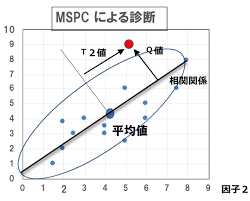
Die Grundidee der Erkennung von Anomalien besteht darin, einen Bereich festzulegen, in dem normale Daten in einem mehrdimensionalen Raum vorhanden sind. Wenn Daten beobachtet werden, die von diesem Bereich abweichen, wird dies als Anomalie beurteilt. Daher ist es möglich, ein Anomalieerkennungsmodell zu erstellen, indem nur normale Daten gelernt werden.
Als nächstes erklären wir, wie das Verwaltungslimit festgelegt wird, das die Grenze zwischen dem normalen Zustand und dem abnormalen Zustand darstellt. Es ist ein kleiner Nachteil, aber normalerweise gibt es eine Art Beziehung (Korrelation) zwischen den Variablen, und es ist notwendig, die Beziehung zwischen den Variablen zu erfassen, wenn der Bereich, der normale Daten enthält, richtig bestimmt wird. Mit anderen Worten, es ist notwendig, eine Ellipse für zwei Variablen und eine Superellipse für n Variablen vorzubereiten. MCPC verwendet die Hauptkomponentenanalyse (PCA) zur Berechnung des Maharanobis-Abstands als Methode zur Berücksichtigung der Beziehungen zwischen Variablen. MSPC ist eine Methode, die PCA verwendet, um eine Superellipse zu erstellen, ein Verwaltungslimit festzulegen und festzustellen, ob Daten davon abweichen.
MSPC verwendet PCA, um die Dispersion jeder Hauptkomponente auf 1 zu standardisieren, und standardisiert nicht alle Hauptkomponenten auf Dispersion 1, wenn der Maharanobis-Abstand berechnet wird. Berechnen Sie den Abstand vom Ursprung, indem Sie nur die Hauptkomponenten auf Dispersion 1 standardisieren. Das Quadrat dieser Entfernung wird als T ^ 2 $ -Statistik von $ Hotelling bezeichnet. Andererseits wird die Nicht-Haupthauptkomponente als Q-Statistik (quadratischer Vorhersagefehler) bezeichnet und durch das Quadrat der Entfernung (Vorhersagefehler) von dem von der Haupthauptkomponente überspannten Unterraum definiert.
Zusammenfassung der MSPC
Das Verfahren von MSPC ist unten organisiert.
- Holen Sie sich normale Daten
- Verwenden Sie PCA für normale Daten
- Bestimmen Sie die Anzahl der Hauptkomponenten
- Die Hauptkomponente berechnet die Statistik $ T ^ 2 $, und die anderen Hauptkomponenten berechnen die Statistik $ Q $.
- Legen Sie Verwaltungslimits für $ T ^ 2 $ -Statistiken und $ Q $ -Statistiken fest
MSPC-Implementierung
Dieses Mal haben wir die Daten (Probendatennummer: 2.756, Spaltennummer: 90) für den Test vorbereitet. Wir haben 1000 normale Daten und die restlichen 1.756 als Bewertungsdaten verwendet, um zu sehen, wie stark sie vom normalen Zustand abweichen.
Der Python-Code ist unten.
#Importieren Sie die erforderlichen Bibliotheken
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
%matplotlib inline
from sklearn.preprocessing import StandardScaler
from scipy import stats
from sklearn.neighbors.kde import KernelDensity
from sklearn.decomposition import PCA
df = pd.read_csv('test_data.csv', encoding='shift_jis', header=1, index_col=0)
df.head()
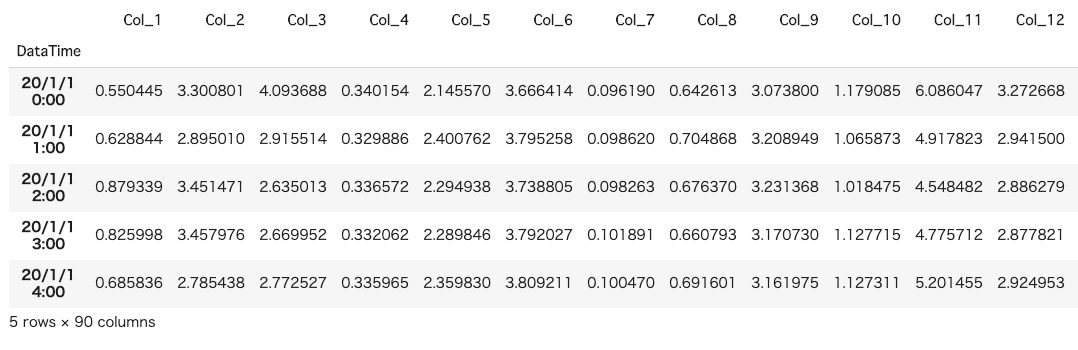
Die Eingabedaten sehen wie oben aus. Dieses Mal setzen wir Zufallszahlen in jede Spalte.
Als nächstes werden wir die Trainingsdaten und Bewertungsdaten aufteilen und standardisieren.
#Splitpunkt
split_point = 1000
#Unterteilt in Trainingsdaten (Zug) und Bewertungsdaten (Test)
train_df = df.iloc[:(split_point-1),]
test_df = df.iloc[split_point:,]
#Daten standardisieren
sc = StandardScaler()
sc.fit(train_df)
train_df_std = sc.transform(train_df)
Als nächstes führen wir eine Hauptkomponentenanalyse durch, um die Hauptkomponenten zu bestimmen. Die Hauptkomponente war diesmal der Teil, in dem der kumulierte Beitragssatz bis zu 95% betrug.
# PCA
pca = PCA()
pca.fit(train_df_std)
#Diagramm des kumulativen Beitrags
plt.figure()
variance = pca.explained_variance_ratio_
variance_total = np.zeros(np.shape(variance)[0])
plt.bar(range(np.shape(variance)[0]), variance)
for i in range(np.shape(variance)[0]):
variance_total[i] = np.sum(variance[0:i+1])
plt.plot(variance_total)
NumOfScore = np.min(np.where(variance_total>0.95))
x1=[NumOfScore,NumOfScore]
y1=[0,1]
plt.plot(x1,y1,ls="--", color = "r")
pca = PCA(n_components = NumOfScore)
pca.fit(train_df_std)
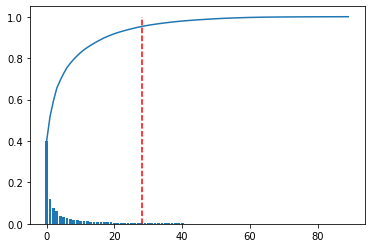
Als nächstes finden Sie die Q-Statistik.
#Q-Statistiken
scores = pca.transform(train_df_std)
residuals = pca.inverse_transform(scores)-train_df_std
dist = np.sqrt(np.sum(np.power(residuals,2),axis=1))/(np.shape(train_df_std)[1])
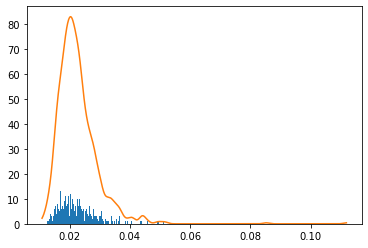
Da wir die Kontrollgrenze aus normalen Daten festlegen müssen, legen wir die Kontrollgrenze mithilfe der Kernel-Dichteschätzung fest.
#Kontrollgrenze (Schätzung der Kerneldichte)
cr = 0.99
X = dist.reshape(np.shape(dist)[0],1)
bw= (np.max(X)-np.min(X))/100
kde = KernelDensity(kernel='gaussian', bandwidth=bw).fit(X)
X_plot = np.linspace(np.min(X), np.max(X), 1000)[:, np.newaxis]
log_dens = kde.score_samples(X_plot)
plt.figure()
plt.hist(X, bins=X_plot[:,0])
plt.plot(X_plot[:,0],np.exp(log_dens))
prob = np.exp(log_dens) / np.sum(np.exp(log_dens))
calprob = np.zeros(np.shape(prob)[0])
calprob[0] = prob[0]
for i in range(1,np.shape(prob)[0]):
calprob[i]=calprob[i-1]+prob[i]
cl = X_plot[np.min(np.where(calprob>cr))]
Überprüfen Sie anschließend, wann die Testdaten nicht aus dem normalen Datenbereich kommen.
#Daten standardisieren
test_df_std = sc.transform(test_df)
# Test Data
newscores = pca.transform(test_df_std)
newresiduals = pca.inverse_transform(newscores)-test_df_std
newdist = np.sqrt(np.sum(np.power(newresiduals,2),axis=1))/(np.shape(test_df_std)[1])
Legen Sie abschließend die Kontrollgrenzen fest, die anhand der Q-Statistik (einschließlich Trainings- und Testdaten) und der Schätzung der Kerneldichte berechnet wurden.
#Darstellung der Q-Statistik
SPE = np.r_[dist,newdist]
plt.figure()
x = range(0,np.shape(df.index)[0],100)
NewTimeIndices = np.array(df.index[x])
x2 = [0, np.shape(SPE)[0]]
y2 = [cl,cl]
plt.title('SPE')
plt.plot(SPE)
plt.xticks(x,NewTimeIndices,rotation='vertical')
plt.plot(x2,y2,ls="-", color = "r")
#plt.ylim([0,1])
plt.xlabel("Time")
plt.ylabel("SPE")
# contribution plot
plt.figure()
total_residuals= np.r_[residuals,newresiduals]
CspeTimeseries = np.power(total_residuals,2)
cspe_summary=np.zeros([np.shape(CspeTimeseries)[0],10])
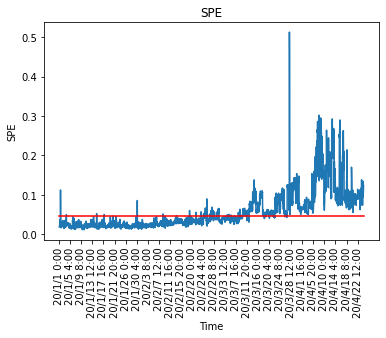
Tatsächlich wird das Beitragsdiagramm von hier aus berechnet, und wenn die Kontrollgrenze überschritten wird, wird berechnet, welche erklärende Variable sich auswirkt und abnormal wird. Auf die gleiche Weise können Sie auch das Verwaltungsdiagramm $ T ^ 2 $ verwalten und prüfen, welche erklärenden Variablen sich auf das Überschreiten des Verwaltungslimits auswirken.
Durch die Verwendung von MSPC ist es möglich, die Sensordaten mit 90 Variablen mit zwei Verwaltungsdiagrammen zu überwachen, und es ist möglich zu identifizieren, welcher Sensor abnormal ist, wenn der Alarm ertönt, also die Überwachungslast am Produktionsstandort Wird auch runter gehen. Es ist auch möglich, die Kernel-PCA anstelle der PCA zu verwenden, wenn die Beziehungen zwischen den Variablen nicht linear sind.
schließlich
Vielen Dank für das Lesen bis zum Ende. Dieses Mal haben wir die am Produktionsstandort erforderliche Anomalieerkennungsmethode (MSPC) implementiert. Im eigentlichen Bereich gibt es viele Optimierungsfaktoren wie die Standardmethode des Normalzustands und die Einstellung des Verwaltungslimits, aber ich denke, es ist besser, diese während des Betriebs vor Ort festzulegen.
Wenn Sie eine Korrekturanfrage haben, würden wir uns freuen, wenn Sie uns kontaktieren könnten.
Recommended Posts