[PYTHON] Ich habe ein Anomalieerkennungsmodell erstellt, das unter iOS funktioniert
Hintergrund
Ich möchte eine Anwendung für Landwirtschaft x Deep Learning erstellen!
Basierend auf diesem Motiv können wir meiner Meinung nach eine App erstellen, die den Gesundheitszustand einer Kultur diagnostiziert, indem wir sie beispielsweise eingeben.
Selbst wenn Sie eine App mit einem großartigen Modell erstellen, das Krankheiten beurteilen kann, ist es ein wichtiges Problem, ob der Benutzer das Bild der Zielkultur korrekt eingibt oder nicht, um die Zuverlässigkeit der App sicherzustellen.
Wenn Sie beispielsweise eine App erstellen, die die oben genannten Reiskrankheiten diagnostiziert, selbst wenn der Benutzer ein Bild von Unkraut eingibt, und wenn Sie ein solches Ergebnis ausgeben, ist das Diagnoseergebnis dieser App selbst verdächtig. Ich werde am Ende.
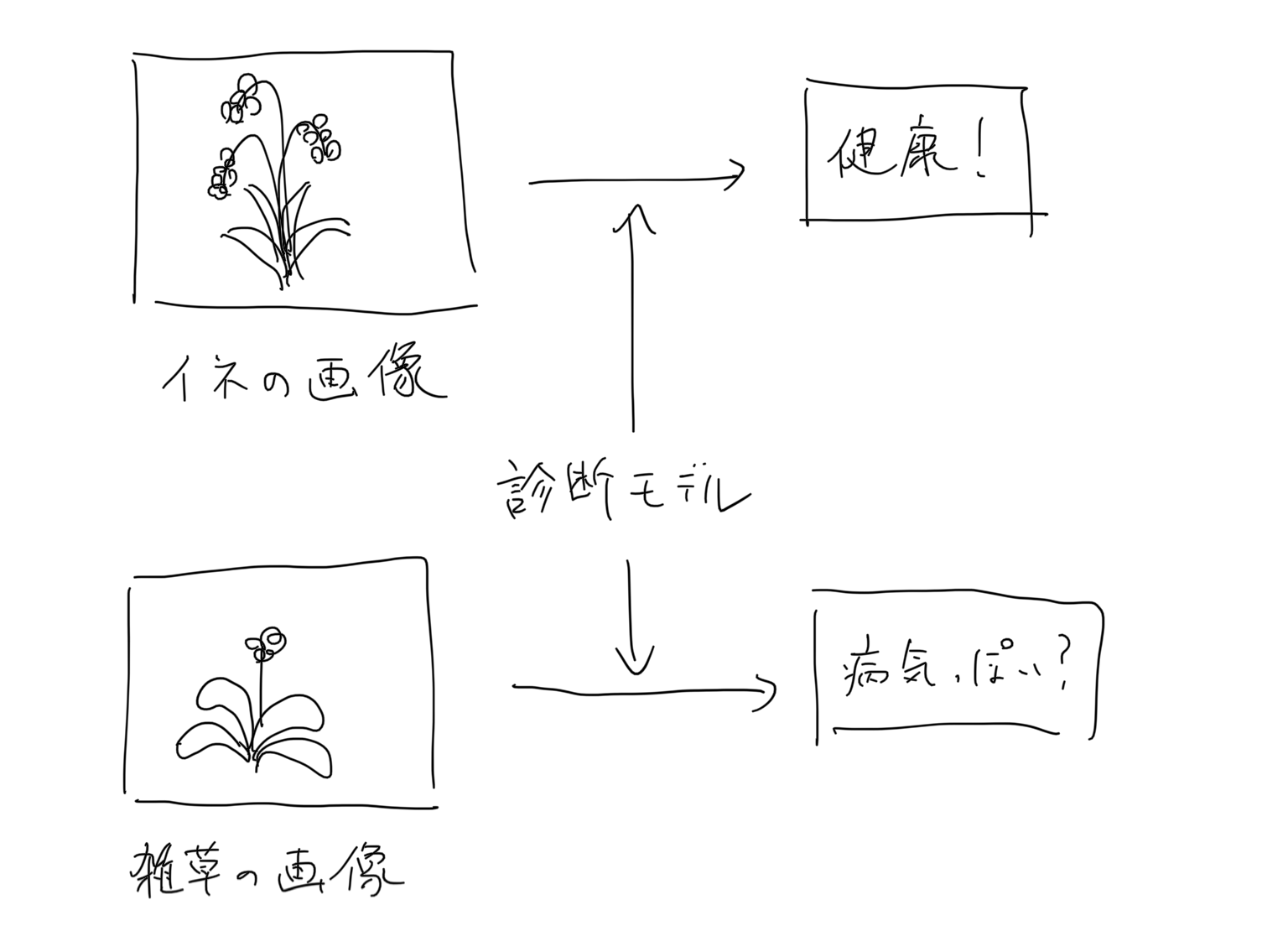
Um dieses Problem zu lösen, dachte ich, dass es besser wäre, ein abnormales Bilderkennungsmodell des Eingabebildes vor das Hauptmodell zu stellen.

Wenn nur die Bilder, die im Anomalieerkennungsmodell als normal beurteilt werden, an das Hauptmodell übergeben werden, können anscheinend äußerst zuverlässige Ergebnisse ausgegeben werden.
Was wurde gemacht
Ich habe die App auf einem iPhone X installiert, das ich vor drei Jahren gekauft habe, ein Bild von Reis und Unkraut auf meinem Laptop angezeigt und ein Foto davon gemacht. Wenn Sie auf die kreisförmige Spur oben rechts achten, können Sie sehen, wie Reis und Unkraut irgendwie voneinander unterschieden werden.

Im Folgenden werde ich aufschreiben, was ich getan habe.
Metrisches Lernen
Metrisches Lernen ist eine Technik, mit der ein Modell erstellt wird, das bestimmt, ob ein Bildpaar identisch ist. Für diese Anforderung haben wir diese Technik verwendet, um festzustellen, ob das Eingabebild mit dem trainierten Normalbild übereinstimmt.
Ich habe auf den folgenden Artikel verwiesen. https://qiita.com/shinmura0/items/06d81c72601c7578c6d3
Modell-
Ich habe Pytorch verwendet, um das Modell zu erstellen.
Da das Ziel darin besteht, es auf ein Smartphone zu übertragen, werden wir das leichte MobileNet V2 als Feature-Extraktor verwenden. MobileNet V2 wird standardmäßig von torchvision bereitgestellt.
Dieses Mal beträgt die Bildgröße 128 x 128. Formen Sie die Ausgabe der Feature-Ebene gut und machen Sie die endgültige Ausgabe zu einem 512-dimensionalen Vektor.
from torchvision.models import MobileNetV2
class MobileNetFeatures(nn.Module):
def __init__(self):
super(MobileNetFeatures, self).__init__()
self.head = MobileNetV2().features
self.pool = nn.AvgPool2d(4, 4)
self.flat = nn.Flatten()
self.fc = nn.Linear(1280, 512)
def forward(self, x):
x = self.head(x)
x = self.pool(x)
x = self.flat(x)
x = self.fc(x)
return x
Lernen
Datensatz
Als Trainingsdaten ist es notwendig, gleichzeitig mit einem normalen Bild ein zufälliges abnormales Bild zu geben. Daher haben wir zufällig die gleiche Anzahl normaler Bilder aus dem offenen Datensatz COCO-Datensatz extrahiert und diese als Satz abnormaler Bilder verwendet.
Verlustfunktion
Ich habe die relativ neue Verlustfunktion ** Arcface ** verwendet. Was die Erklärung von Arcface betrifft, war der folgende Artikel wahnsinnig leicht zu verstehen. https://qiita.com/yu4u/items/078054dfb5592cbb80cc
Außerdem wird im folgenden Repository die neueste Papierimplementierung eines solchen metrischen Lernens als Bibliothek bereitgestellt, sodass ich diese verwendet habe. https://github.com/KevinMusgrave/pytorch-metric-learning
Abnormalitätsmessung
Die Ausgabe des trainierten Modells ist eine 512-dimensionale Einbettung. Um festzustellen, ob das Eingabebild abnormal ist, ist es notwendig, ** Kosinusähnlichkeit ** mit der Einbettung zu nehmen, die aus dem normalen Bild erhalten wird.
Speichern Sie daher in der Trainingsphase den durchschnittlichen Vektor der Einbettung von Validierungsdaten gleichzeitig mit dem Speichern des Modells.
Dann kann dies zum Zeitpunkt der Inferenz gelesen werden und die Kosinusähnlichkeit mit dem Eingabebild kann genommen werden, um zu bestimmen, ob es abnormal ist oder nicht.
train.py
if save_interval > 0 and epoch_id % save_interval == 0:
model.eval()
#Messen Sie die Kosinusähnlichkeit zwischen normalen und abnormalen Bildern.
positive_dist = []
negative_dist = []
for batch in valid_loader:
images = batch[0].to(device)
labels = batch[1].numpy().tolist()
labels = [bool(i) for i in labels]
with torch.no_grad():
embeddings = model(images).cpu().numpy()
positive_embeddings = embeddings[labels]
negative_embeddings = embeddings[[not i for i in labels]]
mean_embedding = np.mean(positive_embeddings, axis=0)
for pe in positive_embeddings:
cos_sim = np.dot(mean_embedding, pe) / (np.linalg.norm(mean_embedding, ord=2) * np.linalg.norm(pe, ord=2))
positive_dist.append(cos_sim)
for ne in negative_embeddings:
cos_sim = np.dot(mean_embedding, ne) / (np.linalg.norm(mean_embedding, ord=2) * np.linalg.norm(ne, ord=2))
negative_dist.append(cos_sim)
mean_positive_dist = sum(positive_dist) / len(positive_dist)
mean_negative_dist = sum(negative_dist) / len(negative_dist)
print(f"epoch{epoch_id}: {mean_positive_dist} {mean_negative_dist}")
model.train()
#Einbettung speichern
features_save_path = f"../saved_features/embedding.txt"
np.savetxt(features_save_path, mean_embedding, delimiter=",")
Umstellung auf ein Smartphone-Modell
Dieses Mal habe ich coreML verwendet, vorausgesetzt, es wird unter iOS installiert.
Für die Konvertierung vom Pytorch-Modell in das CoreML werden wir einmal die Konvertierung in das ONNX-Format durchführen. (Die neueste Version von coremltools scheint in der Lage zu sein, ohne ONNX zu konvertieren, aber dieses Mal werde ich aufgrund mangelnder Forschung der alten Methode folgen.)
Bitte beziehen Sie sich auf das folgende Skript.
- Pytorch -> ONNX
- https://github.com/fltwtn/light_weight_annomaly_detection/blob/main/src/save_onnx.py
- ONNX -> CoreML
- https://github.com/fltwtn/light_weight_annomaly_detection/blob/main/src/save_coreml.py
Beachten Sie, dass ab dem 14. November 2020 in der Python 3.8.2-Umgebung ein ProtocolBuffer-Fehler aufgetreten ist und die Konvertierung in ONNX-> CoreML nicht funktioniert hat. Dies kann mit 3.7.7 gelöst werden.
Alles was Sie tun müssen, ist das generierte ".mlmodel" in Swift zu integrieren.
Am Ende
Das gesamte Projekt befindet sich im folgenden Repository. https://github.com/fltwtn/light_weight_annomaly_detection
Als ich es tatsächlich auf meinem Smartphone bediente, erkannte ich wieder die Geschwindigkeit von MobileNet V2. Vielleicht ist es über 30fps. .. .. Vor kurzem wurden hochpräzise und schnelle Modelle nacheinander veröffentlicht, daher werde ich weiterhin versuchen, verschiedene Modelle in Smartphone-Modelle umzuwandeln.
Recommended Posts