[PYTHON] Verwenden Sie PyCaret, um den Preis von Gebrauchtwohnungen in Tokio vorherzusagen!
§ Was ist PyCaret? </ strong>
Ich möchte die Schritte zur Vorhersage des Preises einer gebrauchten Wohnung vorstellen, indem ich ein Vorhersagemodell mit PyCaret erstelle, das jetzt ein heißes Thema auf Twitter usw. ist. Überlegen.
Mit PyCaret können Sie eine Reihe von Schritten des maschinellen Lernens ausführen, z. B. das Erstellen eines Vorhersagemodells, das Optimieren und das Erstellen von Vorhersagen mit einem Minimum an Python-Code. Es wird sein.
Was ist in diesem Artikel maschinelles Lernen durch Pycaret für diejenigen, die mit dem maschinellen Lernen beginnen möchten? Ich möchte fortfahren, während ich das vorstelle. Bitte beachten Sie, dass es Ausdrücke geben kann, die von der strengen Definition abweichen, da wir das sinnliche Verständnis betonen.
Mit diesem PyCaret können Sie jetzt verschiedene Prozesse ausführen, die zum Erstellen eines Vorhersagemodells für maschinelles Lernen mit einem einfachen Code erforderlich sind. Es ist ein ausgezeichnetes Produkt, das Ihnen bietet und wie bequem es ist, es zu verwenden! Ich war überrascht von. Und es ist kostenlos </ strong>!
Aber wie auch immer. Wenn Sie die Schwierigkeit des maschinellen Lernprozesses überhaupt nicht verstehen, werden Sie es möglicherweise nicht zu schätzen wissen.
§ Was ist überwachtes maschinelles Lernen? </ strong>
Das Erstellen eines Vorhersagemodells und das Verbessern seiner Genauigkeit ist eine wirklich schwierige Aufgabe.
Zunächst möchte ich die notwendigen Arbeiten für "überwachtes maschinelles Lernen" </ strong> überprüfen.
Beim überwachten maschinellen Lernen wird eine Regel (Modell) basierend auf früheren Daten abgeleitet, für die das Ergebnis (die Antwort) bekannt ist, und das zu erkennende Ergebnis wird vorhergesagt, indem es auf die Regel angewendet wird.
Wenn Sie beispielsweise in der Vergangenheit eine Reihe von Immobilienbedingungen und -preisen für eine gebrauchte Eigentumswohnung haben, können Sie den Preis vorhersagen, wenn Sie die Bedingungen kennen, z. B. wo sich die nächste Station befindet, wie viele Quadratmeter sie ist und wie viele Jahre sie gebaut wurde. Lassen Sie die Maschine diese Regel mit verschiedenen Algorithmen erstellen. Das ist maschinelles Lernen.
Die Schritte des überwachten maschinellen Lernens sind grob wie folgt unterteilt.
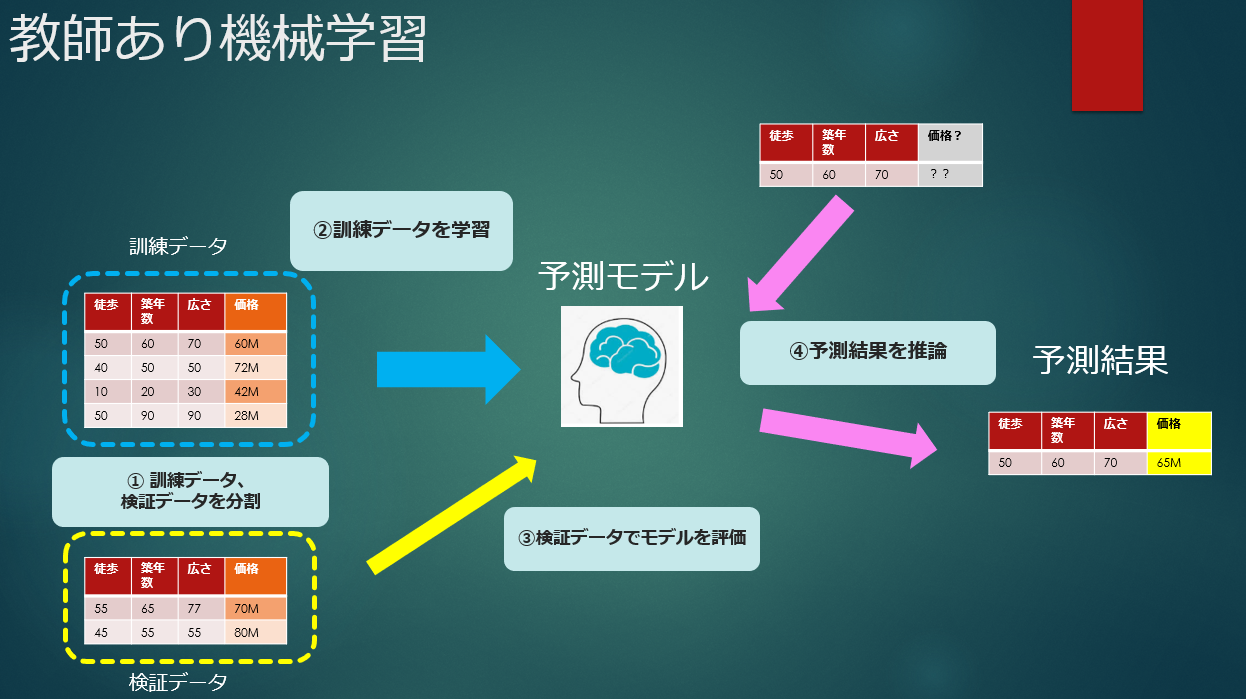
① Teilen Sie die Daten in Trainingsdaten und Verifizierungsdaten </ b> auf
Teilen Sie die Daten in Trainingsdaten und Validierungsdaten auf, um das Modell mit Daten zu validieren, die nicht zum Trainieren des Modells verwendet werden. Wenn Sie es mit Trainingsdaten auswerten, ist es wie Konserven. Um Trainingsdaten und Daten zu verwenden, die die Genauigkeit des Modells gleichmäßig und fair überprüfen, wird normalerweise eine Division durchgeführt und eine Abwechslung (Kreuzvalidierung) durchgeführt.
② Modellerstellung (Lernen) und Optimierung von Hyperparametern </ b>
Entscheiden Sie, welcher Algorithmus für die Vorhersage verwendet werden soll, lernen Sie anhand von Trainingsdaten, erstellen Sie ein Modell und stimmen Sie ab, um die Genauigkeit zu verbessern.
③ Modellbewertung </ b>
Bewerten Sie die Genauigkeit des durch Training erstellten Modells und bewerten Sie, wie viel Fehler es aufweist und ob es verwendbar ist.
④ Vorhersage eines unbekannten Wertes </ b>
Wenn die Auswertung abgeschlossen ist, wird das Vorhersageergebnis durch Eingabe der Daten, deren Ergebnis unbekannt ist, in das Vorhersagemodell erhalten. Ich kenne nur die Bedingungen der Wohnung, aber ich kenne den Preis nicht, also ist das Bild, um es vorherzusagen.
§ Versuchen Sie tatsächlich, PyCaret zu verwenden.
Lassen Sie uns diesen Fluss nun mit Pycart ausführen.
Zuerst installieren wir Pycaret mit Pip.
Diesmal laufe ich Pip von Anaconda Powershell.
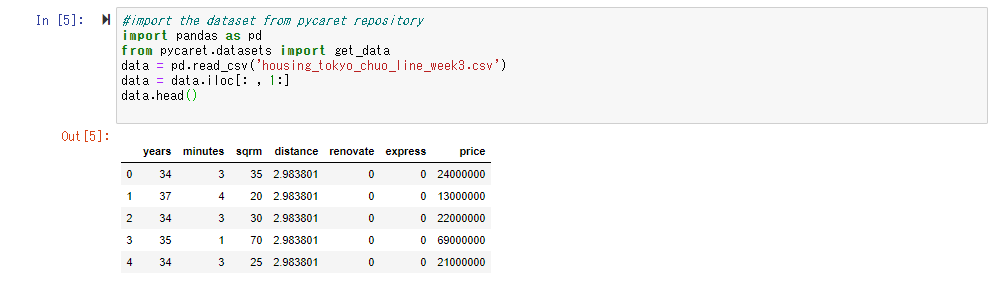
Lassen Sie uns zuerst die Daten lesen. Auch diesmal wird der Preis für die gebrauchte Wohnung entlang der Linie Tokio / Chuo in "Data Science Learning School beginnend mit Tableau" verwendet Verwenden Sie die Daten als Lehrerdaten. Die Daten selbst haben folgenden Inhalt.
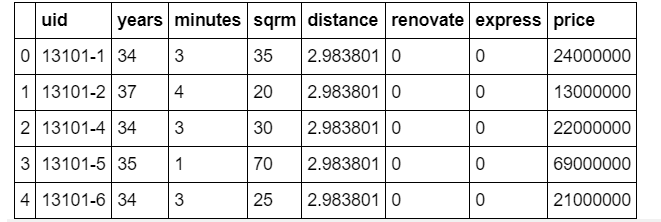
Die Erklärung für jeden Punkt lautet wie folgt.
| Elementname | Beschreibung | Datentyp |
| uid | Eindeutige ID der Eigenschaft | Zeichenfolgentyp |
| years | Alter | Integer-Typ |
| minutes | Fußweg (Minuten) von der nächsten Station | Integer-Typ |
| sqrm | Anzahl der Quadratmeter Grundstück | Integer-Typ |
| distance | Gerade Entfernung zwischen dem Bahnhof Tokio und dem nächsten Bahnhof (wie weit ist es vom Stadtzentrum entfernt?) | Gleitkomma |
| renovate | Überholt oder nicht markiert | Integer-Typ (0 oder 1) |
| express | Flag, um zu sehen, ob der Express stoppt | Integer-Typ (0 oder 1) |
| price | Transaktionspreis (Zielvariable) | Integer-Typ (Einheit: 1 Yen) |
Rufen Sie Pycaret mit Import an. Diesmal ist es ein Regressionsmodell, das den Preis errät, also importieren Sie aus pycaret.regression.
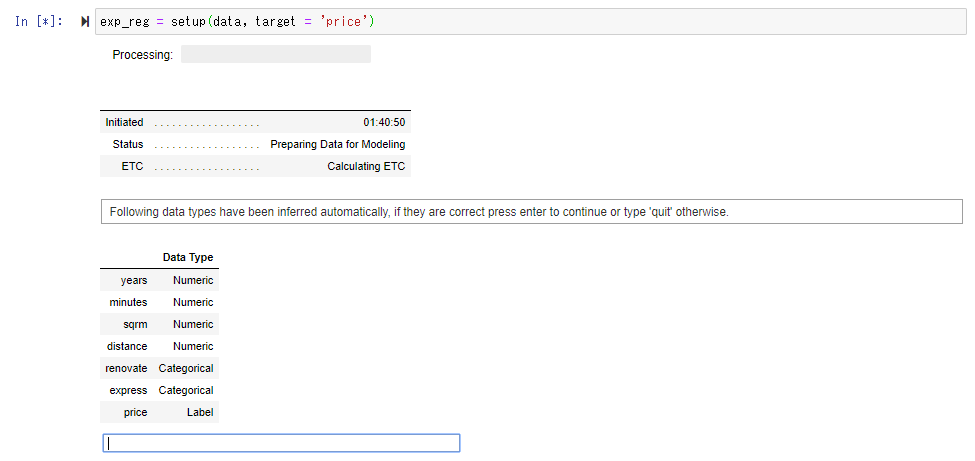
Wenn Sie die Zielvariable (Variable, die Sie vorhersagen möchten) auf den Wohnungspreis "Preis" setzen und die Funktion Setup () ausführen, wird automatisch ermittelt, ob jedes Feld eine numerische Zeichenfolge oder eine Kategoriespalte ist und ob es keinen Unterschied gibt. Führen Sie die Eingabetaste aus.
Führen Sie die notwendige Vorbehandlung durch.


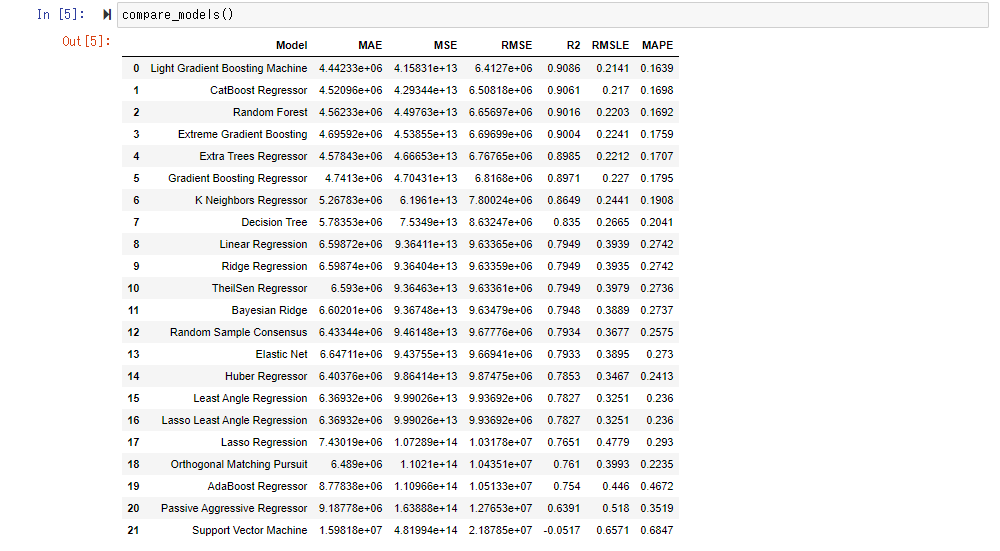
Bewerten und vergleichen Sie verschiedene Modelle mit compare_model () und ordnen Sie sie in der Reihenfolge des geringsten Fehlers an. Intern wird eine Kreuzvalidierung (die Lehrerdaten und die Verifizierungsdaten werden gleichmäßig und gleichmäßig ausgetauscht) durchgeführt, und standardmäßig ist Fold = 10 (die Daten werden in 10 unterteilt und die Trainingsdaten und die Verifizierungsdaten werden ausgetauscht). Die durchschnittliche Punktzahl wird angezeigt.
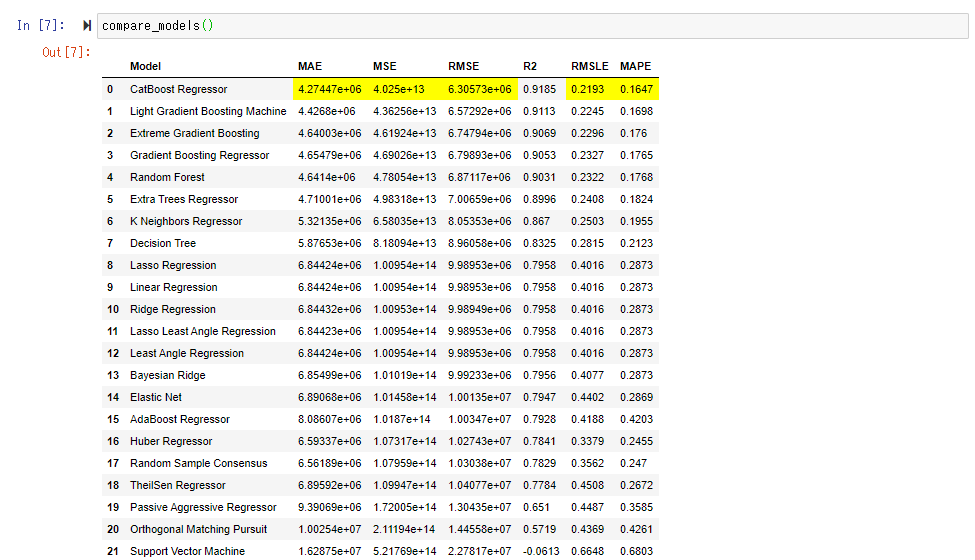
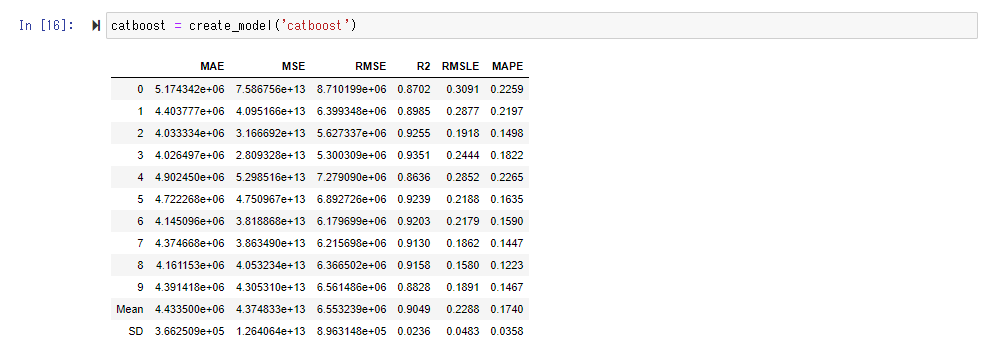
Diesmal scheint die Punktzahl " CatBoost Regressor " gut zu sein. Da RMSE 6,3 Millionen beträgt, können Sie ungefähr verstehen, dass der durchschnittliche Fehler pro Wohnung etwa 6,3 Millionen beträgt.
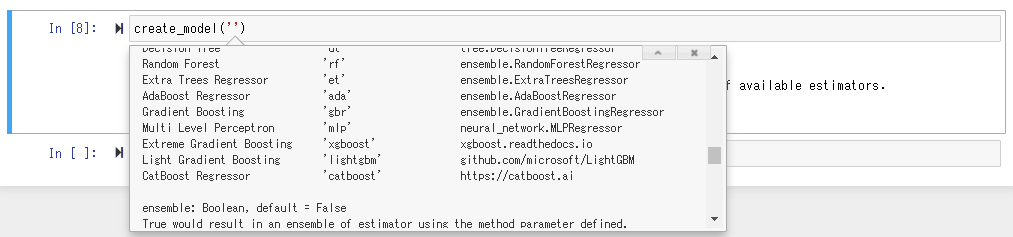
Führen Sie die Funktion create_model () aus, um das tatsächlich trainierte Modell zu verwenden. Shift + Tab gibt Ihnen eine Anleitung, was Sie in das Argument einfügen sollen, aber hier geben wir den "Cat Boost Regressor" mit der besten Punktzahl an.
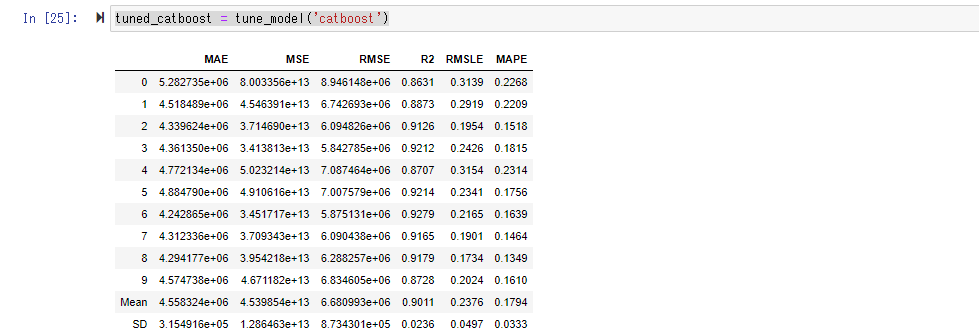
Wenn Sie ein Modell mit tune_model () erstellen, bleiben die Hyperparameter (vor dem Training festgelegt, Standardparameter für das Modellverhalten) auf ihren Standardwerten. Finden Sie den geeigneten Hyperparameter im voreingestellten Bereich. Es scheint, dass die Zufallssuche hier als beste Parametersuchmethode verwendet wird.
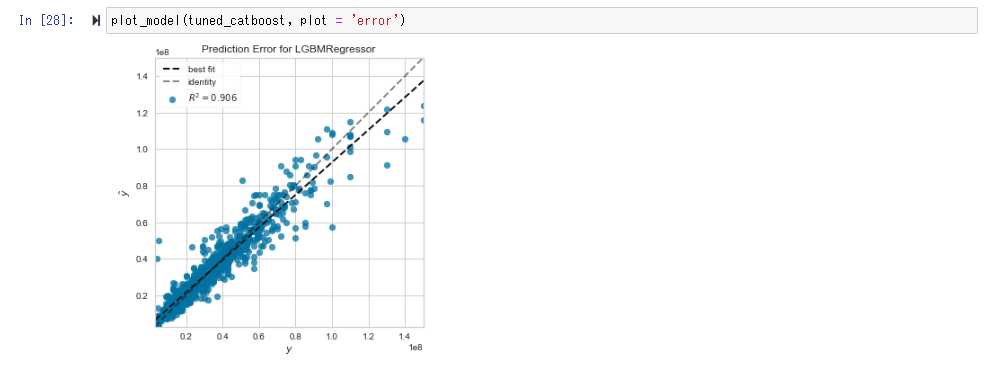
Visualisieren und überprüfen Sie die Genauigkeit des Modells mit plot_model ().
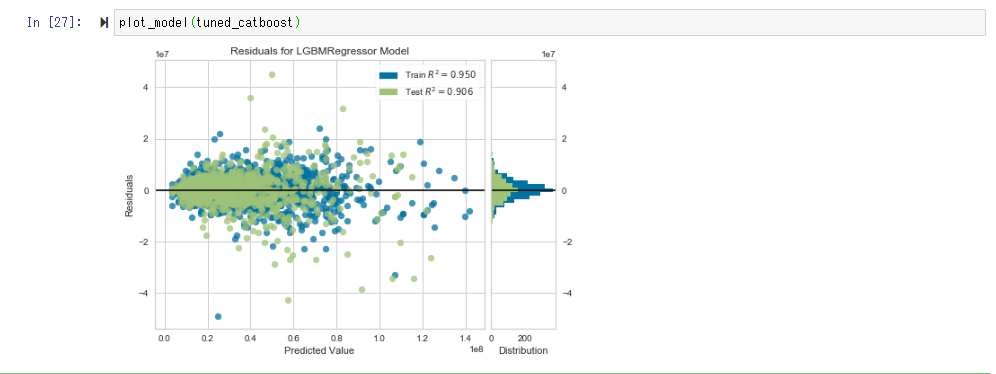
Wenn bei Fehlerdiagramm Vorhersage und Messung gleich sind, nähert sich die Verteilung der geraden Linie von y = x.
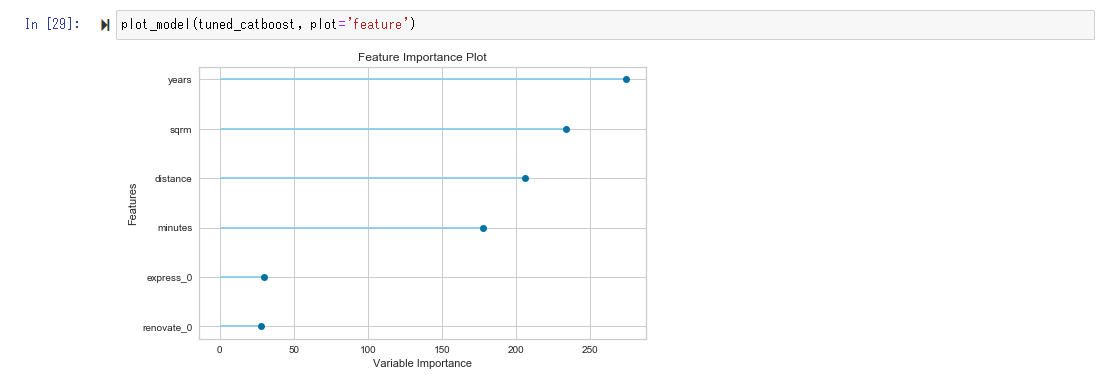
Das Feature-Wichtigkeitsdiagramm zeigt an, welche Variablen stark an der Vorhersage beteiligt sind. In diesem Fall können Sie sehen, dass der Einfluss in der Reihenfolge des Alters (Jahre), der Anzahl der Quadratmeter (qm), der Entfernung (gerade Entfernung vom Bahnhof Tokio zum nächsten Bahnhof) und der Minuten (Minuten zu Fuß vom nächsten Bahnhof) stark ist.
Führen Sie abschließend finalize_model () aus, um das Modell fertigzustellen. Sie können die optimierten Hyperparameter sehen, indem Sie hier drucken.

Nachdem Sie ein geschultes Modell haben, bereiten Sie die Wohnungspreisinformationen vor, die von der Immobilienseite im Web stammen, mit der das Modell erstellt wird, und fügen Sie sie in den Datenrahmen mit dem Namen "data_unseen" ein.
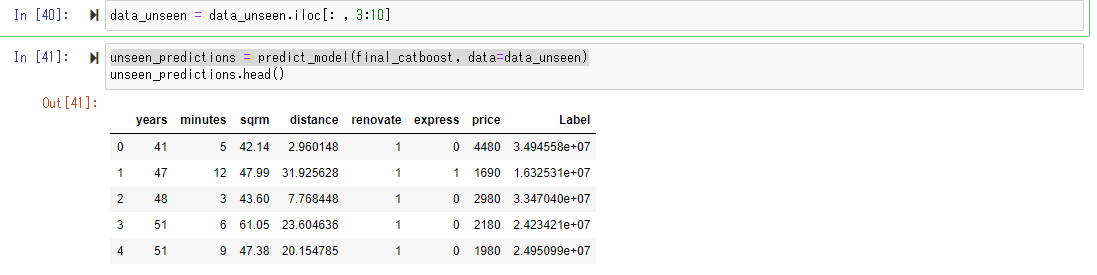
Fügen wir diese "unseen_data" in das soeben erstellte Prognosemodell ein und lassen Sie es den Preis vorhersagen.
Diese Operation ist sehr einfach. Schneiden Sie die erklärenden Variablen in derselben Form wie die Trainingsdaten aus und verwenden Sie die Funktion pred_model (), um den vorhergesagten Wert zu berechnen.
Unten sehen Sie, dass der vorhergesagte Wert als "Label" hinzugefügt wurde. Ursprünglich kennen wir für unbekannte Daten die Zielvariable "Preis" nicht, aber diesmal gibt es einen Preis für eine Wohnung, der bereits im Internet veröffentlicht wurde, sodass "Preis" in den Daten enthalten ist. (Die Einheit der öffentlichen Information beträgt jedoch 10.000 Yen.) Wenn man den in diesem Web veröffentlichten "Preis" mit dem vom Vorhersagemodell vorhergesagten "Wert" vergleicht, ist dies ein relativ guter Wert. Sie können fühlen, dass es herauskommt. (Ungefähr 20-40 Millionen scheinen in Tokio im Bereich der Wohnungspreise zu liegen.)
Da diese Daten in CSV abgelegt werden können, werden sie in CSV abgelegt und dann zur Visualisierung mit Taleau verbunden.
Wenn Sie den im Web veröffentlichten Preis "Preis" mit dem vom Prognosemodell berechneten "Label" vergleichen, finden Sie möglicherweise "Schnäppchenimmobilien", deren tatsächlicher Preis günstiger als die Prognose ist, und umgekehrt. Hmm. (Im Folgenden wird die Verwendung des geschätzten Preises in Tableau mit diesem Link identisch.)
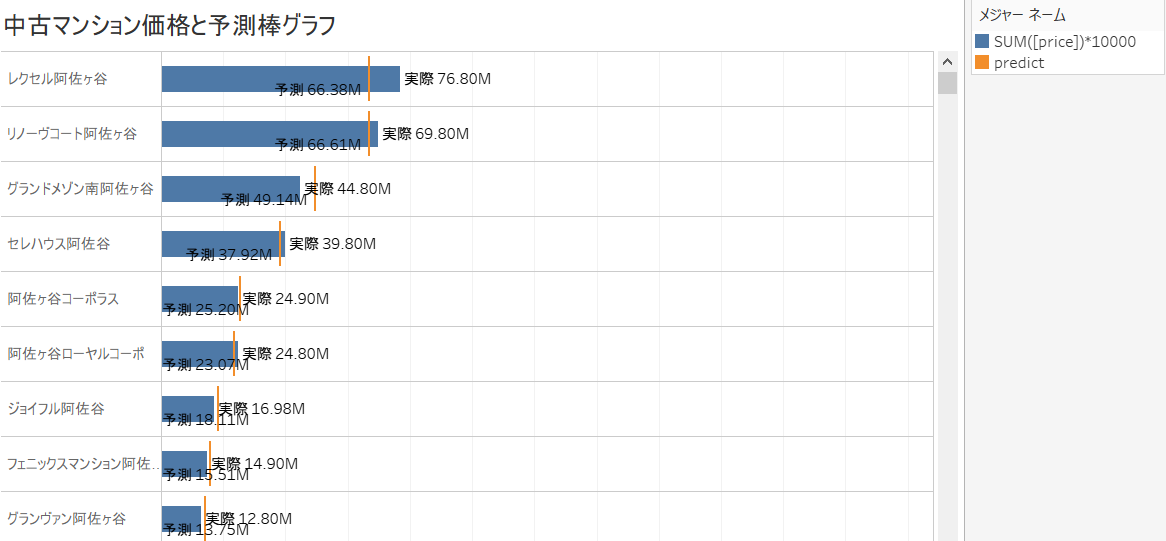
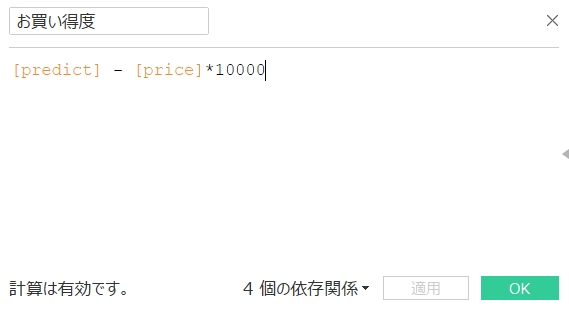
Wenn das Schnäppchen wie unten gezeigt als berechnetes Feld definiert ist und der vorhergesagte Preis höher als der gebuchte Preis ist, ist das Schnäppchen tatsächlich höher als erwartet, weil es "billiger als erwartet!" Ist, und umgekehrt ist der vorhergesagte Preis niedriger als der gebuchte Preis. Eigentlich ist es "höher als ich erwartet hatte!", Also werde ich versuchen, das Schnäppchen zu reduzieren.
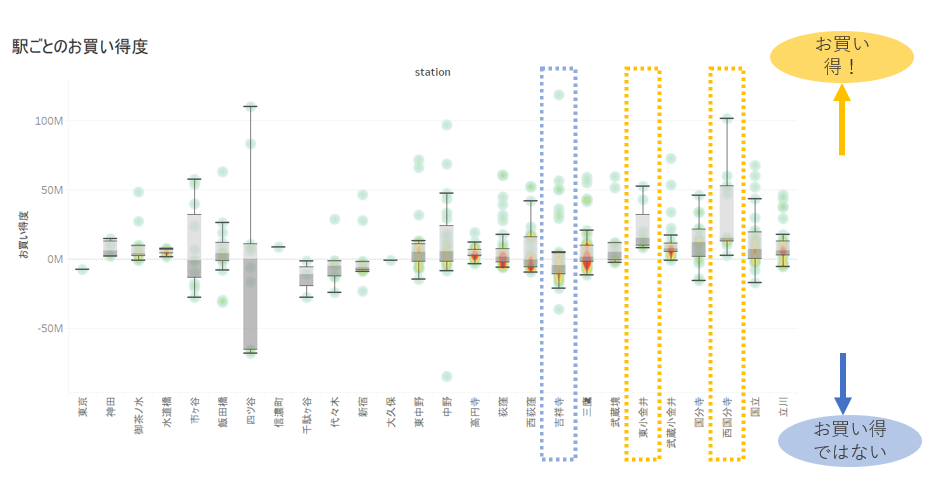
Wenn Sie für jede Station ein Box-Bart-Diagramm zeichnen und es visualisieren, sieht es wie folgt aus.
Es gibt Entdeckungen wie, dass Yotsuyas Reichweite zu groß ist, um zuverlässig zu sein, Kichijojis Schnäppchen niedrig und Nishikokubunjis Schnäppchen hoch ist.
Dies deutet darauf hin, dass zusätzlich zu der erklärenden Variablen der Entfernung vom Bahnhof Tokio zum nächsten Bahnhof (wie nahe am Stadtzentrum) keine Erklärung vorliegt, es sei denn, neue Faktoren wie "Beliebtheit des nächstgelegenen Bahnhofs" werden berücksichtigt. Sie können es bekommen. (* Hinweis: Ob es sich um ein tatsächliches Geschäft handelt oder nicht, hängt von den einzelnen Werten ab. Der Artikel basiert auf der Annahme, dass er nicht unbedingt beurteilt werden kann.)
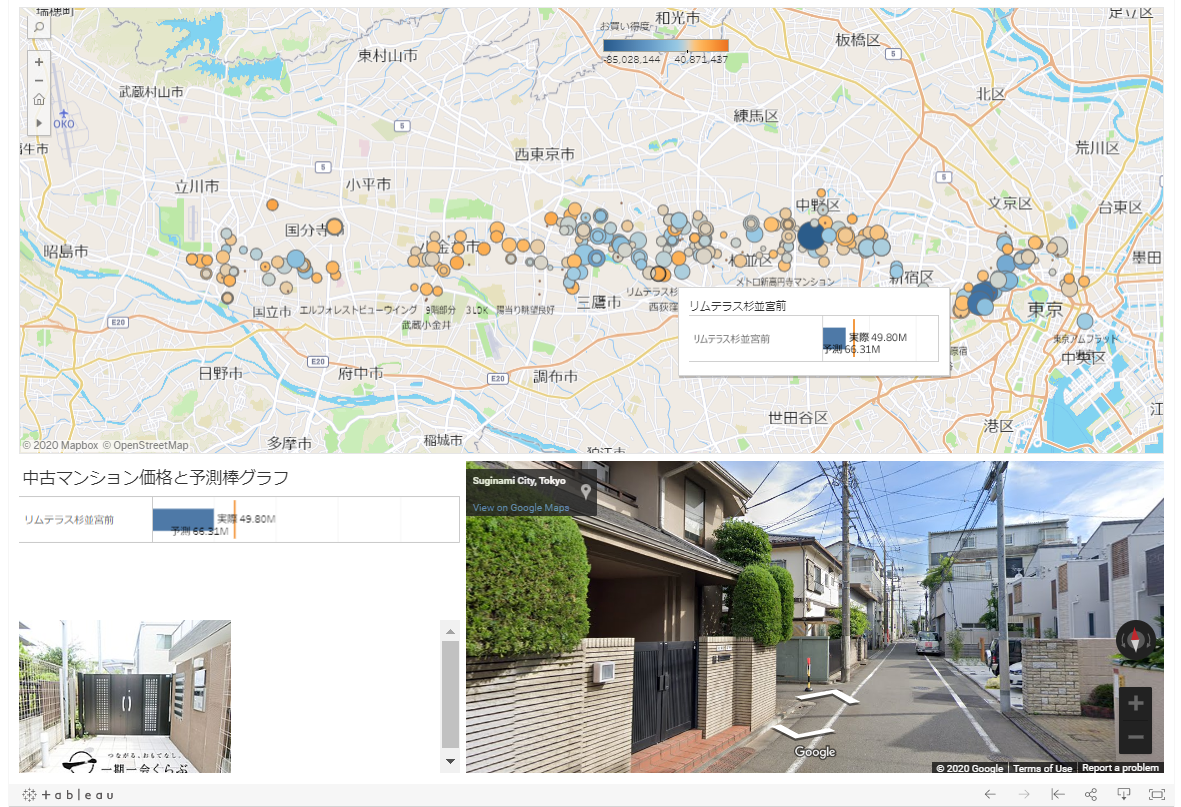
Als Weiterentwicklung der Datennutzung geocodieren wir außerdem Breiten- und Längengrade anhand von Daten und kartierten Schnäppcheneigenschaften auf einer Karte. Unten bedeutet Orange, dass die Immobilie ein Schnäppchen ist, Blau bedeutet, dass es kein Schnäppchen ist, und die Größe des Kreises ist der Preis der Immobilie. Durch Klicken auf den Punkt der Immobilie auf der Karte können Sie in Zusammenarbeit mit Google Street View die Bildinformationen der Immobilie und den Zustand der umliegenden Stadt überprüfen. Natürlich wird es hier nicht veröffentlicht, aber es ist auch möglich, Eigenschaftsinformationen im Dashboard anzuzeigen, indem Sie auf die veröffentlichte Webseite verlinken.
Wie oben erwähnt, wird mit PyCaret der Prozess, der ursprünglich für die Modellerstellung beim maschinellen Lernen erforderlich war, vollständig ausgeführt, sodass Sie problemlos ein Vorhersagemodell und Hyperparameter erstellen können, ohne dass Python-Codierung oder Debugging erforderlich sind. Es war ein Schock, (kostenlos) stimmen zu können.
Selbst wenn Sie Python für mehr Genauigkeit einstellen, können Sie die anfängliche Arbeitslast erheblich reduzieren, indem Sie Pycaret als Ausgangspunkt verwenden.
Es scheint jedoch immer noch notwendig zu sein, das Mindestwissen über Pandas und die grundlegende Methode zu verstehen, die als Fluss des maschinellen Lernens implementiert wird.
Darüber hinaus kann der Wert von Prognosedaten verdoppelt werden, indem Fehler mit Tableau usw. visualisiert, mit Domänenwissen zusammengestellt, neue erklärende Variablen hinzugefügt und Vorhersageergebnisse in einem interaktiven Dashboard verwendet werden. Ist das nicht möglich
Zusätzlich zum Ensemble scheint PyCaret in der Lage zu sein, Klassifizierung, Clustering, Erkennung von Anomalien, Verarbeitung natürlicher Sprache und Assoziationsanalyse für die Regression durchzuführen, die wir dieses Mal aufgenommen haben. Fügen Sie daher praktische Beispiele hinzu, die Sie in Zukunft verwenden werden. Ich denke
Classification Regression Clustering Anomaly Detection Natural Language Processing Association Rule Mining
Bitte probieren Sie es aus.
Verweise:
Qiita Artikel:
Recommended Posts