"""
## 49.Extraktion von Abhängigkeitspfaden zwischen Nomenklaturen[Permalink](https://nlp100.github.io/ja/ch05.html#49-ExtraktionvonAbhängigkeitspfadenzwischenNomenklaturen)
Extrahieren Sie den kürzesten Abhängigkeitspfad, der alle Nomenklaturpaare im Satz verbindet. Die Klauselnummern des Nomenklaturpaars sind jedoch ii und jj (i)<ji<Im Fall von j) muss der Abhängigkeitspfad die folgenden Spezifikationen erfüllen.
-Wie in Frage 48 beschreibt der Pfad die Darstellung (oberflächenmorphologische Sequenz) jeder Phrase von der Startklausel bis zur Endklausel.` -> `Express durch Verbindung mit
-Ersetzen Sie die in den Abschnitten ii und jj enthaltene Nomenklatur durch X bzw. Y.
Darüber hinaus kann die Form des Abhängigkeitspfads auf zwei Arten betrachtet werden.
-Wenn Klausel jj auf dem Pfad von Klausel ii zum Stamm des Syntaxbaums vorhanden ist:Zeigen Sie den Pfad von Klausel jj aus Klausel ii an
-Anders als oben, wenn sich Klausel ii und Klausel jj bei einer gemeinsamen Klausel kk auf der Route von der Wurzel des Syntaxbaums überschneiden:Der Pfad unmittelbar vor der Phrase ii zur Phrase kk, der Pfad unmittelbar vor der Phrase jj zur Phrase kk und der Inhalt der Phrase kk werden als "` | `Anzeige durch Verbinden mit
Betrachten Sie den Beispielsatz "John McCarthy hat den Begriff künstliche Intelligenz auf der ersten Konferenz über KI geprägt." Wenn CaboCha für die Abhängigkeitsanalyse verwendet wird, kann die folgende Ausgabe erhalten werden.
'''
X ist|Über Y.->Der Erste->Bei einem Treffen|Erstellt
X ist|Y's->Bei einem Treffen|Erstellt
X ist|In Y.|Erstellt
X ist|Genannt Y.->Terminologie|Erstellt
X ist|Y.|Erstellt
Über X.->Y's
Über X.->Der Erste->In Y.
Über X.->Der Erste->Bei einem Treffen|Genannt Y.->Terminologie|Erstellt
Über X.->Der Erste->Bei einem Treffen|Y.|Erstellt
Von X.->In Y.
Von X.->Bei einem Treffen|Genannt Y.->Terminologie|Erstellt
Von X.->Bei einem Treffen|Y.|Erstellt
In X.|Genannt Y.->Terminologie|Erstellt
In X.|Y.|Erstellt
X genannt->Y.
'''
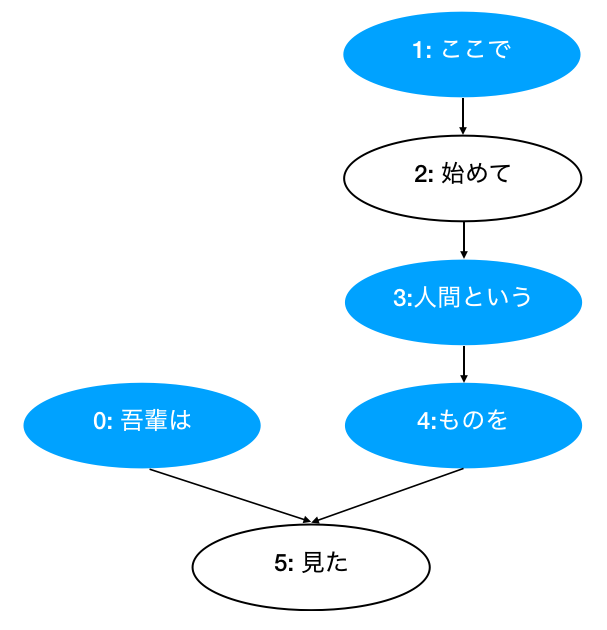
[Chunk( id: 0, dst: 5, srcs: [], morphs: [Morph(ich), Morph(Ist)] ),
Chunk( id: 1, dst: 2, srcs: [], morphs: [Morph(Hier), Morph(damit)] ),
Chunk( id: 2, dst: 3, srcs: ['1'], morphs: [Morph(Start), Morph(Hand)] ),
Chunk( id: 3, dst: 4, srcs: ['2'], morphs: [Morph(Mensch), Morph(Das)] ),
Chunk( id: 4, dst: 5, srcs: ['3'], morphs: [Morph(Ding), Morph(Zu)] ),
Chunk( id: 5, dst: -1, srcs: ['0', '4'], morphs: [Morph(Sie sehen), Morph(Ta), Morph(。)] )]
'''
Pattern 1 (Without root)
1 -> 3 -> 4
1 -> 3
1 -> 4
3 -> 4
Pattern 2 (With root):
From 0 to 1:
0 | 1 -> 3 -> 4 | 5
From 0 to 3:
0 | 3 -> 4 | 5
From 0 to 4:
0 | 4 | 5
'''
"""
from collections import defaultdict
from typing import List
def read_file(fpath: str) -> List[List[str]]:
"""Get clear format of parsed sentences.
Args:
fpath (str): File path.
Returns:
List[List[str]]: List of sentences, and each sentence contains a word list.
e.g. result[1]:
['* 0 2D 0/0 -0.764522',
'\u3000\t Symbol,Leer,*,*,*,*,\u3000,\u3000,\u3000',
'* 1 2D 0/1 -0.764522',
'ich\t Substantiv,Gleichbedeutend,Allgemeines,*,*,*,ich,Wagahai,Wagahai',
'Ist\t Assistent,Hilfe,*,*,*,*,Ist,C.,Beeindruckend',
'* 2 -1D 0/2 0.000000',
'Katze\t Substantiv,Allgemeines,*,*,*,*,Katze,Katze,Katze',
'damit\t Hilfsverb,*,*,*,Besondere,Kontinuierlicher Typ,Ist,De,De',
'Gibt es\t Hilfsverb,*,*,*,Fünf Schritte, La Linie Al,Grundform,Gibt es,Al,Al',
'。\t Symbol,Phrase,*,*,*,*,。,。,。']
"""
with open(fpath, mode="rt", encoding="utf-8") as f:
sentences = f.read().split("EOS\n")
return [sent.strip().split("\n") for sent in sentences if sent.strip() != ""]
class Morph:
"""Morph information for each token.
Args:
data (dict): A dictionary contains necessary information.
Attributes:
surface (str):Oberfläche
base (str):Base
pos (str):Teil (Basis)
pos1 (str):Teil Teil Unterklassifizierung 1 (pos1)
"""
def __init__(self, data):
self.surface = data["surface"]
self.base = data["base"]
self.pos = data["pos"]
self.pos1 = data["pos1"]
def __repr__(self):
return f"Morph({self.surface})"
def __str__(self):
return "surface[{}]\tbase[{}]\tpos[{}]\tpos1[{}]".format(
self.surface, self.base, self.pos, self.pos1
)
class Chunk:
"""Containing information for Clause/phrase.
Args:
data (dict): A dictionary contains necessary information.
Attributes:
chunk_id (int): The number of clause chunk (Phrasennummer).
morphs List[Morph]: Morph (Morphem) list.
dst (int): The index of dependency target (Indexnummer der Kontaktklausel).
srcs (List[str]): The index list of dependency source. (Original-Klauselindexnummer).
"""
def __init__(self, chunk_id, dst):
self.id = int(chunk_id)
self.morphs = []
self.dst = int(dst)
self.srcs = []
def __repr__(self):
return "Chunk( id: {}, dst: {}, srcs: {}, morphs: {} )".format(
self.id, self.dst, self.srcs, self.morphs
)
def get_surface(self) -> str:
"""Concatenate morph surfaces in a chink.
Args:
chunk (Chunk): e.g. Chunk( id: 0, dst: 5, srcs: [], morphs: [Morph(ich), Morph(Ist)]
Return:
e.g. 'ich bin'
"""
morphs = self.morphs
res = ""
for morph in morphs:
if morph.pos != "Symbol":
res += morph.surface
return res
def validate_pos(self, pos: str) -> bool:
"""Return Ture if 'Substantiv' or 'Verb' in chunk's morphs. Otherwise, return False."""
morphs = self.morphs
return any([morph.pos == pos for morph in morphs])
def get_noun_masked_surface(self, mask: str) -> str:
"""Get masked surface.
Args:
mask (str): e.g. X or Y.
Returns:
str: 'ich bin' -> 'X ist'
'Mensch' -> 'Genannt Y.'
"""
morphs = self.morphs
res = ""
for morph in morphs:
if morph.pos == "Substantiv":
res += mask
elif morph.pos != "Symbol":
res += morph.surface
return res
def convert_sent_to_chunks(sent: List[str]) -> List[Morph]:
"""Extract word and convert to morph.
Args:
sent (List[str]): A sentence contains a word list.
e.g. sent:
['* 0 1D 0/1 0.000000',
'ich\t Substantiv,Gleichbedeutend,Allgemeines,*,*,*,ich,Wagahai,Wagahai',
'Ist\t Assistent,Hilfe,*,*,*,*,Ist,C.,Beeindruckend',
'* 1 -1D 0/2 0.000000',
'Katze\t Substantiv,Allgemeines,*,*,*,*,Katze,Katze,Katze',
'damit\t Hilfsverb,*,*,*,Besondere,Kontinuierlicher Typ,Ist,De,De',
'Gibt es\t Hilfsverb,*,*,*,Fünf Schritte, La Linie Al,Grundform,Gibt es,Al,Al',
'。\t Symbol,Phrase,*,*,*,*,。,。,。']
Parsing format:
e.g. "* 0 1D 0/1 0.000000"
|Säule|Bedeutung|
| :----: | :----------------------------------------------------------- |
| 1 |Die erste Spalte ist`*`.. Zeigt an, dass es sich um ein Ergebnis der Abhängigkeitsanalyse handelt.|
| 2 |Phrasennummer (Ganzzahl ab 0)|
| 3 |Kontaktnummer +`D` |
| 4 |Hauptadresse/Funktionswortposition und beliebig viele Identitätsspalten|
| 5 |Verlobungspunktzahl. Im Allgemeinen ist es umso einfacher, sich zu engagieren, je größer der Wert ist.|
Returns:
List[Chunk]: List of chunks.
"""
chunks = []
chunk = None
srcs = defaultdict(list)
for i, word in enumerate(sent):
if word[0] == "*":
# Add chunk to chunks
if chunk is not None:
chunks.append(chunk)
# eNw Chunk beggin
chunk_id = word.split(" ")[1]
dst = word.split(" ")[2].rstrip("D")
chunk = Chunk(chunk_id, dst)
srcs[dst].append(chunk_id) # Add target->source to mapping list
else: # Add Morch to chunk.morphs
features = word.split(",")
dic = {
"surface": features[0].split("\t")[0],
"base": features[6],
"pos": features[0].split("\t")[1],
"pos1": features[1],
}
chunk.morphs.append(Morph(dic))
if i == len(sent) - 1: # Add the last chunk
chunks.append(chunk)
# Add srcs to each chunk
for chunk in chunks:
chunk.srcs = list(srcs[chunk.id])
return chunks
class Sentence:
"""A sentence contains a list of chunks.
e.g. [Chunk( id: 0, dst: 5, srcs: [], morphs: [Morph(ich), Morph(Ist)] ),
Chunk( id: 1, dst: 2, srcs: [], morphs: [Morph(Hier), Morph(damit)] ),
Chunk( id: 2, dst: 3, srcs: ['1'], morphs: [Morph(Start), Morph(Hand)] ),
Chunk( id: 3, dst: 4, srcs: ['2'], morphs: [Morph(Mensch), Morph(Das)] ),
Chunk( id: 4, dst: 5, srcs: ['3'], morphs: [Morph(Ding), Morph(Zu)] ),
Chunk( id: 5, dst: -1, srcs: ['0', '4'], morphs: [Morph(Sie sehen), Morph(Ta), Morph(。)] )]
"""
def __init__(self, chunks):
self.chunks = chunks
self.root = None
def __repr__(self):
message = f"""Sentence:
{self.chunks}"""
return message
def get_root_chunk(self):
chunks = self.chunks
for chunk in chunks:
if chunk.dst == -1:
return chunk
def get_noun_path_to_root(self, src_chunk: Chunk) -> List[Chunk]:
"""Get path from noun Chunk to root Chunk.
e.g. [Chunk( id: 0, dst: 5, srcs: [], morphs: [Morph(ich), Morph(Ist)] ),
Chunk( id: 1, dst: 2, srcs: [], morphs: [Morph(Hier), Morph(damit)] ),
Chunk( id: 2, dst: 3, srcs: ['1'], morphs: [Morph(Start), Morph(Hand)] ),
Chunk( id: 3, dst: 4, srcs: ['2'], morphs: [Morph(Mensch), Morph(Das)] ),
Chunk( id: 4, dst: 5, srcs: ['3'], morphs: [Morph(Ding), Morph(Zu)] ),
Chunk( id: 5, dst: -1, srcs: ['0', '4'], morphs: [Morph(Sie sehen), Morph(Ta), Morph(。)] )]
Args:
src_chunk (Chunk): A Chunk. e.g. Chunk( id: 1, dst: 2, srcs: [], morphs: [Morph(Hier), Morph(damit)] ),
Returns:
List[Chunk]: The path from a chunk to root.
The path from 'Hier' to 'sah': Hier ->Mensch->Dinge-> sah
So we should get: ['Hier', 'Mensch', 'Dinge', 'sah']
"""
chunks = self.chunks
path = [src_chunk]
dst = src_chunk.dst
while dst != -1:
dst_chunk = chunks[dst]
if dst_chunk.validate_pos("Substantiv") and dst_chunk.dst != -1:
path.append(dst_chunk)
dst = chunks[dst].dst
return path
def get_path_between_nouns(self, src_chunk: Chunk, dst_chunk: Chunk) -> List[Chunk]:
"""[summary]

Example:
[Chunk( id: 0, dst: 5, srcs: [], morphs: [Morph(ich), Morph(Ist)] ),
Chunk( id: 1, dst: 2, srcs: [], morphs: [Morph(Hier), Morph(damit)] ),
Chunk( id: 2, dst: 3, srcs: ['1'], morphs: [Morph(Start), Morph(Hand)] ),
Chunk( id: 3, dst: 4, srcs: ['2'], morphs: [Morph(Mensch), Morph(Das)] ),
Chunk( id: 4, dst: 5, srcs: ['3'], morphs: [Morph(Ding), Morph(Zu)] ),
Chunk( id: 5, dst: -1, srcs: ['0', '4'], morphs: [Morph(Sie sehen), Morph(Ta), Morph(。)] )]
Two patterns:
Pattern 1 (Without root): save as a list.
1 -> 3 -> 4
1 -> 3
1 -> 4
3 -> 4
Pattern 2 (With root): save as a dict.
From 0 to 1:
0 | 1 -> 3 -> 4 | 5
From 0 to 3:
0 | 3 -> 4 | 5
From 0 to 4:
0 | 4 | 5
Pattern 1:
src_chunk (Chunk): e.g. Chunk( id: 1, dst: 2, srcs: [], morphs: [Morph(Hier), Morph(damit)] ),
dst_chunk (Chunk): e.g. Chunk( id: 4, dst: 5, srcs: ['3'], morphs: [Morph(Ding), Morph(Zu)] )
Path:
From 'Hier' to 'Dinge': Hier ->Mensch-> Dinge
Returns:
List[Chunk]: [Chunk(Mensch)]
Pattern 2:
src_chunk (Chunk): e.g. Chunk( id: 0, dst: 5, srcs: [], morphs: [Morph(ich), Morph(Ist)] ),
dst_chunk (Chunk): e.g. Chunk( id: 3, dst: 4, srcs: ['2'], morphs: [Morph(Mensch), Morph(Das)] )
Path:
From Chunk(ich bin) to Chunk(Mensch):
0 | 3 -> 4 | 5
- Chunk(ich bin) -> Chunk(sah)
- Chunk(Mensch) -> Chunk(Dinge) -> Chunk(sah)
Returns:
Dict: {'src_to_root': [Chunk(ich bin)],
'dst_to_root': [Chunk(Mensch), Chunk(Dinge)]}
"""
chunks = self.chunks
pattern1 = []
pattern2 = {"src_to_root": [], "dst_to_root": []}
if src_chunk.dst == dst_chunk.id:
return pattern1
current_src_chunk = chunks[src_chunk.dst]
while current_src_chunk.dst != dst_chunk.id:
# Pattern 1
if current_src_chunk.validate_pos("Substantiv"):
pattern1.append(src_chunk)
# Pattern 2
if current_src_chunk.dst == -1:
pattern2["src_to_root"] = self.get_noun_path_to_root(src_chunk)
pattern2["dst_to_root"] = self.get_noun_path_to_root(dst_chunk)
return pattern2
current_src_chunk = chunks[current_src_chunk.dst]
return pattern1
def write_to_file(sents: List[dict], path: str) -> None:
"""Write to file.
Args:
sents ([type]):
e.g. [[['ich bin', 'Sei eine Katze']],
[['Name ist', 'Nein']],
[['wo', 'Wurde geboren', 'Verwende nicht'], ['Ich habe eine Ahnung', 'Verwende nicht']]]
"""
# convert_frame_to_text
lines = []
for sent in sents:
for chunk in sent:
lines.append(" -> ".join(chunk))
# write_to_file
with open(path, "w") as f:
for line in lines:
f.write(f"{line}\n")
def get_pattern1_text(src_chunk, path_chunks, dst_chunk):
"""
Pattern 1:
src_chunk (Chunk): e.g. Chunk( id: 1, dst: 2, srcs: [], morphs: [Morph(Hier), Morph(damit)] ),
dst_chunk (Chunk): e.g. Chunk( id: 4, dst: 5, srcs: ['3'], morphs: [Morph(Ding), Morph(Zu)] )
Path:
From 'Hier' to 'Dinge': Hier ->Mensch-> Dinge
path_chunks:
List[Chunk]: [Chunk(Mensch)]
"""
path = []
path.append(src_chunk.get_noun_masked_surface("X"))
for path_chunk in path_chunks:
path.append(path_chunk.get_surface())
path.append(dst_chunk.get_noun_masked_surface("Y"))
return " -> ".join(path)
def get_pattern2_text(path_chunks, sent):
"""
Path:
From Chunk(ich bin) to Chunk(Mensch):
0 | 3 -> 4 | 5
- Chunk(ich bin) -> Chunk(sah)
- Chunk(Mensch) -> Chunk(Dinge) -> Chunk(sah)
path_chunks:
Dict: {'src_to_root': [Chunk(ich bin)],
'dst_to_root': [Chunk(Mensch), Chunk(Dinge)]}
"""
path_text = "{} | {} | {}"
src_path = []
for i, chunk in enumerate(path_chunks["src_to_root"]):
if i == 0:
src_path.append(chunk.get_noun_masked_surface("X"))
else:
src_path.append(chunk.get_surface())
src_text = " -> ".join(src_path)
dst_path = []
for i, chunk in enumerate(path_chunks["dst_to_root"]):
if i == 0:
dst_path.append(chunk.get_noun_masked_surface("Y"))
else:
dst_path.append(chunk.get_surface())
dst_text = " -> ".join(dst_path)
root_chunk = sent.get_root_chunk()
root_text = root_chunk.get_surface()
return path_text.format(src_text, dst_text, root_text)
def get_paths(sent_chunks: List[Sentence]):
paths = []
for sent_chunk in sent_chunks:
sent = Sentence(sent_chunk)
chunks = sent.chunks
for i, src_chunk in enumerate(chunks):
if src_chunk.validate_pos("Substantiv") and i + 1 < len(chunks):
for j, dst_chunk in enumerate(chunks[i + 1 :]):
if dst_chunk.validate_pos("Substantiv"):
path_chunks = sent.get_path_between_nouns(src_chunk, dst_chunk)
if isinstance(path_chunks, list): # Pattern 1
paths.append(
get_pattern1_text(src_chunk, path_chunks, dst_chunk)
)
if isinstance(path_chunks, dict): # Pattern 2
paths.append(get_pattern2_text(path_chunks, sent))
return paths
fpath = "neko.txt.cabocha"
sentences = read_file(fpath)
sent_chunks = [convert_sent_to_chunks(sent) for sent in sentences] # ans41
# ans49
paths = get_paths(sent_chunks)
for p in paths[:20]:
print(p)
#X ist|In Y.->Mensch->Dinge|sah
#X ist|Genannt Y.->Dinge|sah
#X ist|Y.|sah
#In X.->Genannt Y.
#In X.->Y.
#X genannt->Y.
Recommended Posts