[PYTHON] So zeichnen Sie interaktiv eine Pipeline für maschinelles Lernen mit scikit-learn und speichern sie in HTML
In diesem Artikel werde ich die Implementierung der ab Version 0.23 von scicit-learn installierten interaktiven Pipeline-Bestätigung sowie deren Speicherung und Verwendung als HTML erläutern.
Umgebung
- scikit-learn==0.23.2
- Google Colaboratory
Der Implementierungscode für diesen Artikel finden Sie hier https://github.com/YutaroOgawa/Qiita/tree/master/sklearn
Implementierung
[1] Versionsaktualisierung
Erstens ist die Version von scikit-learn von Google Colaboratory im September 2020 Version 0.22. Aktualisieren Sie sie daher auf Version 0.23.
!pip install scikit-learn==0.23.2
Führen Sie nach dem Update mit pip "Runtime" -> "Restart runtime" von Google Colaboratory aus. Starten Sie die Laufzeit neu. (Dies ist die neue Version 0.23, die Scikit-Learn mit pip integriert hat.)
[2] Pipelinebau
Beispielsweise wurden das Vorverarbeitungs- und das maschinelle Lernmodell wie folgt kombiniert: Erstellen Sie eine ** Pipeline für maschinelles Lernen **.
[Notwendigen Import durchführen]
python
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import OneHotEncoder, StandardScaler
from sklearn.impute import SimpleImputer
from sklearn.compose import make_column_transformer
from sklearn.linear_model import LogisticRegression
[Erstellen Sie eine Pipeline]
```python```
#Vorverarbeitung numerischer Daten (Standardisierung durch Ergänzung fehlender Werte mit Medianwert)
num_proc = make_pipeline(SimpleImputer(strategy='median'), StandardScaler())
#Vorverarbeitung von Kategoriedaten (für fehlende Werte"misssing"Substitution abgeschlossen, eine Hot-Codierung)
cat_proc = make_pipeline(
SimpleImputer(strategy='constant', fill_value='missing'),
OneHotEncoder(handle_unknown='ignore'))
#Erstellen Sie eine Vorverarbeitungsklasse
preprocessor = make_column_transformer((num_proc, ('feat1', 'feat3')),
(cat_proc, ('feat0', 'feat2')))
#Kombinieren Sie Vorverarbeitungs- und maschinelles Lernmodelle in einer Pipeline
clf = make_pipeline(preprocessor, LogisticRegression())
[3] Interaktive Visualisierung der Pipeline
Um die Pipeline interaktiv zu visualisieren, ist es einfach:
sklearn.set_config(display="diagram")
Einfach hinzufügen.
[Interaktive Visualisierung]
python
Einstellungen zum Anzeigen der Pipeline
from sklearn import set_config
set_config(display="diagram")
Zeichnung
clf
Anschließend wird die Pipeline in der Ergebnisspalte von JupyterNotebook (Google Colabortory) gezeichnet (siehe unten).
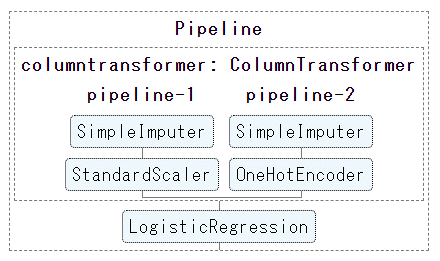
Klicken Sie auf jedes Element in diesem Pipeline-Diagramm
Das Bild ändert sich interaktiv und zeigt die detaillierten Einstellungen für dieses Element an.
(Die folgende Abbildung zeigt die detaillierte Bestätigung der Methode zur Verarbeitung fehlender Werte für die Spaltenvorverarbeitung: Pipeline.-Klicken Sie auf 2 Simple Impactor)

##So speichern Sie die Pipeline als HTML
Wie Sie in den Kommentaren erwähnt haben, können Sie diese interaktive Pipeline als HTML speichern.
"Es ist ein bisschen, wenn es nur auf Jupyter Notebook funktioniert ..."
Ich dachte, es sind also sehr nette Informationen.
@Vielen Dank an DataSkywalker.
Schließlich als Implementierung,
```python
from sklearn.utils import estimator_html_repr
with open('my_estimator.html', 'w') as f:
f.write(estimator_html_repr(clf))
Ausführen. Dann meine_estimator.Der HTML-Code der interaktiven Pipeline wird als HTML gespeichert.
Mit Google Colaboratory
# Download von Google Colaboratory
from google.colab import files
files.download('my_estimator.html')
Indem ich meine laufen lasse_estimator.Sie können HTML herunterladen (Die HTML-Datei enthielt den CSS-Stil und bestand aus etwa 300 Zeilen).
Als Material zur interaktiven Erklärung der Pipeline Es scheint, dass Sie HTML in Dokumente usw. einfügen können.
Sie können es als Link in die MD-Datei einfügen oder die MD-Datei zwangsweise in HTML konvertieren und dann kombinieren. (Es ist schwierig, HTML zu lesen, da es in der MD-Datei enthalten ist ...?)

Alle Dateien hier sind auch hier platziert https://github.com/YutaroOgawa/Qiita/tree/master/sklearn
##Zusammenfassung
scikit-Lerne Version v0.23 oder höher
sklearn.set_config(display="diagram")Einfach hinzufügen
Sie können Ihre Pipeline interaktiv visualisieren (und als HTML speichern).
Bitte versuchen Sie es ♪
###Bemerkungen
**【Schriftsteller】**Dentsu Internationaler Informationsdienst (ISID)AI Transformation CenterEntwicklung Gr Yutaro Ogawa (Hauptbuch)"Lerne beim Machen!Development Deep Learning von PyTorch ",Andere"DetailsderSelbsteinführung")
【Twitter】 Ich konzentriere mich auf IT / KI und Business / Management und versende Artikel, die ich interessant finde, und Eindrücke von neuen Büchern, die ich kürzlich gelesen habe. Wenn Sie Informationen zu diesen Feldern sammeln möchten, folgen Sie uns bitte ♪ (Es gibt viele Informationen aus Übersee)
[Andere] Das von mir geleitete "AI Transformation Center Development Team" sucht Mitglieder. Wenn Sie interessiert sind,Diese SeiteWir freuen uns auf Ihre Bewerbung.
[Sokumen-Kun] Wenn Sie sich plötzlich bewerben möchten, haben wir ein ungezwungenes Interview mit "Sokumen-kun". Bitte benutzen Sie dies auch ♪ https://sokumenkun.com/2020/08/17/yutaro-ogawa/
[Haftungsausschluss] Der Inhalt dieses Artikels ist die Meinung des Autors./Es ist eine Übermittlung, keine offizielle Ansicht des Unternehmens, zu dem der Autor gehört.
(Referenz) https://scikit-learn.org/stable/auto_examples/release_highlights/plot_release_highlights_0_23_0.html https://towardsdatascience.com/9-things-you-should-know-about-scikit-learn-0-23-9426d8e1772c
Recommended Posts