[PYTHON] Ich versuchte das Weckwort zu erkennen
Was ging
Frohes neues Jahr. Dies ist eine Aufzeichnung meiner Hobby-Studie, die ich während meiner Neujahrs-Heimkehr besucht habe.
Wenn Sie einen Sprachassistenten verwenden, ist es normalerweise in Ordnung, mit einem Weckwort wie Google anzurufen. Als ich von Dr. Andrew Ng Deep Learning Specialization (Coursera) erhielt Es gab ein Problem bei der Implementierung eines Modells, das Weckstimmen erkennt.
Dieser Artikel ist eine Überprüfung des oben genannten Kurses, Dies ist eine Aufzeichnung der Generierung von Trainingsdaten basierend auf den aufgezeichneten Daten Ihrer eigenen Stimme und des Trainings mit dem implementierten Modell. Es gibt wenig Daten und die Ergebnisse sind einfach, aber irgendwann möchte ich die Daten erhöhen und das Modell zum Experimentieren verbessern.
Deep Learning Specialization ist umfangreich, aber leicht zu verstehen. Ich empfehle es, weil ich es schon als Anfänger verstehen konnte.
Ausführungsumgebung
- Google Colaboratory
- Laufzeittyp: Python 3
- Hardwarebeschleuniger: GPU
- Tensorflow ver 1.15.0
Trainingsdaten erstellen
Material
- Hintergrundgeräusche .wav 2 Arten --Stimmaufnahme .wav ――Zwei Arten von Aufnahmen Ihrer eigenen Stimme mit der Aufschrift "TEST" (Grundstimme, Rückstimme)
Inhalt
- Definierte eine Funktion zum Generieren einer großen Menge von Trainingsdaten aus einer kleinen Menge von Material
- Ändern Sie nach dem Zufallsprinzip die Lautstärke, den Ort, an dem die Stimme kombiniert wird, und die Zahl (1 bis 3), um eine Variation zu gewährleisten
--Was du bekommst
- Eingabedaten X: Spektrogramm der synthetischen Schallquelle für 10 Sekunden (Anzahl der Zeitrahmen, Anzahl der Frequenzbereiche)
- Korrigieren Sie die Bezeichnung y: 0 oder 1 Flag ――Das Label ca. 40 ms nach dem Teil, in dem die Stimme synthetisiert wurde, wurde auf 1 gesetzt. Der Rest ist 0
Generierte Daten
- Die obige Abbildung ist ein Spektrogramm, das Eingabedaten enthält (vertikal: Frequenz [Hz] horizontal: Zeit). ――Die Farbe des entsprechenden Teils hat sich aufgrund der Zusammensetzung der Stimme geändert. ――Diese Farbe zeigt die Stärke der Frequenzkomponente der Stimme an.
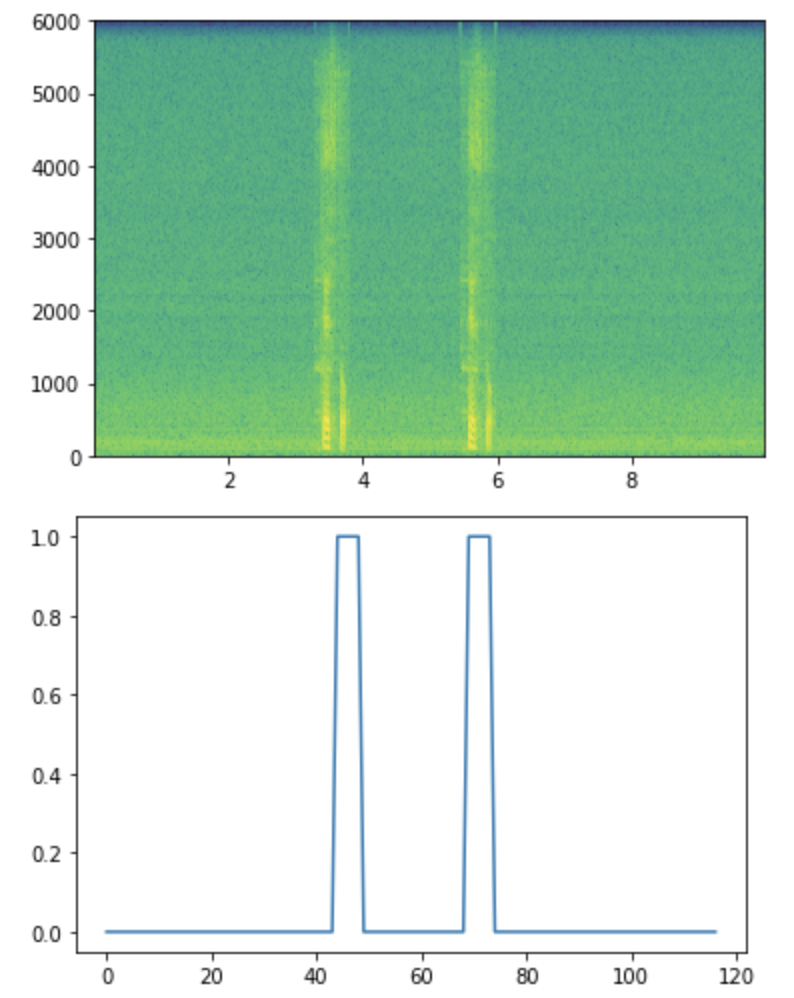
- Die folgende Abbildung zeigt das generierte richtige Antwortetikett.
- Die Bezeichnung des kombinierten Teils wird in 1 geändert.
- Versuchen Sie, dies aus den Eingabedaten abzuleiten
Funktion zur Erzeugung
Eine für die Datengenerierung definierte Funktion
- make_train_sound(background, target, length, dumpwav=False)
- Generieren Sie eine synthetische Klangquelle und ein korrektes Antwortetikett
- make_train_pattern(pattern_num)
- Tippen Sie mehrmals auf make_train_sound, um Trainingsdaten zu generieren
BACKGROUND_DIR = '/tmp/background'
VOICE_DIR = '/tmp/voice'
RATE = 12000
Ty = 117
TRAIN_DATA_LENGTH = int(10*RATE)
def make_train_sound(background, target, length, dumpwav=False):
"""
arguments
background: background noise data
target: target sound data (will be added to background noise)
length: sample length
dumpwav: make wav data
output
X: spectrogram data ( shape = (NFFT, frames))
y: flag data (shap)
"""
NFFT = 512
FLAG_DULATION = 5
TARGET_SYNTH_NUM = np.random.randint(1,high=3)
# initialize
train_sound = np.copy(background[:length])
gain = np.random.random()
train_sound *= gain
target_length = len(target)
y_size = Ty
y = [0 for i in range(y_size)]
# Synthesize
for num in range(TARGET_SYNTH_NUM):
# Decide where to add target into background noise
range_start = int(length*num/TARGET_SYNTH_NUM)
range_end = int(length*(num+1)/TARGET_SYNTH_NUM)
synth_start_sample = np.random.randint(range_start, high=( range_end - target_length - FLAG_DULATION*(NFFT) ))
# Add
train_sound[synth_start_sample:synth_start_sample + target_length] += np.copy(target)
# get Spectrogram
specgram, freqs, t, img = plt.specgram(train_sound,NFFT=NFFT, Fs=RATE, noverlap=int(NFFT/2), scale="dB")
X = specgram # (freqs, time)
# Labeling
target_end_sec = (synth_start_sample+target_length)/RATE
train_sound_sec = length/RATE
flag_start_sample = int( ( target_end_sec / train_sound_sec ) * y_size)
flag_end_sample = flag_start_sample+FLAG_DULATION
if y_size <= flag_end_sample:
over_length = flag_end_sample-y_size
flag_end_sample -= over_length
duration = FLAG_DULATION - over_length
else:
duration = FLAG_DULATION
y[flag_start_sample:flag_end_sample] = [1 for i in range(duration)]
if dumpwav:
scipy.io.wavfile.write("train.wav", RATE, train_sound)
y = np.array(y)
return (X, y)
def make_train_pattern(pattern_num):
"""
return list of training data
[(X_1, y_1), (X_2, y_2) ... ]
arguments
pattern_num: Number of patterns (X, y)
output:
train_pattern: X input_data, y labels
[(X_1, y_1), (X_2, y_2) ... ]
"""
bg_items = get_item_list(BACKGROUND_DIR)
voice_items = get_item_list(VOICE_DIR)
train_pattern = []
for i in range(pattern_num):
item_no = get_item_no(bg_items)
fs, bgdata = read(bg_items[item_no])
item_no = get_item_no(voice_items)
fs, voicedata = read(voice_items[item_no])
pattern = make_train_sound(bgdata, voicedata, TRAIN_DATA_LENGTH, dumpwav=False)
train_pattern.append(pattern)
return train_pattern
- Mit diesen wurden 1500 Daten generiert und für Zug, Validierung und Test getrennt.
- Seit 1500 oder mehr haben die RAM von Colab überschritten und bisher gestoppt
- Um die Eingabedaten als Zeitreihendaten zu behandeln, wurde die Form geändert (Anzahl der Zeitrahmen, Anzahl der Frequenzbereiche).
#Daten erstellen
train_patterns = make_train_pattern(1500)
#Eingabe vom erhaltenen Taple,Teilen Sie in richtige Antwortetiketten
X = []
y = []
for t in train_patterns:
X.append(t[0].T) # (Time, Freq)
y.append(t[1])
X = np.array(X)
y = np.array(y)[:,:,np.newaxis]
train_patterns = None
# training, validation,Zum Test teilen
train_num = int(0.7*len(X))
val_num = int(0.2*len(X))
test_num = int(0.1*len(X))
X_train = X[:train_num]
y_train = y[:train_num]
X_validation = X[train_num:train_num+val_num]
y_validation = y[train_num:train_num+val_num]
X_test = X[train_num+val_num:]
y_test = y[train_num+val_num:]
train_data_shape = X_train[0].shape
Lernmodell
- Definierte ein Modell mit einer Schicht CNN und zwei Schichten LSTM. --input_shape wird auf die Größe der Trainingsdaten eingestellt (Spektrogramm)
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_6 (InputLayer) (None, 467, 257) 0
_________________________________________________________________
conv1d_6 (Conv1D) (None, 117, 196) 755776
_________________________________________________________________
batch_normalization_16 (Batc (None, 117, 196) 784
_________________________________________________________________
activation_6 (Activation) (None, 117, 196) 0
_________________________________________________________________
dropout_16 (Dropout) (None, 117, 196) 0
_________________________________________________________________
cu_dnnlstm_11 (CuDNNLSTM) (None, 117, 128) 166912
_________________________________________________________________
batch_normalization_17 (Batc (None, 117, 128) 512
_________________________________________________________________
dropout_17 (Dropout) (None, 117, 128) 0
_________________________________________________________________
cu_dnnlstm_12 (CuDNNLSTM) (None, 117, 128) 132096
_________________________________________________________________
batch_normalization_18 (Batc (None, 117, 128) 512
_________________________________________________________________
dropout_18 (Dropout) (None, 117, 128) 0
_________________________________________________________________
time_distributed_6 (TimeDist (None, 117, 1) 129
=================================================================
Total params: 1,056,721
Trainable params: 1,055,817
Non-trainable params: 904
_________________________________________________________________
- Es scheint, dass Sie die vollständig verbundene Ebene mithilfe von TimeDistributed auf die Zeitreihen anwenden können.
- Die vollständig verbundene Schicht des Aktivierungsfunktionssigmoid wird in der letzten Schicht so eingestellt, dass die Wahrscheinlichkeit ausgegeben wird.
X = TimeDistributed(Dense(1, activation='sigmoid'))(X)
--CuDNNL STM wurde verwendet, um die Geschwindigkeit zu priorisieren
- Ich habe es geändert, weil der Fortschritt beim Training mit normalem LSTM langsam war --CuDNNLSTM funktionierte bei Verwendung der Tensorflow ver2.0-Serie nicht mit Colab
- Ist es möglich, es durch Importieren aus tf.compat.v1.keras.layers zu verwenden?
- Dieses Mal habe ich es mit Version 1.15.0 versucht, um Zeit zu sparen.
Lernergebnis
――Wir haben mit dem Lernen unter den folgenden Bedingungen fortgefahren
detector = model(train_data_shape)
optimizer = Adam(lr=0.0001, beta_1=0.9, beta_2=0.999, decay=0.01)
detector.compile(loss='binary_crossentropy', optimizer=optimizer, metrics=["accuracy"])
history = detector.fit(X_train, y_train, batch_size=10,
epochs=500, verbose=1, validation_data=(X_validation, y_validation))
――Das Lernen dauerte ungefähr drei Sekunden pro Epoche. Hohe Geschwindigkeit statt CuDNNLSTM-Effekt
Epoch 1/500
1050/1050 [==============================] - 5s 5ms/step - loss: 0.6187 - acc: 0.8056 - val_loss: 14.2785 - val_acc: 0.0648
Epoch 2/500
1050/1050 [==============================] - 3s 3ms/step - loss: 0.5623 - acc: 0.8926 - val_loss: 14.1574 - val_acc: 0.0733
――Es ist ein Übergang des Lernens. Es schien, dass ich ungefähr 200 Epochen genug lernen konnte
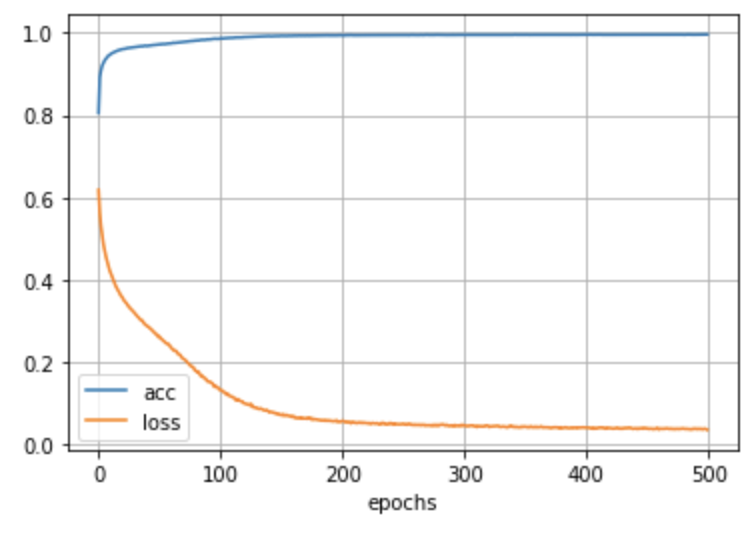
――Die richtige Antwortrate war selbst in TEST-Daten hoch.
detector.evaluate(X_test, y_test)
150/150 [==============================] - 0s 873us/step
[0.018092377881209057, 0.9983475764592489]
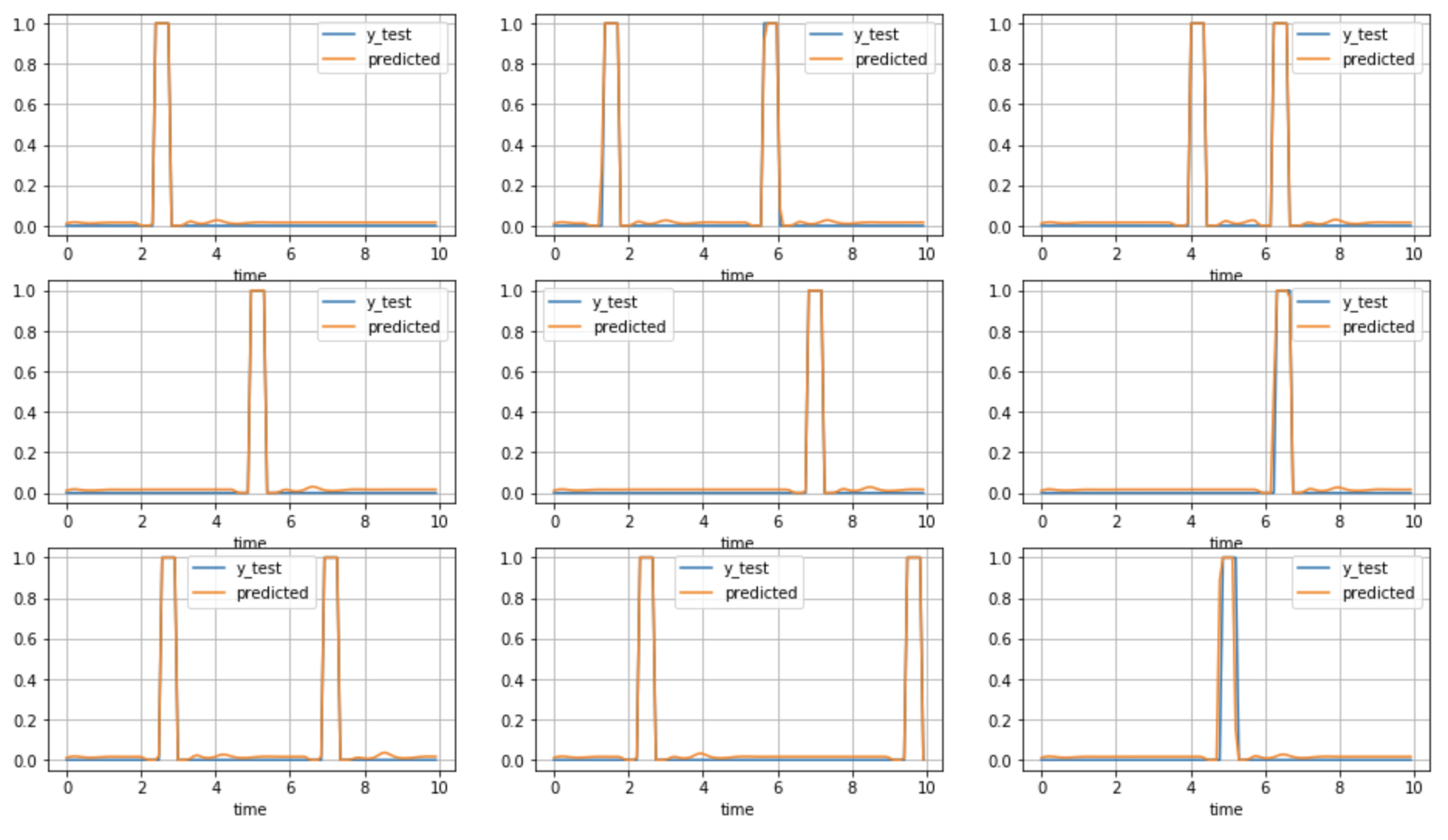
- Es schien, dass die Vorhersage im Vergleich zur korrekten Bezeichnung der TEST-Daten fast genau war (blau: korrekt orange: Vorhersage).
――Es ist zu vorhersehbar und etwas stimmt nicht
abschließend
――Ich habe mein Verständnis für den Fluss von der Datengenerierung zum Lernen vertieft. ――Es wurde ein einfaches Modell, das nur die Stimme erkennt, aber ich habe gelernt
- Die Menge und Variation der Trainingsdaten war unzureichend
- Da die Stimmdaten nicht variieren, scheint sie auf andere Wörter zu reagieren
- Vielleicht erkennt es nur den Teil, den Sie synthetisieren
――In Zukunft wäre es meiner Meinung nach gut, wenn wir das Modell und die Daten für das Lernen verbessern und die Ergebnisse zur Erstellung einer App verwenden könnten.
Vielen Dank. Ich wünsche Ihnen auch dieses Jahr ein schönes Jahr.
Referenz
Recommended Posts