[PYTHON] Ich habe versucht, eine Super-Resolution-Methode / ESPCN zu erstellen
Überblick
Dieses Mal habe ich ESPCN (Efficient Sub-Pixel Convolutional Neural Network) erstellt, eine der Methoden mit Superauflösung, daher werde ich es als Zusammenfassung veröffentlichen. Klicken Sie hier, um das Originalpapier zu erhalten. html)
Inhaltsverzeichnis
- Zuallererst
- Was ist ESPCN?
- PC-Umgebung
- Codebeschreibung
- Am Ende
1. Zuallererst
Super-Resolution ist eine Technologie, die die Auflösung von Bildern mit niedriger Auflösung und bewegten Bildern verbessert, und ESPCN ist eine 2016 vorgeschlagene Methode. (SRCNN, das als erste Deeplearning-Methode erwähnt wird, ist übrigens 2014) SRCNN war eine Methode zur Verbesserung der Auflösung, indem sie mit der vorhandenen Vergrößerungsmethode wie der bikubischen Methode kombiniert wurde. In diesem ESPCN wird die Vergrößerungsphase jedoch in das Deeplearning-Modell eingeführt und kann bei jeder Vergrößerung vergrößert werden. Ich werde. Dieses Mal habe ich diese Methode mit Python erstellt, daher möchte ich den Code einführen. Der vollständige Code ist auch auf GitHub verfügbar. Überprüfen Sie ihn daher dort. https://github.com/nekononekomori/espcn_keras
2. Was ist ESPCN?
ESPCN ist eine Methode zur Verbesserung der Auflösung durch Einführung von Subpixel Convolution (Pixel Shuffle) in das Deeplearning-Modell. Da die Hauptsache darin besteht, den Code zu veröffentlichen, werde ich die ausführliche Erklärung weglassen, aber ich werde die Site veröffentlichen, die ESPCN erklärt. https://buildersbox.corp-sansan.com/entry/2019/03/20/110000 https://qiita.com/oki_uta_aiota/items/74c056718e69627859c0 https://qiita.com/jiny2001/items/e2175b52013bf655d617
3. PC-Umgebung
cpu : intel corei7 8th Gen gpu : NVIDIA GeForce RTX 1080ti os : ubuntu 20.04
4. Codebeschreibung
Wie Sie aus GitHub sehen können, besteht es hauptsächlich aus drei Codes. ・ Datacreate.py → Programm zur Datensatzgenerierung ・ Model.py → ESPCN-Programm ・ Main.py → Ausführungsprogramm Ich habe eine Funktion mit datacreate.py und model.py erstellt und mit main.py ausgeführt.
Beschreibung von datacreate.py
datacreate.py
import cv2
import os
import random
import glob
import numpy as np
import tensorflow as tf
#Ein Programm, das eine beliebige Anzahl von Frames ausschneidet
def save_frame(path, #Pfad der Datei, die die Daten enthält
data_number, #Anzahl der Fotos, die aus einem Bild ausgeschnitten werden sollen
cut_height, #Speichergröße(Vertikal)(Geringe Bildqualität)
cut_width, #Speichergröße(Seite)(Geringe Bildqualität)
mag, #Vergrößerung
ext='jpg'):
#Generieren Sie eine Liste von Datensätzen
low_data_list = []
high_data_list = []
path = path + "/*"
files = glob.glob(path)
for img in files:
img = cv2.imread(img, cv2.IMREAD_GRAYSCALE)
H, W = img.shape
cut_height_mag = cut_height * mag
cut_width_mag = cut_width * mag
if cut_height_mag > H or cut_width_mag > W:
return
for q in range(data_number):
ram_h = random.randint(0, H - cut_height_mag)
ram_w = random.randint(0, W - cut_width_mag)
cut_img = img[ram_h : ram_h + cut_height_mag, ram_w: ram_w + cut_width_mag]
#Schrumpft nach dem Verwischen mit dem Usian-Filter
img1 = cv2.GaussianBlur(img, (5, 5), 0)
img2 = img1[ram_h : ram_h + cut_height_mag, ram_w: ram_w + cut_width_mag]
img3 = cv2.resize(img2, (cut_height, cut_width))
high_data_list.append(cut_img)
low_data_list.append(img3)
#numpy → tensor +Normalisierung
low_data_list = tf.convert_to_tensor(low_data_list, np.float32)
high_data_list = tf.convert_to_tensor(high_data_list, np.float32)
low_data_list /= 255
high_data_list /= 255
return low_data_list, high_data_list
Dies ist das Programm, das den Datensatz generiert.
def save_frame(path, #Pfad der Datei, die die Daten enthält
data_number, #Anzahl der Fotos, die aus einem Bild ausgeschnitten werden sollen
cut_height, #Speichergröße(Vertikal)(Niedrige Auflösung)
cut_width, #Speichergröße(Seite)(Niedrige Auflösung)
mag, #Vergrößerung
ext='jpg'):
Hier ist die Definition der Funktion. Wie ich im Kommentar geschrieben habe, Pfad ist der Pfad des Ordners. (Wenn Sie beispielsweise ein Foto in einem Ordner mit dem Namen file haben, geben Sie "./file" ein.) data_number schneidet mehrere Fotos aus und dreht die Daten. cut_height und cut_wedth sind Bildgrößen mit niedriger Auflösung. Das endgültige Ausgabeergebnis ist der Wert multipliziert mit dem Vergrößerungsmagazin. Wenn (cut_height = 300, cut_width = 300, mag = 300, Das Ergebnis ist ein Bild mit einer Größe von 900 * 900. )
path = path + "/*"
files = glob.glob(path)
Dies ist eine Liste aller Fotos in der Datei.
for img in files:
img = cv2.imread(img, cv2.IMREAD_GRAYSCALE)
H, W = img.shape
cut_height_mag = cut_height * mag
cut_width_mag = cut_width * mag
if cut_height_mag > H or cut_width_mag > W:
return
for q in range(data_number):
ram_h = random.randint(0, H - cut_height_mag)
ram_w = random.randint(0, W - cut_width_mag)
cut_img = img[ram_h : ram_h + cut_height_mag, ram_w: ram_w + cut_width_mag]
#Nach dem Verwischen mit dem Gaußschen Filter schrumpfen
img1 = cv2.GaussianBlur(img, (5, 5), 0)
img2 = img1[ram_h : ram_h + cut_height_mag, ram_w: ram_w + cut_width_mag]
img3 = cv2.resize(img2, (cut_height, cut_width))
high_data_list.append(cut_img)
low_data_list.append(img3)
Hier nehme ich die zuvor aufgelisteten Fotos einzeln heraus und schneide so viele wie die Anzahl der Datennummern aus. Ich verwende random.randint, weil ich es zufällig schneiden möchte. Dann wird es mit einem Gaußschen Filter unscharf, um ein Bild mit niedriger Auflösung zu erzeugen. Schließlich habe ich es der Liste mit Anhängen hinzugefügt.
#numpy → tensor +Normalisierung
low_data_list = tf.convert_to_tensor(low_data_list, np.float32)
high_data_list = tf.convert_to_tensor(high_data_list, np.float32)
low_data_list /= 255
high_data_list /= 255
return low_data_list, high_data_list
Hier ist es in Keras und Tensorflow erforderlich, anstelle eines Numpy-Arrays in einen Tensor zu konvertieren, sodass eine Konvertierung durchgeführt wird. Gleichzeitig erfolgt hier die Normalisierung.
Schließlich endet die Funktion mit einer Liste mit Bildern mit niedriger Auflösung und einer Liste mit Bildern mit hoher Auflösung.
Beschreibung von main.py.
main.py
import tensorflow as tf
from tensorflow.python.keras.models import Model
from tensorflow.python.keras.layers import Conv2D, Input, Lambda
def ESPCN(upsampling_scale):
input_shape = Input((None, None, 1))
conv2d_0 = Conv2D(filters = 64,
kernel_size = (5, 5),
padding = "same",
activation = "relu",
)(input_shape)
conv2d_1 = Conv2D(filters = 32,
kernel_size = (3, 3),
padding = "same",
activation = "relu",
)(conv2d_0)
conv2d_2 = Conv2D(filters = upsampling_scale ** 2,
kernel_size = (3, 3),
padding = "same",
)(conv2d_1)
pixel_shuffle = Lambda(lambda z: tf.nn.depth_to_space(z, upsampling_scale))(conv2d_2)
model = Model(inputs = input_shape, outputs = [pixel_shuffle])
model.summary()
return model
Wie erwartet ist es kurz.
Wenn ich mir das ESPCN-Papier anschaue, schreibe ich übrigens, dass es eine solche Struktur hat.
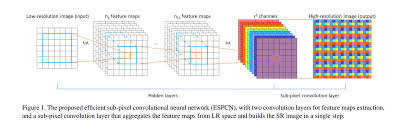 Klicken Sie hier für Details zur Faltungsschicht → Keras-Dokumentation
pixel_shuffle ist in Keras nicht standardmäßig installiert, daher habe ich es durch Lambda ersetzt.
Lambbda steht für Erweiterung, da Sie jeden Ausdruck in das Modell integrieren können.
Lambda-Dokumentation → https://keras.io/ja/layers/core/#lambda
Tensorflow-Dokumentation → https://www.tensorflow.org/api_docs/python/tf/nn/depth_to_space
Klicken Sie hier für Details zur Faltungsschicht → Keras-Dokumentation
pixel_shuffle ist in Keras nicht standardmäßig installiert, daher habe ich es durch Lambda ersetzt.
Lambbda steht für Erweiterung, da Sie jeden Ausdruck in das Modell integrieren können.
Lambda-Dokumentation → https://keras.io/ja/layers/core/#lambda
Tensorflow-Dokumentation → https://www.tensorflow.org/api_docs/python/tf/nn/depth_to_space
Hier scheint es verschiedene Möglichkeiten zu geben, mit dem Pixel-Shuffle umzugehen.
Beschreibung von model.py
model.py
import model
import data_create
import argparse
import os
import cv2
import numpy as np
import tensorflow as tf
if __name__ == "__main__":
def psnr(y_true, y_pred):
return tf.image.psnr(y_true, y_pred, 1, name=None)
train_height = 17
train_width = 17
test_height = 200
test_width = 200
mag = 3.0
cut_traindata_num = 10
cut_testdata_num = 1
train_file_path = "../photo_data/DIV2K_train_HR" #Ordner mit Fotos
test_file_path = "../photo_data/DIV2K_valid_HR" #Ordner mit Fotos
BATSH_SIZE = 256
EPOCHS = 1000
opt = tf.keras.optimizers.Adam(learning_rate=0.0001)
parser = argparse.ArgumentParser()
parser.add_argument('--mode', type=str, default='espcn', help='espcn, evaluate')
args = parser.parse_args()
if args.mode == "espcn":
train_x, train_y = data_create.save_frame(train_file_path, #Pfad des zu beschneidenden Bildes
cut_traindata_num, #Anzahl der generierten Datensätze
train_height, #Speichergröße
train_width,
mag) #Vergrößerung
model = model.ESPCN(mag)
model.compile(loss = "mean_squared_error",
optimizer = opt,
metrics = [psnr])
#https://keras.io/ja/getting-started/faq/
model.fit(train_x,
train_y,
epochs = EPOCHS)
model.save("espcn_model.h5")
elif args.mode == "evaluate":
path = "espcn_model"
exp = ".h5"
new_model = tf.keras.models.load_model(path + exp, custom_objects={'psnr':psnr})
new_model.summary()
test_x, test_y = data_create.save_frame(test_file_path, #Pfad des zu beschneidenden Bildes
cut_testdata_num, #Anzahl der generierten Datensätze
test_height, #Speichergröße
test_width,
mag) #Vergrößerung
print(len(test_x))
pred = new_model.predict(test_x)
path = "resurt_" + path
os.makedirs(path, exist_ok = True)
path = path + "/"
for i in range(10):
ps = psnr(tf.reshape(test_y[i], [test_height, test_width, 1]), pred[i])
print("psnr:{}".format(ps))
before_res = tf.keras.preprocessing.image.array_to_img(tf.reshape(test_x[i], [int(test_height / mag), int(test_width / mag), 1]))
change_res = tf.keras.preprocessing.image.array_to_img(tf.reshape(test_y[i], [test_height, test_width, 1]))
y_pred = tf.keras.preprocessing.image.array_to_img(pred[i])
before_res.save(path + "low_" + str(i) + ".jpg ")
change_res.save(path + "high_" + str(i) + ".jpg ")
y_pred.save(path + "pred_" + str(i) + ".jpg ")
else:
raise Exception("Unknow --mode")
Die Hauptleitung ist ziemlich lang, aber ich habe den Eindruck, dass ich mehr tun kann, wenn ich sie verkürzen kann. Im Folgenden werde ich den Inhalt erklären.
import model
import data_create
import argparse
import os
import cv2
import numpy as np
import tensorflow as tf
Hier laden wir eine Funktion oder eine andere Datei in dasselbe Verzeichnis. datacreate.py, model.py und main.py sollten sich im selben Verzeichnis befinden.
def psnr(y_true, y_pred):
return tf.image.psnr(y_true, y_pred, 1, name=None)
Dieses Mal habe ich psnr als Kriterium für die Beurteilung der Qualität des generierten Bildes verwendet, das ist also die Definition. psnr wird als Spitzensignal-Rausch-Verhältnis bezeichnet und ist in einfachen Worten wie die Berechnung der Differenz zwischen den Pixelwerten der Bilder, die Sie vergleichen möchten. Ich werde hier nicht im Detail erklären, aber dieser Artikel ist ziemlich detailliert und es werden mehrere Bewertungsmethoden beschrieben.
train_height = 17
train_width = 17
test_height = 200
test_width = 200
mag = 3.0
cut_traindata_num = 10
cut_testdata_num = 1
train_file_path = "../photo_data/DIV2K_train_HR" #Ordner mit Fotos
test_file_path = "../photo_data/DIV2K_valid_HR" #Ordner mit Fotos
BATSH_SIZE = 256
EPOCHS = 1000
opt = tf.keras.optimizers.Adam(learning_rate=0.0001)
Hier wird der diesmal verwendete Wert eingestellt. Wenn Sie sich github ansehen, ist es in Ordnung, wenn Sie eine separate config.py haben. Da es sich jedoch nicht um ein umfangreiches Programm handelt, wird es zusammengefasst.
Was die Größe der Trainingsdaten angeht, wurden die Zugdaten in der Zeitung als 51 * 51 geschrieben, daher habe ich 17 * 17 angenommen, was der Wert geteilt durch das Magazin ist. Der Test ist zur einfachen Anzeige nur übergroß. __ Das Ergebnis ist dreimal so groß. __ __ Die Anzahl der Daten beträgt das Zehnfache der Anzahl der in der Datei enthaltenen Bilder. (Bei 800 Blatt beträgt die Anzahl der Daten 8.000)
Dieses Mal habe ich DIV2K Dataset verwendet, das häufig für die Superauflösung verwendet wird. Da die Qualität der Daten gut ist, wird gesagt, dass mit einer kleinen Datenmenge eine gewisse Genauigkeit erzielt werden kann.
parser = argparse.ArgumentParser()
parser.add_argument('--mode', type=str, default='espcn', help='espcn, evaluate')
args = parser.parse_args()
Ich wollte das Lernen und die Bewertung des Modells hier trennen, also habe ich es so gemacht, damit ich es mit --mode auswählen kann. Ich werde nicht im Detail erklären, also werde ich die offizielle Python-Dokumentation veröffentlichen. https://docs.python.org/ja/3/library/argparse.html
if args.mode == "espcn":
train_x, train_y = data_create.save_frame(train_file_path, #Pfad des zu beschneidenden Bildes
cut_traindata_num, #Anzahl der generierten Datensätze
train_height, #Speichergröße
train_width,
mag) #Vergrößerung
model = model.ESPCN(mag)
model.compile(loss = "mean_squared_error",
optimizer = opt,
metrics = [psnr])
#https://keras.io/ja/getting-started/faq/
model.fit(train_x,
train_y,
epochs = EPOCHS)
model.save("espcn_model.h5")
Ich lerne hier. Wenn Sie srcnn auswählen (die Methode wird später beschrieben), funktioniert dieses Programm.
In data_create.save_frame wird die Funktion save_frame von data_create.py gelesen und verfügbar gemacht. Nachdem sich die Daten in train_x und train_y befinden, laden Sie das Modell auf die gleiche Weise und kompilieren und passen Sie es an.
Weitere Informationen zum Kompilieren und mehr finden Sie unter Keras-Dokumentation. Wir verwenden die gleichen wie die Papiere.
Speichern Sie schließlich das Modell und Sie sind fertig.
elif args.mode == "evaluate":
path = "espcn_model"
exp = ".h5"
new_model = tf.keras.models.load_model(path + exp, custom_objects={'psnr':psnr})
new_model.summary()
test_x, test_y = data_create.save_frame(test_file_path, #Pfad des zu beschneidenden Bildes
cut_testdata_num, #Anzahl der generierten Datensätze
test_height, #Speichergröße
test_width,
mag) #Vergrößerung
print(len(test_x))
pred = new_model.predict(test_x)
path = "resurt_" + path
os.makedirs(path, exist_ok = True)
path = path + "/"
for i in range(10):
ps = psnr(tf.reshape(test_y[i], [test_height, test_width, 1]), pred[i])
print("psnr:{}".format(ps))
before_res = tf.keras.preprocessing.image.array_to_img(tf.reshape(test_x[i], [int(test_height / mag), int(test_width / mag), 1]))
change_res = tf.keras.preprocessing.image.array_to_img(tf.reshape(test_y[i], [test_height, test_width, 1]))
y_pred = tf.keras.preprocessing.image.array_to_img(pred[i])
before_res.save(path + "low_" + str(i) + ".jpg ")
change_res.save(path + "high_" + str(i) + ".jpg ")
y_pred.save(path + "pred_" + str(i) + ".jpg ")
else:
raise Exception("Unknow --mode")
Es ist endlich die Erklärung des Letzten. Laden Sie zunächst das zuvor gespeicherte Modell, damit Sie psnr verwenden können. Generieren Sie als Nächstes einen Datensatz zum Testen und ein Bild mit Vorhersage.
Ich wollte den psnr-Wert vor Ort wissen, also habe ich ihn berechnet. Ich wollte das Bild speichern, also habe ich es vom Tensor in ein Numpy-Array konvertiert, es gespeichert und schließlich war es fertig!
Die Auflösung wurde so fest erhöht.


5. Am Ende
Diesmal habe ich versucht, ESPCN zu erstellen. Ich mache mir Sorgen darüber, welches Papier ich als nächstes implementieren soll. Wir freuen uns immer auf Ihre Anfragen und Fragen. Danke fürs Lesen.
Recommended Posts