[PYTHON] Apprenez le flux de l'estimation bayésienne et comment utiliser Pystan grâce à un modèle de régression simple
introduction
[Introduction à l'analyse des données par modélisation statistique bayésienne à partir de R et Stan](https://www.amazon.co.jp/%E5%AE%9F%E8%B7%B5Data-Science%E3%82%B7%E3%83] % AA% E3% 83% BC% E3% 82% BA-R% E3% 81% A8Stan% E3% 81% A7% E3% 81% AF% E3% 81% 98% E3% 82% 81% E3% 82 % 8B-% E3% 83% 99% E3% 82% A4% E3% 82% BA% E7% B5% B1% E8% A8% 88% E3% 83% A2% E3% 83% 87% E3% 83% AA% E3% 83% B3% E3% 82% B0% E3% 81% AB% E3% 82% 88% E3% 82% 8B% E3% 83% 87% E3% 83% BC% E3% 82% BF% E5% 88% 86% E6% 9E% 90% E5% 85% A5% E9% 96% 80-KS% E6% 83% 85% E5% A0% B1% E7% A7% 91% E5% AD% A6% J'ai lu E5% B0% 82% E9% 96% 80% E6% 9B% B8 / dp / 4065165369). C'était facile à comprendre et j'ai pu le lire sans obstruction. c'est recommandé. Pour une meilleure compréhension, j'aimerais retracer le contenu du livre et l'essayer. Ce livre utilise R et stan, mais ici nous utilisons Python et Pystan. Le contenu général de cet article est le suivant:
- Théorème de Bayes
- Méthode MCMC
- Comment utiliser Pystan
- Modèle de régression simple
Vous apprendrez le flux d'estimation bayésienne et comment utiliser Pystan à travers un modèle simple appelé modèle de régression simple.
0. Module
Ici, importez les modules requis à l'avance.
import numpy as np
import matplotlib.pyplot as plt
import pystan
import arviz
plt.rcParams["font.family"] = "Times New Roman" #Définir la police entière
plt.rcParams["xtick.direction"] = "in" #Vers l'intérieur de la ligne d'échelle de l'axe x
plt.rcParams["ytick.direction"] = "in" #Vers l'intérieur de la ligne d'échelle de l'axe y
plt.rcParams["xtick.minor.visible"] = True #Ajout de l'échelle auxiliaire sur l'axe x
plt.rcParams["ytick.minor.visible"] = True #Ajout de l'échelle auxiliaire de l'axe y
plt.rcParams["xtick.major.width"] = 1.5 #Largeur de ligne de la ligne d'échelle principale de l'axe x
plt.rcParams["ytick.major.width"] = 1.5 #Largeur de ligne de la ligne d'échelle principale de l'axe y
plt.rcParams["xtick.minor.width"] = 1.0 #Largeur de ligne de la ligne d'échelle auxiliaire de l'axe x
plt.rcParams["ytick.minor.width"] = 1.0 #Largeur de ligne de la ligne d'échelle auxiliaire de l'axe y
plt.rcParams["xtick.major.size"] = 10 #longueur de la ligne d'échelle principale sur l'axe des x
plt.rcParams["ytick.major.size"] = 10 #Longueur de la ligne d'échelle principale de l'axe y
plt.rcParams["xtick.minor.size"] = 5 #longueur de la ligne d'échelle auxiliaire sur l'axe des x
plt.rcParams["ytick.minor.size"] = 5 #longueur de la ligne d'échelle auxiliaire sur l'axe y
plt.rcParams["font.size"] = 14 #Taille de police
plt.rcParams["axes.linewidth"] = 1.5 #Épaisseur du boîtier
1. Théorème de Bayes
L'estimation bayésienne est basée sur le théorème bayésien.
p(\theta|x)=p(\theta) \frac{p(x|\theta)}{\int p(x|\theta)p(\theta)d\theta}
ici
(Distribution ex post) = (Distribution antérieure) \times \frac{(Responsabilité)}{(周辺Responsabilité)}
La vraisemblance périphérique est une constante de normalisation qui définit la valeur intégrée de la distribution postérieure à 1. Par conséquent, la relation suivante est valable, en omettant le terme de vraisemblance marginale.
(Distribution ex post) \propto (Distribution antérieure) \times (Responsabilité)
1.1 Exemple
Considérons l'estimation bayésienne de la valeur moyenne, en utilisant la variable de probabilité $ x $ qui suit une distribution normale à titre d'exemple. Supposons que vous sachiez que l'écart type est de 1. La fonction de densité de probabilité de la distribution normale est la suivante.
\begin{align} p(x|\mu, \sigma=1) &= \frac{1}{\sqrt{2\pi\sigma^2}}\exp{\left(-\frac{(x-\mu)^2}{2\sigma^2}\right)} \\
&= \frac{1}{\sqrt{2\pi}}\exp{\left(-\frac{(x-\mu)^2}{2}\right)} \end{align}
np.random.seed(seed=1) #Graine aléatoire
mu = 5.0 #moyenne
s = 1.0 #écart-type
N = 10 #Quantité
x = np.random.normal(mu,s,N)
print(x)
array([6.62434536, 4.38824359, 4.47182825, 3.92703138, 5.86540763,
2.6984613 , 6.74481176, 4.2387931 , 5.3190391 , 4.75062962])
Trouvez la probabilité (probabilité) d'obtenir les données ci-dessus. Les données sont $ D $. Puisque les événements qui obtiennent chaque donnée sont indépendants, les probabilités d'obtenir chaque donnée sont multipliées.
f(D|\mu) = \prod_{i=0}^{N-1} \frac{1}{\sqrt{2\pi}}\exp{\left(-\frac{(x_i-\mu)^2}{2}\right)}
Bien que pas dans le livre, visualisons la fonction ci-dessus. Ici, prendre la valeur maximale de la fonction de vraisemblance et déterminer que la moyenne est de 5 (estimation ponctuelle) est appelée la méthode la plus vraisemblable.
mu_ = np.linspace(-5.0,15.0,1000)
f_D = 1.0
for x_ in x:
f_D *= 1.0/np.sqrt(2.0*np.pi) * np.exp(-(x_-mu_)**2 / 2.0) #Fonction responsabilité
fig,axes = plt.subplots(figsize=(8,6))
axes.plot(mu_,np.log(f_D))
axes.set_xlabel(r"$\mu$")
axes.set_ylabel(r"$log (f(D|\mu))$")
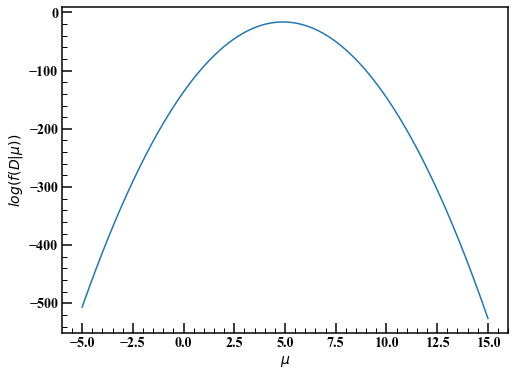
Revenons à l'estimation bayésienne et déterminons la distribution a priori. Si vous ne connaissez pas le paramètre $ \ mu $ à l'avance, suivez le principe des motifs inadéquats et envisagez une distribution large pour le moment. Cette fois, la distribution est de 10000 et la moyenne est de 0.
Dans l'estimation bayésienne, la distribution postérieure peut être complexe et difficile à intégrer. Même si vous obtenez la fonction de densité de probabilité de la distribution postérieure, si vous ne pouvez pas l'intégrer, par exemple, la probabilité que la valeur moyenne soit comprise entre 4 et 6 ne peut pas être obtenue. La méthode MCMC est utile dans de tels cas. Dans cet exemple, il n'y a qu'un seul paramètre, donc divisons-le par $ \ mu $ au lieu de la méthode MCMC et voyons à quoi ressemble la distribution postérieure.
f_mu = 1.0/np.sqrt(20000.0*np.pi) * np.exp(-mu_**2.0 / 20000) #Distribution antérieure
f_mu_poster = f_mu * f_D #(Distribution antérieure)×(Responsabilité)
f_mu_poster /= np.sum(f_mu_poster) #Définissez la valeur intégrée sur 1
fig,axes = plt.subplots(figsize=(8,6))
axes.plot(mu_,f_mu,label="Prior distribution")
axes.plot(mu_,f_mu_poster,label="Posterior distribution")
axes.legend(loc="best")
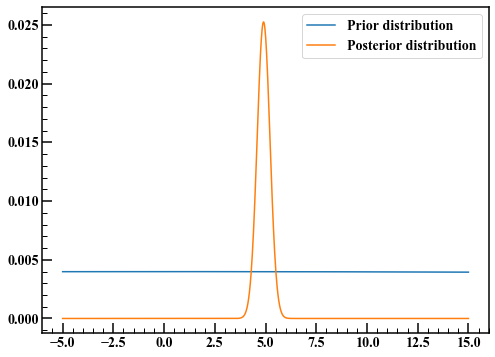
La pré-distribution était à queue large, mais la distribution postérieure mise à jour par Bayes a des queues étroites. La valeur attendue de la distribution postérieure semble être à 5, telle qu'elle est obtenue par la méthode la plus probable.
2. Méthode MCMC
La méthode MCMC est une abréviation de la méthode Monte Carlo par chaîne de Markov. Il s'agit d'une méthode de génération de nombres aléatoires qui utilise la chaîne de Markov, dans laquelle la valeur à un certain point dans le temps n'est affectée que par le point dans le temps précédent. Dans l'estimation bayésienne, les nombres aléatoires qui suivent la distribution postérieure des paramètres sont générés par la méthode MCMC et utilisés à la place de l'intégration. Par exemple, si vous souhaitez trouver la valeur attendue de la distribution postérieure, vous pouvez la trouver en calculant la moyenne des nombres aléatoires.
2.1 Méthode Metropolis Hastings (méthode MH)
Décrit un algorithme qui génère des nombres aléatoires qui suivent une certaine distribution de probabilité. Pour simplifier, nous n’estimerons qu’un paramètre.
- Déterminez la valeur initiale du nombre aléatoire $ \ hat {\ theta} $.
- Générez des nombres aléatoires qui suivent une distribution normale avec une moyenne de 0 et une variance de $ \ sigma ^ 2 $.
- Calculez la somme de son nombre aléatoire et de la valeur initiale $ \ hat {\ theta} $. Soit $ \ theta ^ {suggest} $.
- Calculez le rapport des densités de probabilité de $ \ hat {\ theta} $ et $ \ theta ^ {suggest} $.
- Si le rapport des densités de probabilité est supérieur à 1, $ \ theta ^ {suggérer} $ est adopté, et s'il est égal ou inférieur à 1, cette valeur est utilisée comme probabilité et adoptée ou rejetée.
Le nombre aléatoire adopté est utilisé comme valeur initiale et répété plusieurs fois. Plus la densité de probabilité est élevée, plus il est facile d'adopter des nombres aléatoires, on a donc l'impression de suivre la distribution de probabilité. En utilisant à nouveau l'exemple de 1.1, générons un nombre aléatoire qui suit la distribution postérieure par la méthode ci-dessus.
np.random.seed(seed=1) #Graine aléatoire
def posterior_dist(mu): #Distribution ex post
#(Distribution antérieure)×(Responsabilité)
return 1.0/np.sqrt(20000.0*np.pi) * np.exp(-mu**2.0 / 20000) \
* np.prod(1.0/np.sqrt(2.0*np.pi) * np.exp(-(x-mu)**2 / 2.0))
def MH_method(N,s):
rand_list = [] #Nombre aléatoire adopté
theta = 1.0 #1.Déterminez la valeur initiale de manière appropriée
for i in range(N):
rand = np.random.normal(0.0,s) #2.Générer des nombres aléatoires qui suivent une distribution normale avec une moyenne de 0 et un écart type s
suggest = theta + rand #3.
dens_rate = posterior_dist(suggest) / posterior_dist(theta) #4.Rapport de densité de probabilité
# 5.
if dens_rate >= 1.0 or np.random.rand() < dens_rate:
theta = suggest
rand_list.append(theta)
return rand_list
Répétez les étapes 1 à 5 50000 fois, avec l'écart type des nombres aléatoires générés à l'étape 2 comme 1.
rand_list = MH_method(50000,1.0)
len(rand_list) / 50000
0.3619
La probabilité qu'un nombre aléatoire sera adopté s'appelle le taux d'acceptation. Cette fois, il était de 36,2%.
fig,axes = plt.subplots(figsize=(8,6))
axes.plot(rand_list)
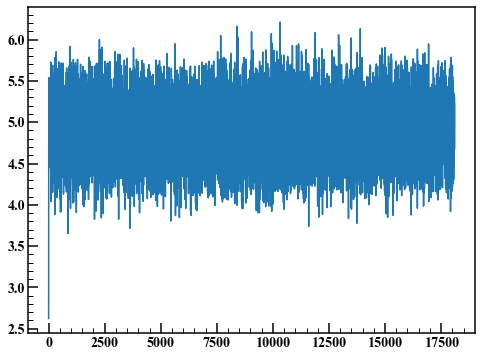
Un tel graphe s'appelle un tracé de trace. Les premiers points ne sont pas stationnaires en raison de l'influence des valeurs initiales. Ici, les 1000 premiers points sont ignorés et un histogramme est dessiné.
fig,axes = plt.subplots(figsize=(8,6))
axes.hist(rand_list[1000:],30)
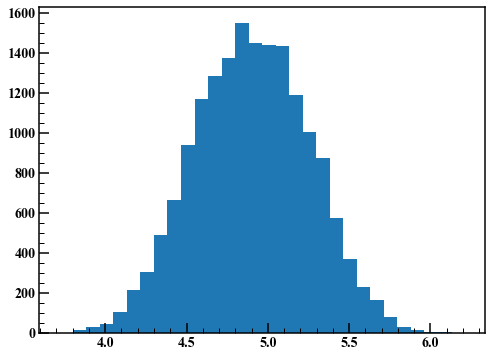
J'ai obtenu un bon résultat. Ensuite, définissez l'écart type des nombres aléatoires générés à l'étape 2 sur 0,01 et répétez le même processus.
rand_list = MH_method(50000,0.01)
len(rand_list) / 50000
0.98898
Le taux d'acceptation est passé à 98,9%.
fig,axes = plt.subplots(figsize=(8,6))
axes.plot(rand_list)
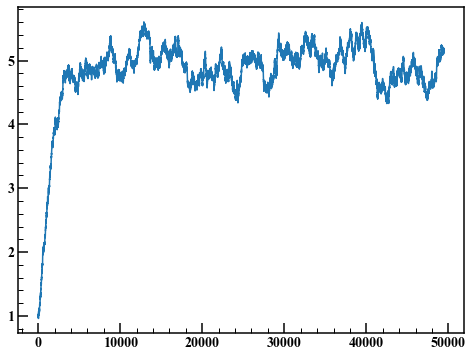
Jeter les 10 000 premiers points et dessiner un histogramme.
fig,axes = plt.subplots(figsize=(8,6))
axes.hist(rand_list[10000:],30)
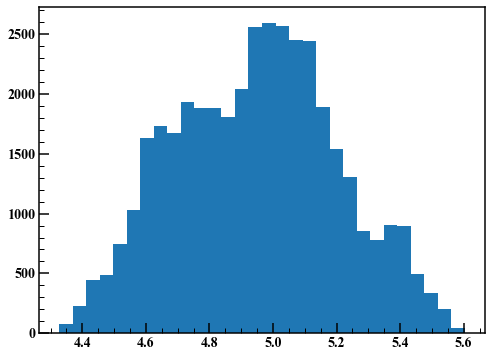
Comme vous pouvez le voir, le résultat de la méthode MH dépend de la dispersion des nombres aléatoires utilisés à l'étape 2. La méthode hamiltonienne de Monte Carlo est l'un des algorithmes permettant de résoudre ce problème. Stan bénéficie d'une variété d'algorithmes intelligents mis en œuvre.
3. Comment utiliser Pystan
Le code Stan nécessite un bloc de données, un bloc de paramètres et un bloc de modèle. Le bloc de données décrit les informations des données à utiliser, le bloc de paramètres décrit les paramètres à estimer et le bloc de modèle décrit la distribution et la vraisemblance antérieures. Le bloc de quantités généré peut générer des nombres aléatoires en utilisant les paramètres estimés. J'ai écrit la méthode de description dans le commentaire dans le code Stan.
stan_code = """
data {
int N; //taille de l'échantillon
vector[N] x; //Les données
}
parameters {
real mu; //moyenne
real<lower=0> sigma; //écart-type<lower=0>Spécifie que prend uniquement des valeurs supérieures ou égales à 0
}
model {
//Distribution normale du mu moyen, écart-type sigma
x ~ normal(mu, sigma); // "~"Le symbole indique que le côté gauche suit la distribution du côté droit
}
generated quantities{
//Obtenez la distribution de prédiction postérieure
vector[N] pred;
//Contrairement à Python, les indices commencent à 1
for (i in 1:N) {
pred[i] = normal_rng(mu, sigma);
}
}
"""
Compilez le code Stan.
sm = pystan.StanModel(model_code=stan_code) #Compilation du code Stan
Résumez les données à utiliser. Correspond au nom de variable déclaré dans le bloc de données du code Stan ci-dessus.
#Rassemblez les données
stan_data = {"N":len(x), "x":x}
Avant d'exécuter MCMC, examinons les arguments de la méthode d'échantillonnage.
- Nombre d'itérations iter: Le nombre de nombres aléatoires générés. Si rien n'est spécifié, la valeur par défaut est 2000. Si la convergence est mauvaise, cela peut être une valeur élevée.
- Préchauffage de la période de rodage: comme le tracé de trace de la version 2.1, il est initialement affecté par la valeur initiale. Pour éviter cet effet, supprimez les points spécifiés par l'échauffement.
- Amincissement fin: Adoptez un nombre aléatoire pour chaque fin. Puisque la méthode MCMC utilise la chaîne de Markov, elle est affectée il y a une fois et a une autocorrélation. Réduisez cet effet.
- Chaînes de chaînes: Afin d'évaluer la convergence, la valeur initiale est modifiée et des nombres aléatoires sont générés par les chaînes MCMC fois. Si les résultats de chaque essai sont similaires, on peut juger qu'ils ont convergé.
Exécutez MCMC.
#Exécutez MCMC
mcmc_normal = sm.sampling(
data = stan_data,
iter = 2000,
warmup = 1000,
chains = 4,
thin = 1,
seed = 1
)
Affichez le résultat. Les données utilisées étaient des nombres aléatoires suivant une distribution normale avec une moyenne de 5 et un écart type de 1. mu représente la moyenne et sigma représente l'écart type. Décrit chaque élément du tableau des résultats.
- moyenne: valeur attendue de la distribution postérieure
- se_mean: la valeur attendue de la distribution postérieure divisée par la racine carrée du nombre d'échantillons valides [^ 1]
- sd: écart type de la distribution postérieure
- 2,5% -97,5%: intervalle de crédit Bayes. Disposez les nombres aléatoires qui suivent la distribution postérieure dans l'ordre croissant et vérifiez les valeurs qui correspondent aux points de 2,5% à 97,5%. Si vous prenez cette différence, vous obtiendrez un intervalle de crédit bayésien de 95% (intervalle de confiance).
- n_eff: nombre de nombres aléatoires adoptés
- Rhat: Représente le rapport de la distribution de tous les nombres aléatoires comprenant différentes chaînes à la valeur moyenne de la distribution des nombres aléatoires dans la même chaîne. Lorsque les chaînes sont égales à 3 ou plus, Rhat semble être plus petit que 1,1.
- lp__: Probabilité logistique a posteriori [^ 2]
mcmc_normal
Inference for Stan model: anon_model_710b192b75c183bf7f98ae89c1ad472d.
4 chains, each with iter=2000; warmup=1000; thin=1;
post-warmup draws per chain=1000, total post-warmup draws=4000.
mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat
mu 4.9 0.01 0.47 4.0 4.61 4.89 5.18 5.87 1542 1.0
sigma 1.46 0.01 0.43 0.89 1.17 1.38 1.66 2.58 1564 1.0
pred[1] 4.85 0.03 1.58 1.77 3.88 4.86 5.83 8.0 3618 1.0
pred[2] 4.9 0.03 1.62 1.66 3.93 4.9 5.89 8.11 3673 1.0
pred[3] 4.87 0.03 1.6 1.69 3.86 4.85 5.86 8.14 3388 1.0
pred[4] 4.86 0.03 1.57 1.69 3.89 4.87 5.81 7.97 3790 1.0
pred[5] 4.88 0.03 1.6 1.67 3.89 4.89 5.89 7.98 3569 1.0
pred[6] 4.86 0.03 1.61 1.56 3.94 4.87 5.81 8.01 3805 1.0
pred[7] 4.89 0.03 1.6 1.7 3.9 4.88 5.86 8.09 3802 1.0
pred[8] 4.88 0.03 1.61 1.62 3.87 4.88 5.9 8.12 3210 1.0
pred[9] 4.87 0.03 1.6 1.69 3.86 4.87 5.85 8.1 3845 1.0
pred[10] 4.91 0.03 1.63 1.73 3.91 4.88 5.9 8.3 3438 1.0
lp__ -7.63 0.03 1.08 -10.48 -8.03 -7.29 -6.85 -6.57 1159 1.0
Samples were drawn using NUTS at Wed Jan 1 14:32:42 2020.
For each parameter, n_eff is a crude measure of effective sample size,
and Rhat is the potential scale reduction factor on split chains (at
convergence, Rhat=1).
Quand j'ai essayé fit.plot (), un AVERTISSEMENT est apparu, alors suivez-le.
WARNING:pystan:Deprecation warning.
PyStan plotting deprecated, use ArviZ library (Python 3.5+).
pip install arviz; arviz.plot_trace(fit))
Vous pouvez facilement vérifier le tracé et la distribution postérieure.
arviz.plot_trace(mcmc_normal)
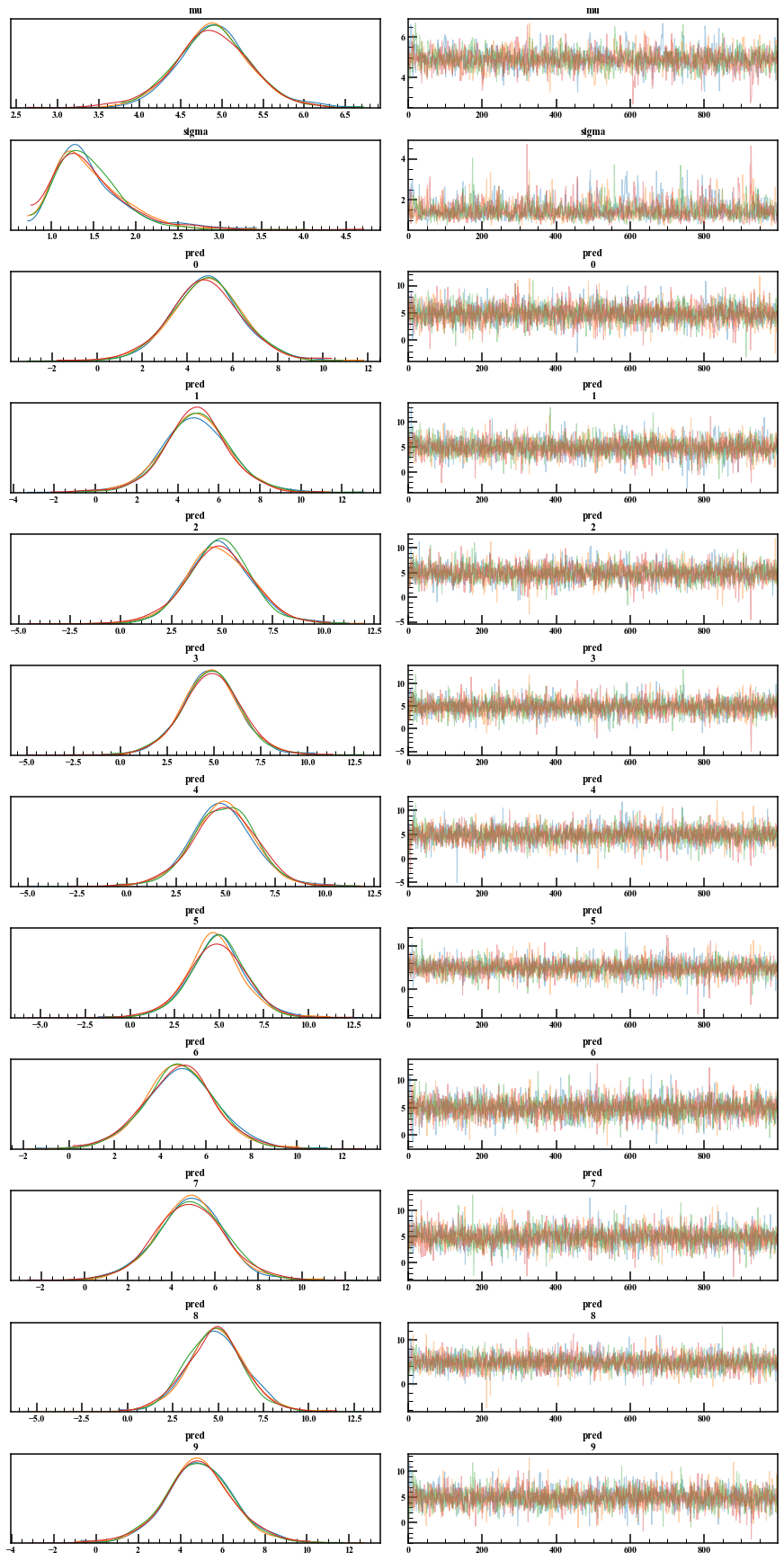
Si vous souhaitez jouer directement avec l'échantillon MCMC, ou si vous souhaitez vous en tenir davantage au graphique, vous pouvez l'extraire avec un extrait. Par défaut, permuté = True, qui renvoie un nombre aléatoire d'ordre mixte. Je veux que le tracé de trace soit une série chronologique, alors laissez cet argument sur False. De plus, inc_warmup indique s'il faut inclure la période de rodage. De plus, fit ["nom de la variable"] a donné des nombres aléatoires en excluant la période de rodage.
mcmc_extract = mcmc_normal.extract(permuted=False, inc_warmup=True)
mcmc_extract.shape
(2000, 4, 13)
Si vous vérifiez les dimensions, ce sera (iter, chaînes, nombre de paramètres). Bien que le nombre de graphiques soit 12, il y a une 13ème dimension, mais quand je trace et vérifie cela, cela ressemble à lp__.
4. Analyse de régression simple
Pour résumer jusqu'à présent, nous allons effectuer une analyse de régression simple avec une estimation bayésienne. Soit $ y $ la variable de réponse et $ x $ la variable explicative. Supposons que $ y $ suit une distribution normale avec une moyenne $ \ mu = ax + b $ et un écart-type $ \ sigma ^ 2 $ avec un gradient $ a $ et une section $ b $.
\begin{align}
\mu &= ax + b \\
y &\sim \mathcal{N}(\mu,\sigma^2)
\end{align}
Il montre également les notations couramment trouvées dans d'autres descriptions simples d'analyse de régression.
\begin{align}
y &= ax + b + \varepsilon \\
\varepsilon &\sim \mathcal{N}(0,\sigma^2)
\end{align}
Les deux formules ci-dessus sont les mêmes. La première expression affichée est plus pratique pour écrire du code Stan. Dans cet exemple, le processus d'obtention de $ y $ est décidé et la valeur en est échantillonnée pour effectuer une estimation bayésienne. Regardez et faites un essai et une erreur pour modifier le modèle.
4.1 Confirmation des données
Tout d'abord, créez les données que vous souhaitez utiliser.
np.random.seed(seed=1) #Graine aléatoire
a,b = 3.0,1.0 #Inclinaison et section
sig = 2.0 #écart-type
x = 10.0* np.random.rand(100)
y = a*x + b + np.random.normal(0.0,sig,100)
Tracez et vérifiez. De plus, la régression linéaire par la méthode des moindres carrés est également affichée.
a_lsm,b_lsm = np.polyfit(x,y,1) #Régression linéaire avec la méthode des moindres carrés(2.936985017531063, 1.473914508297817)
fig,axes = plt.subplots(figsize=(8,6))
axes.scatter(x,y)
axes.plot(np.linspace(0.0,10.0,100),a_lsm*np.linspace(0.0,10.0,100)+b_lsm)
axes.set_xlabel("x")
axes.set_ylabel("y")
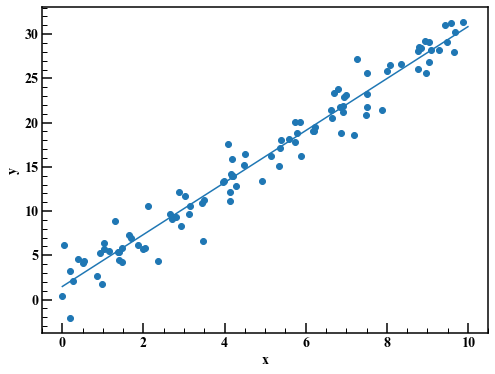
4.2 Prise en compte du processus de génération de données et création du code Stan
En supposant que vous ayez complètement oublié le processus de création des données, regardez le graphique et pensez que $ y $ et $ x $ sont susceptibles d'être dans une relation proportionnelle. Écrivez le code Stan en supposant que la variabilité suit une distribution normale.
stan_code = """
data {
int N; //taille de l'échantillon
vector[N] x; //Les données
vector[N] y; //Les données
int N_pred; //Taille d'échantillon prévue
vector[N_pred] x_pred; //Données prédites
}
parameters {
real a; //Inclinaison
real b; //Section
real<lower=0> sigma; //écart-type<lower=0>Spécifie que prend uniquement des valeurs supérieures ou égales à 0
}
transformed parameters {
vector[N] mu = a*x + b;
}
model {
// b ~ normal(0, 1000)Spécification de la distribution antérieure
//Distribution normale du mu moyen, écart-type sigma
y ~ normal(mu, sigma); // "~"Le symbole indique que le côté gauche suit la distribution du côté droit
}
generated quantities {
vector[N_pred] y_pred;
for (i in 1:N_pred) {
y_pred[i] = normal_rng(a*x_pred[i]+b, sigma);
}
}
"""
Le bloc de paramètres transformés nouvellement introduit peut créer de nouvelles variables en utilisant les variables déclarées dans le bloc de paramètres. Cette fois, c'est une formule simple, donc il n'y a pas beaucoup de différence, mais si c'est une formule compliquée, cela vous donnera une meilleure vue. En outre, lors de la spécification de la distribution précédente, écrivez comme "b ~ normal (0, 1000)" dans le bloc de modèle commenté.
4.3 Exécution de MCMC
Compilez le code Stan et exécutez MCMC.
sm = pystan.StanModel(model_code=stan_code) #Compilation du code Stan
x_pred = np.linspace(0.0,11.0,200)
stan_data = {"N":len(x), "x":x, "y":y, "N_pred":200, "x_pred":x_pred}
#Exécutez MCMC
mcmc_linear = sm.sampling(
data = stan_data,
iter = 4000,
warmup = 1000,
chains = 4,
thin = 1,
seed = 1
)
4.4 Vérification des résultats
print(mcmc_linear)
Inference for Stan model: anon_model_28ac7b1919f5bf2d52d395ee71856f88.
4 chains, each with iter=4000; warmup=1000; thin=1;
post-warmup draws per chain=3000, total post-warmup draws=12000.
mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat
a 2.94 9.0e-4 0.06 2.82 2.89 2.94 2.98 3.06 4705 1.0
b 1.47 5.1e-3 0.35 0.79 1.24 1.47 1.71 2.16 4799 1.0
sigma 1.83 1.7e-3 0.13 1.59 1.74 1.82 1.92 2.12 6199 1.0
mu[1] 13.72 1.8e-3 0.19 13.35 13.59 13.72 13.85 14.09 10634 1.0
mu[2] 22.63 2.2e-3 0.24 22.16 22.47 22.63 22.78 23.1 11443 1.0
Samples were drawn using NUTS at Wed Jan 1 15:07:22 2020.
For each parameter, n_eff is a crude measure of effective sample size,
and Rhat is the potential scale reduction factor on split chains (at
convergence, Rhat=1).
Il est omis car il s'agit d'une sortie très longue. En regardant Rhat, la convergence semble aller bien. L'intervalle de crédit de 95% est illustré à partir de la distribution des prévisions postérieures.
reg_95 = np.quantile(mcmc_linear["y_pred"],axis=0,q=[0.025,0.975]) #Distribution de prédiction ex post
fig,axes = plt.subplots(figsize=(8,6))
axes.scatter(x,y,label="Data",c="k")
axes.plot(x_pred,np.average(mcmc_linear["y_pred"],axis=0),label="Expected value")
axes.fill_between(x_pred,reg_95[0],reg_95[1],alpha=0.1,label="95%")
axes.legend(loc="best")
axes.set_xlabel("x")
axes.set_ylabel("y")
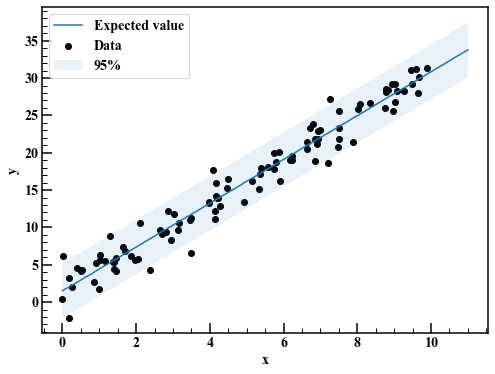
Cela a l'air bien en général.
Résumé
Grâce à l'estimation bayésienne du modèle de régression simple, j'ai appris le flux de l'estimation bayésienne et comment utiliser Stan. Enregistrez à nouveau le flux d'estimation bayésienne.
- Vérifiez les données: saisissez la structure des données en les traçant sur un graphique.
- Prise en compte du processus de génération de données et création du code Stan: Ecrire le code Stan en formulant la structure des données.
- Exécutez MCMC: exécutez MCMC pour obtenir la distribution postérieure.
- Vérifiez le résultat: vérifiez le résultat et modifiez le modèle à plusieurs reprises.
Cette fois, j'ai utilisé un modèle simple, mais la prochaine fois, j'aimerais essayer un modèle plus général tel qu'un modèle d'espace d'états.