[PYTHON] Détection de visage avec Haar Cascades
Basé sur py_face_detection.markdown Dans "Open CV-Python Tutorials" traduction japonaise [Face Detection using Haar Cascades] (http://docs.opencv.org/3.0-beta/doc/py_tutorials/py_objdetect/py_face_detection/py_face_detection.html#face-detection) J'ai fait une traduction de. La traduction japonaise est ajoutée après l'anglais d'origine. J'espère que cela vous aidera à vous intéresser à l'algorithme.
La page suivante est en place, donc je n'ai plus besoin de ma traduction de merde.
Page de document du didacticiel OpenCV-Python de l'Université Tottori [Détection de visage à l'aide de Haar Cascades] (http://labs.eecs.tottori-u.ac.jp/sd/Member/oyamada/OpenCV/html/py_tutorials/py_objdetect/py_face_detection/py_face_detection.html#face-detection)
Face Detection using Haar Cascades {#tutorial_py_face_detection} Détection de visage avec Haar Cascades
Goal
In this session,
- We will see the basics of face detection using Haar Feature-based Cascade Classifiers
- We will extend the same for eye detection etc.
Dans cette section,
- Apprenez les bases de la détection de visage à l'aide du classificateur Cascade basé sur les fonctionnalités de Haar. ――Il est étendu et utilisé pour la détection des yeux.
Basics
Object Detection using Haar feature-based cascade classifiers is an effective object detection method proposed by Paul Viola and Michael Jones in their paper, "Rapid Object Detection using a Boosted Cascade of Simple Features" in 2001. It is a machine learning based approach where a cascade function is trained from a lot of positive and negative images. It is then used to detect objects in other images. La détection d'objets à l'aide du classificateur Cascade basé sur les fonctionnalités de Haar est une méthode efficace de détection d'objets, décrite par Paul Viola et Michael Jones comme «Détection rapide d'objets à l'aide d'un». Proposé dans un article dans Boosted Cascade of Simple Features "(2001). La technique est une approche basée sur l'apprentissage automatique, dans laquelle chaque classificateur en cascade est formé à partir d'un grand nombre d'images positives et négatives. Après l'entraînement, il est utilisé pour détecter des objets dans d'autres images.
Here we will work with face detection. Initially, the algorithm needs a lot of positive images (images of faces) and negative images (images without faces) to train the classifier. Then we need to extract features from it. For this, haar features shown in below image are used. They are just like our convolutional kernel. Each feature is a single value obtained by subtracting sum of pixels under white rectangle from sum of pixels under black rectangle.
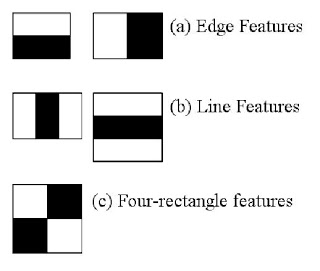
Commençons maintenant par la détection des visages. Premièrement, l'algorithme utilise un grand nombre d'images positives (images de visage) et d'images négatives (images sans visage) pour entraîner le classificateur. Ensuite, nous devons extraire les fonctionnalités de l'image. À cette fin, les fonctionnalités Haar illustrées dans la figure ci-dessous sont utilisées. Les fonctionnalités de Haar sont comme un noyau convolutif. Chaque caractéristique est un nombre unique, qui est la somme de la luminosité des pixels à la position du carré noir moins la luminosité totale des pixels à la position du carré blanc.
Now all possible sizes and locations of each kernel is used to calculate plenty of features. (Just imagine how much computation it needs? Even a 24x24 window results over 160000 features). For each feature calculation, we need to find sum of pixels under white and black rectangles. To solve this, they introduced the integral images. It simplifies calculation of sum of pixels, how large may be the number of pixels, to an operation involving just four pixels. Nice, isn't it? It makes things super-fast.
À ce stade, toutes les tailles et positions possibles de chaque noyau sont utilisées pour calculer un grand nombre de caractéristiques. (Imaginez le nombre de calculs dont vous avez besoin. Même une fenêtre de 24 x 24 pixels a plus de 16 000 fonctionnalités.) Pour résoudre ce problème, ils ont introduit une image intégrée. En utilisant l'image intégrée, il est facile de calculer la valeur totale des pixels. Peu importe le nombre de pixels, nous le remplaçons par une opération qui utilise les valeurs de quatre pixels (dans l'image intégrée). Ce serait bien. En utilisant l'image intégrée, c'est très rapide.
But among all these features we calculated, most of them are irrelevant. For example, consider the image below. Top row shows two good features. The first feature selected seems to focus on the property that the region of the eyes is often darker than the region of the nose and cheeks. The second feature selected relies on the property that the eyes are darker than the bridge of the nose. But the same windows applying on cheeks or any other place is irrelevant. So how do we select the best features out of 160000+ features? It is achieved by Adaboost.

Cependant, la plupart de ces caractéristiques calculées ne sont pas pertinentes (pour l'identification du visage). Voir la figure ci-dessous pour un exemple. La rangée du haut montre deux bonnes fonctionnalités. La première caractéristique sélectionnée semble se concentrer sur la caractéristique que le contour des yeux a tendance à être plus sombre que le nez et les joues. La deuxième caractéristique sélectionnée dépend de la caractéristique que la zone des deux yeux est plus sombre que les muscles nasaux. Mais même dans la même fenêtre, celle utilisée sur la joue ou ailleurs n'est pas pertinente (pour identifier s'il s'agit d'un visage). Alors, comment sélectionnez-vous les multiples fonctionnalités optimales parmi plus de 16000 fonctionnalités? Il a été réalisé par ** Ada Boost **.
For this, we apply each and every feature on all the training images. For each feature, it finds the best threshold which will classify the faces to positive and negative. But obviously, there will be errors or misclassifications. We select the features with minimum error rate, which means they are the features that best classifies the face and non-face images. (The process is not as simple as this. Each image is given an equal weight in the beginning. After each classification, weights of misclassified images are increased. Then again same process is done. New error rates are calculated. Also new weights. The process is continued until required accuracy or error rate is achieved or required number of features are found).
Cela appliquera chaque fonctionnalité à toutes les images d'entraînement. Pour chaque fonctionnalité, trouvez le meilleur seuil pour classer les candidats du visage en positif et négatif. Cependant, comme il est clair, des erreurs et des erreurs de classification se produisent. Sélectionnez la fonction qui donne le taux d'erreur le plus bas. En d'autres termes, c'est la quantité de caractéristiques qui classe le mieux les images faciales et non faciales. (Le processus réel n'est pas aussi simple que celui décrit ici. Au départ, toutes les images reçoivent le même poids. Après chaque classification, les images mal classées sont pondérées. Ce processus est la précision requise. Il se répète jusqu'à ce que le taux d'erreur soit atteint ou que la quantité de caractéristiques du nombre de valeurs demandées soit trouvée.)
Final classifier is a weighted sum of these weak classifiers. It is called weak because it alone can't classify the image, but together with others forms a strong classifier. The paper says even 200 features provide detection with 95% accuracy. Their final setup had around 6000 features. (Imagine a reduction from 160000+ features to 6000 features. That is a big gain).
Le dernier discriminateur est obtenu par la pondération de ces discriminateurs faibles. On l'appelle un classificateur faible car il ne peut pas classer les images par lui-même, mais il est combiné avec plusieurs autres classificateurs faibles pour former un classificateur fort. Selon l'article, même 200 fonctionnalités permettent une détection avec une précision de 95%. Leur configuration finale utilise environ 6000 fonctionnalités. (Tenez compte du fait que le nombre de fonctionnalités a été réduit de plus de 160 000 à 6 000. Il aura considérablement diminué.)
So now you take an image. Take each 24x24 window. Apply 6000 features to it. Check if it is face or not. Wow.. Wow.. Isn't it a little inefficient and time consuming? Yes, it is. Authors have a good solution for that.
Je vais donc préparer une image maintenant. Appliquez chaque fenêtre de 24 x 24 pixels. Appliquez 6000 fonctionnalités à la fenêtre. Vérifiez s'il s'agit de visage ou non. Oh, êtes-vous un peu ridicule et inefficace et vous perdez votre temps? C'est vrai. Les auteurs ont une bonne solution à cela.
In an image, most of the image region is non-face region. So it is a better idea to have a simple method to check if a window is not a face region. If it is not, discard it in a single shot. Don't process it again. Instead focus on region where there can be a face. This way, we can find more time to check a possible face region.
Dans une seule image, la plupart des zones de l'image sont des zones sans visage. C'est donc une bonne idée d'avoir un moyen facile de s'assurer que la zone de la fenêtre n'est pas la zone du visage. Si la zone de la fenêtre n'est pas la zone du visage, jetez-la immédiatement. Il ne sera pas traité à nouveau (avec un discriminateur fort). Au lieu de cela, concentrez-vous sur les zones qui peuvent être des visages. De cette façon, vous pouvez passer plus de temps à rechercher d'éventuelles zones du visage.
For this they introduced the concept of Cascade of Classifiers. Instead of applying all the 6000 features on a window, group the features into different stages of classifiers and apply one-by-one. (Normally first few stages will contain very less number of features). If a window fails the first stage, discard it. We don't consider remaining features on it. If it passes, apply the second stage of features and continue the process. The window which passes all stages is a face region. How is the plan !!!
À ce sujet, ils ont introduit le concept de ** classificateur en cascade **. Au lieu d'appliquer toutes les 6000 fonctionnalités à une zone de fenêtre, l'ensemble des fonctionnalités est regroupé en classificateurs appartenant à différentes étapes et appliqués un par un. (Habituellement, les premières étapes contiennent un très petit nombre de fonctionnalités.)
Si vous échouez à la première étape dans une zone de fenêtre. Jeter cette zone de fenêtre. Il ne prend pas en compte les caractéristiques restantes dans cette zone. S'il réussit à la première étape, appliquez le deuxième groupe de fonctionnalités et poursuivez le traitement. La zone de la fenêtre passée à travers toutes les étapes est la zone du visage.
Authors' detector had 6000+ features with 38 stages with 1, 10, 25, 25 and 50 features in first five stages. (Two features in the above image is actually obtained as the best two features from Adaboost). According to authors, on an average, 10 features out of 6000+ are evaluated per sub-window.
Le détecteur de l'auteur est un classificateur à 38 étages avec plus de 6000 caractéristiques, avec 1, 10, 25, 25, 50 caractéristiques dans les 5 premières étapes. (Les deux caractéristiques de la figure ci-dessus ont en fait été obtenues par Adaboost comme étant les deux meilleures caractéristiques.) Selon l'auteur, en moyenne 10 sur 6000 ou plus par sous-fenêtre. Les fonctionnalités sont évaluées
So this is a simple intuitive explanation of how Viola-Jones face detection works. Read paper for more details or check out the references in Additional Resources section. Voici une explication rapide et intuitive du fonctionnement de la détection des visages Viola-Jones. Pour plus d'informations, lisez l'article ou reportez-vous aux informations de référence fournies dans la section Ressources supplémentaires.
Haar-cascade Detection in OpenCV Détection en cascade Haar dans OpenCV
OpenCV comes with a trainer as well as detector. If you want to train your own classifier for any object like car, planes etc. you can use OpenCV to create one. Its full details are given here: Cascade Classifier Training.
OpenCV dispose d'un entraîneur ainsi que d'un détecteur. Si vous souhaitez entraîner (apprendre) vos propres classificateurs pour des objets tels que des voitures et des avions, vous pouvez utiliser OpenCV pour cela. Les détails peuvent être trouvés ici. Apprendre le détecteur de cascade.
Here we will deal with detection. OpenCV already contains many pre-trained classifiers for face, eyes, smile etc. Those XML files are stored in opencv/data/haarcascades/ folder. Let's create face and eye detector with OpenCV.
Maintenant, détectons-le. OpenCV comprend déjà des détecteurs qualifiés tels que la détection des visages, la détection des yeux et la détection des sourires. Ces XML sont stockés dans le dossier opencv / data / haarcascades /. Faisons un détecteur de visage et d'yeux OpenCV.
First we need to load the required XML classifiers. Then load our input image (or video) in grayscale mode.
Tout d'abord, vous devez lire le classificateur XML donné. Ensuite, lisez l'image d'entrée (ou la vidéo) en mode échelle de gris.
python
import numpy as np
import cv2
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
eye_cascade = cv2.CascadeClassifier('haarcascade_eye.xml')
img = cv2.imread('sachin.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
Now we find the faces in the image. If faces are found, it returns the positions of detected faces as Rect(x,y,w,h). Once we get these locations, we can create a ROI for the face and apply eye detection on this ROI (since eyes are always on the face !!! ).
Trouvez maintenant le visage dans l'image. Si un visage est trouvé, la position de chaque visage détecté est renvoyée par Rect (x, y, w, h). Dès que ces emplacements sont trouvés, vous pouvez définir le retour sur investissement du visage et appliquer la détection des yeux à ce retour sur investissement. (Parce que j'ai toujours les yeux sur mon visage)
python
faces = face_cascade.detectMultiScale(gray, 1.3, 5)
for (x,y,w,h) in faces:
cv2.rectangle(img,(x,y),(x+w,y+h),(255,0,0),2)
roi_gray = gray[y:y+h, x:x+w]
roi_color = img[y:y+h, x:x+w]
eyes = eye_cascade.detectMultiScale(roi_gray)
for (ex,ey,ew,eh) in eyes:
cv2.rectangle(roi_color,(ex,ey),(ex+ew,ey+eh),(0,255,0),2)
cv2.imshow('img',img)
cv2.waitKey(0)
cv2.destroyAllWindows()
Result looks like below: Le résultat est le suivant:

Additional Resources
-# Video Lecture on Face Detection and Tracking 2. An interesting interview regarding Face Detection by Adam Harvey
Exercises
Recommended Posts