[PYTHON] Première reconnaissance faciale d'anime avec Chainer
Je voulais essayer le Deep Learning, mais avec Caffe, j'étais frustré sans avoir envie d '«écrire», mais le chainer est apparu, alors j'ai décidé de faire un essai.
Quoi qu'il en soit, j'essaierai la reconnaissance faciale d'anime, ce que j'ai toujours voulu faire. En fait, j'aimerais essayer le détecteur de visage + la classification des personnages par visage, mais je vise d'abord à classer les visages et autres.
Soit dit en passant, en ce qui concerne la reconnaissance faciale dans les animes, il existe un Detector by OpenCV + Cascade, et il le reconnaît assez bien. Mais,
―― En principe, vous ne pouvez reconnaître rien d'autre que le visage de face. ――Il n'est pas détecté même s'il est légèrement incliné.
Puisqu'il y a des problèmes tels que, je voudrais améliorer la précision de détection d'une manière ou d'une autre.
Étape 1: préparer l'image de test
J'ai décidé de le préparer moi-même, en envisageant de l'utiliser également pour d'autres tâches. Cela prend environ 20 heures. Poyo-n.
politique
- Utilisez OpenCV et lbpcascade_animeface pour découper un visage dans un cadre d'anime.
- À l'exception de l'image mal reconnue à partir de là, mettez-la dans le jeu de réponses correct.
- En utilisant à nouveau OpenCV, extrayez le cadre où le visage n'a pas été reconnu.
- À partir de l'image en 3., trouvez celle qui montre réellement le visage, découpez le visage cible et ajoutez-le au jeu de réponses correct.
- Recadrez au hasard le reste du cadre sans le visage et ajoutez-le au jeu de réponses incorrect.
- Faites pivoter chaque image de 90 degrés, 180 degrés, 270 degrés pour multiplier les données par un facteur de quatre.
- Converti en 64x64 car il était nécessaire d'avoir la même taille d'entrée en raison de la conception du réseau.
Ensemble d'entraînement
--110,525 (34355 données de visage, 76170 autres images) --AngelBeats!, Kilmy Baby, Feast ... etc. «J'avais l'intention de sélectionner celui qui semble avoir un modèle différent.
Ensemble de validation
―― 8 525 feuilles (données de face 3 045 feuilles, autres images 5 480 feuilles) --Kin Mosa
Je n'aime pas le fait que le rapport entre l'ensemble d'apprentissage et l'ensemble de validation ne soit pas le même, mais je vais passer à autre chose pour le moment.
Échantillon d'image
-Image de visage

- L'ensemble

Étape 2: créer un apprenant
CNN
network/frgnet64.py
import chainer
import chainer.functions as F
class FrgNet64(chainer.FunctionSet):
insize = 64
def __init__(self):
super(FrgNet64, self).__init__(
conv1 = F.Convolution2D(3, 96, 5, pad=2),
bn1 = F.BatchNormalization(96),
conv2 = F.Convolution2D(96, 128, 5, pad=2),
bn2 = F.BatchNormalization(128),
conv3 = F.Convolution2D(128, 256, 3, pad=1),
conv4 = F.Convolution2D(256, 384, 3, pad=1),
fc5 = F.Linear(18816, 2048),
fc6 = F.Linear(2048, 2),
)
def forward_but_one(self, x_data, train=True):
x = chainer.Variable(x_data, volatile=not train)
h = F.max_pooling_2d(F.relu(self.bn1(self.conv1(x))), 5, stride=2)
h = F.max_pooling_2d(F.relu(self.bn2(self.conv2(h))), 5, stride=2)
h = F.max_pooling_2d(F.relu(self.conv3(h)), 3, stride=2)
h = F.leaky_relu(self.conv4(h), slope=0.2)
h = F.dropout(F.leaky_relu(self.fc5(h), slope=0.2), train=train)
return self.fc6(h)
def calc_confidence(self, x_data):
h = self.forward_but_one(x_data, train=False)
return F.softmax(h)
def forward(self, x_data, y_data, train=True):
""" You must subtract the mean value from the data before. """
y = chainer.Variable(y_data, volatile=not train)
h = self.forward_but_one(x_data, train=train)
return F.softmax_cross_entropy(h, y), F.accuracy(h, y)
- Si le nombre de couches entièrement connectées est de trois, la précision peut être légèrement améliorée, mais la vitesse de traitement a considérablement diminué, nous ne l'avons donc pas utilisée.
Code d'apprentissage
network/manager.py
import numpy as np
import time
import six
from util import loader
from chainer import cuda, optimizers
class NetSet:
def __init__(self, meanpath, model, gpu=-1):
self.mean = loader.load_mean(meanpath)
self.model = model
self.gpu = gpu
self.insize = model.insize
if gpu >= 0:
cuda.init(gpu)
self.model.to_gpu()
def calc_max_label(self, prob_arr):
h, w = prob_arr.shape
labels = [0] * h
for i in six.moves.range(0, h):
label = prob_arr[i].argmax()
labels[i] = (label, prob_arr[i][label])
return labels
def forward_data_seq(self, dataset, batchsize):
sum_loss = 0
sum_accuracy = 0
for i in range(0, len(dataset), batchsize):
mini_dataset = dataset[i:i+batchsize]
x_batch, y_batch = self.create_minibatch(mini_dataset)
loss, acc = self.forward_minibatch(x_batch, y_batch)
loss_data = loss.data
acc_data = acc.data
if self.gpu >= 0:
loss_data = cuda.to_cpu(loss_data)
acc_data = cuda.to_cpu(acc_data)
sum_loss += float(loss_data) * len(mini_dataset)
sum_accuracy += float(acc_data) * len(mini_dataset)
return sum_loss, sum_accuracy
def forward_minibatch(self, x_batch, y_batch, train=False):
if self.gpu >= 0:
x_batch = cuda.to_gpu(x_batch)
y_batch = cuda.to_gpu(y_batch)
return self.model.forward(x_batch, y_batch, train=False)
def create_minibatch(self, dataset):
minibatch = np.ndarray(
(len(dataset), 3, self.insize, self.insize), dtype=np.float32)
minibatch_label = np.ndarray((len(dataset),), dtype=np.int32)
for idx, tuple in enumerate(dataset):
path, label = tuple
minibatch[idx] = loader.load_image(path, self.mean, False)
minibatch_label[idx] = label
return minibatch, minibatch_label
def create_minibatch_random(self, dataset, batchsize):
if dataset is None or len(dataset) == 0:
return self.create_minibatch([])
rs = np.random.random_integers(0, high=len(dataset) - 1, size=(batchsize,))
minidataset = []
for idx in rs:
minidataset.append(dataset[idx])
return self.create_minibatch(minidataset)
train/batch.py
import numpy as np
import sys
import time
import six
import six.moves.cPickle as pickle
from util import loader, visualizer
from chainer import cuda, optimizers
from network.manager import NetSet
class Trainer(NetSet):
""" Network utility class """
def __init__(self, trainlist, validlist, meanpath, model,
optimizer, weight_decay=0.0001, gpu=-1):
super(Trainer, self).__init__(meanpath, model, gpu)
self.trainset = loader.load_image_list(trainlist)
self.validset = loader.load_image_list(validlist)
self.optimizer = optimizer
self.wd_rate = weight_decay
if gpu >= 0:
cuda.init(gpu)
self.model.to_gpu()
optimizer.setup(model.collect_parameters())
def train_random(self, batchsize, lr_decay=0.1, valid_interval=500,
model_interval=10, log_interval=100, max_epoch=100):
epoch_iter = 0
if batchsize > 0:
epoch_iter = len(self.trainset) // batchsize + 1
begin_at = time.time()
for epoch in six.moves.range(1, max_epoch + 1):
print('epoch {} starts.'.format(epoch))
train_duration = 0
sum_loss = 0
sum_accuracy = 0
N = batchsize * log_interval
for iter in six.moves.range(1, epoch_iter):
iter_begin_at = time.time()
x_batch, y_batch = self.create_minibatch_random(self.trainset, batchsize)
loss, acc = self.forward_minibatch(x_batch, y_batch)
train_duration += time.time() - iter_begin_at
if epoch == 1 and iter == 1:
visualizer.save_model_graph(loss, 'graph.dot')
visualizer.save_model_graph(loss, 'graph.split.dot', remove_split=True)
print('model graph is generated.')
sum_loss += float(cuda.to_cpu(loss.data)) * batchsize
sum_accuracy += float(cuda.to_cpu(acc.data)) * batchsize
if iter % log_interval == 0:
throughput = batchsize * iter / train_duration
print('training: iteration={:d}, mean loss={:.8f}, accuracy rate={:.6f}, learning rate={:f}, weight decay={:f}'
.format(iter + (epoch - 1) * epoch_iter, sum_loss / N, sum_accuracy / N, self.optimizer.lr, self.wd_rate))
print('epoch {}: passed time={}, throughput ({} images/sec)'
.format(epoch, train_duration, throughput))
sum_loss = 0
sum_accuracy = 0
if iter % valid_interval == 0:
N_test = len(self.validset)
valid_begin_at = time.time()
valid_sum_loss, valid_sum_accuracy = self.forward_data_seq(self.validset, batchsize, train=False)
valid_duration = time.time() - valid_begin_at
throughput = N_test / valid_duration
print('validation: iteration={:d}, mean loss={:.8f}, accuracy rate={:.6f}'
.format(iter + (epoch - 1) * epoch_iter, valid_sum_loss / N_test, valid_sum_accuracy / N_test))
print('validation time={}, throughput ({} images/sec)'
.format(valid_duration, throughput))
sys.stdout.flush()
self.optimizer.lr *= lr_decay
self.wd_rate *= lr_decay
if epoch % model_interval == 0:
print('saving model...(epoch {})'.format(epoch))
pickle.dump(self.model, open('model-' + str(epoch) + '.dump', 'wb'), -1)
print('train finished, total duration={} sec.'
.format(time.time() - begin_at))
pickle.dump(self.model, open('model.dump', 'wb'), -1)
def forward_data_seq(self, dataset, batchsize, train=True):
sum_loss = 0
sum_accuracy = 0
for i in range(0, len(dataset), batchsize):
mini_dataset = dataset[i:i+batchsize]
x_batch, y_batch = self.create_minibatch(mini_dataset)
loss, acc = self.forward_minibatch(x_batch, y_batch, train)
loss_data = loss.data
acc_data = acc.data
if self.gpu >= 0:
loss_data = cuda.to_cpu(loss_data)
acc_data = cuda.to_cpu(acc_data)
sum_loss += float(loss_data) * len(mini_dataset)
sum_accuracy += float(acc_data) * len(mini_dataset)
return sum_loss, sum_accuracy
def forward_minibatch(self, x_batch, y_batch, train=True):
if self.gpu >= 0:
x_batch = cuda.to_gpu(x_batch)
y_batch = cuda.to_gpu(y_batch)
if train:
self.optimizer.zero_grads()
loss, acc = self.model.forward(x_batch, y_batch, train)
if train:
loss.backward()
self.optimizer.weight_decay(self.wd_rate)
self.optimizer.update()
return loss, acc
util/loader.py
import os
import numpy as np
import six.moves.cPickle as pickle
from PIL import Image
### functions to load files, such as model.dump, images, and mean file.
def unpickle(filepath):
return pickle.load(open(filepath, 'rb'))
def load_model(filepath):
""" load trained model.
If the model is trained on GPU, then you must initialize cuda-driver before.
"""
return unpickle(filepath)
def load_mean(filepath):
""" load mean file
"""
return unpickle(filepath)
def load_image_list(filepath):
""" load image-file list. Image-file list file consists of filepath and the label.
"""
tuples = []
for line in open(filepath):
pair = line.strip().split()
if len(pair) == 0:
continue
elif len(pair) > 2:
raise ValueError("list file format isn't correct: [filepath] [label]")
else:
tuples.append((pair[0], np.int32(pair[1])))
return tuples
def image2array(img):
return np.asarray(img).transpose(2, 0, 1).astype(np.float32)
def load_image(path, mean, flip=False):
image = image2array(Image.open(path))
image -= mean
if flip:
return image[:, :, ::-1]
else:
return image
Puisque main.py est désordonné, je vais extraire uniquement la partie formation.
main.py
### a function for training.
def train(trainlist, validlist, meanpath, modelname, batchsize, max_epoch=100, gpu=-1):
model = None
if modelname == "frg64":
model = FrgNet64()
elif modelname == "frg128":
model = FrgNet128()
optimizer = optimizers.MomentumSGD(lr=0.001, momentum=0.9)
trainer = batch.Trainer(trainlist, validlist, meanpath, model,
optimizer, 0.0001, gpu)
trainer.train_random(batchsize, lr_decay=0.97, valid_interval=1000,
model_interval=5, log_interval=20, max_epoch=max_epoch)
L'apprentissage utilise essentiellement le GPU, et comme la taille de l'image est petite, le côté CPU n'est pas écrit pour le multithreading.
Étape 3: apprentissage
Paramètres
| Paramètres | Définir la valeur | Remarques |
|---|---|---|
| learning rate | 0.001 | 0 pour chaque époque.Multiplier 97 |
| Mini taille de lot | 10 | |
| Atténuation du poids | 0.0001 | Chaque fois que l'époque s'écoule, le coefficient λ devient 0.Multiplier 97 |
| momentum | 0.9 | Valeur par défaut du chainer |
―― J'ai essayé de réduire le taux d'apprentissage lorsque le changement d'erreur est devenu stable, mais je l'ai arrêté car l'erreur pour l'ensemble de validation ne convergeait pas bien. ―― J'ai essayé la taille du mini lot à 100 au début, mais je l'ai réduite car la différence entre l'ensemble d'apprentissage et l'ensemble de validation était grande. ――Le coefficient d'atténuation du poids aurait pu être fixe, mais je craignais que le taux d'apprentissage et la valeur s'inversent éventuellement, alors je le réduit progressivement.
environnement
| Version etc. | |
|---|---|
| GPU | GeForce GTX TITAN X |
| Python | Python 3.4.3 |
résultat
Temps requis
Cela a pris moins de 3 heures au total et l'erreur d'apprentissage était presque 0, donc cela s'est terminé avec l'époque 30. La vitesse de traitement de l'image est approximative
- Pendant la formation 560 feuilles / sec --Validation de 780 feuilles / sec
était.
Erreur
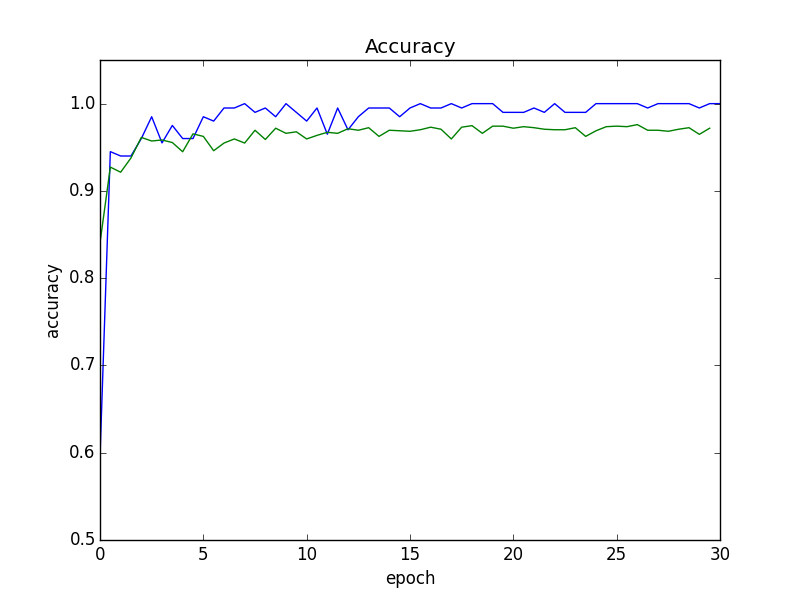
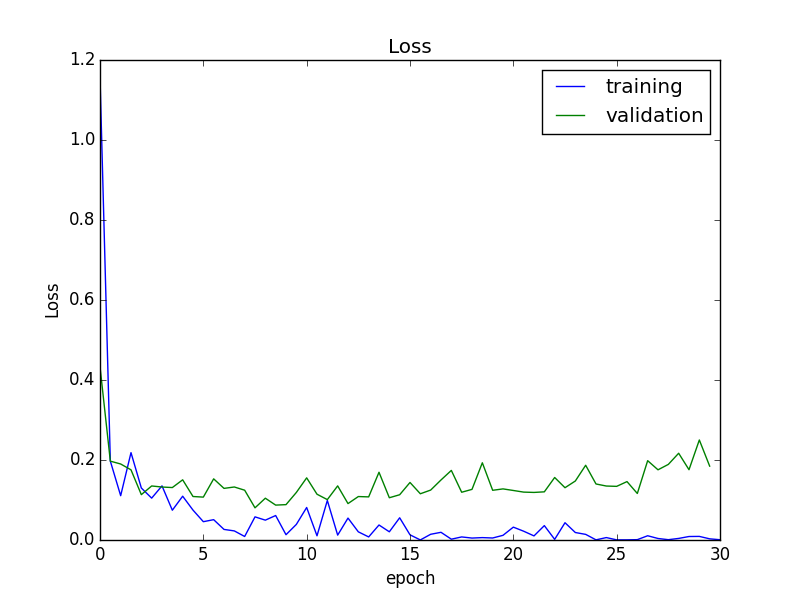
À partir du milieu, la précision de la reconnaissance a presque convergé, mais l'erreur par rapport à l'ensemble de validation a légèrement augmenté. Par conséquent, dans les expériences suivantes, nous utiliserons le modèle à la fin de l'époque 15, qui a la plus petite erreur.
Ce modèle avait une précision de reconnaissance de 95,5% pour l'ensemble de validation. Voici un exemple de cas d'échec.
Exemple de mauvaise reconnaissance
Cas reconnus par erreur comme des visages

Il semble que certaines données de test soient défectueuses (erreur d'étiquetage). ..
Cas où le visage ne peut pas être reconnu

Il y a des données sur lesquelles je n'ai pas découpé le visage proprement, mais j'ai l'impression de faire une erreur, alors je suis un peu inquiet ...
Étape 4: saisir les données réelles
Découpez l'image dans la fenêtre coulissante et placez-la dans le réseau formé. Si vous le découpez simplement, ce sera un nombre considérable de feuilles, donc après avoir réduit la largeur de l'image à 512,
- Rapport d'aspect 1: 1
- (taille, foulée) a 3 modèles de (48, 16), (72, 24), (144, 48)
Je l'ai découpé et redimensionné à la même taille que 64x64 pendant l'entraînement. (Dans l'image à portée de main, il y a 630 façons au total) (Corrigé le 8 août 2015)
De plus, si vous pouvez le mettre dans le réseau et extraire la zone candidate pour le visage, tamisez la zone en fonction de l'IoU (Intersection over Union)> = 30%, et la valeur de sortie (probabilité) du réseau est le maximum. J'en choisis un. (Je ne sais pas si la valeur absolue de cette valeur est significative) L'IoU avec des zones autres que le visage n'est pas prise en compte en particulier.
Expérience
Il est affiché en comparaison avec le résultat d'essayer avec OpenCV + lbpcascade_animeface. Cependant, les résultats peuvent changer en fonction des paramètres, donc je ne pense pas que ce soit nécessairement une comparaison juste. (Le haut est l'image détectée par CNN et le bas est l'image détectée par OpenCV) Le temps d'exécution moyen était d'environ 0,8 seconde pour CNN (GPU) et d'environ 0,35 seconde pour OpenCV (CPU).
Tout d'abord, à partir des images qui pourraient être reconnues à la fois par OpenCV et ce CNN. Comme prévu, la position du visage d'anime semble exacte.

 © Yui Hara / Yoshibunsha / Comité de production de la mosaïque Kiniro
© Yui Hara / Yoshibunsha / Comité de production de la mosaïque Kiniro
Vient ensuite l'image avec un profil que je visais cette fois. La position du cadre est délicate, mais je peux reconnaître le profil qui n'a pas été pris par OpenCV. Cependant, il y a un cadre étrange entre Alice et Shinobu. ..

 © Yui Hara / Yoshibunsha / Comité de production de la mosaïque Kiniro
© Yui Hara / Yoshibunsha / Comité de production de la mosaïque Kiniro
Finalement,

 © Koi / Yoshibunsha / Votre commande est-elle un comité de production?
© Koi / Yoshibunsha / Votre commande est-elle un comité de production?
Ah, le bac, le bac est détecté. .. Bien sûr, OpenCV l'a détecté plus précisément. triste
Résumé
En ce qui concerne le ressenti, j'estime que le nombre de cas pouvant être captés est bien supérieur à celui de la version OpenCV, mais en même temps, j'ai eu l'impression que le taux de méconnaissance des parties autres que le visage en tant que visage a également augmenté. Basé sur cela ...
Ce qui a fonctionné
- Prolifération des données d'entraînement ――Lorsque j'ai ajouté une rotation à l'image et propagé les données, la vitesse de convergence augmentait considérablement. Après tout, j'ai réalisé que la quantité de données était importante.
- Mini ajustement de la taille du lot ――Lorsque je mettais à jour les paramètres en alimentant 100 feuilles à la fois, l'erreur de formation a convergé, mais l'erreur de validation s'est rapidement stabilisée. Cependant, lorsque je l'ai réduit à 10, la précision de la validation a augmenté d'environ 2 pt, ce qui donne l'impression qu'elle était efficace telle quelle.
Points d'amélioration, réflexion, etc.
- Détecteur
- La détection est une simple fenêtre coulissante, elle prend donc un temps considérable. Pour éviter cela, nous limitons la taille de l'image recadrée, mais dans ce cas, le visage qui remplit l'écran ne peut pas être détecté. .. ――Cette fois, c'est la détection de visage, donc je ne pense pas que ce soit un gros problème, mais le rapport hauteur / largeur est fixé à 1: 1. «Je pense que j'aurais dû utiliser des données étiquetées de position depuis le début.
- Données de formation «Après tout, je pense que le montant absolu était encore faible.
- Les données de réponse incorrectes (qualité) peuvent ne pas avoir été suffisantes J'ai recadré au hasard à partir d'une image sans visage, mais il y avait de nombreuses images où l'objet lui-même était à peine réfléchi et la limite de l'objet n'a pas été capturée, donc je pense qu'il était encore faible en tant que données. .. Le taux élevé de faux positifs est probablement dû à son influence.
prochain··
Je me demande si je voudrais faire un détecteur avec les données avec l'étiquette de position. Avec la méthode actuelle, même si la précision sort, la vitesse ne sort pas, donc je voudrais essayer autour de SPP-net.
Code source
Comme la version de chainer a changé et que cela ne fonctionne pas, j'ai téléchargé le code corrigé sur Github. https://github.com/homuler/pyon2-detector/
Recommended Posts