[PYTHON] Prédire les travaux de courte durée de Weekly Shonen Jump par apprentissage automatique (Partie 1: Analyse des données)
1.Tout d'abord
Weekly Shonen Jump (ci-après appelé Jump) est le magazine de dessins animés le plus vendu au Japon [^ circulation]. Inutile de dire que je suis un grand fan.
La réunion de sérialisation du service éditorial jump est très sévère. Dans le dessin animé de fiction "Bakuman." représentant la lutte d'un écrivain de saut, le département éditorial [Enquête auprès des lecteurs de chaque numéro](https://ja.wikipedia.org/wiki/%E9%80%B1%E5%88%8A%E5%B0%91%E5%B9%B4%E3%82%B8 % E3% 83% A3% E3% 83% B3% E3% 83% 97 # .E3.82.A2.E3.83.B3.E3.82.B1.E3.83.BC.E3.83.88.E8. Basé sur 87.B3.E4.B8.8A.E4.B8.BB.E7.BE.A9), la popularité de chaque manga est évaluée et l'ordre de publication et le travail abandonné sont décidés [^] Ordre de publication]. Il n'est pas rare que la sérialisation soit interrompue dans les 10 semaines suivant le début de la sérialisation (environ un livre). C'est un monde très difficile.
Dans cet article, nous utiliserons l'apprentissage automatique pour prédire les travaux de courte durée (travaux qui seront achevés dans un délai de 10 semaines). ** Le but ultime est de prédire le travail à interrompre avant la rédaction de saut, et si le travail que vous aimez est dangereux, émettez un questionnaire pour éviter l'arrêt ** [^ Jump]. Comme nous ne pouvons pas connaître le résultat du questionnaire du lecteur, nous entrons l'historique de l'ordre de publication et indiquons s'il s'agit d'un travail de courte durée Multilayer Perceptron [^ [Multilayer] est implémenté dans TensorFlow. Pour apprendre, utilisez Web API et Cultural Agency Media Arts Database, Les informations sur la vaisselle depuis environ 46 ans sont utilisées.
Cet article sera divisé en deux parties. La première partie (cette fois) acquerra et analysera les données, et la deuxième partie (la prochaine fois) apprendra et testera les données. La figure ci-dessous fait partie du résultat de l'analyse de la première partie.

[^ Nombre de tirages]: d'après une enquête de la Japan Magazine Association. Du 1er octobre 2015 au 30 septembre 2016 Nombre d'exemplaires de magazines de bandes dessinées pour garçons, Bandes dessinées pour hommes Tirage du magazine, Tirage du magazine BD pour filles /data_002/w5.html#001), Nombre de magazines de bandes dessinées pour femmes.
[^ Ordre de publication]: Au cours du travail, l'ordre de publication et les travaux abandonnés ont été décidés principalement sur la base des résultats du questionnaire du lecteur. Selon l'article suivant, la rédaction de jump semble l'avoir démenti en déclarant: «Nous ne considérons pas nécessairement uniquement les résultats de l'enquête auprès des lecteurs». Le département éditorial de "Jump" nie les rumeurs sur le principe suprême du questionnaire ... Les lecteurs sont compliqués
[^ Multi-couches]: programmé. Nous envisagerons une autre méthode en fonction des performances.
[^ Jump]: Comme mentionné ci-dessus, en réalité, le service éditorial de saut décide du travail interrompu en tenant compte de divers facteurs. J'espère que vous comprenez cet article comme une illusion d'un fan de saut.
2. Environnement
Créez l'environnement virtuel suivant comic avec ʻanaconda`.
conda create -n comic python=3.5
source activate comic
conda install pandas matplotlib jupyter notebook scipy scikit-learn seaborn scrapy
pip install tensorflow
Le fichier yml est ici. Tensorflow et scikit-learn sont inclus car ils seront nécessaires dans la deuxième partie. .. De plus, puisque pairplot () est utilisé pour la visualisation, seaborn Est inséré.
3. Acquisition de données
3.1 Source
Base de données sur les arts médiatiques de l'Agence culturelle, Jump table for about 46 years (3 novembre 1969-25 juillet 2016) Est ouvert au public [^ actuellement].
[^ Present]: depuis le 4 avril 2017.


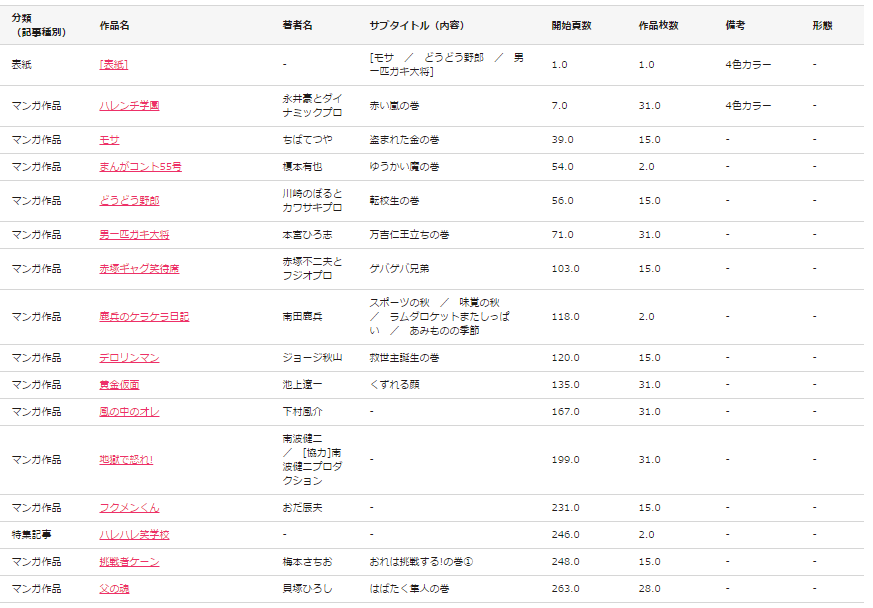
La figure ci-dessus est un exemple de recherche sur la table des matières du numéro du 3 novembre 1969 de Jump. Dans ce qui suit, les informations de table des matières seront extraites à l'aide de l 'API Web introduite dans la section des commentaires.
3.2 Web API
** Données traitées de Mon github autant que possible pour minimiser la charge sur le serveur de l'Agence culturelle. Veuillez l'obtenir **. Le cahier est ici, donc j'espère que vous pourrez l'utiliser.
Utilisez Base de données des arts médiatiques de l'agence culturelle Manga Field WebAPI pour obtenir les données nécessaires à l'analyse. Pour l'utilisation de l'API Web à l'aide de python3, reportez-vous à Jusqu'à l'accès à l'API Web qui renvoie json avec Python3 et la sortie du résultat. Je vous remercie.
import
import json
import urllib.request
from time import sleep
Obtenez des résultats de recherche de volume de magazine
Utilisez la fonction suivante search_magazine () pour rechercher les informations de volume de magazine de Weekly Shonen Jump. L'identifiant unique obtenu par cette fonction sera nécessaire pour «Obtenir des informations sur le volume du magazine» dans la section suivante.
def search_magazine(key='JUMPrgl', n_pages=25):
"""
Magazines qui incluent la clé dans «ID unique», «ID de volume de magazine» ou «code de magazine»
n_C'est une fonction pour obtenir des pages.
"""
url = 'https://mediaarts-db.bunka.go.jp/mg/api/v1/results_magazines?id=' + \
key + '&page='
magazines = []
for i in range(1, n_pages):
response = urllib.request.urlopen(url + str(i))
content = json.loads(response.read().decode('utf8'))
magazines.extend(content['results'])
return magazines
Dans l'API Web, vous pouvez spécifier "ID unique", "ID de volume de magazine" et "code de magazine" avec ʻid, et le numéro de page de recherche (100 éléments par page, la valeur par défaut est 1) avec page. Puisque Weekly Shonen Jump inclut JUMPrgl dans" l'ID de volume de magazine ", spécifiez ʻid = JUMPrgl. De plus, étant donné que les résultats de la recherche pour Weekly Shonen Jump ont un total de 24 pages (2320 résultats), il est nécessaire de spécifier 1 à 24 pour "page". Pour plus de détails, reportez-vous aux Spécifications de l'API Web.
Étant donné que l'URL de la base de données sur les arts médiatiques de l'Agence culturelle a été modifiée à partir du 31 mars 2017, l'URL de la demande (https://mediaarts-db.bunka.go.jp/webapi_proto_documents.pdf) décrite dans Spécifications de l'API Web La nouvelle URL (https: // mediaarts-db.bunka.go.jp / mg / api / v1 / results_magazines) au lieu de https: // mediaarts-db.jp / mg / api / v1 / results_magazines) Veuillez noter que vous devez utiliser.
Acquisition d'informations sur le volume du magazine
La fonction suivante ʻextract_data () extrait les informations d'index nécessaires, et save_data () `sauvegarde les informations d'index.
def extract_data(content):
"""
C'est une fonction pour obtenir les informations d'index incluses dans le contenu.
- year:Année d'émission
- no:Nombre de problèmes
- title:Titre de l'œuvre
- author:Auteur
- color:Que ce soit la couleur ou non
- pages:Nombre de pages publiées
- start_page:Page de démarrage du travail
- best:Ordre de publication compté depuis le début
- worst:Ordre de publication compté à partir de la fin du livre
"""
#Seules les œuvres de manga sont extraites.
comics = [comic for comic in content['contents']
if comic['category']=='Travail de manga']
data = []
year = int(content['basics']['date_indication'][:4])
#Le traitement des exceptions est requis car le nombre de problèmes peut ne pas être répertorié.
try:
no = int(content['basics']['number_indication'])
except ValueError:
no = content['basics']['number_indication']
for comic in comics:
title= comic['work']
if not title:
continue
#Un traitement d'exception est nécessaire car certaines œuvres n'ont pas le nombre de pages répertoriées.
#Il n'y a pas de raison particulière, mais les œuvres non répertoriées seront traitées sur 10 pages.
try:
pages = int(comic['work_pages'])
except ValueError:
pages = 10
#Pour prendre en charge les œuvres publiées en plusieurs épisodes par semaine, comme "Inumaru Dashi"
#Si le titre est déjà inclus dans les données, ne l'enregistrez pas en tant que nouvelle donnée.
#Seul le nombre de pages de données existantes sera ajouté.
if len(data) > 0 and title in [datum['title'] for datum in data]:
data[[datum['title'] for datum in
data].index(title)]['pages'] += pages
else:
data.append({
'year': year,
'no': no,
'title': comic['work'],
'author': comic['author'],
'subtitle': comic['subtitle'],
'color': int('Couleur' in comic['note']),
'pages': int(comic['work_pages']),
'start_pages': int(comic['start_page'])
})
#Afin d'exclure le mini-manga du projet, les datums d'un total de 5 pages ou moins sont exclus de la liste.
filterd_data = [datum for datum in data if datum['pages'] > 5]
for n, datum in enumerate(filterd_data):
datum['best'] = n + 1
datum['worst'] = len(filterd_data) - n
return filterd_data
C'est une histoire boueuse, mais j'ai eu du mal à gérer certains dessins animés de bâillon. Par exemple, "Inumaru Dashi" correspond essentiellement à deux épisodes par semaine. Bien qu'il ait été publié, chaque histoire est décrite dans une ligne distincte dans la base de données. Puisque ceux-ci doivent être considérés comme une seule œuvre, si le titre de la bande dessinée est dans les données, il n'est pas ajouté aux données comme une autre donnée '', et la donnée existante '' Nous sommes en train d'ajouter des pages. De plus, par exemple, "Pyu to Blow! Jaguar" est sérialisé indépendamment de sa popularité (c'était en fait incroyablement intéressant). A toujours été publié à la fin du magazine. Je m'inquiétais de savoir s'il fallait exclure cela comme valeur aberrante, mais j'ai finalement décidé de le laisser.
def save_data(magazines, offset=0, file_name='data/wj-api.json'):
"""
Pour tous les magazines inclus dans les magazines, du début au volume après offset
Obtenir des informations sur la table des matières, fichier_C'est une fonction à enregistrer dans le nom.
"""
url = 'https://mediaarts-db.bunka.go.jp/mg/api/v1/magazine?id='
#Première ligne de fichier
if offset == 0:
with open(file_name, 'w') as f:
f.write('[\n')
with open(file_name, 'a') as f:
#Accédez à l'API Web pour chaque magazine dans les magazines.
for m, magazine in enumerate(magazines[offset:]):
response = urllib.request.urlopen(url + str(magazine['id']),
timeout=30)
content = json.loads(response.read().decode('utf8'))
#L'extrait de fonction ci-dessus_data()Ensuite, extrayez les informations nécessaires.
comics = extract_data(content)
print('{0:4d}/{1}: Extracted data from {2}'.\
format(m + offset, len(magazines), url + str(magazine['id'])))
#Pour chaque bande dessinée en bande dessinée, fichier_Enregistrez les informations dans le nom.
for n, comic in enumerate(comics):
#Pour la première bande dessinée de magazine autre que le début du fichier,
#Premier',\n'Ajoutée.
if m + offset > 0 and n == 0:
f.write(',\n')
json.dump(comic, f, ensure_ascii=False)
#Sauf pour la dernière bande dessinée',\n'Ajoutée.
if not n == len(comics) - 1:
f.write(',\n')
print('{0:9}: Saved data to {1}'.format(' ', file_name))
#Veillez à faire une pause pour réduire la charge sur le serveur.
sleep(3)
#Dernière ligne de fichier
with open(file_name, 'a') as f:
f.write(']')
Afin de gérer de manière flexible les délais d'expiration, les informations de la table des matières ne sont pas traitées dans un lot, mais sont traitées de manière séquentielle de force. Notez également qu'il est mis en pause avec sleep () pour ne pas mettre de charge sur le serveur.
Là encore, l'URL de la requête (https://mediaarts-db.jp/mg/api/v1" décrite dans [Spécifications de l'API Web](https://mediaarts-db.bunka.go.jp/webapi_proto_documents.pdf) Veuillez noter que vous devez utiliser la nouvelle URL (https: // mediaarts-db.bunka.go.jp / mg / api / v1 / magazine) au lieu de / magazine).
Courir
Utilisez la fonction ci-dessus pour obtenir les informations d'index de l'API Web et enregistrez-les dans data / wj-api.json.
magazines = search_magazine()
save_data(magazines)
# 0/2320: Extracted data from https://mediaarts-db.bunka.go.jp/mg/api/v1/magazine?id=323270
# : Saved data to data/wj-api.json
# 1/2320: Extracted data from https://mediaarts-db.bunka.go.jp/mg/api/v1/magazine?id=323269
# : Saved data to data/wj-api.json
# ...
# 447/2320: Extracted data from https://mediaarts-db.bunka.go.jp/mg/api/v1/magazine?id=322833
# : Saved data to data/wj-api.json
#---------------------------------------------------------------------------
#gaierror Traceback (most recent call last)
#/home/anaconda3/envs/comic/lib/python3.5/urllib/request.py in do_open(self, http_class, req, **http_conn_args)
# 1253 try:
#-> 1254 h.request(req.get_method(), req.selector, req.data, headers)
# 1255 except OSError as err: # timeout error
S'il expire, utilisez ʻoffset` pour le redémarrer. Par exemple, si le délai d'attente se produit à «447/2320», exécutez «save_data (offset = 448)».
save_data(magazines, offset=448)
# 448/2320: Extracted data from https://mediaarts-db.bunka.go.jp/mg/api/v1/magazine?id=322832
# : Saved data to data/wj-api.json
# 449/2320: Extracted data from https://mediaarts-db.bunka.go.jp/mg/api/v1/magazine?id=322831
# : Saved data to data/wj-api.json
#...
3.3 (Référence) Grattage
En raison de mon manque de recherche, j'avais l'habitude d'obtenir des données sur la vaisselle par grattage Web jusqu'à ce que je le souligne dans la section des commentaires. Pour votre information, les paramètres à ce moment-là sont décrits, mais veuillez utiliser l'API Web du chapitre 3.2 autant que possible.
Cette fois, nous utiliserons Scrapy, qui est un framework typique. Pour plus d'informations sur Scrapy, veuillez vous référer à la section de référence à la fin de cet article. Tout d'abord, créez le projet comic pour cet article avec la commande suivante.
scrapy startproject comic
Le répertoire suivant doit être créé (Tutoriel officiel).
comic/
scrapy.cfg # deploy configuration file
comic/ # project's Python module, you'll import your code from here
__init__.py
items.py # project items definition file
pipelines.py # project pipelines file
settings.py # project settings file
spiders/ # a directory where you'll later put your spiders
__init__.py
Placez le comic_spider.py suivant dans comic / spiders.
comic_spider.py
# -*- coding: utf-8 -*-
import scrapy
class WjSpider(scrapy.Spider):
"""
start_C'est une araignée qui extrait de manière récursive les informations de table des matières suivantes à partir des URL.
Commencer ici_urls est enregistrée dans la base de données des arts médiatiques de l'Agence culturelle
Il s'agit de la plus ancienne information sur la table hebdomadaire de Shonen Jump (numéro du 3 novembre 1969).
- year:Année d'émission
- no:Nombre de problèmes
- title:Titre de l'œuvre
- author:Auteur
- color:Que ce soit la couleur ou non
- pages:Nombre de pages publiées
- start_page:Page de démarrage du travail
- best:Ordre de publication compté depuis le début
- worst:Ordre de publication compté à partir de la fin du livre
"""
name = 'wj'
start_urls = [
'http://mediaarts-db.bunka.go.jp/mg/magazines/323270'
]
n_page = 0
def parse(self, response):
"""C'est le corps principal de l'araignée."""
year = int(response.css('section.block tr td::text').extract()[3][:4])
try:
no = int(response.css('section.block tr td::text').extract()[8])
except ValueError:
no = response.css('section.block tr td::text').extract()[8]
#Seules les œuvres de manga sont extraites.
comics = [comic for comic in response.css('table.infoTbl2 tr')
if len(comic.css('td::text')) > 0
and comic.css('td::text')[0].extract() == 'Travail de manga']
data = []
for comic in comics:
title = comic.css('a::text').extract_first()
if not title:
continue
#Un traitement d'exception est nécessaire car certaines œuvres n'ont pas le nombre de pages répertoriées.
#Il n'y a pas de raison particulière, mais les œuvres non répertoriées seront traitées sur 10 pages.
try:
pages = float(comic.css('td::text')[6].extract())
except ValueError:
pages = 10
#Pour prendre en charge les œuvres publiées en plusieurs épisodes par semaine, comme "Inumaru Dashi"
#Si le titre est déjà inclus dans les données, ne l'enregistrez pas en tant que nouvelle donnée.
#Seul le nombre de pages de données existantes sera ajouté.
if len(data) > 0 and title in [datum['title'] for datum in data]:
data[[datum['title'] for datum in
data].index(title)]['pages'] += pages
else:
data.append({
'year': year,
'no': no,
'title': comic.css('a::text').extract_first(),
'author': comic.css('td::text')[3].extract(),
'subtitle': comic.css('td::text')[4].extract(),
'color': comic.css('td::text')[7].extract().count('Couleur'),
'pages': pages,
'start_page': float(comic.css('td::text')[5].extract())})
#Afin d'exclure le mini-manga du projet, les datums d'un total de 5 pages ou moins sont exclus de la liste.
filtered_data = [datum for datum in data if datum['pages'] > 5]
for n, datum in enumerate(filtered_data):
datum['best'] = n + 1
datum['worst'] = len(filtered_data) - n
yield datum
#Obtenez les informations du prochain numéro de manière récursive.
next_page = response.css('li.nxt a::attr(href)').extract_first()
if next_page is not None:
next_page = response.urljoin(next_page)
yield scrapy.Request(next_page, callback=self.parse)
** Veillez à définir DOWNLOAD_DELAY dans ** settings.py pour ne pas surcharger le serveur (il a été commenté par défaut). Aussi, je veux cracher des données en japonais, alors définissez FEED_EXPORT_ENCODING sur ʻutf-8`.
settings.py
### -----Abréviation-----
DOWNLOAD_DELAY = 3
FEED_EXPORT_ENCODING = 'utf-8'
### -----Abréviation-----
Exécutez ce qui suit pour obtenir les données.
scrapy crawl wj -o wj.json
4. Analyse des données
En fait, vous pouvez jouer beaucoup avec juste wj-api.json [^ article séparé]. Le cahier est ici, donc j'espère que vous pourrez l'utiliser. Dans ce qui suit, nous supposerons qu'il y a wj-api.json sous le répertoire data.
[^ Article séparé]: J'ai aimé jouer plus que ce à quoi je m'attendais, alors je l'ai fait en deux parties.
4.1 Préparation
Je veux afficher le titre de chaque œuvre en japonais, alors définissez-le en faisant référence à Dessiner le japonais avec matplotlib sur Ubuntu. Si vous n'utilisez pas Ubuntu, veuillez prendre les mesures appropriées.
import json
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
sns.set(style='ticks')
import matplotlib
from matplotlib.font_manager import FontProperties
font_path = '/usr/share/fonts/truetype/takao-gothic/TakaoPGothic.ttf'
font_prop = FontProperties(fname=font_path)
matplotlib.rcParams['font.family'] = font_prop.get_name()
4.2 ComicAnalyzer
Pour l'analyse wj-api.json, définissez la classe suivante ComicAnalyzer.
ComicAnalyzer
class ComicAnalyzer():
"""Cette classe lit et gère les informations de catalogue des magazines de manga."""
def __init__(self, data_path='data/wj-api.json', min_week=7, short_week=10):
"""
A l'initialisation, les données_En chemin.Extrayez les informations de table des matières du fichier json.
- self.data:Type de liste contenant toutes les informations de la table
- self.all_titles:Type de liste contenant toutes les informations sur le nom du travail
- self.serialized_titles: min_Type de liste contenant tous les titres des œuvres sérialisées sur une semaine
- self.last_year:Type numérique contenant l'année des dernières informations de table
- self.last_no:Type numérique contenant le numéro de la dernière information de table des matières
- self.end_titles: self.serialized_Des titres, moi.last_année et
self.last_Type de liste contenant tous les titres des œuvres complétées par non
- self.short_end_titles: self.end_Des titres, court_dans une semaine
Type de liste contenant les titres des œuvres sérialisées
- self.long_end_titles: self.end_Des titres, court_week+Depuis plus d'une semaine
Type de liste contenant les titres des œuvres sérialisées
"""
self.data = self.read_data(data_path)
self.all_titles = self.collect_all_titles()
self.serialized_titles = self.drop_short_titles(self.all_titles, min_week)
self.last_year = self.find_last_year(self.serialized_titles[-100:])
self.last_no = self.find_last_no(self.serialized_titles[-100:], self.last_year)
self.end_titles = self.drop_continued_titles(
self.serialized_titles, self.last_year, self.last_no)
self.short_end_titles = self.drop_long_titles(
self.end_titles, short_week)
self.long_end_titles = self.drop_short_titles(
self.end_titles, short_week + 1)
def read_data(self, data_path):
""" data_Lit le fichier json dans path et renvoie une liste de toutes les informations de table des matières."""
with open(data_path, 'r', encoding='utf-8') as f:
data = json.load(f)
return data
def collect_all_titles(self):
""" self.Renvoie une liste de tous les titres de travail extraits des données."""
titles = []
for comic in self.data:
if comic['title'] not in titles:
titles.append(comic['title'])
return titles
def extract_item(self, title='ONE PIECE', item='worst'):
""" self.Renvoie une liste de tous les éléments de titre extraits des données."""
return [comic[item] for comic in self.data if comic['title'] == title]
def drop_short_titles(self, titles, min_week):
"""Des titres, min_semaine Renvoie une liste de titres sérialisés pendant plus d'une semaine."""
return [title for title in titles
if len(self.extract_item(title)) >= min_week]
def drop_long_titles(self, titles, max_week):
"""Parmi les titres, max_semaine Renvoie une liste de titres terminés en une semaine."""
return [title for title in titles
if len(self.extract_item(title)) <= max_week]
def find_last_year(self, titles):
"""Renvoie la dernière année des magazines dans lesquels les titres sont publiés."""
return max([self.extract_item(title, 'year')[-1]
for title in titles])
def find_last_no(self, titles, year):
"""Renvoie le dernier numéro de numéro de l'année des magazines dans lesquels les titres ont été publiés."""
return max([self.extract_item(title, 'no')[-1]
for title in titles
if self.extract_item(title, 'year')[-1] == year])
def drop_continued_titles(self, titles, year, no):
"""Parmi les titres, renvoie une liste des titres qui ont été sérialisés par le numéro no de l'année."""
end_titles = []
for title in titles:
last_year = self.extract_item(title, 'year')[-1]
if last_year < year:
end_titles.append(title)
elif last_year == year:
if self.extract_item(title, 'no')[-1] < no:
end_titles.append(title)
return end_titles
def search_title(self, key, titles):
"""Renvoie une liste de titres comprenant la clé des titres."""
return [title for title in titles if key in title]
Puisqu'il s'agit d'un processus assez difficile à comprendre, il complète l'opération au moment de l'initialisation (__init __ ()).
self.all_titlescontient littéralement tous les titres. Cependant,self.all_titlescontient clairement des travaux de lecture et des travaux prévus.- Par conséquent, les œuvres sérialisées ci-dessus
min_weeksont extraites en tant queself.serialized_titles. Cependant,self.serialized_titlescontient des œuvres qui sont en cours de sérialisation au moment des dernières informations du catalogue, et la durée de sérialisation est incorrecte. Par exemple, "Devil's Blade" Est un ouvrage populaire qui est toujours en cours de sérialisation, mais la sérialisation s'est terminée dans 21 semaines. Cela ressemble à une œuvre. - Par conséquent, seules les œuvres dont la sérialisation a été (probablement) terminée au moment de la dernière information d'index dans la base de données sont extraites comme
self.end_titles.self.end_titlesest l'ensemble complet de cette analyse. - Parmi les «self.end_titles», les œuvres achevées dans les 10 semaines sont extraites en tant que «self.short_end_titles», et les œuvres qui ont continué pendant 11 semaines ou plus sont extraites en tant que «self.long_end_titles».
4.3 Analyse
Maintenant, jouons avec ComicAnalyzer.
wj = ComicAnalyzer()
Commençons par tracer l'ordre de publication (le pire) des 10 dernières œuvres de courte durée jusqu'aux 10 premières semaines. Plus la valeur était élevée, plus elle était publiée vers le début du livre.
for title in wj.short_end_titles[-10:]:
plt.plot(wj.extract_item(title)[:50], label=title[:6])
plt.xlabel('Week')
plt.ylabel('Worst')
plt.ylim(0,22)
plt.legend()

Il contient des projets (travail de voyage d'affaires [^ gag manga weather]) tels que "Gag manga weather" Je ne suis pas satisfait, mais il n'y a aucun moyen de l'exclure uniquement des informations sur la vaisselle. cette? "Saiki Kusuo" a été sérialisé pendant plus de 10 semaines ...? Dans ce cas, utilisez search_title ().
[^ Gag Manga Weather]: devrait être sérialisé dans Jump Square ([wikipedia](https://ja.wikipedia.org/wiki/%E3%82%AE%E3%83%A3%E3%82%] B0% E3% 83% 9E% E3% 83% B3% E3% 82% AC% E6% 97% A5% E5% 92% 8C)). Au 18 avril 2017, les informations d'index de Jump Square n'étaient pas encore enregistrées dans la base de données.
wj.search_title('Saiki', wj.all_titles)
# ['La difficulté Ψ de la personne super-puissante Kusuo Saiki', 'Difficulté Ψ de Saiki Kusuo']
len(wj.extract_item('La difficulté Ψ de la personne super-puissante Kusuo Saiki'))
# 7
wj.extract_item('La difficulté Ψ de la personne super-puissante Kusuo Saiki', 'year'), \
wj.extract_item('La difficulté Ψ de la personne super-puissante Kusuo Saiki', 'no')
# ([2011, 2011, 2011, 2011, 2011, 2011, 2011], [22, 27, 29, 33, 42, 43, 50])
len(wj.extract_item('Difficulté Ψ de Saiki Kusuo'))
# 201
Apparemment, dans "La difficulté Ψ de Saiki Kusuo Super-power person" Après avoir lu et publié 7 fois à titre d'essai, "[Saiki Kusuo's Ψ Difficulty](https://mediaarts-db.bunka.go.jp/mg/magazine_works/1071?ids%5B%5D=1071&ids%5B%5D] Il semble que la sérialisation de "= 1566)" ait commencé (wikipedia 9B% 84% E3% 81% AE% CE% A8% E9% 9B% A3)). Ensuite, nous afficherons l'ordre de publication des 10 premiers épisodes des hits récents (arbitraire).
target_titles = ['ONE PIECE', 'NARUTO-Naruto-', 'BLEACH', 'HUNTER×HUNTER']
for title in target_titles:
plt.plot(wj.extract_item(title)[:10], label=title[:6])
plt.xlabel('Week')
plt.ylabel('Worst')
plt.ylim(0,22)
plt.legend()

Bien qu'il ne soit pas directement lié à cet article, je m'y suis personnellement intéressé, je vais donc regarder l'ordre de publication jusqu'à 50 épisodes.
target_titles = ['ONE PIECE', 'NARUTO-Naruto-', 'BLEACH', 'HUNTER×HUNTER']
for title in target_titles:
plt.plot(wj.extract_item(title)[:100], label=title[:6])
plt.xlabel('Week')
plt.ylabel('Worst')
plt.ylim(0,22)
plt.legend()
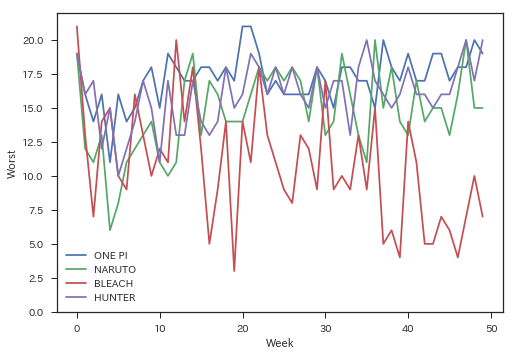
Je m'y attendais dans une certaine mesure, mais c'est quand même incroyable. Au fait, si vous regardez l'ordre de publication tout en obtenant le titre de chaque histoire en utilisant ʻextract_item () `, les amateurs de mangas peuvent sourire.
wj.extract_item('ONE PIECE', 'subtitle')[:10]
#['1.ROMANCE DAWN-Dawn of Adventure-',
# 'Épisode 2!!l'homme"Chapeau de paille Luffy"',
# 'Épisode 3"Zoro de la chasse aux pirates"Apparence',
# 'Épisode 4 Navy Captain"Hache Morgan"',
# 'Épisode 5"Roi des pirates et grand épéiste"',
# 'Épisode 6"1ère personne"',
# 'Épisode 7"ami"',
# 'Épisode 8"Nami est apparu"',
# 'Épisode 9"Femme diabolique"',
# 'Épisode 10"Une caisse de bar"']
J'ai trop fait un détour. Faisons une analyse de corrélation avec pairplot () of seaborn. Ici, je vais tracer l'ordre d'affichage de la 2ème semaine à la 6ème semaine pour le moment. J'ai raté la première semaine car la plupart des ouvrages seront publiés au début de la première semaine. Étant donné que plusieurs points se chevauchent aux mêmes coordonnées et sont très difficiles à voir, un bruit aléatoire est ajouté pour plus de commodité pour améliorer l'apparence.
end_data = pd.DataFrame(
[[wj.extract_item(title)[1] + np.random.randn() * .3,
wj.extract_item(title)[2] + np.random.randn() * .3,
wj.extract_item(title)[3] + np.random.randn() * .3,
wj.extract_item(title)[4] + np.random.randn() * .3,
wj.extract_item(title)[5] + np.random.randn() * .3,
'Travail de courte durée' if title in wj.short_end_titles else 'Travaux de poursuite']
for title in wj.end_titles])
end_data.columns = ["Worst (week2)", "Worst (week3)", "Worst (week4)",
"Worst (week5)", "Worst (week6)", "Type"]
sns.pairplot(end_data, hue="Type", palette="husl")
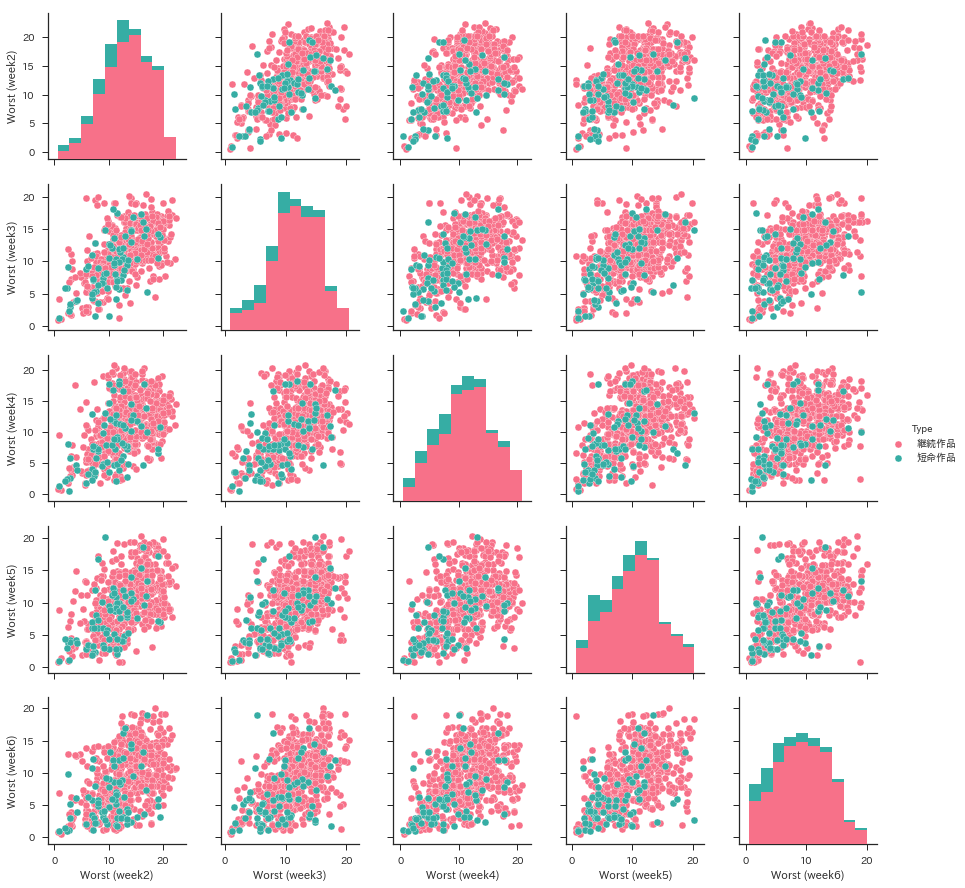
Le rose est un travail qui a duré plus de 11 semaines, et le vert est un travail de courte durée qui s'est terminé en 10 semaines. Je pensais que ce serait plus divisé, mais il semble difficile de séparer. Probablement, j'ai l'impression que des projets tels que "Gag Manga Hiyori" et des ouvrages de lecture expérimentaux tels que "Super Powerful Kusuo Saiki's Ψ Difficulty" sont bruyants. Il est normal de se distinguer par la continuité des numéros publiés, mais cela le rend indiscernable des œuvres suspendues ... C'est ennuyant. Pour le moment, j'essaierai le machine learning avec ces données telles quelles.
5. Conclusion
Quand j'ai réalisé que j'avais échappé à la réalité, j'ai fait quelque chose comme ça. La prochaine fois sera la production proprement dite, alors j'espère que vous l'apprécierez. Merci d'avoir lu pour moi jusqu'à la fin!
Les références
En créant cet article, j'ai fait référence à ce qui suit. Merci beaucoup! : arc:
- Bakuman. : Ceci est un dessin animé de dessinateur sérialisé dans Weekly Shonen Jump. C'était intéressant d'entendre une histoire assez crue comme les frais de manuscrit.
- Jusqu'à accéder à l'API Web qui renvoie json avec Python 3 et afficher le résultat: Permettez-moi de vous référer à la façon d'utiliser l'API Web en utilisant python3. Nous avons reçu.
- Introduction à Scrapy (1): C'était soigné et organisé et très utile.
- Tutoriel Scrapy: Après avoir bougé mes mains, j'ai en quelque sorte compris comment l'utiliser.
- Dessin japonais avec matplotlib sur Ubuntu: J'ai utilisé ceci comme référence lors de l'affichage du titre de l'œuvre en japonais.
Recommended Posts