[PYTHON] Analyse des données avant la génération de fonctionnalités titanesques de Kaggle
introduction
J'ai essayé de prédire les survivants du Titanic, qui est un tutoriel de kaggle.
** Cette fois, au lieu de construire un modèle d'apprentissage automatique pour prédire la probabilité de survie, nous examinerons les relations entre les données et étudierons le type de personnes qui ont survécu **.
Et j'aimerais utiliser les résultats obtenus pour compléter les valeurs manquantes et générer des quantités de caractéristiques.
1. Aperçu des données
Importez la bibliothèque et lisez et vérifiez les données du train
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
data=pd.read_csv("/kaggle/input/titanic/train.csv")
data.head()
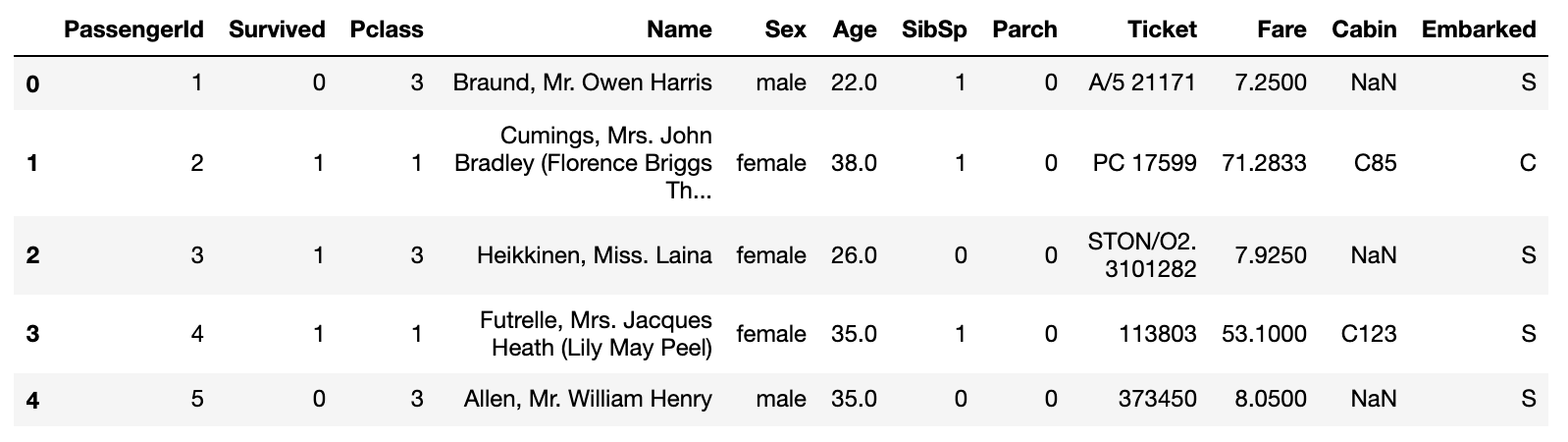 ** Types de fonctionnalités **
・ PassengerId: ID du passager
・ Survécu: vie et mort (0: mort, 1: survie)
・ Pclass: classe sociale des passagers (1: supérieur, 2: moyen, 3: inférieur)
· Nom nom
・ Sexe: sexe
・ Âge: Âge
・ SibSp: nombre de frères et de conjoints chevauchant ensemble
・ Parch: nombre de parents et d'enfants chevauchant ensemble
・ Ticket: numéro de ticket
・ Tarif: frais d'embarquement
・ Cabine: numéro de chambre
・ Embarqué: port à bord
** Types de fonctionnalités **
・ PassengerId: ID du passager
・ Survécu: vie et mort (0: mort, 1: survie)
・ Pclass: classe sociale des passagers (1: supérieur, 2: moyen, 3: inférieur)
· Nom nom
・ Sexe: sexe
・ Âge: Âge
・ SibSp: nombre de frères et de conjoints chevauchant ensemble
・ Parch: nombre de parents et d'enfants chevauchant ensemble
・ Ticket: numéro de ticket
・ Tarif: frais d'embarquement
・ Cabine: numéro de chambre
・ Embarqué: port à bord
Tout d'abord, examinons les valeurs manquantes des données, les statistiques récapitulatives et le coefficient de corrélation entre chaque entité.
#Vérifiez les valeurs manquantes
data.isnull().sum()
| Nombre de valeurs manquantes | |
|---|---|
| PassengerId | 0 |
| Survived | 0 |
| Pclass | 0 |
| Name | 0 |
| Sex | 0 |
| Age | 177 |
| SibSp | 0 |
| Parch | 0 |
| Ticket | 0 |
| Fare | 0 |
| Cabin | 687 |
| Embarked | 2 |
#Vérifier les statistiques récapitulatives
#Vous pouvez vérifier la valeur maximale, la valeur minimale, la valeur moyenne et le nombre de fractions.
#Calculé en excluant les valeurs manquantes
data.describe()
| PassengerId | Survived | Pclass | Age | SibSp | Parch | Fare | |
|---|---|---|---|---|---|---|---|
| count | 891.000000 | 891.000000 | 891.000000 | 714.000000 | 891.000000 | 891.000000 | 891.000000 |
| mean | 446.000000 | 0.383838 | 2.308642 | 29.699118 | 0.523008 | 0.381594 | 32.204208 |
| std | 257.353842 | 0.486592 | 0.836071 | 14.526497 | 1.102743 | 0.806057 | 49.693429 |
| min | 1.000000 | 0.000000 | 1.000000 | 0.420000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 223.500000 | 0.000000 | 2.000000 | 20.125000 | 0.000000 | 0.000000 | 7.910400 |
| 50% | 446.000000 | 0.000000 | 3.000000 | 28.000000 | 0.000000 | 0.000000 | 14.454200 |
| 75% | 668.500000 | 1.000000 | 3.000000 | 38.000000 | 1.000000 | 0.000000 | 31.000000 |
| max | 891.000000 | 1.000000 | 3.000000 | 80.000000 | 8.000000 | 6.000000 | 512.329200 |
#Vérifiez le coefficient de corrélation de chaque entité
data.corr()
| PassengerId | Survived | Pclass | Age | SibSp | Parch | Fare | |
|---|---|---|---|---|---|---|---|
| PassengerId | 1.000000 | -0.005007 | -0.035144 | 0.036847 | -0.057527 | -0.001652 | 0.012658 |
| Survived | -0.005007 | 1.000000 | -0.338481 | -0.077221 | -0.035322 | 0.081629 | 0.257307 |
| Pclass | -0.035144 | -0.338481 | 1.000000 | -0.369226 | 0.083081 | 0.018443 | -0.549500 |
| Age | 0.036847 | -0.077221 | -0.369226 | 1.000000 | -0.308247 | -0.189119 | 0.096067 |
| SibSp | -0.057527 | -0.035322 | 0.083081 | -0.308247 | 1.000000 | 0.414838 | 0.159651 |
| Parch | -0.001652 | 0.081629 | 0.018443 | -0.189119 | 0.414838 | 1.000000 | 0.216225 |
| Fare | 0.012658 | 0.257307 | -0.549500 | 0.096067 | 0.159651 | 0.216225 | 1.000000 |
J'aimerais voir les fonctionnalités liées à Survived from the coefficient de corrélation, mais c'est un peu difficile à comprendre s'il s'agit d'un tableau avec seulement des nombres ... Par conséquent, je supprimerai les valeurs superposées dans ce tableau et afficherai les valeurs absolues dans la carte thermique.
#Faire de la valeur une valeur absolue
corr_matrix = data.corr().abs()
#Créer une matrice triangulaire inférieure, corr_Appliquer à la matrice
map_data = corr_matrix.where(np.tril(np.ones(corr_matrix.shape), k=-1).astype(np.bool))
#Déterminez la taille de l'image et convertissez-la en carte thermique
plt.figure(figsize=(10,10))
sns.heatmap(map_data, annot=True, cmap='Greens')
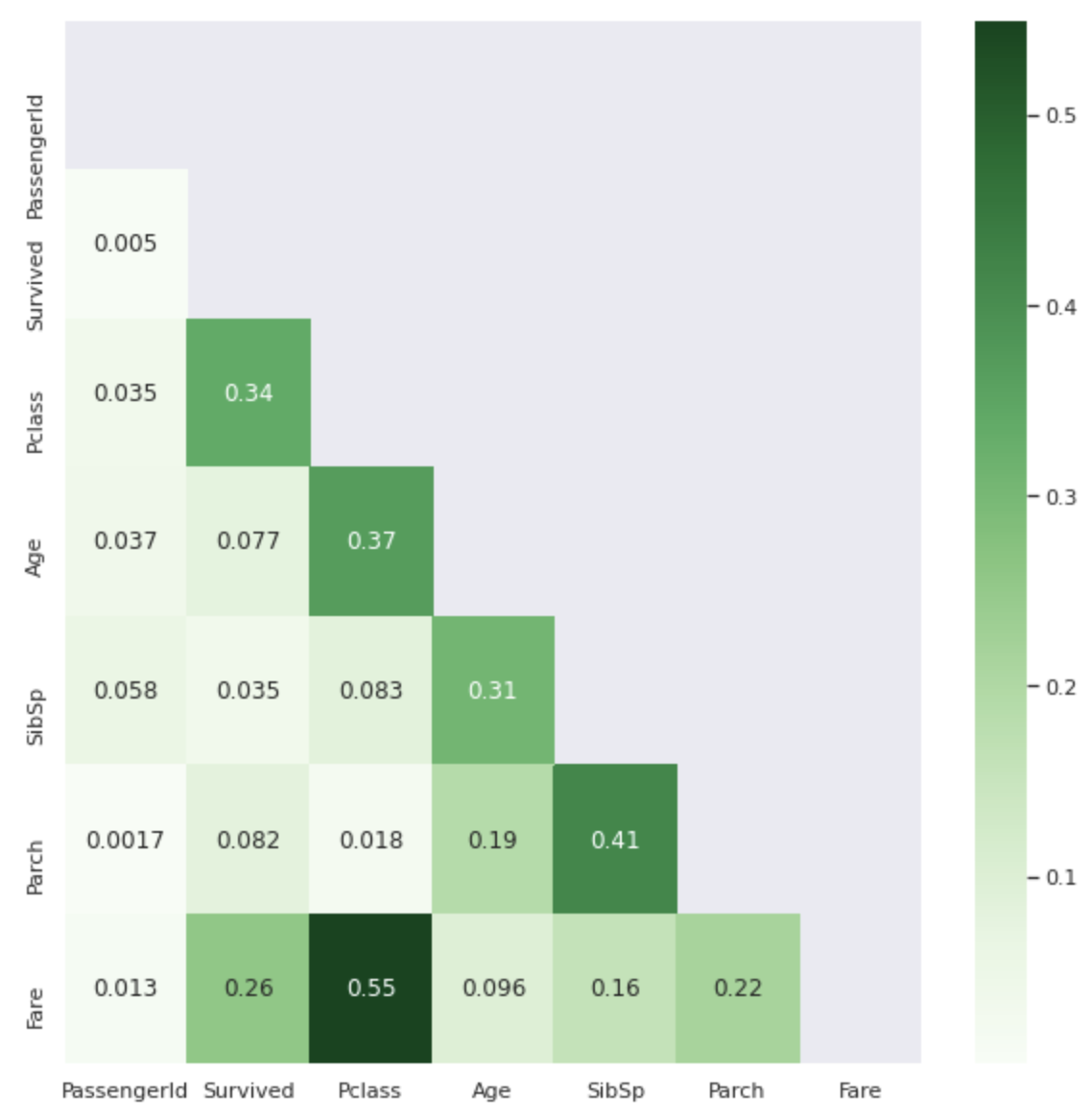 Plus la couleur est foncée, plus la valeur du coefficient de corrélation est proche de 1.
N'est-ce pas plus facile à voir que la table .corr ()?
Plus la couleur est foncée, plus la valeur du coefficient de corrélation est proche de 1.
N'est-ce pas plus facile à voir que la table .corr ()?
Je ne connais pas les fonctionnalités non numériques (nom, sexe, billet, cabine, embarqué), mais dans le tableau ci-dessus, vous pouvez voir que ** Pclass et Fare ** sont les principaux acteurs impliqués dans Survived. ..
- Pclass Tout d'abord, vérifions la relation entre Pclass et Survived.
sns.barplot(x='Pclass',y='Survived',hue='Sex', data=data)
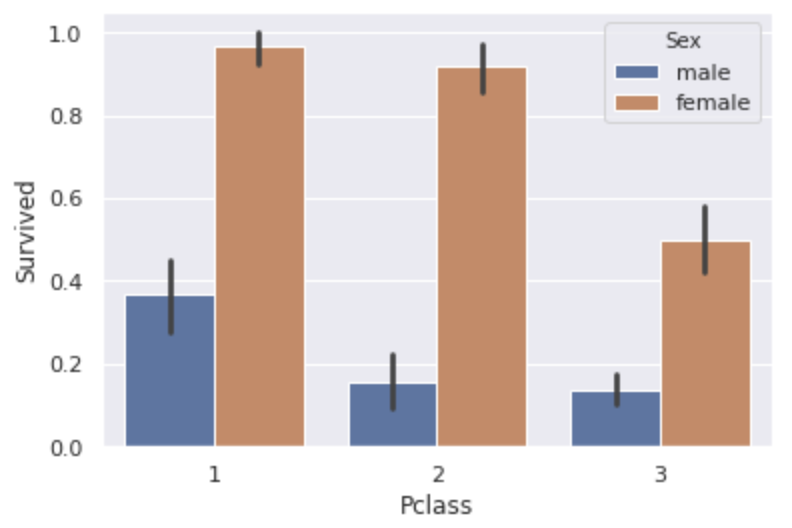 ** Plus la classe P est élevée, plus le taux de survie est élevé **.
Cela signifie-t-il que plus le rang est élevé, plus il est favorisé?
Vous pouvez également voir que ** les femmes ont plus du double du taux de survie des hommes ** dans chaque classe.
À propos, le taux de survie globale des hommes était de 18,9% et celui des femmes de 74,2%.
** Plus la classe P est élevée, plus le taux de survie est élevé **.
Cela signifie-t-il que plus le rang est élevé, plus il est favorisé?
Vous pouvez également voir que ** les femmes ont plus du double du taux de survie des hommes ** dans chaque classe.
À propos, le taux de survie globale des hommes était de 18,9% et celui des femmes de 74,2%.
- Fare Puisque la valeur minimale est 0 et la valeur maximale est 512, examinons la distribution globale.
plt.figure(figsize=(20,8))
sns.distplot(data['Fare'], bins=50, kde=False)
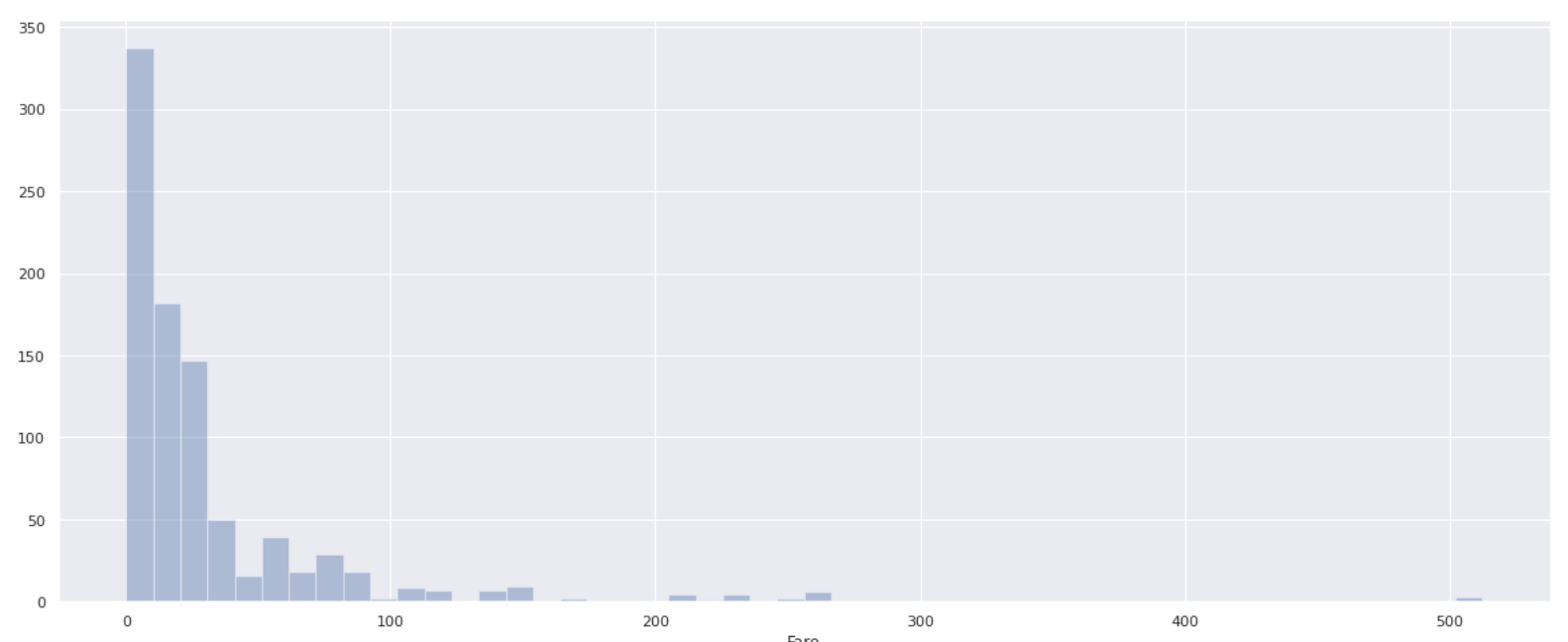
** Peu de personnes ont des frais d'embarquement de plus de 100, et la plupart des passagers ont des frais d'embarquement de 0 à 100 **. Afin d'étudier comment le taux de survie change en fonction des frais d'embarquement, divisez la valeur du tarif par 10 (0 à 10, 10 à 20, 20 à 30 ...) et calculez le taux de survie pour chacun.
#Divisé en 10'Fare_bin'Ajouter une colonne aux données
data['Fare_bin'] = pd.cut(data['Fare'],[i for i in range(0,521,10)], right=False)
bin_list = []
survived_list = []
for i in range(0,511,10):
#Trouvez le taux de survie dans chaque section
survived=data[data['Fare_bin'].isin([i])]['Survived'].mean()
#Excluez la section qui est NaN et n'ajoutez que la section pour laquelle le taux de survie est requis à la liste
if survived >= 0:
bin_list.append(f'{i}~{i+10}')
survived_list.append(survived)
#Créez un bloc de données à partir de deux listes et transformez-le en graphique
plt.figure(figsize=(20,8))
fare_bin_df = pd.DataFrame({'Fare_bin':bin_list, 'Survived':survived_list})
sns.barplot(x='Fare_bin', y='Survived', data=fare_bin_df, color='skyblue')
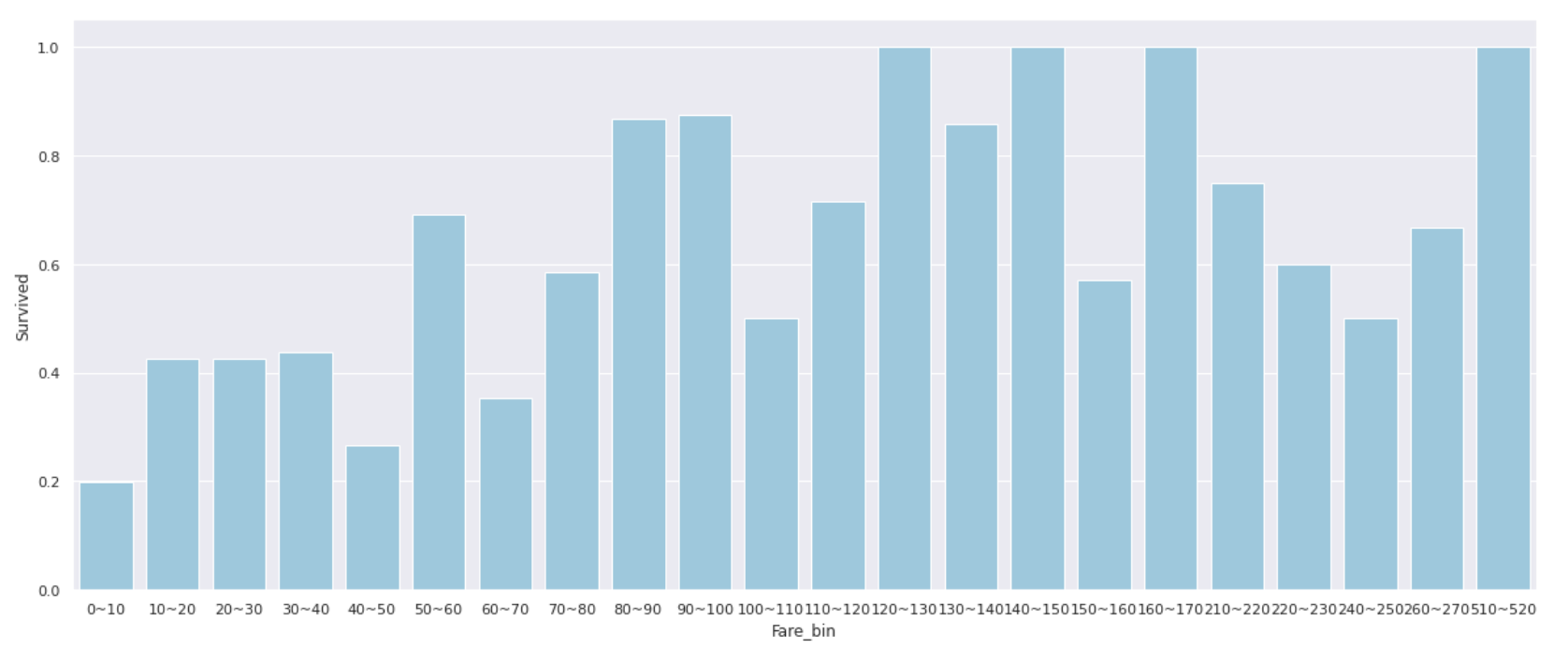
Les personnes avec un tarif de 0 à 10 ont un taux de survie extrêmement faible de 20% ou moins **, et lorsque le tarif dépasse 50, le taux de survie dépasse souvent 50% **.
Au lieu d'utiliser la valeur telle qu'elle est, il peut être bon d'utiliser __classified comme une quantité de caractéristiques telle que "Faible" pour 0 à 10 personnes et "Milieu" pour 10 à 50 personnes. ..
De plus, le coefficient de corrélation entre Pclass et Fare était de 0,55, donc quand j'ai regardé la relation entre les deux, il est devenu comme le graphique ci-dessous.
(* La classe P pour les personnes avec un tarif de 100 ou plus était 1 donc omis)
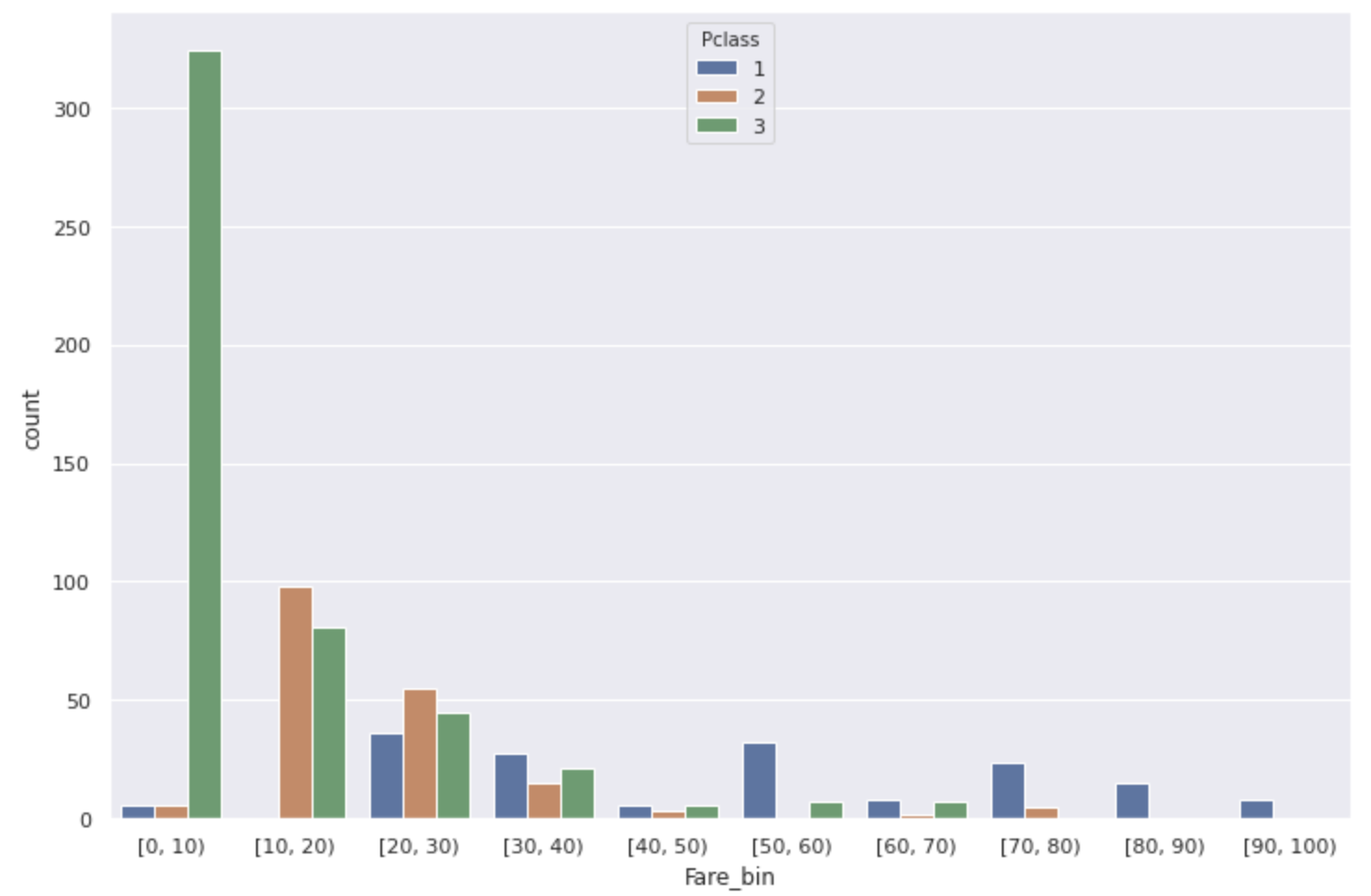 La plupart des Fare [0,10), qui ont un faible taux de survie, sont des personnes de bas rang.
La plupart des Fare [0,10), qui ont un faible taux de survie, sont des personnes de bas rang.
De plus, en regardant les données où le taux de survie est de 1,0 dans les graphiques de Survived et Fare_bin, ** les noms de famille sont communs ** ou ** les numéros de billets sont les mêmes **.
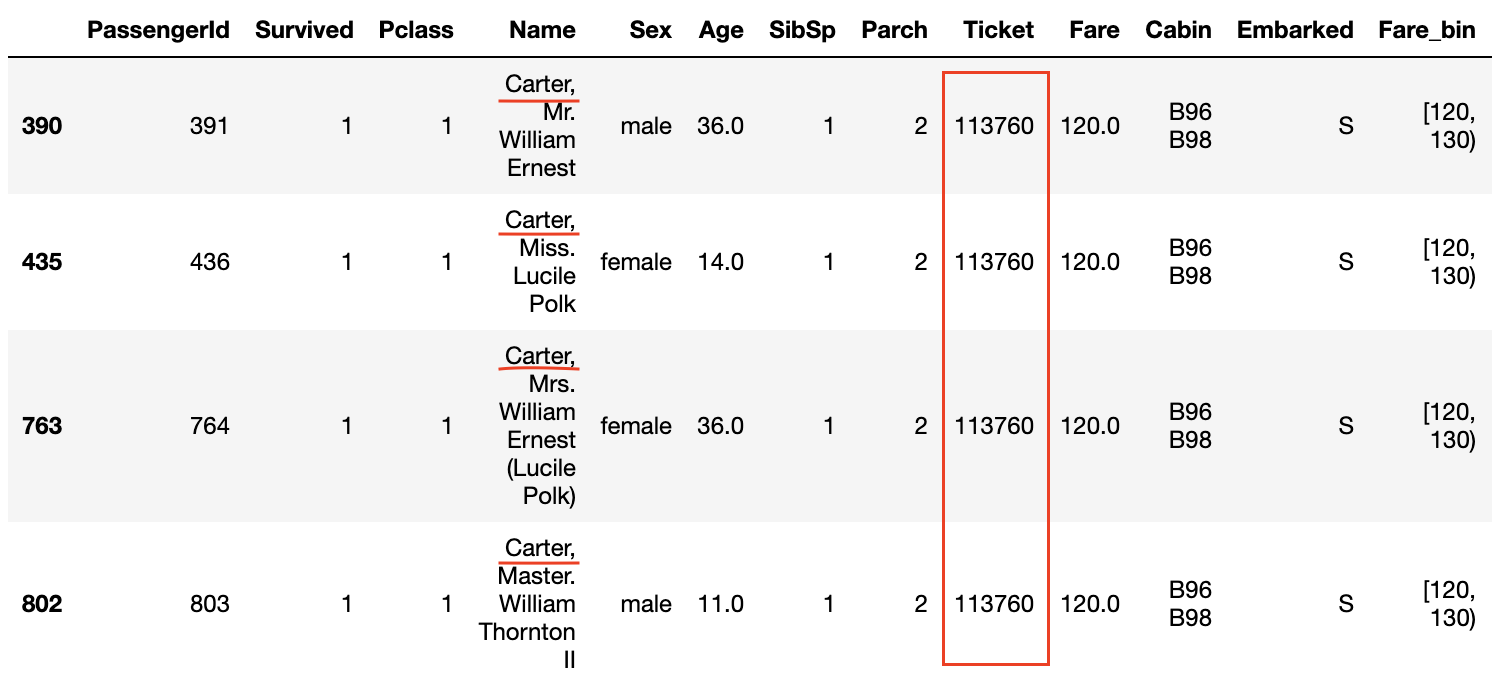
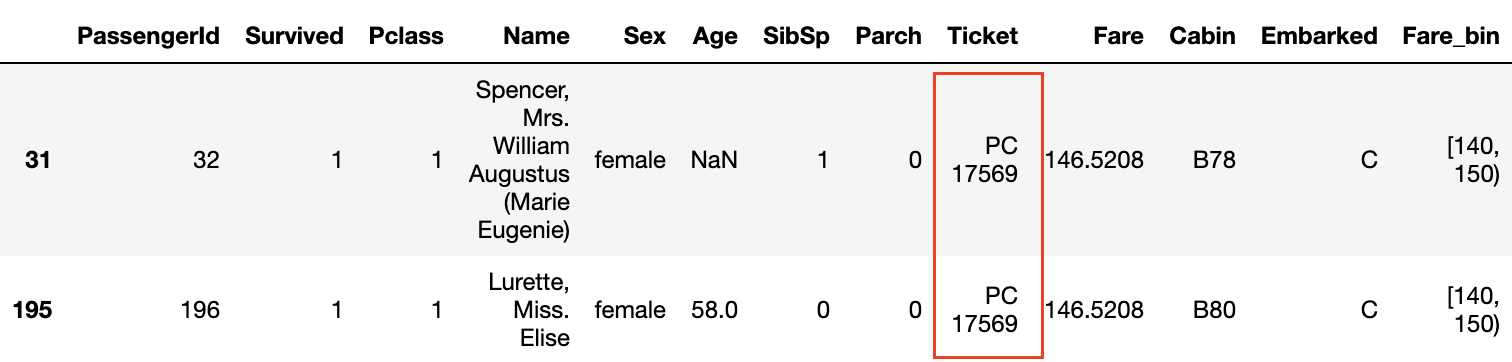
 De plus, même si la classe P est de 3 et que le tarif n'est pas élevé, il semble que le taux de survie soit élevé si les numéros de billets sont les mêmes **.
De plus, même si la classe P est de 3 et que le tarif n'est pas élevé, il semble que le taux de survie soit élevé si les numéros de billets sont les mêmes **.
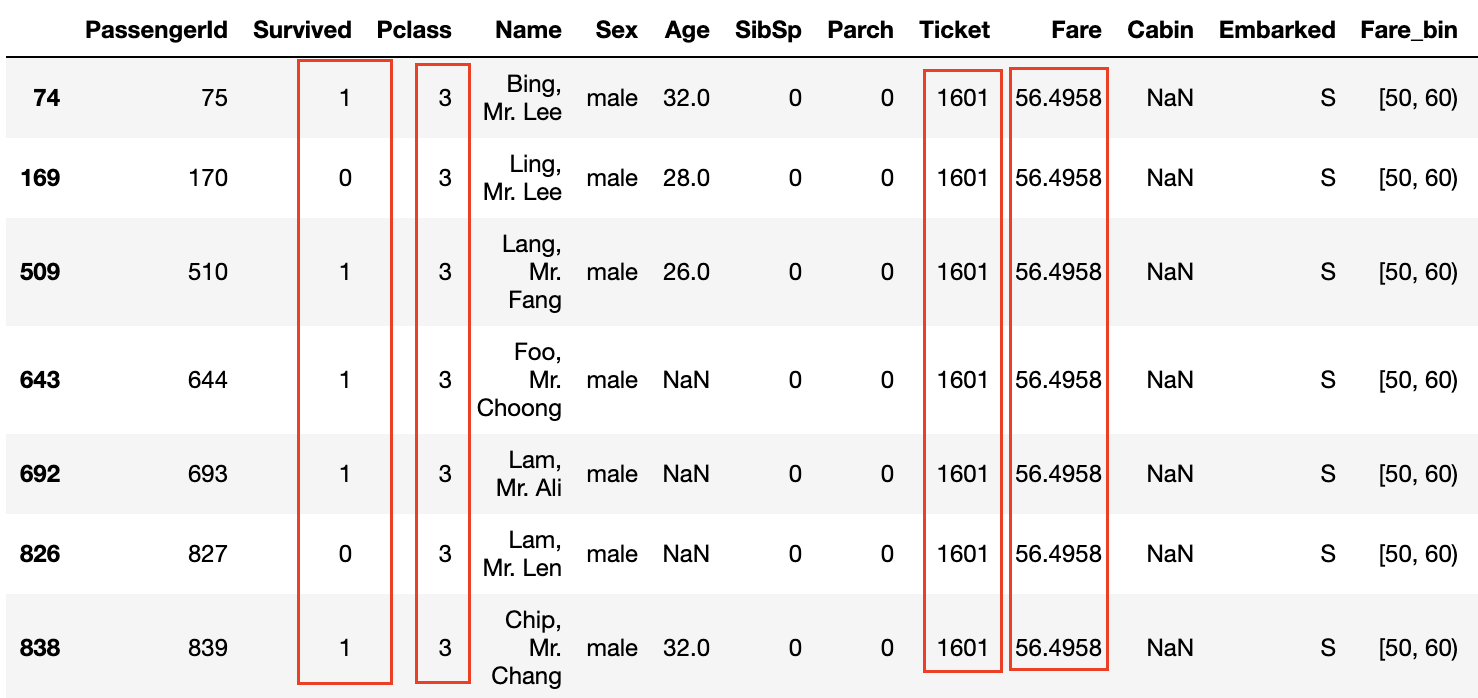 Le même numéro de billet signifie que ** la famille et les amis ont acheté le billet ensemble **, et ils ont pu agir ensemble à bord et s'entraider lorsqu'ils s'échappent du navire. Il semble que.
Le même numéro de billet signifie que ** la famille et les amis ont acheté le billet ensemble **, et ils ont pu agir ensemble à bord et s'entraider lorsqu'ils s'échappent du navire. Il semble que.
Voyons s'il y a une différence de taux de survie en fonction du nombre de membres de la famille et du numéro de billet.
4. SibSP et Parch
En utilisant les valeurs de SibSp et Parch basées sur les données du Titanic, créons une quantité caractéristique «Taille de la famille» qui indique le nombre de familles à bord du Titanic.
#Family_Créer une quantité de fonction de taille
data['Family_size'] = data['SibSp']+data['Parch']+1
fig,ax = plt.subplots(1,2,figsize=(20,8))
plt.figure(figsize=(12,8))
#Représenter graphiquement le nombre de survivants et de décès
sns.countplot(data['Family_size'],hue=data['Survived'], ax=ax[0])
#Family_Trouvez le taux de survie pour chaque taille
sns.barplot(x='Family_size', y='Survived',data=data, color='orange', ax=ax[1])
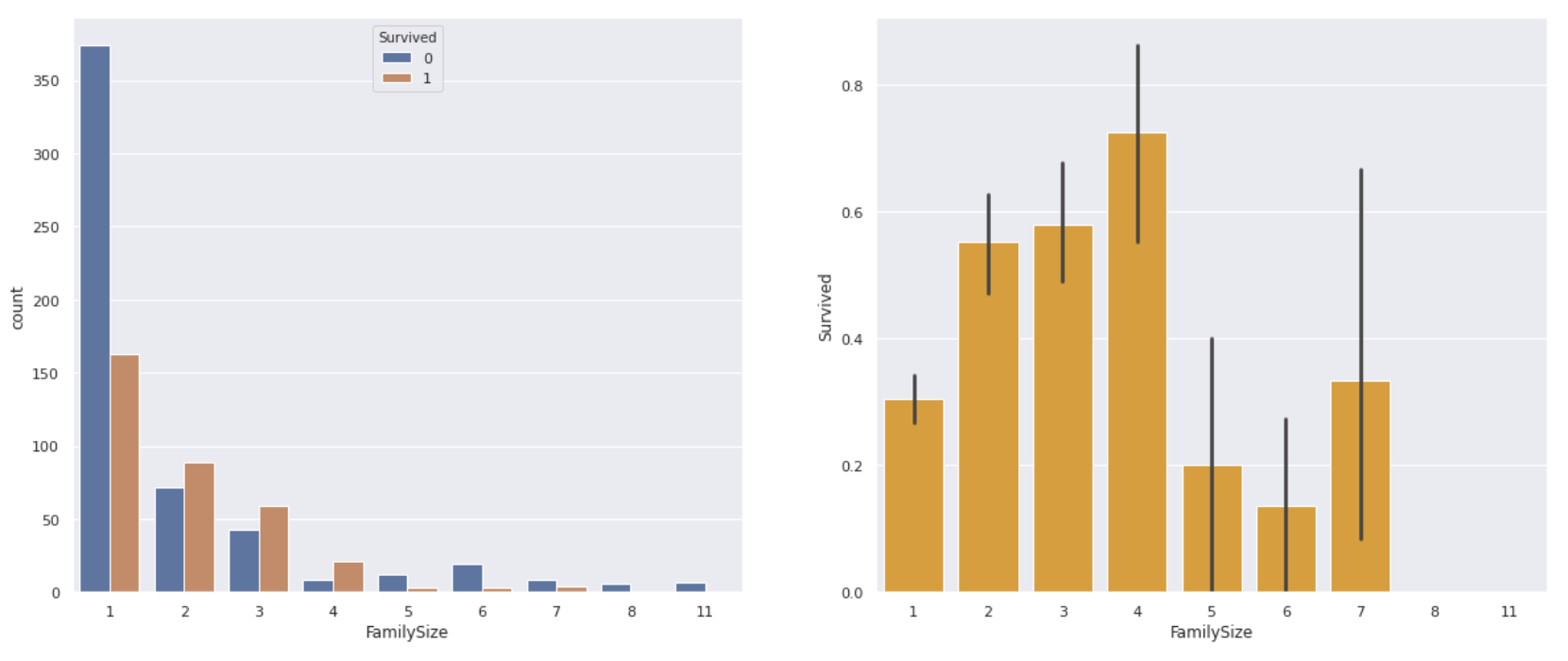
** Le tour d'une personne avait un taux de survie plus faible que le tour d'une personne, et la famille de quatre personnes avait le taux de survie le plus élevé. ** Au contraire, si le nombre de membres de la famille est trop important, il semble qu'il ait été difficile d'agir ensemble ou de survivre.
Comme Fare, il semble qu'il puisse être utilisé comme montant de fonction en le classant en environ 4 en fonction du nombre de membres de la famille.
- Ticket Mettez le nombre de numéros de billets en double dans la colonne "Ticket_count" Avec cela, il semble que nous puissions voir non seulement le taux de survie non seulement de la famille, mais aussi le taux de survie des ** (probablement) amis qui sont montés à bord du navire **.
#Ticket_Créer une colonne pour le nombre
data['Ticket_count'] = data.groupby('Ticket')['PassengerId'].transform('count')
#Trouver le taux de survie
plt.figure(figsize=(12,8))
sns.barplot(x='Ticket_count', y='Survived',data=data, color='skyblue')
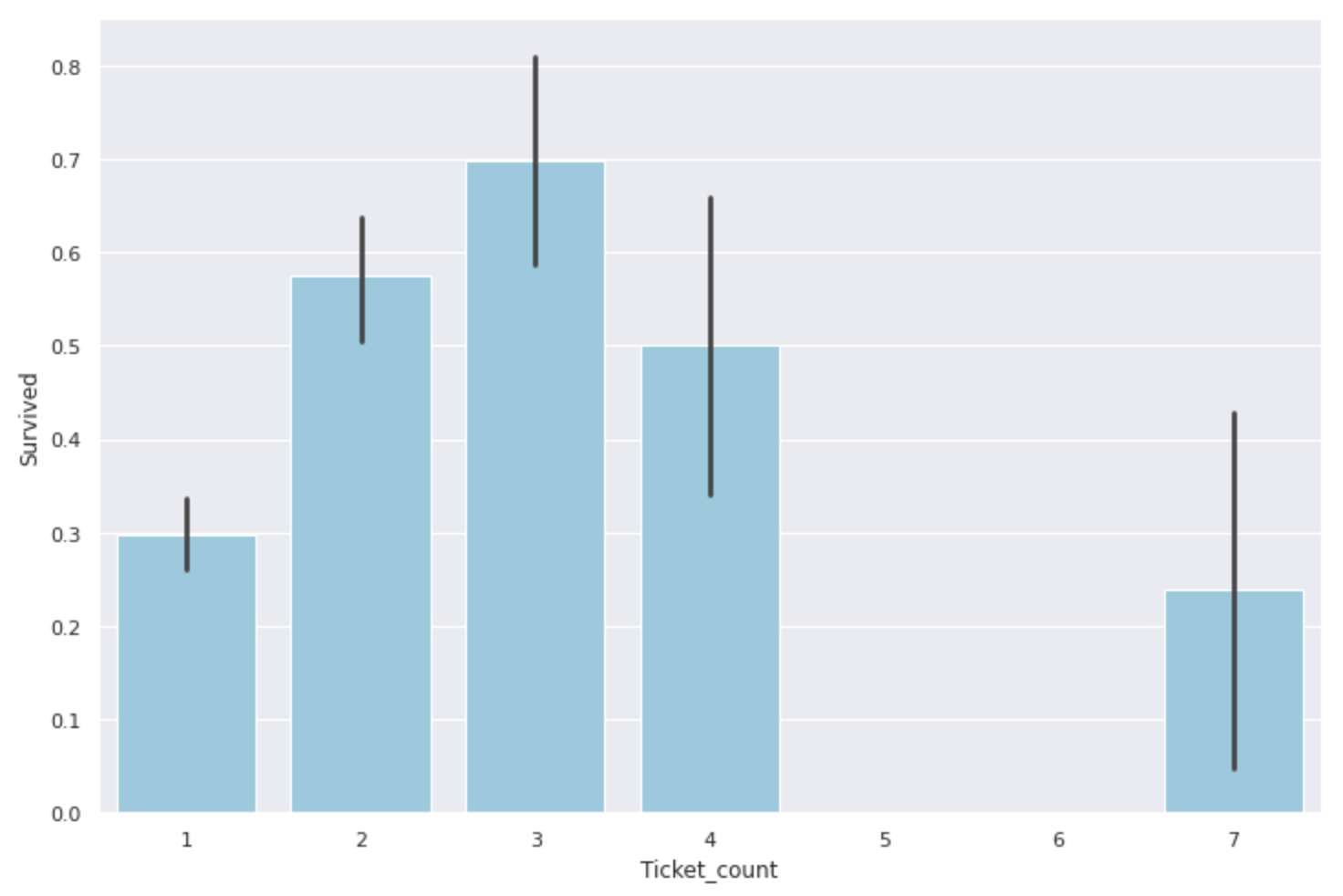
Comme pour le nombre de membres de la famille, ** les groupes de 2 à 4 personnes sont les plus utiles et les groupes de 1 personne ou de 5 personnes ou plus ont un faible taux de survie **. Semblable à Fare et Family_size, cela peut également être classé comme une quantité d'entités.
Maintenant, approfondissons les informations que vous obtenez de vos billets. Je me suis référé à ce site pour la classification détaillée des billets. journal de pyhaya: analyse des données Titanic de Kaggle
Il y a des numéros de billets avec uniquement des chiffres et ceux avec des chiffres et des alphabets, nous allons donc les classer.
#Obtenez un billet à numéro uniquement
num_ticket = data[data['Ticket'].str.match('[0-9]+')].copy()
num_ticket_index = num_ticket.index.values.tolist()
#Billets avec uniquement des numéros supprimés des données d'origine et le reste contient des alphabets
num_alpha_ticket = data.drop(num_ticket_index).copy()
Voyons d'abord comment les numéros de ticket avec uniquement des numéros sont distribués.
#Le numéro du ticket étant saisi sous forme de chaîne de caractères, il est converti en valeur numérique
num_ticket['Ticket'] = num_ticket['Ticket'].apply(lambda x:int(x))
plt.figure(figsize=(12,8))
sns.jointplot(x='PassengerId', y='Ticket', data=num_ticket)
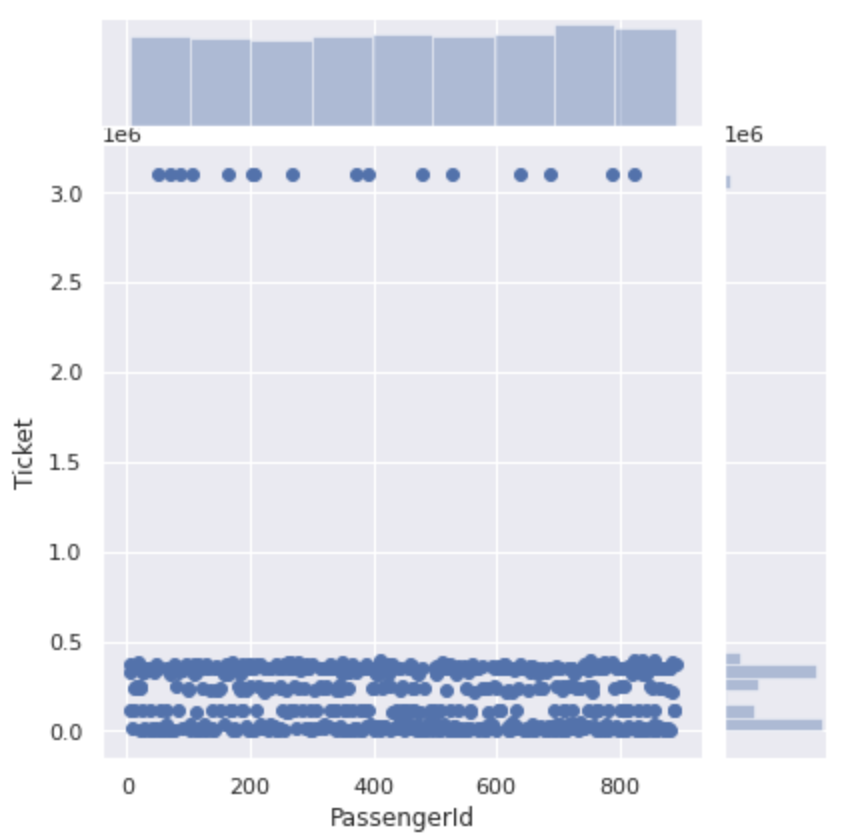 Il est grossièrement divisé en nombres de 500 000 ou moins et en nombres de 300 000 ou plus.
Si vous regardez de plus près la section de 0 à 500000, le numéro de ticket pour cette section est divisé en quatre.
Il est grossièrement divisé en nombres de 500 000 ou moins et en nombres de 300 000 ou plus.
Si vous regardez de plus près la section de 0 à 500000, le numéro de ticket pour cette section est divisé en quatre.
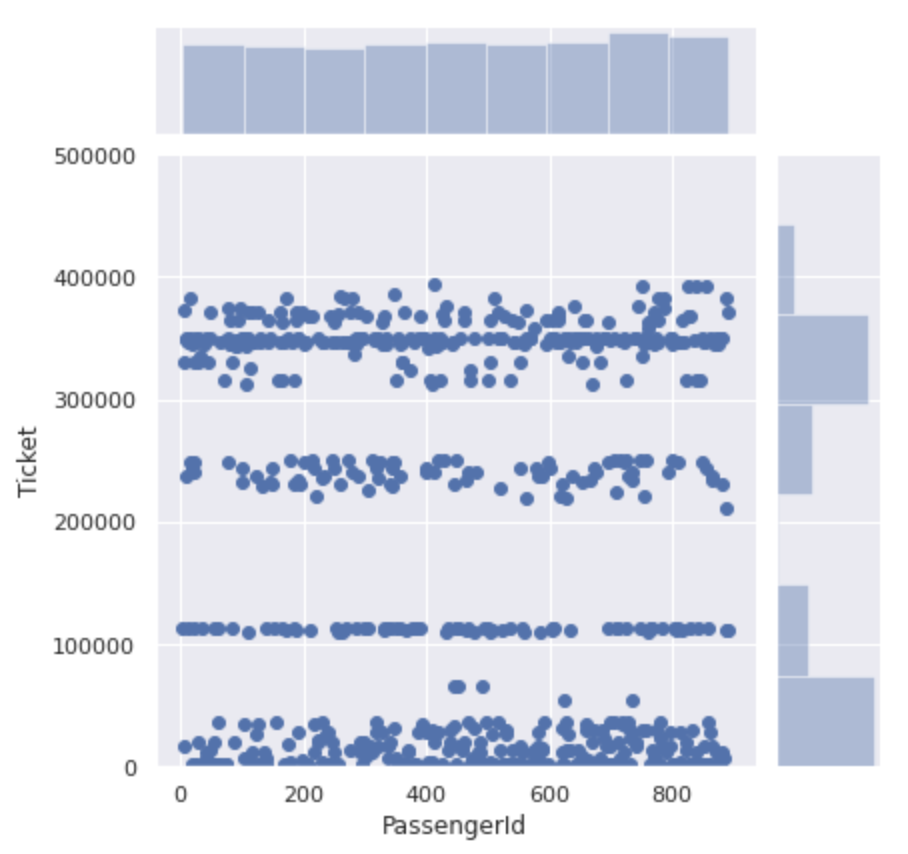 Il semble que les numéros de billets ne sont pas seulement des numéros de série, mais ** il existe un groupe pour chaque numéro **.
Classifions cela en groupe et voyons la différence de taux de survie de chacun.
Il semble que les numéros de billets ne sont pas seulement des numéros de série, mais ** il existe un groupe pour chaque numéro **.
Classifions cela en groupe et voyons la différence de taux de survie de chacun.
#0~Les billets avec 99999 numéros sont en classe 0
num_ticket['Ticket_bin'] = 0
num_ticket.loc[(num_ticket['Ticket']>=100000) & (num_ticket['Ticket']<200000),'Ticket_bin'] = 1
num_ticket.loc[(num_ticket['Ticket']>=200000) & (num_ticket['Ticket']<300000),'Ticket_bin'] = 2
num_ticket.loc[(num_ticket['Ticket']>=300000) & (num_ticket['Ticket']<400000),'Ticket_bin'] = 3
num_ticket.loc[(num_ticket['Ticket']>=3000000),'Ticket_bin'] = 4
plt.figure(figsize=(12,8))
sns.barplot(x='Ticket_bin', y='Survived', data=num_ticket)
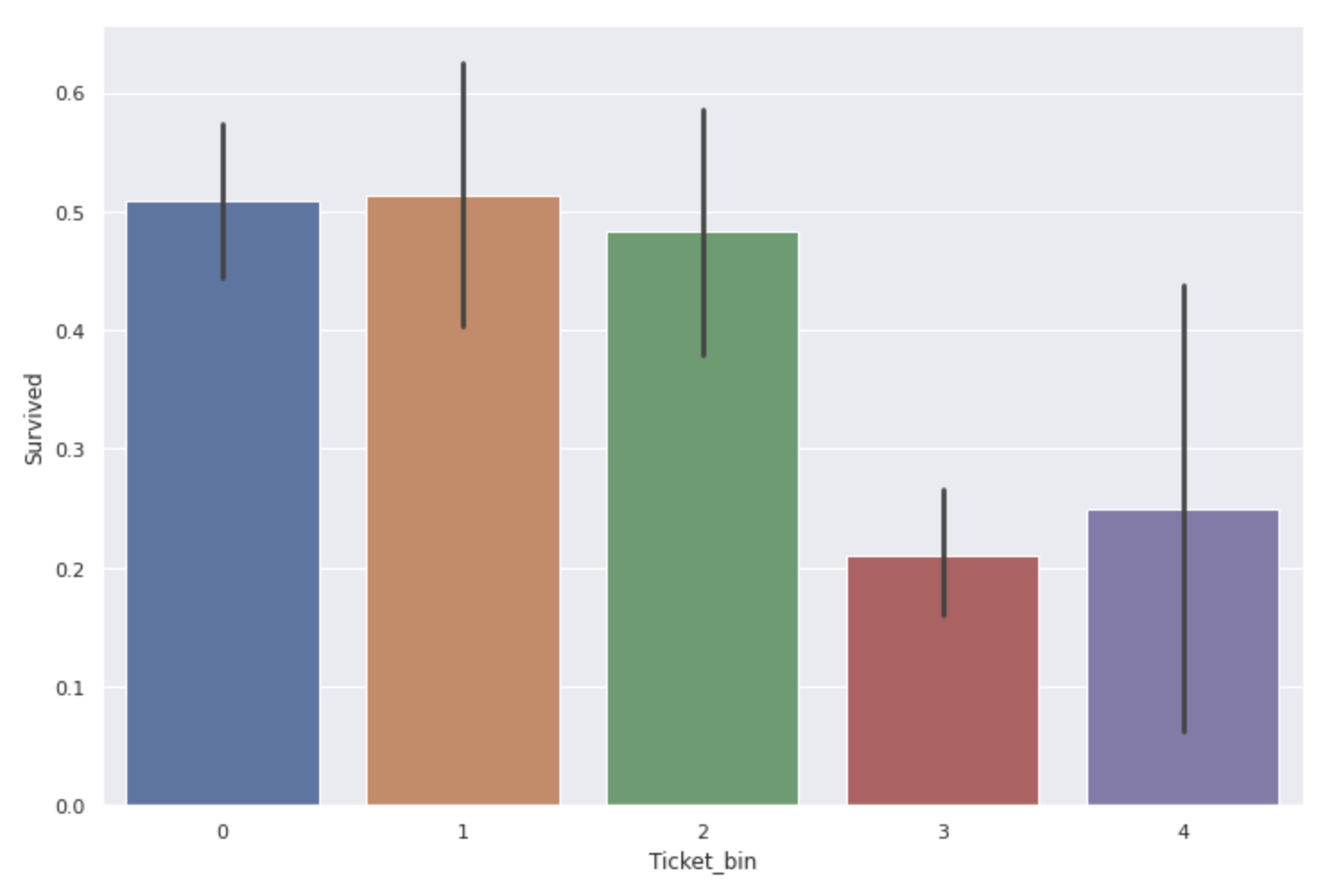 ** Le taux de survie des personnes avec des numéros de billets de 300000 ~ 400000 et 3000000 ou plus est considérablement faible **.
** Le taux de survie des personnes avec des numéros de billets de 300000 ~ 400000 et 3000000 ou plus est considérablement faible **.
Ensuite, nous examinerons les nombres et les tickets alphabétiques de la même manière. Tout d'abord, vérifions de quel type il existe.
#Trier par type pour une visualisation facile
sorted(num_alpha_ticket['Ticket'].value_counts().items())
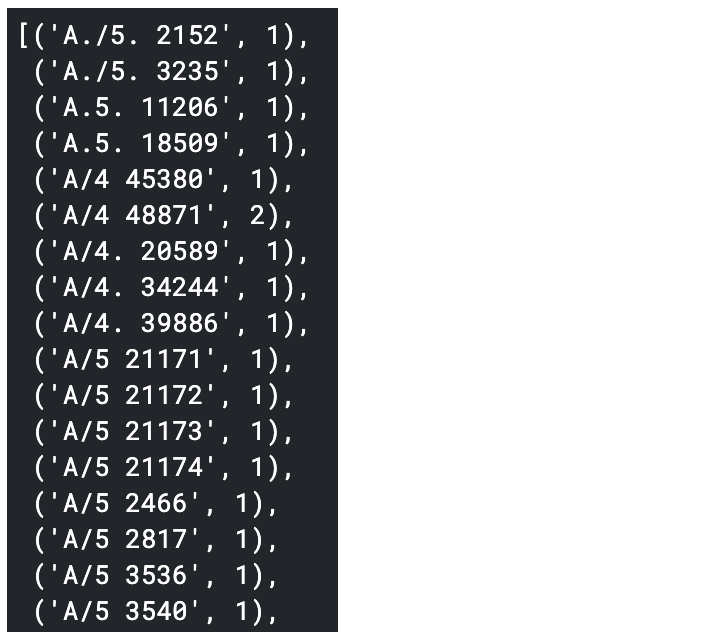 Comme il existe de nombreux types, les classes 1 à 10 sont attribuées à ceux qui ont un certain nombre, et les classes avec un petit nombre sont collectivement mises à 0.
(Le code couleur du code a changé en raison de l'influence de '' ...)
Comme il existe de nombreux types, les classes 1 à 10 sont attribuées à ceux qui ont un certain nombre, et les classes avec un petit nombre sont collectivement mises à 0.
(Le code couleur du code a changé en raison de l'influence de '' ...)
num_alpha_ticket['Ticket_bin'] = 0
num_alpha_ticket.loc[num_alpha_ticket['Ticket'].str.match('A.+'),'Ticket_bin'] = 1
num_alpha_ticket.loc[num_alpha_ticket['Ticket'].str.match('C.+'),'Ticket_bin'] = 2
num_alpha_ticket.loc[num_alpha_ticket['Ticket'].str.match('C\.*A\.*.+'),'Ticket_bin'] = 3
num_alpha_ticket.loc[num_alpha_ticket['Ticket'].str.match('F\.C.+'),'Ticket_bin'] = 4
num_alpha_ticket.loc[num_alpha_ticket['Ticket'].str.match('PC.+'),'Ticket_bin'] = 5
num_alpha_ticket.loc[num_alpha_ticket['Ticket'].str.match('S\.+.+'),'Ticket_bin'] = 6
num_alpha_ticket.loc[num_alpha_ticket['Ticket'].str.match('SC.+'),'Ticket_bin'] = 7
num_alpha_ticket.loc[num_alpha_ticket['Ticket'].str.match('SOTON.+'),'Ticket_bin'] = 8
num_alpha_ticket.loc[num_alpha_ticket['Ticket'].str.match('STON.+'),'Ticket_bin'] = 9
num_alpha_ticket.loc[num_alpha_ticket['Ticket'].str.match('W\.*/C.+'),'Ticket_bin'] = 10
plt.figure(figsize=(12,8))
sns.barplot(x='Ticket_bin', y='Survived', data=num_alpha_ticket)
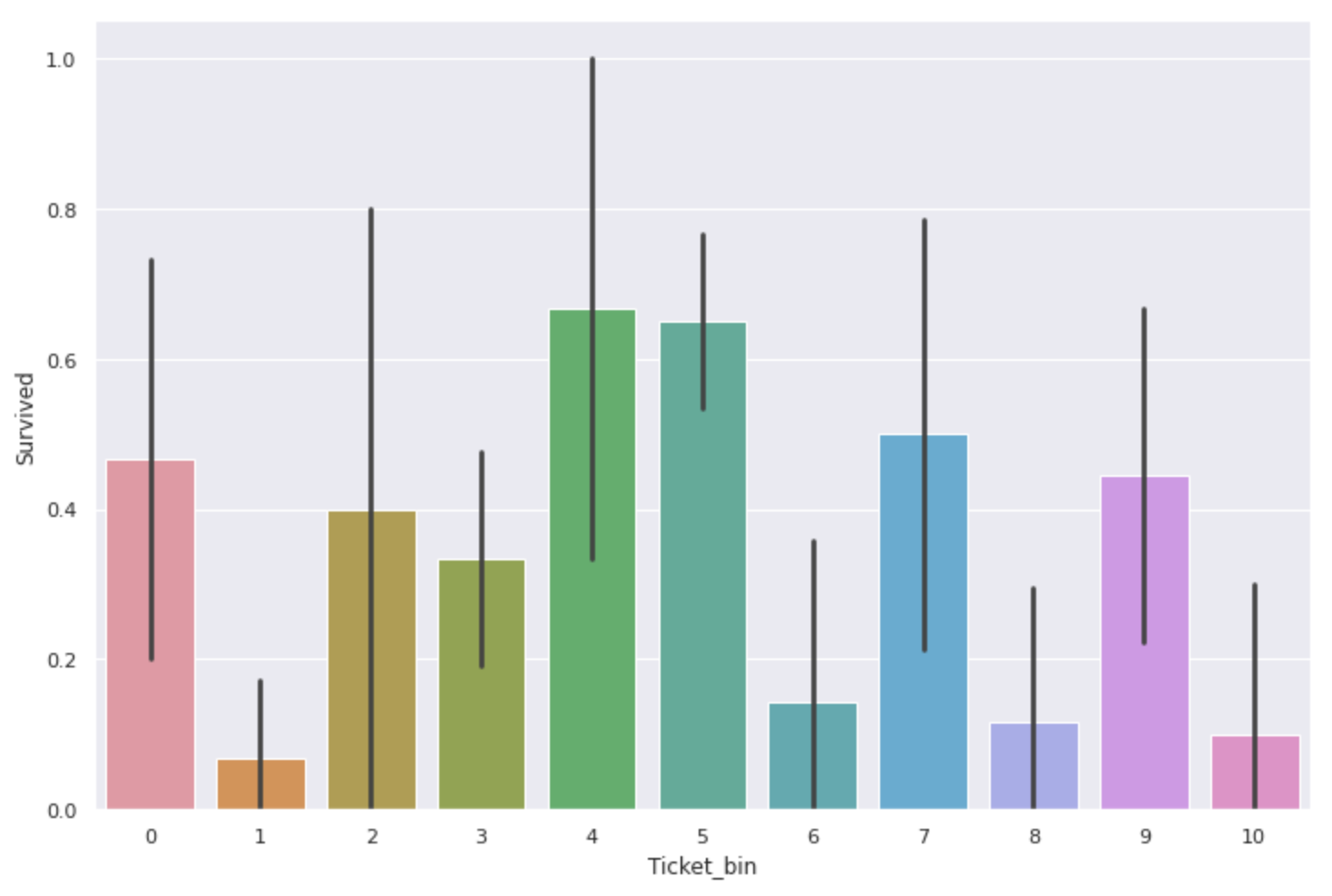 Il y avait aussi une différence de taux de survie ici aussi. ** Ceux avec "F.C" et "PC" sont particulièrement chers **
Cependant, le nombre total de données sur les billets, y compris les alphabets, n'est que de 230, et le nombre de données n'est qu'environ un tiers de celui des billets avec uniquement des chiffres, donc ** la valeur du taux de survie elle-même peut ne pas être très crédible **. Peut être.
Il y avait aussi une différence de taux de survie ici aussi. ** Ceux avec "F.C" et "PC" sont particulièrement chers **
Cependant, le nombre total de données sur les billets, y compris les alphabets, n'est que de 230, et le nombre de données n'est qu'environ un tiers de celui des billets avec uniquement des chiffres, donc ** la valeur du taux de survie elle-même peut ne pas être très crédible **. Peut être.
Il semble que le taux de survie change en fonction du numéro de billet ** car les nombres sont divisés en fonction de l'emplacement et du rang de la salle **. Jetons un coup d'œil aux relations entre Pclass et Fare, qui sont susceptibles d'être liées aux billets.
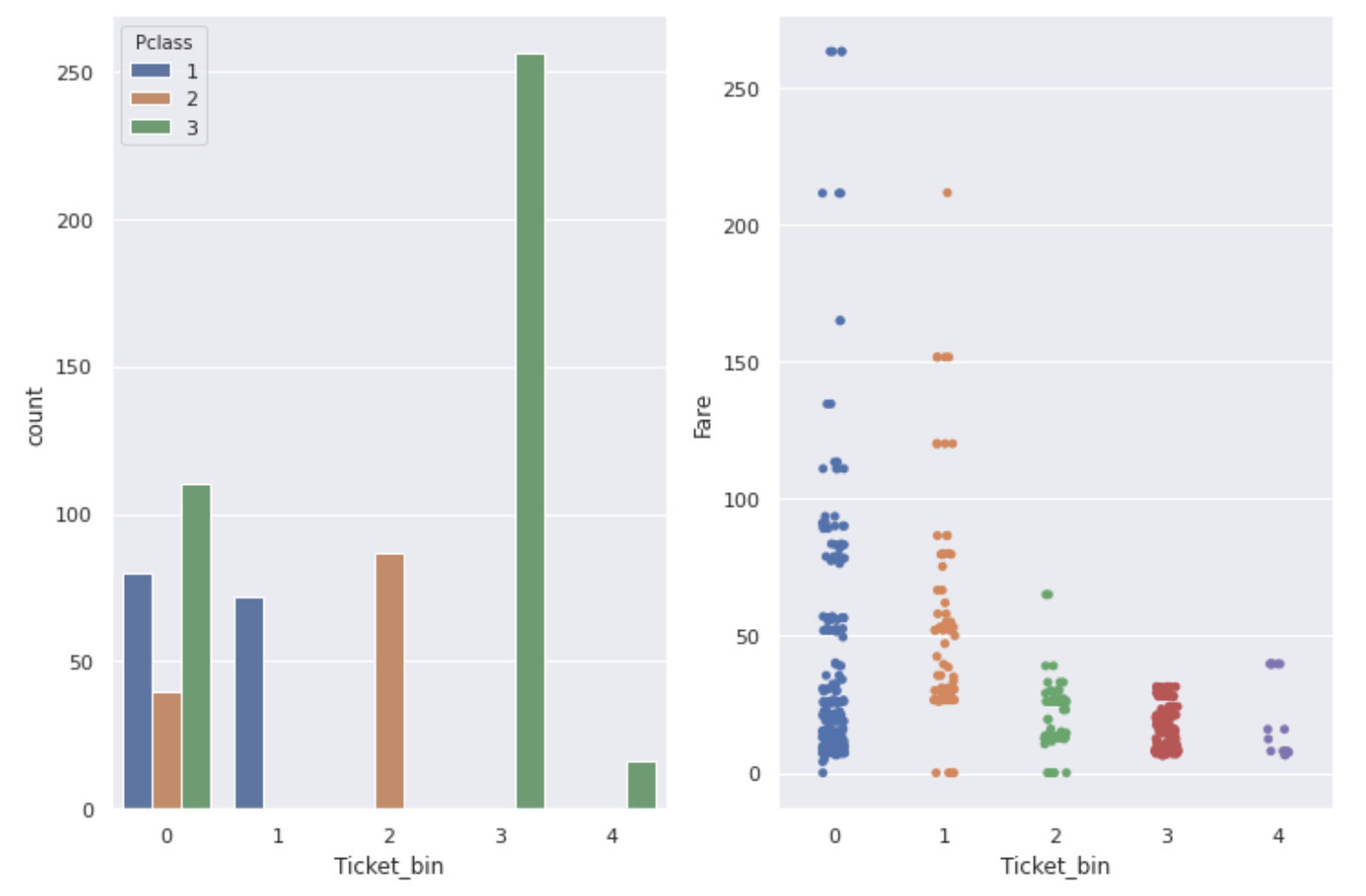
↓ À propos des billets avec uniquement des numéros
fig,ax = plt.subplots(1,2,figsize=(12,8))
sns.countplot(num_ticket['Ticket_bin'], hue=num_ticket['Pclass'], ax=ax[0])
sns.stripplot(x='Ticket_bin', y='Fare', data=num_ticket, ax=ax[1])
 ↓ À propos des tickets numérotés et alphabétiques
↓ À propos des tickets numérotés et alphabétiques
fig,ax = plt.subplots(1,2,figsize=(12,8))
sns.countplot(num_alpha_ticket['Ticket_bin'], hue=num_alpha_ticket['Pclass'], ax=ax[0])
sns.stripplot(x='Ticket_bin', y='Fare', data=num_alpha_ticket, ax=ax[1])
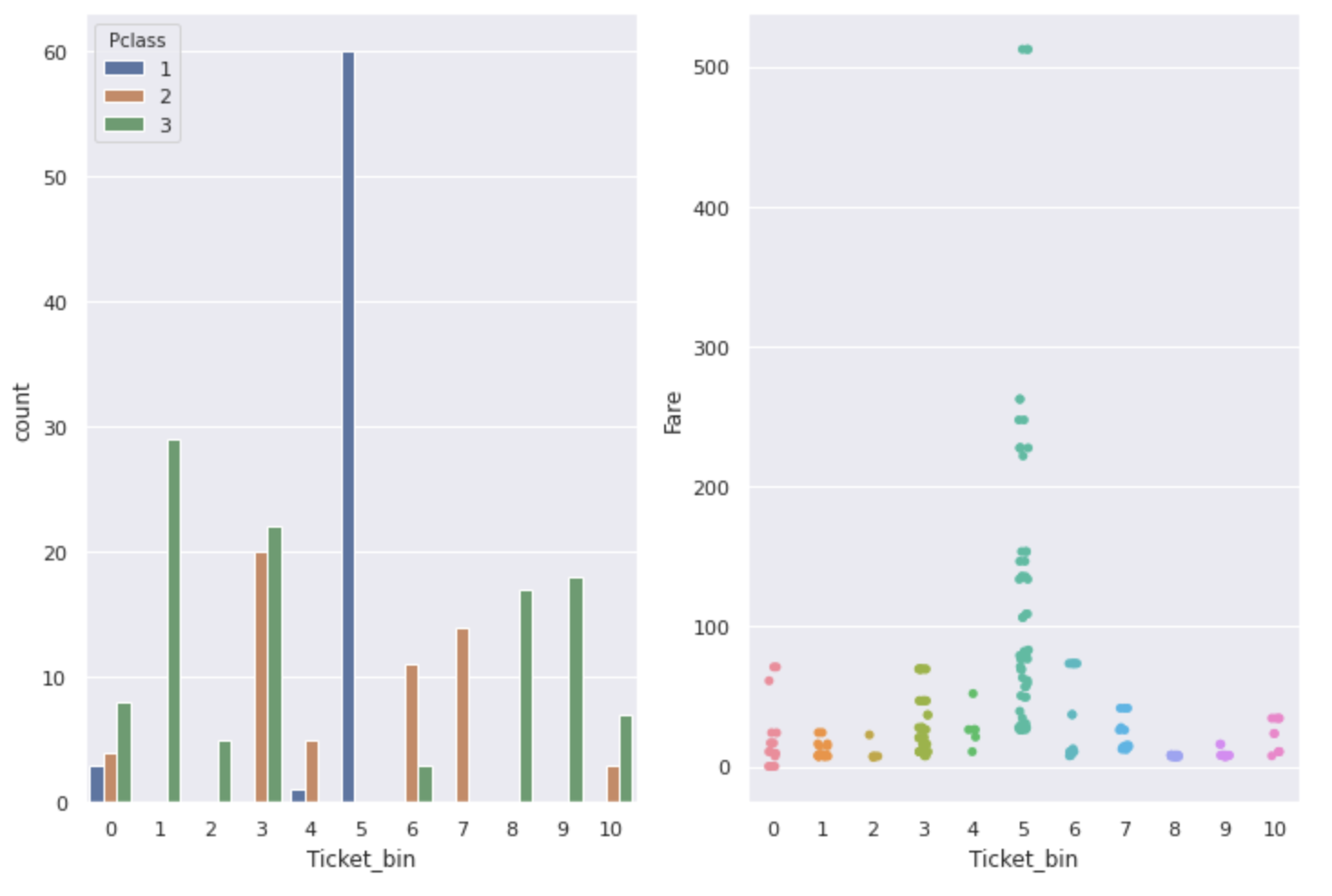
Comme vous pouvez le voir sur le graphique, ** Ticket, Pclass et Fare sont liés les uns aux autres. Les numéros de billets avec un taux de survie particulièrement élevé ont un tarif élevé, et la plupart des personnes avec une Pclass de 1 le sont **.
Un numéro de ticket qui semble inutile à première vue peut être une fonctionnalité utile si vous le recherchez de cette manière.
- Age Puisqu'il contient des valeurs manquantes, supprimez les lignes avec des valeurs manquantes, puis classez-les tous les 10 ans pour vérifier le taux de survie.
#Trame de données excluant les valeurs manquantes de l'âge'age_data'Créer
data_age = data.dropna(subset=['Age']).copy()
#Divisé par 10 ans
data_age['Age_bin'] = pd.cut(data_age['Age'],[i for i in range(0,81,10)])
fig, ax = plt.subplots(1,2, figsize=(20,8))
sns.barplot(x='Age_bin', y='Survived', data=data_age, color='coral', ax=ax[0])
sns.barplot(x='Age_bin', y='Survived', data=data_age, hue='Sex', ax=ax[1])
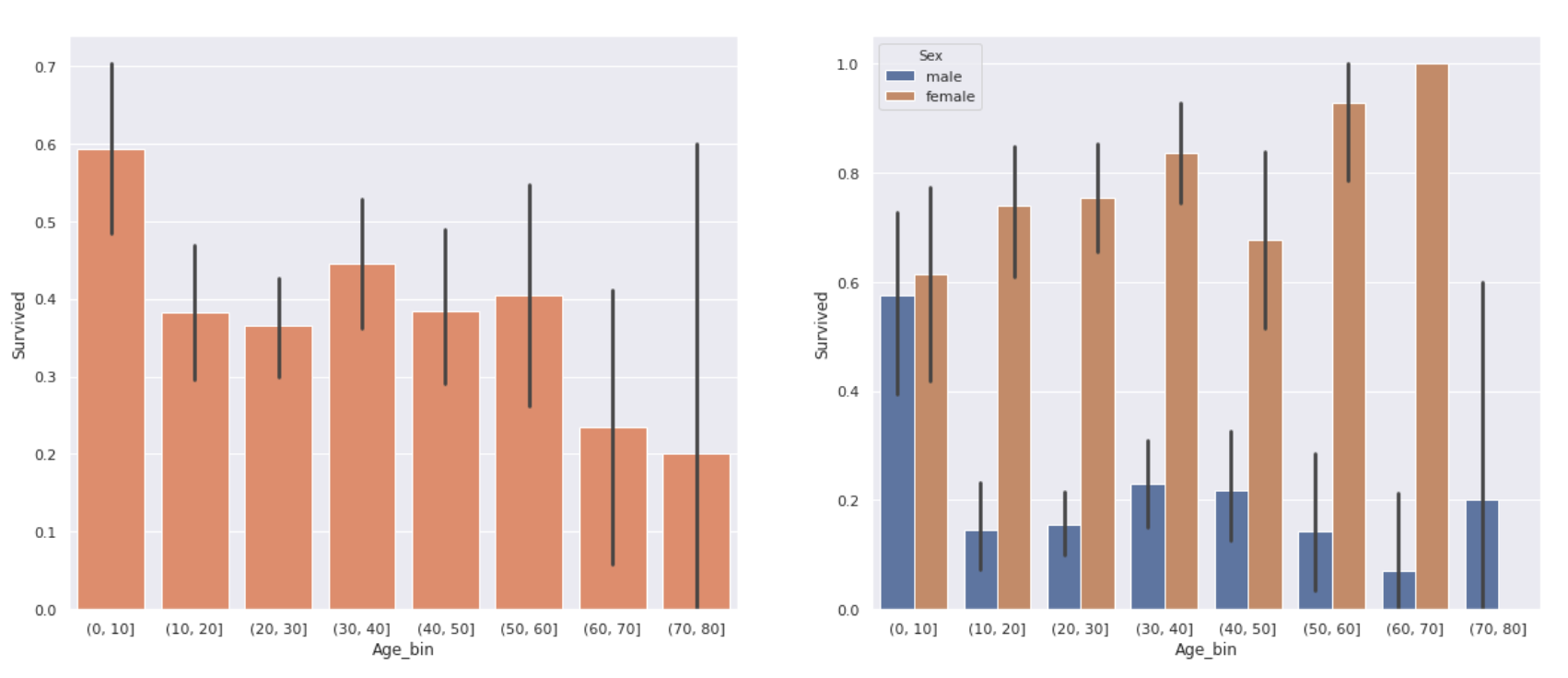
Le graphique de droite est un graphique séparé par sexe sur la gauche. Il y avait une différence de taux de survie selon l'âge. ** Le taux de survie des enfants de moins de 10 ans est relativement élevé et le taux de survie des personnes âgées de plus de 60 ans est assez faible, environ 20% **. De plus, il n'y avait pas de différence significative dans les taux de survie entre les adolescents et la cinquantaine.
Cependant, pour chaque sexe, ** les femmes ont un taux de survie considérablement plus élevé même si elles ont plus de 60 ans **. Le faible taux de survie des personnes âgées dans le graphique de gauche peut également être dû au petit nombre de femmes de plus de 60 ans (seulement 3).
- Embarked Y a-t-il une différence selon le port où les passagers ont embarqué?
plt.figure(figsize=(12,8))
sns.barplot(x='Embarked', y='Survived', data=data)
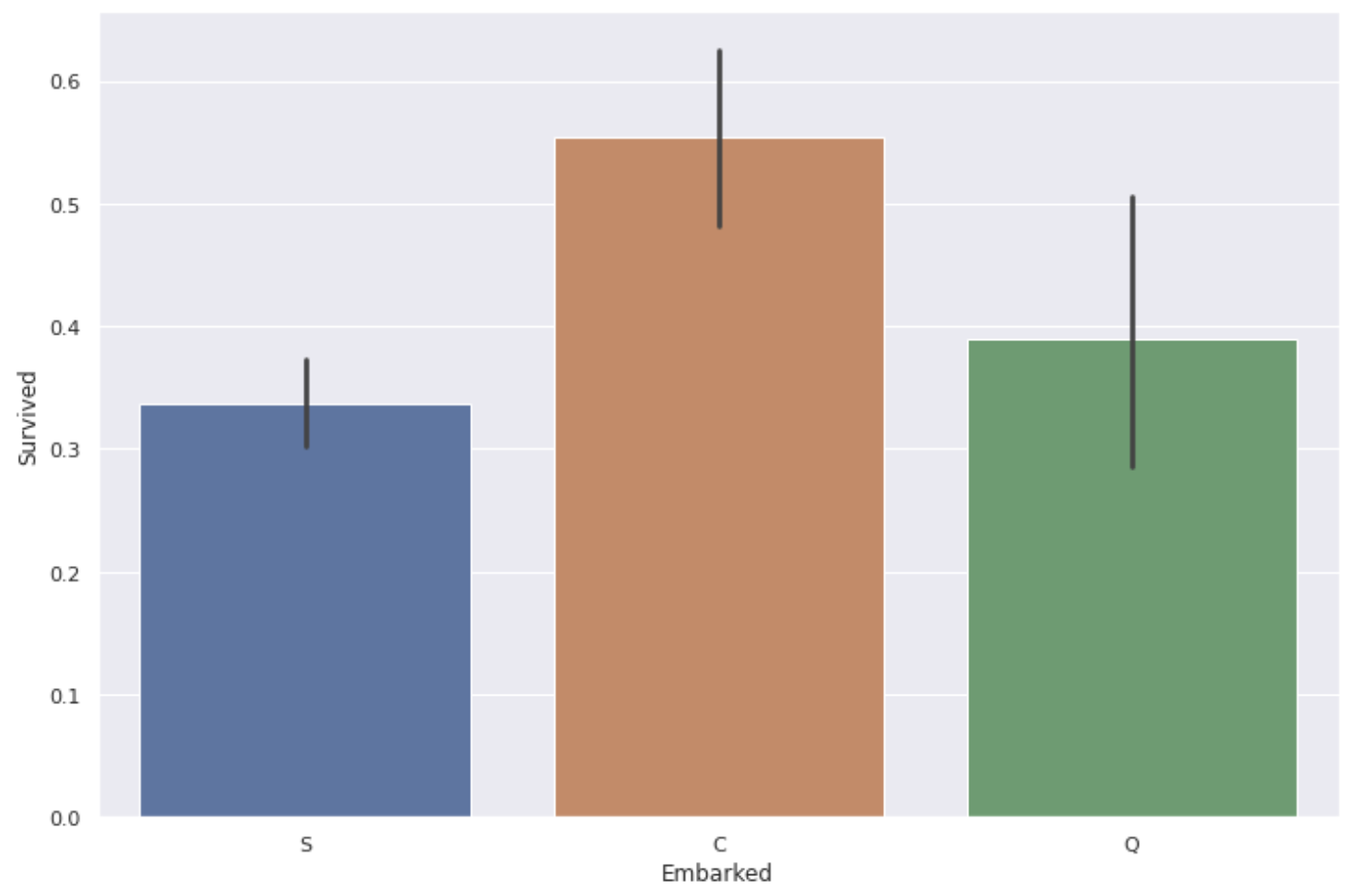 ** Le taux de survie des personnes embarquant depuis le port de C (Cherbourg) est un peu élevé **.
** Le taux de survie des personnes embarquant depuis le port de C (Cherbourg) est un peu élevé **.
Il est peu probable que le port lui-même ait un effet, alors jetons un coup d'œil à la classe P et au tarif pour chaque type de port.
fig, ax = plt.subplots(1,2, figsize=(12,8))
sns.countplot(data['Embarked'], hue= data['Pclass'], ax=ax[0])
sns.boxplot(x='Embarked', y='Fare', data=data, sym='', ax=ax[1])
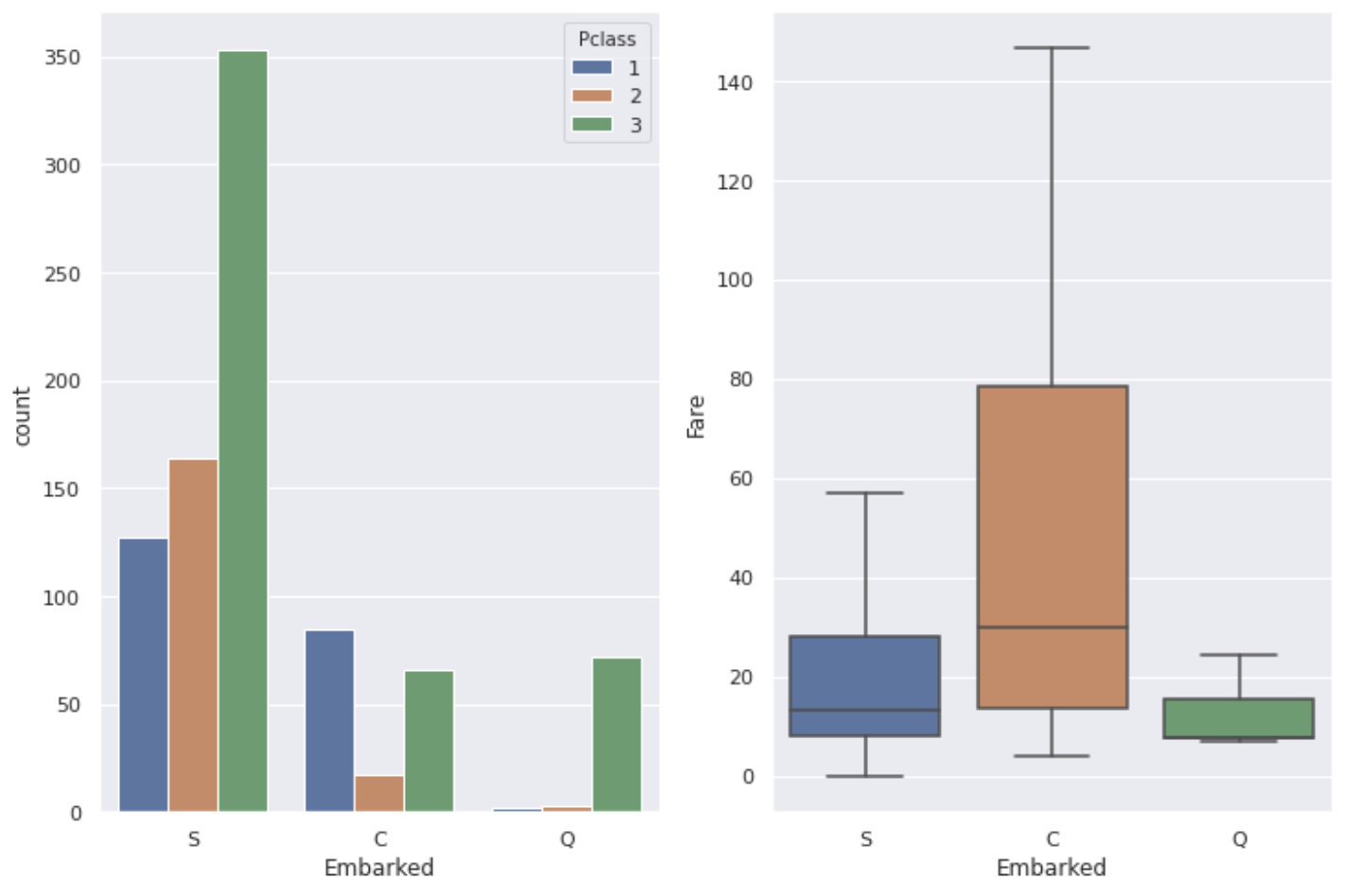 Il semble que la classe et l'occupation des personnes qui y vivent diffèrent selon les zones, il y a donc des différences comme le montre le graphique ci-dessus en fonction du port.
Il semble que la classe et l'occupation des personnes qui y vivent diffèrent selon les zones, il y a donc des différences comme le montre le graphique ci-dessus en fonction du port.
En regardant dans son ensemble, il semble qu'il y ait pas mal de gens qui sont venus du port de S (South Ampton). On peut dire que le taux de survie élevé au port de C est dû à la proportion élevée de ** classe P: 1 personnes et au tarif relativement élevé.
La plupart des gens qui sont arrivés du port de Q (Queenstown) ont la classe P: 3, il semble donc que le taux de survie soit peut-être le plus bas, mais en réalité, le taux de survie au port de S est le plus bas. Il n'y a pas tellement de différence entre S et Q, mais il y a aussi une différence dans le nombre de données, donc la raison pour laquelle le taux de survie des personnes qui sont sorties du port de S est le plus bas est simplement ** "Il y a beaucoup de gens de classe P: 3" Il semble que je ne puisse dire que **.
- Cabin Étant donné que le rapport des valeurs manquantes est aussi élevé que 77%, il est difficile de l'utiliser comme une quantité de caractéristiques à attribuer au modèle de prédiction, mais j'examinerai s'il y a quelque chose qui peut être obtenu en utilisant les données enregistrées.
Un dessin du navire Titanic était sur ce site.
Plans détaillés du Titanic
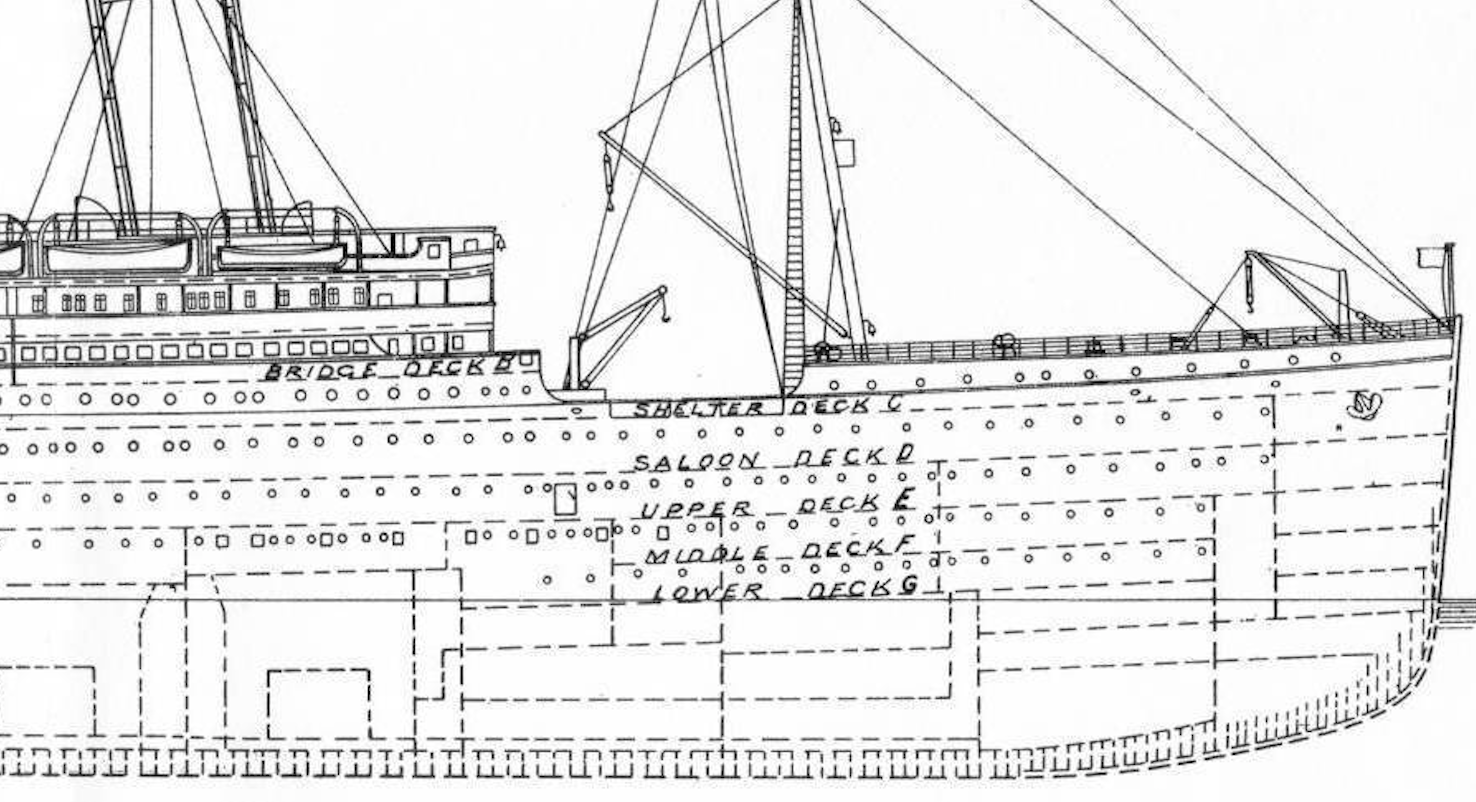 Les chambres sont écrites «B96», et le premier alphabet indique la hiérarchie des chambres.
Il y a des alphabets A à G et T, A est le dernier étage du navire (chambre de luxe) et G est le rez-de-chaussée (salle ordinaire).
** Considérant que l'embarcation de sauvetage est placée sur le pont supérieur ** et ** l'inondation du navire commence par le bas **, le taux de survie de la personne dans la salle A la plus proche du pont supérieur Ça a l'air cher **.
Voyons ce qui se passe avec les données réelles.
Les chambres sont écrites «B96», et le premier alphabet indique la hiérarchie des chambres.
Il y a des alphabets A à G et T, A est le dernier étage du navire (chambre de luxe) et G est le rez-de-chaussée (salle ordinaire).
** Considérant que l'embarcation de sauvetage est placée sur le pont supérieur ** et ** l'inondation du navire commence par le bas **, le taux de survie de la personne dans la salle A la plus proche du pont supérieur Ça a l'air cher **.
Voyons ce qui se passe avec les données réelles.
#Je mets seulement l'alphabet Cabin'Cabin_alpha'Créer une colonne de
#n est la ligne de valeur manquante
data['Cabin_alpha'] = data['Cabin'].map(lambda x:str(x)[0])
data_cabin=data.sort_values('Cabin_alpha')
plt.figure(figsize=(12,8))
sns.barplot(x='Cabin_alpha', y='Survived', data=data_cabin)
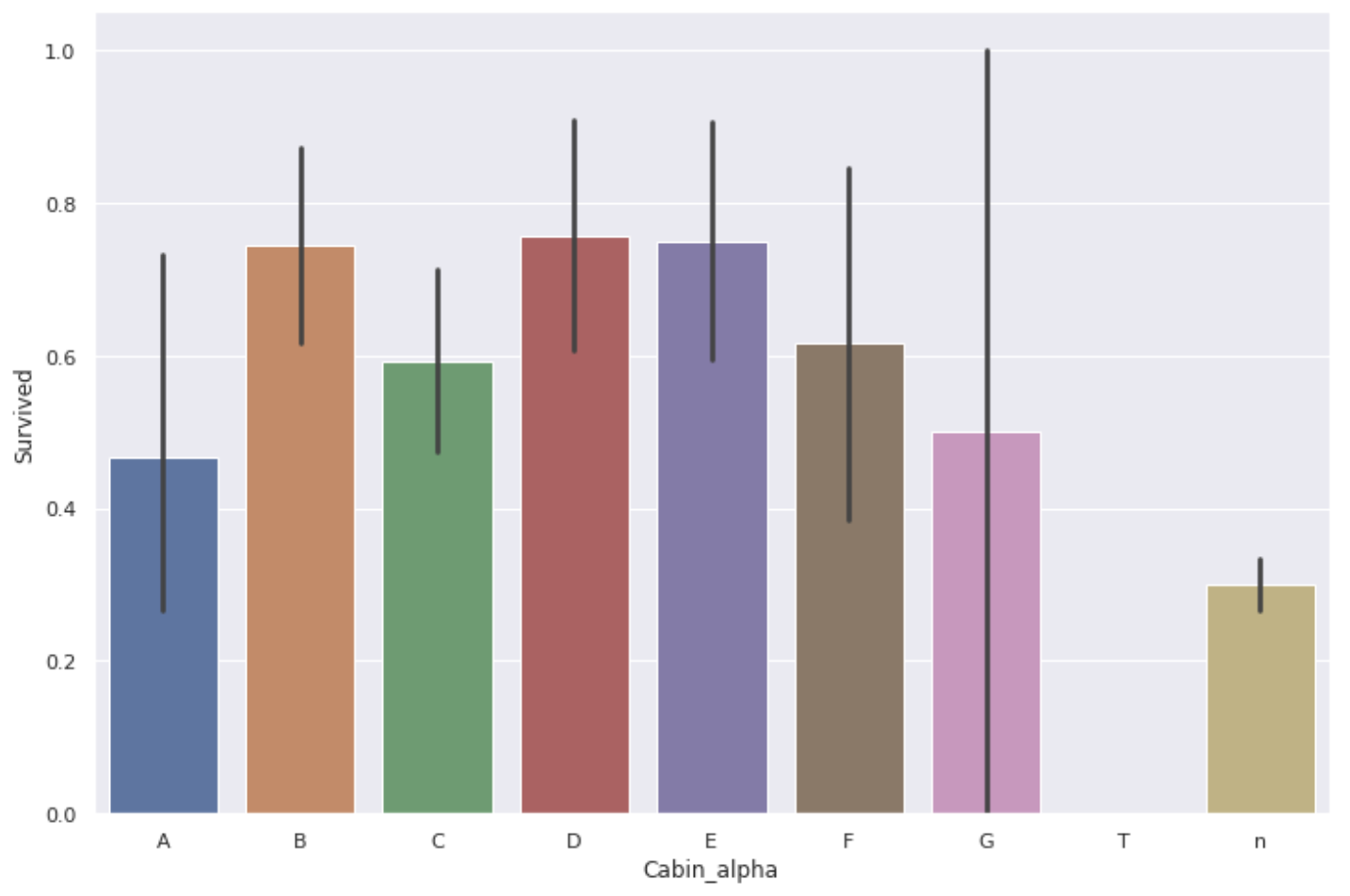 Contrairement aux attentes, le taux de survie de la chambre de A n'était pas très élevé.
Le tableau ci-dessous montre le nombre total de données.
Contrairement aux attentes, le taux de survie de la chambre de A n'était pas très élevé.
Le tableau ci-dessous montre le nombre total de données.
data['Survived'].groupby(data['Cabin_alpha']).agg(['mean', 'count'])
| mean | count | |
|---|---|---|
| Cabin_alpha | ||
| A | 0.466667 | 15 |
| B | 0.744681 | 47 |
| C | 0.593220 | 59 |
| D | 0.757576 | 33 |
| E | 0.750000 | 32 |
| F | 0.615385 | 13 |
| G | 0.500000 | 4 |
| T | 0.000000 | 1 |
| n | 0.299854 | 687 |
La quantité de données pour B et C peut encore être meilleure, mais la quantité de données pour A et G est assez petite, on ne peut donc pas dire qu'il y avait une différence de taux de survie en fonction de l'étage de la chambre **.
De plus, comme pour le billet, il y avait une personne avec le même numéro de chambre, alors j'ai pensé "la chambre est la même" → "embarquement entre amis et famille" → "le taux de survie sera différent", selon que les numéros de chambre sont dupliqués ou non Nous avons calculé le taux de survie de chacun.
data['Cabin_count'] = data.groupby('Cabin')['PassengerId'].transform('count')
data.groupby('Cabin_count')['Survived'].mean()
| Cabin_count | Taux de survie |
|---|---|
| 1 | 0.574257 |
| 2 | 0.776316 |
| 3 | 0.733333 |
| 4 | 0.666667 |
Quand je l'ai vu, le taux de survie de la personne qui était seule dans la pièce était un peu faible ... je n'ai pas pu l'obtenir. Après tout, le nombre de données est trop petit pour obtenir un résultat clair.
Au contraire, la colonne Cabin peut être coupée si elle interfère avec la prédiction ou provoque un surapprentissage.
Résumé
Cette fois, j'ai essayé d'analyser les données principalement sur la relation avec Survived afin de trouver les données qui peuvent être utilisées comme quantité de caractéristiques donnée au modèle de prédiction. Nous avons constaté que les caractéristiques susceptibles d'être significativement liées au taux de survie sont la ** classe P, le tarif, le nombre de membres de la famille (Family_size), les billets en double (Ticket_count), le sexe et l'âge **.
La prochaine fois, j'aimerais compenser les valeurs manquantes contenues dans les données de train et les données de test et compléter la trame de données donnée au modèle de prédiction.
Si vous avez des opinions ou des suggestions, nous vous serions reconnaissants de bien vouloir commenter.
Recommended Posts