[PYTHON] Qu'est-ce que l'hyperopt?
Résumez la logique, l'utilisation et les résultats de vérification d'hyperopt
introduction
Lors de la création d'un modèle avec machine learning, un réglage d'hyper-paramètre est nécessaire.
Ce serait bien si cela pouvait être étudié en profondeur par une recherche de grille, mais si le nombre de paramètres est grand comme DNN, la quantité de calcul sera ridicule.
Il est possible de réduire la quantité de calcul en recherchant des paramètres par recherche aléatoire, mais la probabilité de trouver les paramètres optimaux est faible.
Par conséquent, il existe une méthode appelée Optimisation globale basée sur un modèle séquentiel (SMBO) qui recherche efficacement les bons paramètres.
En python, il existe une bibliothèque appelée hyperopt pour utiliser SMBO (il semble que kaggler l'utilise souvent ...).
Si vous recherchez avec hyperopt, vous pouvez trouver des articles qui expliquent comment l'utiliser, mais il n'y avait pas beaucoup d'articles qui expliquaient la logique interne et la vérification ...
Par conséquent, dans cet article, nous résumerons non seulement comment utiliser hyperopt, mais également la logique interne et les résultats de la vérification. Si vous souhaitez simplement l'utiliser, sautez la première moitié.
logique hyperoptique
Qu'est-ce que l'hyperopt
hyperopt est une bibliothèque python qui recherche efficacement les paramètres des modèles d'apprentissage automatique.
Parmi les PME, hyperopt implémente une logique appelée Approche d'estimation de Parzen structurée en arbre (TPE).
Par conséquent, dans ce chapitre, après avoir expliqué les grandes lignes de SMBO, nous expliquerons brièvement la méthode de calcul de TPE.
Les deux articles suivants ont été mentionnés.
-
[Algorithmes pour l'optimisation des hyper-paramètres (NIPS, 2011)](https://www.google.co.jp/url?sa=t&rct=j&q=1esrc=s&source=web&cd=3&cad=rja&uact=8&ved=0ahUKEwiqh8GBhffVAhWHiQFoDw % 3A% 2F% 2Fwww.lri.fr% 2F ~ kegl% 2Fresearch% 2FPDFs% 2FBeBaBeKe11.pdf & usg = AFQjCNF60kZOogiGZmIBfsuY1Jai4SIVcA]) (papier TPE)
-
http://neupy.com/2016/12/17/hyperparameter_optimization_for_neural_networks.html
En particulier, ce dernier est un article en anglais, mais je le recommande car il explique SMBO-> processus gaussien-> TPE d'une manière facile à comprendre avec des chiffres.
Sequential Model-based Global Optimization(SMBO)
SMBO est l'un des cadres permettant de rechercher efficacement les paramètres du modèle.
Le flux de l'algorithme de SMBO est le suivant.
| Algorithm: SMBO |
|---|
 |
[Algorithmes pour l'optimisation des hyperparamètres](https://www.google.co.jp/url?sa=t&rct=j&q=1esrc=s&source=web&cd=3&cad=rja&uact=8&ved=0ahUKEwiqh8GBhffVAhWHiLwKHXKoDQoF&hl=fr Depuis .lri.fr% 2F ~ kegl% 2Fresearch% 2FPDFs% 2FBeBaBeKe11.pdf & usg = AFQjCNF60kZOogiGZmIBfsuY1Jai4SIVcA])
Explication des symboles
- $ x $: Paramètres
- $ f (x) $: Perte lors de l'utilisation du paramètre $ x $
- $ H $: Ensemble de paramètre $ x $ et perte de modèle $ f (x) $ lors de l'utilisation de ce paramètre
- $ T $: Nombre de tentatives répétées
- $ M $: Une fonction qui prend le paramètre $ x $ et prédit la perte $ f (x) $ lors de l'utilisation de ce paramètre.
- $ S $: une fonction qui calcule la valeur attendue de la perte susceptible d'être réduite lors de l'utilisation d'un certain paramètre $ x $.
Les points de SMBO sont dans la fonction $ M $ et la fonction $ S $.
La fonction $ M $ prédit combien de perte est susceptible de se produire lors de l'utilisation d'un paramètre $ x $. En utilisant cette fonction $ M $, vous pouvez prédire combien de pertes vous êtes susceptible de perdre sans avoir à vous soucier d'estimer le modèle en utilisant $ x $. $ M $ peut être un modèle comme la régression linéaire, par exemple, mais le plus couramment utilisé est le processus gaussien, et hyperopt utilise TPE.
La fonction $ S $ calcule la valeur attendue de la perte susceptible d'être réduite lors de l'utilisation du paramètre $ x $.
Par exemple, disons que vous utilisez un paramètre $ x $ et que vous prédisez la précision à l'aide de la fonction $ M $, et que vous avez 50% de chances de perdre 0,3 et 50% de chances de perdre 0,1. Dans ce cas, la fonction $ S $ calcule que la perte attendue est de 0,3 $ * 0,5 + 0,1 * 0,5 = 0,2 $ lors de l'utilisation du paramètre $ x $.
Vous pouvez utiliser la fonction $ S $ pour trouver le paramètre $ x $ qui est le plus susceptible de réduire la perte.
Ensuite, en utilisant le paramètre estimé $ x $, calculez le modèle et enregistrez la perte que vous avez réellement subie. De plus, sur la base de ce paramètre $ x $ et de la perte $ f (x) $, nous mettons à jour la fonction de prédiction des pertes $ M $.
Le plan de SMBO est de répéter ce calcul $ T $ fois et de retourner le paramètre $ x $ avec la perte la plus faible et sa perte.
Tree-structured Parzen Estimator Approach(TPE)
TPE est une nouveauté de l'article original d'hyperopt, une méthode de calcul des fonctions $ M $ et $ S $ décrite dans la section précédente.
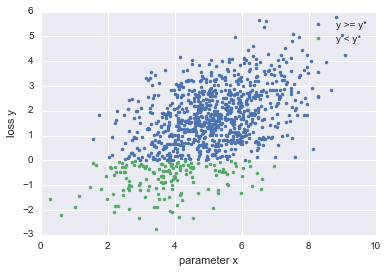
Dans TPE, tout d'abord, en fonction de la valeur du paramètre $ x $, la fonction $ M $ qui calcule la probabilité que la perte soit $ y $ est calculée comme suit.
p(x|y) = \left\{
\begin{array}{ll}
l(x) & (y \lt y^*) \\
g(x) & (y \geq y^*)
\end{array}
\right.
$ y ^ * $ est le seuil, qui calcule la distribution $ l (x) $ pour les paramètres inférieurs à une perte et la distribution $ g (x) $ pour les paramètres supérieurs à une perte.
Expliquant l'image de la fonction $ M $, cela ressemble à la figure ci-dessous
| Paramètres |
|
|---|---|
 |
 |
En définissant la fonction $ M $ de cette manière, la distribution du paramètre $ x $ lorsque la perte est inférieure à $ y ^ \ * $ et la distribution du paramètre $ x $ lorsque la perte est supérieure à $ y ^ \ * $ Peut être calculé.
Dans TPE, basé sur $ l (x) $ et $ g (x) $, la fonction $ S $ qui calcule la perte attendue lorsque le paramètre $ x $ est sélectionné est définie comme suit.
EI_{y^*}(x) = (\gamma + \frac{g(x)}{l(x)}(1 - \gamma))^{-1}
Cependant, $ \ gamma $ est un paramètre qui détermine le pourcentage de données défini comme seuil $ y ^ \ * $.
Pour augmenter cette valeur, rendez $ g (x) $ aussi petit que possible et $ l (x) $ aussi grand que possible. En d'autres termes, la fonction $ S $ sélectionne le paramètre $ x $, qui a une probabilité plus élevée de perdre moins que le seuil $ y ^ \ * $.
De cette manière, TPE recherche le paramètre $ x $ pour calculer la perte suivante.
Remarque
Dans ce chapitre, j'ai simplifié la logique de l'hyperopt. Il y a donc des parties trompeuses. Par exemple, TPE est une méthode de calcul de $ l (x) $ et $ g (x) $ pour être exacte. Si vous voulez connaître la logique exacte, veuillez [article original](https://www.google.co.jp/url?sa=t&rct=j&q=1esrc=s&source=web&cd=3&cad=rja&uact=8&ved=0ahUKEwiqh8GBhffVAhWHggiLwKHXKoDQoD Veuillez lire% 3A% 2F% 2Fwww.lri.fr% 2F ~ kegl% 2Fresearch% 2FPDFs% 2FBeBaBeKe11.pdf & usg = AFQjCNF60kZOogiGZmIBfsuY1Jai4SIVcA).
Comment utiliser hyperopt
Ce chapitre décrit comment utiliser hyperopt avec python. J'ai fait référence au Tutoriel officiel.
Tout d'abord, importez les quatre modules hp, tpe, Trials et fmin depuis hyperopt.
from hyperopt import hp, tpe, Trials, fmin
La description de chaque module est résumée ci-dessous.
- hp: utilisé pour déterminer à partir de quelle distribution les paramètres sont échantillonnés
- tpe: utilisé pour rechercher aléatoirement ou décider d'utiliser la logique tpe
- Essais: créez une instance pour enregistrer le processus de calcul hyperopt
- fmin: La fonction qui effectue réellement le calcul d'hyperopt
Pour utiliser hyperopt
- Quel paramètre rechercher
- Quelle valeur minimiser
Doit être défini à l'avance.
Afin d'expliquer à partir d'un exemple concret, supposons que SVM soit utilisé cette fois.
Définition des paramètres à rechercher
Dans SVM, si les paramètres que vous voulez régler sont, par exemple, $ C $, $ gamma $, $ kernel $, définissez d'abord les paramètres à rechercher dans le type de dictionnaire ou le type de liste comme suit.
hyperopt_parameters = {
'C': hp.uniform('C', 0, 2),
'gamma': hp.loguniform('gamma', -8, 2),
'kernel': hp.choice('kernel', ['rbf', 'poly', 'sigmoid'])
}
hp.uniform est une fonction d'échantillonnage des paramètres à partir d'une distribution uniforme et spécifie le nom du paramètre, min, max.
hp.loguniform recherche les paramètres dans la plage $ exp (min) $ à $ exp (max) $. Par conséquent, pour les paramètres tels que $ C $ et $ gamma $ de SVM qui peuvent être recherchés dans la plage de $ 10 ^ {-5} $ à $ 10 ^ {2} $, hp.loguniform Il vaut mieux utiliser (nous vérifierons dans un chapitre ultérieur).
hp.choice peut échantillonner des catégories. C'est une bonne idée d'utiliser cette fonction lors du choix d'un noyau SVM.
Vous pouvez spécifier une distribution autre que celle illustrée ici. Pour plus d'informations, consultez le didacticiel officiel (https://github.com/hyperopt/hyperopt/wiki/FMin).
Définition de la valeur à minimiser
Dans hyperopt, vous devez définir ce qu'il faut minimiser en tant que fonction.
Pour SVM, la fonction est définie comme suit.
def objective(args):
#Instanciation du modèle
classifier = SVC(**args)
#Entraîner un modèle à l'aide de données de train
classifier.fit(x_train, y_train)
#Prédiction d'étiquettes à l'aide des données de validation
predicts = classifier.predict(x_test)
#Calculez le micro f1 en utilisant une étiquette prédictive et une étiquette correcte
f1 = f1_score(y_test, predicts, average='micro')
#Cette fois je veux maximiser le micro f1-Multipliez par 1 pour minimiser
return -1*f1
L'argument «args» contient les «paramètres_hyperopt» définis dans la section précédente.
Dans cet exemple, nous définissons d'abord les paramètres définis pour créer une instance SVM.
Ensuite, nous entraînerons le modèle en utilisant les données du train.
Utilisez le modèle entraîné pour prédire l'étiquette des données de validation.
Cette fois, le but est de trouver le paramètre qui maximise le micro f1, et le micro f1 des données de validation est calculé.
Il renvoie le dernier micro f1 calculé, mais notez que hyperopt ne prend en charge que la minimisation. Par conséquent, lorsque vous recherchez le paramètre qui maximise la valeur comme cette fois, multipliez-le par -1 et renvoyez-le.
calcul hyperoptique
Recherchez les paramètres en utilisant les paramètres prédéfinis «hyperopt_parameters» et «def objective».
Recherchez des paramètres en procédant comme suit.
#Nombre d'itérations
max_evals = 200
#Une instance qui enregistre le processus de l'essai
trials = Trials()
best = fmin(
#Une fonction qui définit la valeur à minimiser
objective,
#Dict ou liste de paramètres à rechercher
hyperopt_parameters,
#Quelle logique utiliser, essentiellement tpe.suggérer ok
algo=tpe.suggest,
max_evals=max_evals,
trials=trials,
#Processus d'essai de sortie
verbose=1
)
En passant hyperopt_parameters et def objective à la fonction fmin, les paramètres sont recherchés, mais en plus de cela, l'instance essaie pour enregistrer le résultat du calcul, combien de fois rechercher Il spécifie également les max_evals à spécifier.
En calculant de cette manière, les paramètres qui minimisent l'obejctif sont calculés.
Dans l'exemple ci-dessus, le contenu de best est le suivant.
$ best
>> {'C': 1.61749553623185, 'gamma': 0.23056607283675354, 'kernel': 0}
Utilisez également des essais pour vérifier la valeur micro f1 réellement calculée et la valeur du paramètre que vous avez essayé.
$ trials.best_trial['result']
>> {'loss': -0.9698492462311558, 'status': 'ok'}
$ trials.losses()
>> [-0.6700167504187605, -0.9095477386934674, -0.949748743718593, ...]
$ trials.vals['C']
>> [2.085990722493943, 0.00269991295234128, 0.046611673333310344, ...]
Vérification de la précision Hyperopt
Les contenus vérifiés cette fois sont principalement les deux suivants.
- Quel est préférable d'utiliser, «hp.loguniform» ou «hp.uniform»
- Hyperopt est-il plus précis que la recherche aléatoire?
L'ensemble de données utilisé est constitué de chiffres (données de chiffres manuscrits à 64 dimensions) dans sklearn. 1200 pièces ont été utilisées comme données de train et le reste était des données de validation.
Pour le classificateur, nous avons utilisé le SVC de sklearn. Les paramètres recherchés sont $ C $, $ gamma $ et $ kernel $, qui ont été montrés dans les exemples concrets du chapitre précédent.
Le code utilisé pour la vérification est https://github.com/kenchin110100/machine_learning/blob/master/sampleHyperOpt.ipynb C'est dedans.
LogUniform vs Uniform
Dans le chapitre précédent, j'ai écrit qu'il est préférable d'utiliser hp.loguniform dans le cas de SVC, mais j'ai vérifié si c'était vraiment le cas.
Comme méthode de vérification, LogUniform et Uniform ont été recherchés pour 50 itérations 100 fois chacun, et la meilleure distribution estimée des valeurs micro f1 a été comparée.
Chaque `hyperopt_parameters a été défini comme suit.
hyperopt_parameters_loguniform = {
'C': hp.loguniform('C', -8, 2),
'gamma': hp.loguniform('gamma', -8, 2),
'kernel': hp.choice('kernel', ['rbf', 'poly', 'sigmoid'])
}
hyperopt_parameters_uniform = {
'C': hp.uniform('C', 0, 10),
'gamma': hp.uniform('gamma', 0, 10),
'kernel': hp.choice('kernel', ['rbf', 'poly', 'sigmoid'])
}
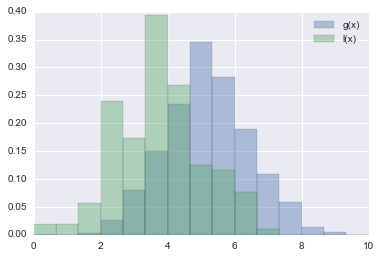
Les résultats de la comparaison sont résumés dans la figure ci-dessous.
| LogUniform vs Uniform |
|---|
 |
L'histgramme du résultat Log Unifrom est bleu et l'histgramme du résultat Uniform est vert. Bien que LogUniform soit plus susceptible d'estimer un micro f1 inférieur, il a presque doublé le nombre de fois où il a enregistré 0,96985, le plus grand micro f1 à la maison cette fois-ci.
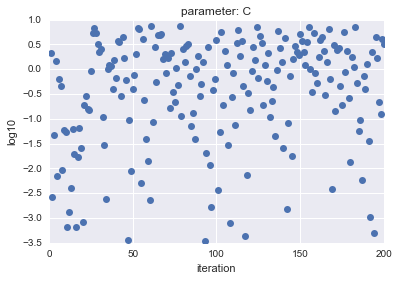
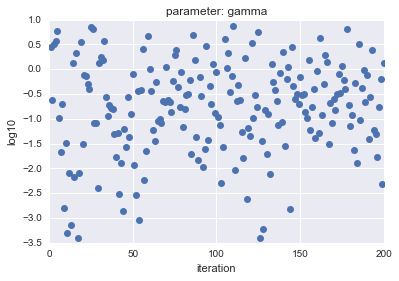
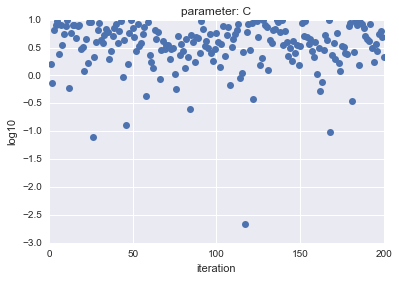
Dans le cas de LogUniform, dans le cas de Uniform, les paramètres d'échantillon $ C $ et $ gamma $ sont tracés et le résultat est le suivant.
- Pour un uniforme de journal
| parameter |
parameter |
|---|---|
 |
 |
- Pour uniforme
| parameter |
parameter |
|---|---|
 |
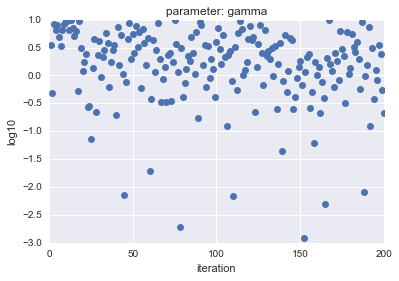 |
L'axe horizontal montre l'itération et l'axe vertical montre les valeurs logarithmiques de $ C $ et $ gamma $.
Comme vous pouvez le voir, LogUniform a un échantillon plus uniforme de l'ensemble. En étant capable d'échantillonner uniformément à partir de l'ensemble, il est plus probable que vous puissiez rechercher des paramètres avec une plus grande précision (bien qu'il soit plus probable que ce soit plus bas ...)
HyperOpt vs RandomSearch
Ensuite, nous avons examiné lequel des cas où HyperOpt a été utilisé et les paramètres ont été estimés par RandomSearch était le plus susceptible d'estimer les paramètres avec une plus grande précision.
L'ensemble de données utilisé et les conditions expérimentales sont les mêmes que ceux de la section précédente. Nous avons estimé 100 fois chacun avec HyperOpt et RandomSearch, et comparé la fréquence des meilleures valeurs micro f1 obtenues.
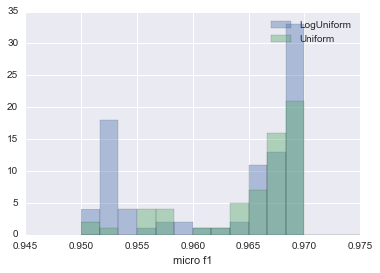
Les résultats de la comparaison sont résumés dans la figure ci-dessous.
| HyperOpt vs RansomSearch |
|---|
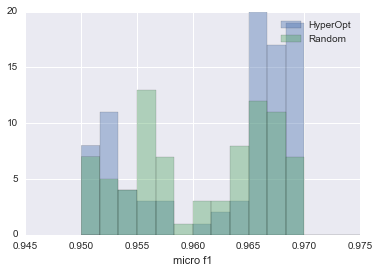 |
Le bleu est HyperOpt et le vert est la recherche aléatoire. Comme vous pouvez le voir, HyperOpt a plus de deux fois plus de chances de pouvoir estimer des paramètres qui produisent une valeur micro f1 de 0,965 ou plus.
Cela montre qu'il vaut mieux utiliser HyperOpt que RandomSearch.
Expérience supplémentaire
Même si HyperOpt est plus précis que RandomSearch, le calcul prend plus de temps, n'est-ce pas? Afin de vérifier la question, nous avons comparé le temps de calcul. Nous avons effectué 200 itérations chacun et mesuré le temps nécessaire.
#Temps de calcul HyperOpt
%timeit hyperopt_search(200)
>> 1 loop, best of 3: 32.1 s per loop
#Temps de calcul de la recherche aléatoire
%timeit random_search(200)
>> 1 loop, best of 3: 46 s per loop
Eh bien, plutôt, hyperopt est plus rapide ... Puisque RandomSearch a été implémenté par moi-même, il peut y avoir un problème avec mon codage, mais il semble que hyperopt est en fait codé pour effectuer automatiquement un traitement distribué. Ainsi, même si vous utilisez hyperopt, il semble que vous puissiez calculer à la même vitesse ou plus rapidement que la recherche aléatoire.
Résumé
Cette fois, nous avons vérifié la logique, l'utilisation et la précision de l'hyperopt de python.
Après tout, il semble préférable d'utiliser hyperopt plutôt que d'ajuster les paramètres avec la recherche aléatoire.
Je l'ai écrit comme le TPE le plus fort, mais il semble y avoir un problème avec TPE (en ignorant la dépendance entre les variables, etc.).
Pourtant, hyperopt a l'avantage de pouvoir être utilisé avec sklearn et xgboost, je vais donc l'utiliser beaucoup à partir de maintenant.
Recommended Posts