[PYTHON] Chainer, RNN et traduction automatique
Traitement du langage naturel et réseau neuronal
Au cours des dernières années, les réseaux neuronaux sont également devenus très populaires dans le domaine du traitement du langage naturel.
Dans le traitement du langage naturel, les principales cibles d'analyse sont les séquences de mots et les arbres de syntaxe, et les modèles basés sur le réseau neuronal récurrent [^ 1] et le réseau neuronal récursif [^ 1] pour exprimer ces informations contenues. Est fréquemment utilisé. La plus grande caractéristique de ceux-ci est que ** le réseau de neurones a une sorte de structure de données **, il n'y a pas autant de nœuds par couche, mais la connexion réseau est compliquée et chaque entrée de données Il a la particularité que la forme du réseau lui-même change. Pour cette raison, il y avait un problème qu'il était difficile de construire avec une boîte à outils qui supposait le réseau neuronal traditionnel.
Chainer est un puissant framework de réseau neuronal qui résout généralement de tels problèmes. Il peut être utilisé si vous connaissez la syntaxe Python et un peu NumPy, et la formule de calcul sur le code source est automatiquement stockée comme informations de connexion du réseau neuronal, donc ** Si vous analysez les données d'entrée, ce sera automatiquement Il existe une fonction ~~ semblable à la triche ~~ appelée ** qui peut être analysée avec un réseau neuronal.
La collection d'échantillons Chainer que j'ai récemment écrite implémente également des modèles de langage, des diviseurs de mots, des modèles de traduction, etc., mais tous sont des parties de base (dans le code). La fonction forward) peut être implémentée en une demi-journée, ou une heure si elle est courte. Comme vous pouvez le voir dans l'exemple, cela revient plus à consacrer l'essentiel de vos efforts à du code périphérique qui organise vos données.
Dans cet article, nous expliquerons principalement comment implémenter le réseau de neurones récurrent dans Chainer et le modèle de traduction encodeur-décodeur, qui est une application dans le traitement du langage naturel.
- Le contenu de l'article est basé sur Chainer 1.4 ou une version antérieure. Nous soutiendrons la série 1.5 en regardant la situation. *
Recurrent Neural Network
Le réseau neuronal récurrent (RNN) le plus élémentaire est un réseau neuronal orthodoxe à trois couches avec rétroaction de couche cachée, comme le montre la figure suivante.
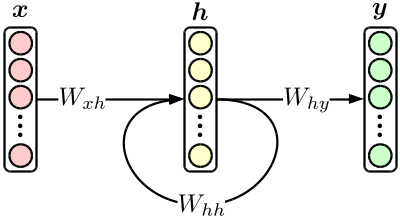
Bien qu'il s'agisse d'un modèle simple, le modèle de traduction introduit plus tard est réalisé en combinant des RNN. De plus, RNN seul est un excellent produit qui peut facilement surpasser le modèle conventionnel * N * -gram lorsqu'il est utilisé dans un modèle de langage. [^ 2]
Si vous notez le chiffre ci-dessus dans la formule,
\begin{align}
{\bf h}_n & = \tanh \bigl( W_{xh} \cdot {\bf x}_n + W_{hh} \cdot {\bf h}_{n-1} \bigr), \\
{\bf y}_n & = {\rm softmax} \bigl( W_{hy} \cdot {\bf h}_n \bigr)
\end{align}
Et utilisez ceci tel quel comme formule de calcul sur Chainer.
Pour l'instant, considérons un modèle de langage RNN qui "entre un ID de mot et prédit l'ID de mot suivant". [^ 3]
Tout d'abord, définissez le ** modèle **. Un modèle est un ** ensemble de paramètres entraînables **, et $ W_ {\ * \ *} $ dans la figure ci-dessus correspond à cela. Dans ce cas, $ W_ {\ * \ *} $ sont tous des éléments d'action linéaires (matrice), utilisez donc Linear ou ʻEmbedID dans chainer.functions. ʻEmbedID est Linear lorsque le côté d'entrée est un vecteur one-hot, et vous pouvez passer l'ID de l'élément de déclenchement au lieu du vecteur.
from chainer import FunctionSet
from chainer.functions import *
model = FunctionSet(
w_xh = EmbedID(VOCAB_SIZE, HIDDEN_SIZE), #Couche d'entrée(one-hot) ->Couche cachée
w_hh = Linear(HIDDEN_SIZE, HIDDEN_SIZE), #Couche cachée->Couche cachée
w_hy = Linear(HIDDEN_SIZE, VOCAB_SIZE), #Couche cachée->Couche de sortie
)
«VOCAB_SIZE» représente le nombre de types de mots et «HIDDEN_SIZE» représente la dimension du calque masqué.
Ensuite, définissez la fonction forward qui effectue l'analyse réelle. Ici, fondamentalement, la structure de réseau de la figure ci-dessus est reproduite selon la définition du modèle et les données d'entrée réelles, et la valeur finale souhaitée est calculée. Dans le cas du modèle de langage, la ** probabilité de combinaison d'instructions ** exprimée dans la formule suivante est calculée.
\begin{align}
\log {\rm Pr} \bigl( {\bf w} \bigr) & = \sum_{n=1}^{|{\bf w}|} \log {\rm Pr} \bigl( w_n \ \big| \ w_1, w_2, \cdots, w_{n-1} \bigr) \\
& = \sum_{n=1}^{|{\bf w}|} \log {\bf y}_n\big[ {\rm index} \bigl( w_n \bigr) \big]
\end{align}
Ce qui suit est un exemple de code, mais comme Chainer est basé sur un traitement par mini-lots, la dimension des données est augmentée de un (le traitement par lots n'est pas effectué dans le code).
import math
import numpy as np
from chainer import Variable
from chainer.functions import *
def forward(sentence, model): #phrase est un tableau de str. En supposant une sortie telle que MeCab.
sentence = [convert_to_your_word_id(word) for word in sentence] #Convertissez les mots en identifiants. Mettez-le en œuvre vous-même.
h = Variable(np.zeros((1, HIDDEN_SIZE), dtype=np.float32)) #Valeur initiale du calque caché
log_joint_prob = float(0) #Probabilité de jointure de phrase
for word in sentence:
x = Variable(np.array([[word]], dtype=np.int32)) #Couche d'entrée suivante
y = softmax(model.w_hy(h)) #Distribution de probabilité du mot suivant
log_joint_prob += math.log(y.data[0][word]) #Mise à jour de la probabilité de jointure
h = tanh(model.w_xh(x) + model.w_hh(h)) #Mise à jour de la couche masquée
return log_joint_prob #Renvoie le résultat du calcul de la probabilité de jointure
Vous pouvez maintenant trouver la probabilité de la phrase. Cependant, ce qui précède n'inclut pas le calcul de la fonction de perte pour entraîner le modèle. Puisque la fonction softmax est utilisée dans la dernière étape cette fois, utilisez chainer.functions.softmax_cross_entropy pour trouver l'entropie croisée avec la bonne réponse et l'utiliser comme fonction de perte.
def forward(sentence, model):
...
accum_loss = Variable(np.zeros((), dtype=np.float32)) #Valeur initiale de la perte cumulée
...
for word in sentence:
x = Variable(np.array([[word]], dtype=np.int32)) #Couche d'entrée suivante(=Cette bonne réponse)
u = model.w_hy(h)
accum_loss += softmax_cross_entropy(u, x) #Accumulation de perte
y = softmax(u)
...
return log_joint_prob, accum_loss #La perte cumulative est également renvoyée
Vous pouvez maintenant apprendre.
from chainer.optimizers import *
...
def train(sentence_set, model):
opt = SGD() #Utilise la méthode du gradient probabiliste
opt.setup(model) #Initialisation de l'apprenant
for sentence in sentence_set:
opt.zero_grad(); #Initialisation du gradient
log_joint_prob, accum_loss = forward(sentence, model) #Calcul des pertes
accum_loss.backward() #Erreur de propagation de retour
opt.clip_grads(10) #Supprimer un dégradé trop grand
opt.update() #Mise à jour des paramètres
Fondamentalement, c'est le seul traitement de Chainer. Dans le passé, j'écrivais un programme avec un nombre désagréable de lignes pour un tel réseau neuronal, mais Chainer a presque tous les calculs gênants cachés dans la syntaxe Python, donc une si courte description est Ce sera possible. Tant que vous vous souvenez comment utiliser Chainer, vous pouvez rapidement écrire et essayer le modèle récemment proposé ou le modèle original que vous venez de créer. [^ 4]
Modèle de traduction encodeur-décodeur
Comme exemple légèrement compliqué d'application de RNN, implémentons le ** modèle de traduction codeur-décodeur **, qui est une méthode de traduction automatique utilisant un réseau neuronal. Il s'agit d'un modèle de traduction dans lequel l'ensemble du processus de l'entrée à la sortie est décrit par un réseau neuronal et, malgré sa simplicité, il atteint une précision comparable à celle des modèles de traduction conventionnels, ce qui a surpris les chercheurs au moment de la présentation. A été bien accueilli.
Il existe différentes variantes du modèle de traduction encodeur-décodeur, mais j'écrirai ici le modèle ci-dessous, qui est également implémenté dans ma collection d'échantillons.
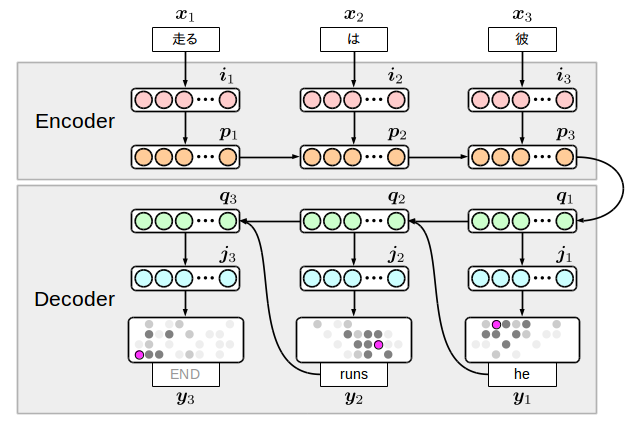
L'idée est simple: préparer deux RNN côté langue d'entrée (encodeur) et côté langue de sortie (décodeur), et les connecter avec un nœud intermédiaire. La chose intéressante à propos de ce modèle est que le côté sortie génère un terminateur avec le mot, donc ** le modèle lui-même décide de la fin de la traduction **. Cependant, pour le dire autrement, si vous ne parvenez pas à apprendre ce symbole terminal, vous finirez par générer un nombre infini de mots, donc si vous générez réellement un nombre approprié de mots mais que cela ne se termine pas, vous devez arrêter le processus. il y a.
$ {\ bf i} $ et $ {\ bf j} $ sont appelés ** couches d'incorporation ** et représentent des informations de mot compressées dimensionnellement. De plus, la chaîne de mots de l'entrée est inversée, mais on sait que cela donnera de bons résultats de traduction expérimentalement. La raison n'est pas très claire, mais elle est parfois interprétée comme parce que le codeur et le décodeur sont dans une relation conversion / inverse.
J'écrirai le code immédiatement, mais mettons-le d'abord dans la formule de calcul. Cela ressemble à ceci:
\begin{align}
{\bf i}_n & = \tanh \bigl( W_{xi} \cdot {\bf x}_n \bigr), \\
{\bf p}_n & = {\rm LSTM} \bigl( W_{ip} \cdot {\bf i}_n + W_{pp} \cdot {\bf p}_{n-1} \bigr), \\
{\bf q}_1 & = {\rm LSTM} \bigl( W_{pq} \cdot {\bf p}_{|{\bf w}|} \bigr), \\
{\bf q}_m & = {\rm LSTM} \bigl( W_{yq} \cdot {\bf y}_{m-1} + W_{qq} \cdot {\bf q}_{m-1} \bigr), \\
{\bf j}_m & = \tanh \bigl( W_{qj} \cdot {\bf q}_m \bigr), \\
{\bf y}_m & = {\rm softmax} \bigl( W_{jy} \cdot {\bf j}_m \bigr).
\end{align}
Ici, LSTM est complètement utilisé pour la transition entre les couches cachées $ {\ bf p} $ et $ {\ bf q} $. [^ 5] peut être compris en regardant la figure, mais comme le côté encodeur est assez éloigné de la position $ {\ bf y} $ où la perte est réellement calculée, avec une fonction d'activation normale C'est parce qu'il y a un problème qui ne peut pas être bien appris. Un tel modèle nécessite un pré-apprentissage des poids ou un élément capable de stocker des dépendances à longue portée comme LSTM.
En passant, si vous regardez la figure et la formule ci-dessus, vous pouvez voir qu'il existe 8 types de transition $ W_ {\ * \ *} $. Ce sont les paramètres que nous allons apprendre cette fois, et nous les listerons dans la définition du modèle.
model = FunctionSet(
w_xi = EmbedID(SRC_VOCAB_SIZE, SRC_EMBED_SIZE), #Couche d'entrée(one-hot) ->Couche intégrée d'entrée
w_ip = Linear(SRC_EMBED_SIZE, 4 * HIDDEN_SIZE), #Couche intégrée d'entrée->Couche masquée d'entrée
w_pp = Linear(HIDDEN_SIZE, 4 * HIDDEN_SIZE), #Couche masquée d'entrée->Couche masquée d'entrée
w_pq = Linear(HIDDEN_SIZE, 4 * HIDDEN_SIZE), #Couche masquée d'entrée->Sortie cachée de la couche
w_yq = EmbedID(TRG_VOCAB_SIZE, 4 * HIDDEN_SIZE), #Couche de sortie(one-hot) ->Sortie cachée de la couche
w_qq = Linear(HIDDEN_SIZE, 4 * HIDDEN_SIZE), #Sortie cachée de la couche->Sortie cachée de la couche
w_qj = Linear(HIDDEN_SIZE, TRG_EMBED_SIZE), #Sortie cachée de la couche->Sortie couche intégrée
w_jy = Linear(TRG_EMBED_SIZE, TRG_VOCAB_SIZE), #Sortie cachée de la couche->Sortie cachée de la couche
)
Il faut faire attention aux paramètres $ W_ {ip}, W_ {pp}, W_ {pq}, W_ {yq}, W_ {qq} $ qui sont entrés dans le LSTM. Vous devez multiplier les dimensions par un facteur de quatre. Le LSTM implémenté par Chainer a trois types d'entrées, porte d'entrée, porte de sortie et porte d'oubli, en plus des entrées normales, et une telle implémentation est nécessaire car elles sont combinées en un seul vecteur. Je suis. [^ 6]
Ensuite, écrivez la fonction forward. Notez que LSTM a un état interne, donc nous avons besoin d'une autre Variable lors du calcul de $ {\ bf p} $ et $ {\ bf q} $.
# src_sentence:Chaîne de mots que vous souhaitez traduire e.g. ['il', 'Est', 'Courir']
# trg_sentence:Chaîne de mots représentant la traduction de la bonne réponse e.g. ['he', 'runs']
# training:Apprentissage ou prédiction? Affecte le comportement du décodeur.
def forward(src_sentence, trg_sentence, model, training):
#Conversion en identifiant de mot (implémentation appropriée par vous-même)
#Ajoutez un terminateur à la traduction correcte.
src_sentence = [convert_to_your_src_id(word) for word in src_sentence]
trg_sentence = [convert_to_your_trg_id(word) for wprd in trg_sentence] + [END_OF_SENTENCE]
#Valeur initiale de l'état interne du LSTM
c = Variable(np.zeros((1, HIDDEN_SIZE), dtype=np.float32))
#Encodeur
for word in reversed(src_sentence):
x = Variable(np.array([[word]], dtype=np.int32))
i = tanh(model.w_xi(x))
c, p = lstm(c, model.w_ip(i) + model.w_pp(p))
#Encodeur->décodeur
c, q = lstm(c, model.w_pq(p))
#décodeur
if training:
#Lors de l'apprentissage, utilisez la traduction correcte en tant que y et renvoyez la perte cumulée résultant de l'avant.
accum_loss = np.zeros((), dtype=np.float32)
for word in trg_sentence:
j = tanh(model.w_qj(q))
y = model.w_jy(j)
t = Variable(np.array([[word]], dtype=np.int32))
accum_loss += softmax_cross_entropy(y, t)
c, q = lstm(c, model.w_yq(t), model.w_qq(q))
return accum_loss
else:
#Au moment de la prédiction, y généré par le traducteur est utilisé pour l'entrée suivante et la chaîne de mots générée à la suite de l'avant est renvoyée.
#Sélectionnez le mot avec la probabilité la plus élevée en y, mais vous n'avez pas besoin de prendre softmax.
hyp_sentence = []
while len(hyp_sentence) < 100: #Ne générez pas plus de 100 mots
j = tanh(model.w_qj(q))
y = model.w_jy(j)
word = y.data.argmax(1)[0]
if word == END_OF_SENTENCE:
break #Fin car le symbole de terminaison a été généré
hyp_sentence.append(convert_to_your_trg_str(word))
c, q = lstm(c, model.w_yq(y), model.w_qq(q))
return hyp_sentence
C'est un peu long, mais si vous le lisez attentivement, vous verrez que les flèches dans la figure ci-dessus correspondent à chaque partie du code. Après cela, si vous ajoutez un apprenant similaire à RNN en dehors de ce code, tout ira bien et vous pourrez apprendre vos propres données de traduction.
Maintenant, comment ce modèle apprend, apprenons en utilisant les exemples de données de traduction japonais-anglais placés dans ici. Si vous étudiez environ 10000 phrases avec 2000 vocabulaire, 100 couches intégrées et 100 couches cachées, vous obtiendrez les résultats de traduction suivants pour chaque génération (j'ai utilisé le programme de la collection d'échantillons pour l'apprentissage). 2017/7/21: Le lien des exemples de données a été ré-lié. </ font>
contribution:Comment était tes vacances?
production:
1: the is is a of of <unk> .
2: the 't is a <unk> of <unk> .
3: it is a good of the <unk> .
4: how is the <unk> to be ?
5: how do you have a <unk> ?
6: how do you have a <unk> ?
7: how did you like the <unk> ?
8: how did you like the weather ?
9: how did you like the weather ?
10: how did you like your work ?
11: how did you like your vacation ?
12: how did you like your vacation ?
13: how did you the weather to drink ?
14: how did you like your vacation ?
15: how did you like your vacation ?
16: how did you like your vacation ?
17: how did you like your vacation ?
18: how did you like your vacation ?
19: how did you enjoy your vacation ?
20: how did you enjoy your vacation now ?
21: how did you enjoy your vacation for you ?
22: how did you enjoy your vacation ?
contribution:Elle a l'air heureuse.
production:
1: she is a of of of .
2: she is a good of of .
3: she is a good of <unk> .
4: she is a good of <unk> .
5: she is a good of <unk> .
6: she is a good of his morning .
7: she is a good of his morning .
8: she is a good of his morning .
9: she is a good of his morning .
11: she is a good of his morning .
12: she is a good of his morning .
13: she is a good of his morning .
14: she is a good of his morning .
15: she is a good at tennis .
16: she is a good at tennis .
17: she is a good at tennis .
18: she is a good of the time .
19: she seems to be very very happy .
20: she is going to be a student .
21: she seems to be very very happy .
22: she seems to be very very happy .
23: she seems to be very happy .
contribution:J'ai froid ce matin.
production:
1: i 'm a of of of .
2: i 'm a <unk> of the <unk> .
3: it is a good of <unk> .
4: it is a good of <unk> .
5: it is a good of <unk> .
6: it is a good of the day .
7: it 's a good of <unk> .
8: it 's a good of <unk> .
9: it 's a good of <unk> .
10: it 's a good of <unk> today .
11: i 'm a good <unk> of time .
12: i 'm a good <unk> of time .
13: i 'm a good <unk> of time .
14: i 'm very busy this <unk> today .
15: i 'm very busy this morning time .
16: i 'm very busy this morning time .
17: i 'm very busy this time .
18: i 'm very busy this time .
19: i have a lot of cold here .
20: i have a lot of <unk> here .
21: i have a lot of <unk> time .
22: i 'm very busy this morning time .
23: i have a lot of cold here .
24: i have a lot of cold here .
25: i have a lot of that morning .
26: i have a lot of cold here .
27: i have a lot of cold here .
28: i have a cold , will do .
29: i feel cold this morning this morning .
Ce que vous pouvez voir à partir des résultats, c'est que vous apprenez d'abord à générer une grammaire grossière et des mots larges, puis que vous vous ajustez progressivement pour vous fier à des mots spécifiques. On peut penser que c'est parce qu'au fur et à mesure que la convergence du réseau neuronal progresse, il devient possible de saisir clairement la différence de sens entre les mots. Le dernier exemple était intéressant, et il semble qu'il se soit trompé à tort «avoir froid ce matin» et «avoir froid» jusqu'à la fin de l'étude. De telles erreurs sémantiques sont propres aux réseaux neuronaux et sont peu susceptibles de se produire avec les techniques traditionnelles de traduction automatique. Le fait que ces différentes caractéristiques soient également considérées comme l'une des raisons pour lesquelles les réseaux de neurones attirent l'attention dans le traitement du langage naturel.
[^ 1]: Les deux sont abrégés en RNN, donc c'est déroutant. Il existe également des modèles tels que R2NN (réseau de neurones récurrents récursifs), qui ont peut-être amené la confusion dans la mauvaise direction.
[^ 2]: Cependant, contrairement au modèle * N * -gramme, il n'est pas possible d'extraire seulement une partie de la phrase et de calculer le score, donc dans des domaines comme la traduction automatique où l'analyse est avancée tout en calculant progressivement le score. Il y a aussi le problème que l'utilisation est limitée.
[^ 3]: Il existe différentes manières de convertir un mot en identifiant de mot, et la méthode utilisée affecte directement la précision du modèle. L'explication s'écarte jusqu'à présent du but de l'article, je ne vais donc pas l'expliquer ici.
[^ 4]: Le temps d'apprentissage fonctionne comme un goulot d'étranglement, donc si vous voulez vraiment faire du développement d'essais et d'erreurs, vous devriez avoir un GPU.
[^ 5]: Pour plus de simplicité, la formule ignore l'état interne du LSTM.
[^ 6]: Une implémentation récente, chainer.links, a une version de LSTM qui cache l'implémentation ici.
Recommended Posts