[PYTHON] Obtenez des données de Poloniex, un bureau de change virtuel, via l'API et utilisez le Deep Learning pour prédire le prix du lendemain.
introduction

Mesdames et messieurs, bonjour. Il s'agit de Yoshizaki (Twitter: @yoshizaki_kkgk), le directeur représentant de Kikagaku Co., Ltd.
Faisons quelque chose d'intéressant pendant nos vacances après une longue absence! Cet article a eu l'idée. Nous espérons que cet article permettra aux lecteurs de mieux comprendre l'approche d'analyse des données.
Étonnamment la réponse!
La dernière fois, j'ai écrit un article pour les débutants pour obtenir des données de Liqui sur l'échange de devises virtuelles via API. Article précédent: Récupérons les informations de l'API du bureau de change virtuel Liqui avec Python
Comment j'ai écrit cet article
Bien sûr, il y a eu une réaction de l'article précédent, mais nous organisons "** Artificial Intelligence / Machine Learning De-Black Box Seminar ** Comme étape suivante, nous avons reçu de nombreuses questions des étudiants participant à "/ séminaires /)", telles que "Comment devrais-je étudier?", Et les avons transmises comme étape suivante. Je voulais écrire un article technique que je pourrais vous donner.
J'ai pensé que quel genre d'article technique devrait être écrit pour répondre aux voix des étudiants, et je cherchais quelque chose qui pourrait satisfaire ce qui suit.
- Des données à grande échelle peuvent être facilement obtenues → ** Monnaie virtuelle ** --Profitez en visualisant et en traitant les données → ** Données de séries chronologiques ** ――Vous pouvez pratiquer des techniques de pointe → ** Apprentissage en profondeur **
Et
** J'espère qu'il y a des avantages **
Dans ce contexte, j'ai décidé de présenter la méthode d'analyse de séries chronologiques la plus avancée en utilisant la monnaie virtuelle comme thème.
Ce but
Je vois souvent des articles sur la création d'un environnement ou l'obtention de données, mais je veux toujours lire les articles qui expliquent du début à la fin **, donc pour moi J'écrirai également un article que je trouve intéressant pour d'autres personnes.
- ** Créez un environnement pour utiliser l'API de Poloniex avec Python **
- Obtenez des données ** Poloniex ** via l'API -Charger des données dans ** Pandas ** et calculer la moyenne mobile
- ** Visualisez vos données avec Matplotlib **
- ** L'analyse de régression multiple ** prédit le prix du jour suivant -Prédire le prix du lendemain avec ** RNN (LSTM) ** en utilisant ** Chainer **
En conclusion, il y a encore place à l'amélioration des prédictions utilisant le deep learning! Cependant, j'écrirai dans cet article au niveau où il peut être inclus dans la discussion d'essais et d'erreurs. Il existe un grand besoin de prévisions de prix / demande pour les monnaies virtuelles, mais j'espère que vous constaterez que c'est encore difficile.
De plus, j'ai amélioré cette méthode et j'ai obtenu des résultats relativement bons! Si oui, faites-le moi savoir! → Yoshizaki (Twitter: @yoshizaki_kkgk)
Création d'un environnement pour utiliser l'API de Poloniex avec Python
Construction de l'environnement Python
Tout d'abord, si vous ne pouvez pas installer Python sur votre PC, veuillez suivre les étapes décrites dans l'article ci-dessous. Des centaines de personnes ont assisté au séminaire organisé par notre société, mais il s'agit d'une procédure de paramétrage sans presque aucune erreur.
Veuillez noter que la procédure de configuration est différente entre Windows et Mac.
· Pour les fenêtres [Definitive Edition] Création d'un environnement d'apprentissage "machine learning" à l'aide de Python sous Windows
Installer le module Poloniex
Ouvrons d'abord le ** Jupyter Notebook **.
Si vous exécutez la commande suivante dans le terminal (invite de commande / Windows Powershell), l'environnement qui peut être exécuté via le navigateur sera lancé.
jupyter notebook
En fait, Jupyter Notebook peut être installé par pip, c'est donc pratique car vous n'avez pas à ouvrir le terminal à chaque fois.
Utilisez «pip» pour Windows et «pip3» pour Mac.
- J'utilise
pip3parce que je travaille sur un Mac.
Veuillez noter que lors de l'utilisation de pip dans Jupyter Notebook, il est nécessaire d'ajouter! Au tout début.
# python-Installation de poloniex
!pip3 install https://github.com/s4w3d0ff/python-poloniex/archive/v0.4.6.zip
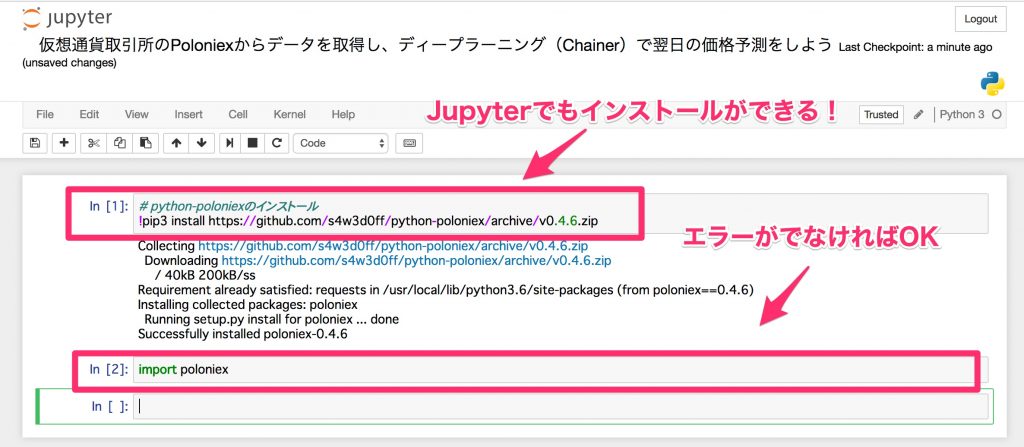
Après l'installation, importez-le et vérifiez s'il est correctement installé.
import poloniex
Vous êtes maintenant prêt à obtenir les données de Poloniex via l'API.
En fait, dans l'API de Poloniex, vous pouvez obtenir des données en cliquant sur l'URL, mais l'interface pour Python qui le rend encore plus facile à utiliser est python-poloniex installé cette fois.
Ces choses, qui ont les mêmes fonctions mais sont faciles à utiliser pour les humains (wrapper), sont appelées wrappers, et dans l'industrie de la programmation, ces choses sont souvent fabriquées et publiées.
Obtenez des données Poloniex via l'API
Obtenez des données
Maintenant, récupérons les données de Poloniex, qui est le sujet principal. Poloniex vous permet de récupérer plusieurs années de données à la fois, vous pouvez donc accéder aux données passées sans avoir à les enregistrer vous-même, ce qui est un excellent environnement pour l'analyse au niveau du prototype.
Grâce au wrapper Poloniex, vous pouvez obtenir les données avec une seule ligne de commande comme celle-ci: Ajustez l'intervalle d'échantillonnage et le nombre de jours au besoin.
import time
#Préparation de l'API poloniex
polo = poloniex.Poloniex()
#Lire 100 jours à 5 minutes d'intervalle (intervalle d'échantillonnage 300 secondes)
chart_data = polo.returnChartData('BTC_ETH', period=300, start=time.time()-polo.DAY*100, end=time.time())
Malheureusement, la seule façon de définir l'intervalle d'échantillonnage et le nombre de jours (en particulier l'intervalle d'échantillonnage) est de lire le code source écrit sur GitHub.
Si vous lisez le code source dans ce document, vous trouverez les commentaires suivants.
def returnChartData(self, currencyPair, period=False, start=False, end=False):
""" Returns candlestick chart data. Parameters are "currencyPair",
"period" (candlestick period in seconds; valid values are 300, 900,
1800, 7200, 14400, and 86400), "start", and "end". "Start" and "end"
are given in UNIX timestamp format and used to specify the date range
for the data returned (default date range is start='1 day ago' to
end='now') """
Autrement dit, la période comprend «300» (5 minutes), «900» (15 minutes), «1800» (1 heure), «7200» (4 heures), «14400» (8 heures), «86400» (12). Time) peut être spécifié.
De plus, bien que ce ne soit pas dans ce commentaire, si vous souhaitez définir la période sur un intervalle d'un jour, vous pouvez utiliser polo.DAY.
Lorsque j'ai vérifié les données acquises cette fois, les données ont été stockées dans le format suivant.
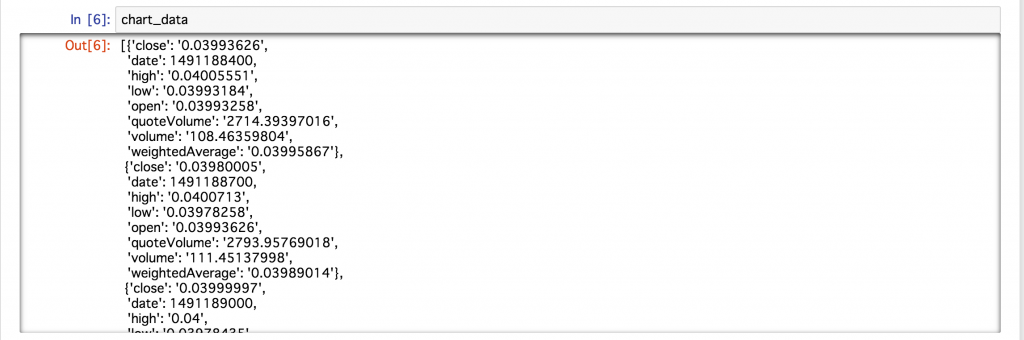
Il semble que les données ci-dessus soient stockées dans le type dictionnaire pour chaque temps d'échantillonnage. Dans l'état actuel des choses, il est difficile de les traiter comme des données, alors extrayons les données efficacement à l'aide de Pandas, ce qui est pratique pour les opérations de base de données.
Chargez des données dans Pandas et calculez la moyenne mobile
Charger des données dans Pandas
Pandas est définitivement utile lors de la manipulation de données en Python (opérabilité + nombreux articles de référence). Vous pouvez également utiliser le bloc-notes Jupyter pour visualiser facilement et proprement votre table.
Le chargement de données dans Pandas est facile. En particulier, si l'étiquette de données et la valeur sont incluses pour chaque temps d'échantillonnage, comme dans ce cas, elles peuvent être lues simplement en utilisant le «DataFrame» de Pandas.
#Importer des pandas
import pandas as pd
#Importez des données dans des pandas
df = pd.DataFrame(chart_data)
Comme beaucoup d'entre vous le savent peut-être déjà,
ModuleNotFoundError: No module named 'pandas'
Si vous obtenez une erreur indiquant qu'il n'y a pas de module appelé pandas comme
!pip3 install pandas # !Peut être installé dans Jupyter Notebook avec
Si vous l'installez comme ça, vous pouvez l'utiliser immédiatement (ou pip).
Maintenant, affichons les 10 premières lignes.
df.head(10)

** Excellent! ** **
Vous pouvez facilement le lire avec une seule commande, et vous pouvez vérifier les données dans un très beau format, ainsi le travail d'analyse des données sera accéléré! Merci Pandas!
À propos, par exemple, si vous souhaitez extraire des données uniquement pour la colonne close, vous pouvez les extraire simplement en nommant la colonne df ['close'], ce qui est très simple.

Calculons la moyenne mobile
Pandas facilite également le calcul des ** moyennes mobiles **.
Cette fois, la largeur de la fenêtre pour le calcul de la moyenne en tant que ligne à court terme a été définie sur 1 jour, et la largeur de fenêtre pour le calcul de la moyenne pour la ligne à long terme a été définie sur 5 jours. Le code source pour le calcul de la moyenne mobile est le suivant.
#Ligne court terme: Largeur de la fenêtre 1 jour (5 minutes x 12 x 24)
data_s = pd.rolling_mean(df['close'], 12 * 24)
#Ligne à long terme: largeur de la fenêtre 5 jours (5 minutes x 12 x 24 x 5)
data_l = pd.rolling_mean(df['close'], 12 * 24 * 5)
Ceci termine le calcul (facile!). Si tel est le cas, vous pouvez essayer de changer la largeur de la fenêtre de différentes manières!
Maintenant, traçons la moyenne mobile calculée cette fois car il est difficile de comprendre le changement uniquement par la valeur numérique.
Visualisez vos données avec Matplotlib
Utilisons-le d'abord
Matplotlib est également un module (bibliothèque) bien connu pour la visualisation de Python. Voir c'est croire! Tracons-le, y compris la moyenne mobile!
#Charger matplotlib (installer avec pip ou pip3 lorsqu'une erreur se produit)
import matplotlib.pyplot as plt
#L'intrigue la plus simple
plt.plot(df['close'])
plt.show()

Oh! Un graphique chronologique comme celui-ci était affiché.
Nettoyez votre parcelle avec Seaborn
Nous utiliserons Seaborn, un wrapper pour Matplotlib, qui peut rendre les tracés dans Matplotlib encore plus propres. De plus, si vous définissez la largeur pour remplir l'écran, ce sera plus facile à voir, donc si vous modifiez un peu ce paramètre avec un copier-coller, ce sera plus facile à analyser.
#Affichez le dessin proprement
from matplotlib.pylab import rcParams
import seaborn as sns
rcParams['figure.figsize'] = 15, 6
Tracons ici les données précédentes.

La largeur est pleine, les lignes de la grille sont incluses et l'arrière-plan est coloré, ce qui le rend beau. En regardant le Jupyter Notebook, la différence est évidente comme ça.
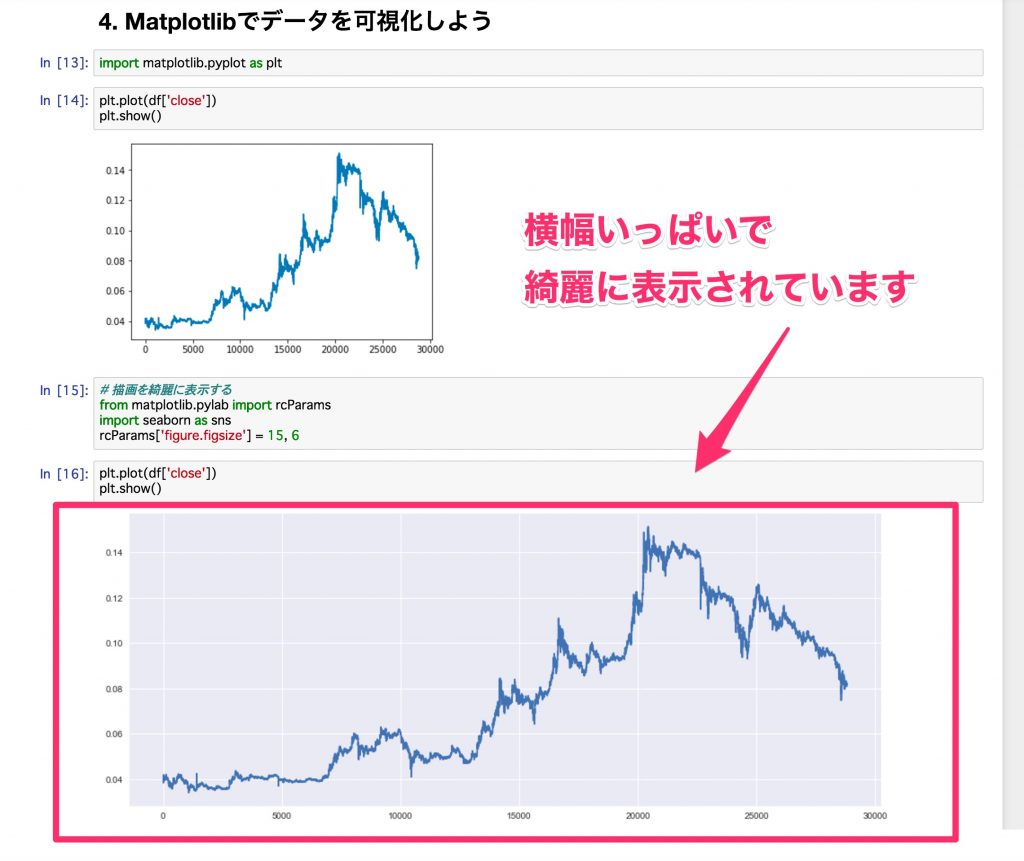
La couleur d'arrière-plan, etc. peut être modifiée du côté Seaborn, donc si vous êtes intéressé, veuillez vous référer à l'article suivant.
Référence: Introduction à Seaborn, une bibliothèque Python qui facilite la création de beaux graphiques
Changeons la couleur du tracé
Avec Matplotlib, changer de couleur est également très simple. Vous pouvez utiliser le nom de la couleur (par exemple, bleu ou rouge) dans l'option de couleur, et si vous êtes particulier sur les belles couleurs, vous devez le spécifier au format hexadécimal # .....
#Précisons la couleur du tracé (couleur)
plt.plot(df['close'], color='#7f8c8d')
plt.show()

De cette façon, la couleur a changé. Cette couleur est sélectionnée parmi ces couleurs plates de l'interface utilisateur.
Référence: couleurs plates de l'interface utilisateur
Tracons la ligne à court terme et la ligne à long terme
Avec Matplotlib, il est également très facile de tracer plusieurs lignes, de déclarer ce que vous voulez afficher, et enfin plt.show () et vous avez terminé.
Maintenant, traçons ensemble la ligne à court terme et la ligne à long terme qui ont été calculées du côté des Pandas.
#Des lignes à court et à long terme sont également tracées
plt.plot(df['close'], color='#7f8c8d')
plt.plot(data_s, color='#f1c40f') #Ligne à court terme
plt.plot(data_l, color='#2980b9') #Ligne à long terme
plt.show()

Je peux bien le tracer! Vous pouvez désormais évaluer visuellement non seulement la valeur numérique, mais également la largeur de la fenêtre pour la ligne à court terme et la ligne à long terme!
Avec Pandas et Matplotlib, c'est vraiment incroyable de pouvoir analyser cela en quelques lignes, et c'est une perte si vous ne savez pas.
Voilà donc pour les données, ** agrégation simple ** et ** visualisation **. À partir de là, nous présenterons une méthode d'analyse de données qui exploite pleinement l'apprentissage automatique avancé (principale technologie de l'intelligence artificielle).
Ce domaine est traité plus en profondeur dans notre ** Séminaire sur l'automatisation des systèmes **, donc si vous êtes intéressé, faites-le!

Prédire le prix du lendemain avec une analyse de régression multiple
Conditions préalables pour travailler avec des données de séries chronologiques
Ensuite, je pense qu'il y a beaucoup de gens qui se demandent s'il est possible de prédire le prix par la technologie d'apprentissage automatique, alors voyons-le dans un format pratique.
Dans les ** données de séries chronologiques (données qui fluctuent à chaque instant) **, il existe de nombreux tests tels que le type de caractéristiques dont ils disposent comme condition préalable à l'analyse, et il est inutile si cette caractéristique n'est pas effacée en premier lieu. Il existe de nombreuses discussions sur ces théories.
Bien sûr, je pense que vous devriez le vérifier un par un, mais ce n'est pas l'essence de cette fois de voir ces petites propriétés, mais pouvez-vous vraiment prédire le prix par apprentissage automatique? ?? Tout d'abord, j'aimerais connaître la conclusion, alors laissons une petite discussion sur la nature de ces données cette fois.
Pour ceux qui souhaitent approfondir cette propriété, les articles suivants sont recommandés car ils sont détaillés sur diverses caractéristiques. Référence: [Points importants que les débutants en analyse de données de séries chronologiques devraient connaître - Analyse de régression - Que faire avant d'effectuer une analyse de corrélation (vérification et transformation de la forme des données)](http://qiita.com / HirofumiYashima / objets / b6dabe412c868d271410)
Prédisons le prix immédiatement après
Ensuite, dans un premier temps, en machine learning, nous associerons la relation entre la variable d'entrée X et la variable de sortie y.
- Dans le programme, les données d'enseignant de la variable de sortie sont «t», et la valeur prédite de la variable de sortie est «y».
Lors de la réalisation de prévisions à l'aide de données de séries chronologiques, il est d'abord nécessaire de considérer dans quelles variables d'entrée et de sortie les données actuelles doivent être séparées. Cette fois, le prix que nous voulons prédire (variable de sortie y) est fixé au prix après 5 minutes, et le facteur utilisé pour la prédiction (variable d'entrée X) est les 30 derniers échantillons (5 minutes x 30 données).
Dans de nombreux cas, il est divisé de cette manière, mais en réalité ce ne sont pas de simples données chronologiques, mais il arrive souvent que la différence soit prise ou que le logarithme de la différence soit pris, mais les essais et erreurs sont la prochaine étape. Faisons le.
#Lecture de numpy, souvent utilisée dans les opérations d'algèbre linéaire
import numpy as np
#Comme il est reçu sous forme de chaîne de caractères (type String) via l'API, convertissez-le en type float.
#De plus, Chainer recommande float32, alors faites-le correspondre ici.
data = df['close'].astype(np.float32)
#Divisez les données en variable d'entrée x et variable de sortie t
x, t = [], []
N = len(data)
M = 30 #Nombre de variables d'entrée: utilisez les 30 derniers échantillons
for n in range(M, N):
#Séparation des variables d'entrée et des variables de sortie
_x = data[n-M: n] #Variables d'entrée
_t = data[n] #Variables de sortie
#Liste pour le calcul(x, t)Ajoutera à
x.append(_x)
t.append(_t)
De plus, lorsque vous l'utilisez pour une analyse ultérieure, il est pratique de stocker les données au format numpy, par exemple en vérifiant la taille, afin de convertir les données.
#Convertir au format numpy (pour plus de commodité)
x = np.array(x)
t = np.array(t).reshape(len(t), 1) #remodeler est une mesure qui ne provoque pas d'erreur dans Chainer plus tard
Diviser en données d'entraînement (train) et données de vérification (test)
En apprentissage automatique, créez un modèle et terminez! Au lieu de cela, il est divisé en deux éléments de données afin de confirmer (vérifier) la précision du modèle créé.
- ** Données de formation (train) **: Données pour la formation du modèle
- ** Données de vérification (test) **: Données pour vérifier l'exactitude en faisant correspondre les réponses
- En tant que développement ultérieur, il existe un cas où les données pour déterminer manuellement les paramètres à déterminer dans le cadre de la méthode appelée hyper-paramètres sont divisées en trois parties.
Tout d'abord, soyons en mesure de vérifier fermement le modèle créé en divisant ces données d'entraînement et de vérification en deux parties. Cette fois, les données de formation représenteront 70% du total et les données de vérification représenteront 30% du total.
# 70%Pour la formation, 30%Pour vérification
N_train = int(N * 0.7)
x_train, x_test = x[:N_train], x[N_train:]
t_train, t_test = t[:N_train], t[N_train:]
Si vous tirez parti de la fonction de découpage de liste de Python, vous pouvez facilement diviser votre ensemble de données comme décrit ci-dessus.
Apprenez un modèle pour l'analyse de régression multiple
En Python, ** Scikit-learn ** est la norme pour l'apprentissage automatique. Si vous n'êtes pas particulier sur la pointe, presque toutes les méthodes sont implémentées ici, et surtout, l'interface de fonctionnement est très bonne, donc c'est recommandé.
Maintenant, implémentons la formation de modèle en utilisant Scikit-learn (sklearn dans le programme).
# scikit-apprendre linéaire_modèle de charge
from sklearn import linear_model
#Déclaration du modèle d'analyse de régression multiple
reg = linear_model.LinearRegression()
#Apprendre un modèle à l'aide des données d'entraînement
reg.fit(x_train, t_train)
Oui. C'est tout! Tout ce que vous avez à faire est de déclarer le modèle, de transmettre les données d'entraînement au modèle et de «fit». C'est assez facile à battre, mais je suis très reconnaissant que ce code simple réduise les erreurs du côté humain.
Lorsque l'analyse des données ne fonctionne pas, il est souvent difficile de dire si les données sont mauvaises ou le programme est mauvais, et en utilisant ces bibliothèques, vous pouvez réduire votre propre responsabilité (erreurs de programme), donc l'analyse factorielle Peut procéder sans heurts.
Valider le modèle
Vérifions l'exactitude en utilisant les données de vérification ci-dessus. Comme indice de précision, nous utilisons un indice appelé coefficient de décision, qui est calculé entre 0 et 1 (à proprement parler, il prend également un moins). En gros, 1 est le meilleur, 0 est hors de question (bien que l'expression soit trop extrême).
En outre, lors de la vérification, examinons la valeur du coefficient de détermination non seulement pour les données de vérification, mais également pour les données d'apprentissage. Idéalement, un bon modèle est bon si les deux valeurs sont comparables et précises.
Vous pouvez utiliser score pour calculer le coefficient de décision.
#Données d'entraînement
reg.score(x_train, t_train)
#Données d'entraînement
reg.score(x_train, t_train)

Comme mentionné ci-dessus, la valeur ** est très proche de ** 1, et j'imagine le développement de l'histoire suivante.
Bienvenue à riche
"Oh! Je pense que cela peut être prédit avec une précision incroyablement bonne! Vous pourriez être très riche à partir de demain." «Je dois penser à des mesures d'économie d'impôt parce que je peux gagner de l'argent grâce à l'investissement. "Commençons l'immobilier avec des appartements par ici. D'accord, achetons 100 millions de dollars."
Visualisez les résultats
Maintenant, traçons la valeur mesurée et la valeur prédite avec l'espoir que le coefficient de décision soit une très bonne valeur.
Tout d'abord, tracez la valeur mesurée (en bleu) et la valeur prévue (en orange) pour les données d'entraînement.
#Données d'entraînement
plt.plot(t_train, color='#2980b9') #La valeur mesurée est bleue
plt.plot(reg.predict(x_train), color='#f39c12') #La valeur prédite est orange
plt.show()

Vous pouvez voir que les deux données se chevauchent très bien et sont presque en accord (augmentation supplémentaire des attentes). Cependant, comme ce sont les données utilisées pour la formation, il est naturel que cela fonctionne bien. Le sujet principal est le résultat des données de vérification.
Maintenant, pour les données de vérification, un tracé de la valeur mesurée (bleu) et de la valeur prédite (orange)
#Données de validation
plt.plot(t_test, color='#2980b9') #La valeur mesurée est bleue
plt.plot(reg.predict(x_test), color='#f39c12') #La valeur prédite est orange
plt.show()

Oh! C'est aussi exactement le chevauchement! Génial! Trop merveilleux! Cela a peut-être confirmé l'homme riche.
Tout le monde, à la prochaine fois à Dubaï.
Tomber d'un homme riche qui était trop tôt
En fait, cela semble très bien fonctionner, mais cela ne fonctionne pas vraiment du tout. Malheureusement, Dubaï est susceptible d'être un peu plus loin. Ah, un million de dollars ... lol
Pour expliquer ce que cela signifie, examinons une partie des données de validation, pas le tout.
Lors de l'extraction d'une pièce, c'est OK si vous spécifiez la plage avec plt.xlim ().
#Jetons un coup d'œil à une partie pour la vérification
plt.plot(t_test, color='#2980b9') #La valeur mesurée est bleue
plt.plot(reg.predict(x_test), color='#f39c12') #La valeur prédite est orange
plt.xlim(200, 300) #Certaines fonctionnalités sont faciles à comprendre
plt.show()

En fait, il semble que la prédiction soit bonne à première vue, mais vous pouvez voir que la valeur prédite (orange) est simplement déviée d'un échantillon de la valeur mesurée (bleu). ..
En bref, je pensais qu'une valeur plausible avait été obtenue par prédiction après apprentissage par apprentissage automatique, mais je viens de sortir la valeur d'un échantillon avant comme valeur prédite, et ce n'était pas du tout une méthode qui utilisait ma tête. Si la valeur d'il y a 5 minutes est utilisée comme valeur prédite, une valeur plausible sortira sûrement et le coefficient de décision sera calculé élevé.
Lorsque j'ai changé cela pour la prédiction après 1 jour au lieu de la prédiction après 5 minutes, un tel résultat a été obtenu.
- Tout le monde, veuillez essayer ce programme.

Il s'agit d'une prédiction pour les données d'apprentissage, mais très particulièrement, le résultat est que la valeur prédite n'a décalé les données que d'un jour (1 échantillon x 12 x 24 = 288 échantillons en 5 minutes).
C'est peut-être la raison pour laquelle on dit que la prévision de la demande est très difficile à réaliser par l'analyse des données.
Pourquoi cela arrive-t-il?
De nombreuses techniques d'apprentissage automatique permettent un meilleur ajustement en ajustant des valeurs appelées paramètres dans le modèle pour réduire l'erreur partout. Et dans les données de séries chronologiques comme cette fois, un phénomène appelé ** marche aléatoire ** se produit, ce qui soulève la difficulté de l'ajustement des paramètres.
Cela signifie que la probabilité que le prix augmente ou diminue dans l'échantillon suivant est de 5: 5 par rapport à l'échantillon précédent. Considérant 5: 5 en moyenne (valeur attendue), la réponse pour honorer l'apprentissage automatique des étudiants est de penser que ** le prochain prix n'augmentera ni ne baissera **. En conséquence, la théorie veut qu'il soit préférable de refléter la valeur du jour précédent comme elle l'est dans la valeur du jour suivant.
Dans l'apprentissage automatique, ce raisonnement est dérivé uniquement des données et reflété dans la valeur prédite.
À titre de test, en regardant la différence de prix par rapport à la veille, l'histogramme est le suivant.
#Faites la différence par rapport à l'échantillon précédent
t_diff = t[:-1] - t[1:]
#le distroplot seaborn est pratique
sns.distplot(t_diff)
plt.show()

La largeur du bac est un peu large, alors regardons de plus près. De plus, les lignes tracées (résultats de l'estimation du rapport de densité du noyau) ne sont pas nécessaires, supprimons-les.
#Augmenter le nombre de bacs, kde(Estimation du rapport de densité du noyau gaussien)Tracer
sns.distplot(t_diff, bins=3000, kde=False)
plt.xlim(-0.00075, 0.00075)
plt.ylim(0, 750)
plt.show()

La moitié droite de 0 est le nombre de fois où le prix a augmenté par rapport à la veille, et la moitié gauche de 0 est le nombre de fois où le prix a baissé par rapport à la veille. Comme vous pouvez le voir, il est distribué symétriquement autour de 0. Par conséquent, il s'agit d'une marche aléatoire de 5: 5 **, qu'elle monte ou descend. Remarque: il existe différentes méthodes de test statistiques pour déterminer la marche aléatoire, pas visuellement, donc si vous êtes intéressé, veuillez le vérifier.
Que devrais-je faire?
Dans les méthodes d'apprentissage automatique telles que l'analyse de régression multiple, on suppose que ** les données sont générées indépendamment de la distribution réelle à chaque instant **. En d'autres termes, on suppose que ** les données à l'instant précédent n'affectent pas les données à la fois suivante ** (elles devraient être générées aléatoirement à partir de la vraie distribution).
Par exemple, lorsqu'il s'agit d'estimer le loyer, le premier échantillon contient les conditions de la maison de M. A (distance de la gare, la taille de la pièce) et le deuxième échantillon contient les conditions de la maison de M. B. Cependant, en particulier, la maison de M. A n'a pas de rapport avec la maison de M. B (elle est générée indépendamment).
Par conséquent, dans le cas de l'analyse de séries chronologiques où les données de l'époque précédente ont une grande influence, les hypothèses sont différentes en premier lieu, donc naturellement cela ne devrait pas fonctionner.
Le modèle de Markov caché était celui qui voulait modéliser cette propriété. L'explication détaillée est omise car l'article suivant l'explique d'une manière merveilleuse et facile à comprendre, mais en bref, ** j'ai créé un mécanisme qui peut prédire même si les données précédentes affectent les données suivantes **. ..
Référence: Données de séries chronologiques: Bases du modèle Markov caché et plate-forme de réseau récurrent
Et il est également implémenté dans le deep learning, en plein essor ces dernières années, ** Recurrent Neural Network **, dit ** RNN **.
Donc, à la fin de cet article, je voudrais conclure en introduisant la modélisation utilisant ce ** RNN **.
Prédire les prix du lendemain avec RNN (LSTM) en utilisant Chainer
Qu'est-ce que Chainer?

** Chainer ** est un framework qui peut être utilisé avec ** Python ** spécialisé dans ** l'apprentissage profond (réseau de neurones) ** développé par la société japonaise ** Preferred Networks **. Il existe également TensorFlow fourni par Google et son wrapper Keras, et je pense personnellement que de nombreuses personnes au Japon utilisent l'un ou l'autre.
** Chainer est à l'origine créé avec une interface facile à apprendre **, et comparé à d'autres frameworks, il est très flexible lors de la personnalisation du développement du deep learning au niveau papier ** Je trouve intéressant que vous puissiez le faire **.
Le mécanisme appelé ** Define by Run ** est une grande différence par rapport aux autres frameworks tels que TensorFlow de Google, et pour les débutants **, vous pouvez vérifier la valeur numérique et la taille pendant l'apprentissage ** etc. ** L'avantage est la facilité de débogage ** (j'ai entendu directement du développeur Chainer). Certes, ** comment il se comporte pendant l'apprentissage et où l'erreur se produit ** est très important pour les développeurs, donc adopter cette structure est ** un gros avantage * Je sens que c'est *.
Notre société est la seule société de formation officielle au Japon (au 27 juillet 2017) à diffuser la technologie Chainer de Preferred Networks à la société. Faire. En outre, nous collaborons également avec Microsoft pour organiser un séminaire pratique d'apprentissage en profondeur où vous pouvez apprendre à accélérer la mise en œuvre de l'apprentissage en profondeur par Chainer sur une machine GPU sur Microsoft Azure, donc si vous le souhaitez ** ici ** Veuillez jeter un coup d'œil.

Prédisons avec LSTM
Maintenant, implémentons une méthode appelée ** LSTM (Long Short-Term Memory) **, qui est souvent implémentée dans RNN. Il y a plusieurs raisons, mais comme le LSTM est souvent introduit sous le nom de RNN, je pense qu'il est bon de se souvenir de RNN ≒ LSTM au début.
Chargez le module requis
Chainer doit charger divers modules et vous vous y habituerez lors de son utilisation, vous pourrez donc d'abord le copier et le coller. Ceux utilisés ci-dessous sont limités au minimum nécessaire, c'est donc une bonne idée de ne retenir que le nom.
import chainer
import chainer.links as L
import chainer.functions as F
from chainer import Chain, Variable, datasets, optimizers
from chainer import report, training
from chainer.training import extensions
Définissons le modèle de LSTM
Sans parler de Chainer, si vous ne savez pas comment utiliser Python, vous pouvez trouver cela difficile au début, mais pour le moment, nous avons inclus la section L.LSTM, donc il est normal d'avoir suffisamment d'intervalles pour implémenter LSTM.
class LSTM(Chain):
#Spécifiez la structure du modèle
def __init__(self, n_units, n_output):
super().__init__()
with self.init_scope():
self.l1 = L.LSTM(None, n_units) #Ajout d'une couche de LSTM
self.l2 = L.Linear(None, n_output)
#Réinitialiser la valeur conservée dans LSTM
def reset_state(self):
self.l1.reset_state()
#Calcul de la fonction de perte
def __call__(self, x, t, train=True):
y = self.predict(x, train)
loss = F.mean_squared_error(y, t)
if train:
report({'loss': loss}, self)
return loss
#Calcul de la propagation vers l'avant
def predict(self, x, train=False):
l1 = self.l1(x)
h2 = self.l2(h1)
return h2
Le reste est pour ceux qui sont habitués à Chainer, mais comme LSTM a une structure qui contient l'état en interne, utilisez reset_state () pour le maintenir dans l'état interne à chaque fois que vous apprenez. Vous devez réinitialiser la valeur que vous avez.
Il est normal d'utiliser cette zone, alors étudions petit à petit.
Personnaliser le programme de mise à jour pour LSTM
C'est le point le plus difficile et il est très difficile de le faire soi-même.
Une nouvelle fonction appelée Trainer a été ajoutée à Chainer, et si vous définissez les informations nécessaires telles que le modèle à l'avance, vous pouvez utiliser trainer.run () pour démarrer automatiquement l'apprentissage et l'état d'apprentissage. Une fonction facile à utiliser a été ajoutée, telle que la vérification de la progression de.
Cependant, comme l'intérieur a été transformé en boîte noire dans le bon sens, il est devenu difficile de le personnaliser moi-même.
Lors de l'utilisation de LSTM, il est nécessaire d'exécuter reset_state () écrit au début pour initialiser la valeur d'état pour chaque boucle d'apprentissage, mais la formation décrite dans le tutoriel officiel etc. Lorsque .StandardUpdater est utilisé, reset_state () pour chaque boucle d'apprentissage n'est pas exécuté (évidemment), et la formation LSTM ne peut pas être effectuée correctement.
Quand j'ai demandé au développeur de Chainer, il m'a dit que cela pouvait être résolu par les deux méthodes suivantes.
- Personnalisez-vous en remplaçant la fonction de la partie mise à jour de
training.StandardUpdater - Écriture en LSTM sans état
La dernière méthode est difficile car les variables détenues en interne sont écrites et transmises par soi-même, et la première méthode sera utilisée pour résoudre le problème.
Créez votre propre LSTMupdater qui hérite de training.StandardUpdater.
Il a été dit que la partie mise à jour est décrite dans ʻupdate_core`, alors remplacez cette fonction.
class LSTMUpdater(training.StandardUpdater):
def __init__(self, data_iter, optimizer, device=None):
super(LSTMUpdater, self).__init__(data_iter, optimizer, device=None)
self.device = device
def update_core(self):
data_iter = self.get_iterator("main")
optimizer = self.get_optimizer("main")
batch = data_iter.__next__()
x_batch, y_batch = chainer.dataset.concat_examples(batch, self.device)
#↓ réinitialiser ici_state()Vous permet de courir
optimizer.target.reset_state()
#D'autres sont identiques à la mise à jour de la série chronologique
optimizer.target.cleargrads()
loss = optimizer.target(x_batch, y_batch)
loss.backward()
#Libérer dans les séries chronologiques_backward()Il semble que l'efficacité du calcul augmentera
loss.unchain_backward()
optimizer.update()
Préparer les données de formation et de validation pour Chainer
Pour le jeu de données utilisé par Chainer, il est nécessaire de préparer les données sous forme de liste ou Numpy, et pour chaque échantillon, il est nécessaire de le résumer dans un taple avec entrée et sortie et le lister.
Il sera difficile d'écrire dans des phrases, mais ce n'est pas grave si vous le donnez comme liste (zip (..., ...)).
Il est difficile de trouver une référence, vous vous demandez peut-être comment créer votre propre jeu de données à utiliser avec Chainer, mais c'est la méthode recommandée par les développeurs de Chainer.
#Si l'ensemble de données pour le chainer est suffisant pour tenir en mémoire, indiquez(zip(...))conseillé
#↑ Méthode recommandée par les développeurs PFN
train = list(zip(x_train, t_train))
test = list(zip(x_test, t_test))
De plus, dans les cas où l'ensemble de données ne tient pas dans la mémoire (par exemple, des dizaines de milliers de données d'image), le «TupleDataset» de Chainer peut être utilisé pour charger efficacement les données dans la mémoire uniquement lorsqu'il est utilisé par lots. Il semble qu'il soit implémenté, donc si vous pensez que la taille des données est grande et lente, veuillez l'utiliser.
À propos de TupleDataset: https://docs.chainer.org/en/stable/reference/datasets.html
Préparation au formateur
À ce stade, la préparation est terminée, alors configurez-le sur «Trainer» dans le flux suivant.
- Déclaration de modèle: utilisez le modèle créé --Définition de l'optimiseur: sélectionnez la méthode d'optimisation et associez-la au modèle --Définition des itérateurs: isoler les jeux de données par lot --Définition du programme de mise à jour: résumer les règles de mise à jour, etc. --Définition du formateur: résumer les paramètres liés à l'exécution de la formation
Aussi, au tout début, corrigez la graine avec la commande suivante, et n'oubliez pas de ** assurer la reproductibilité **. Sachez que si vous oubliez cela, les résultats changeront entre aujourd'hui et demain, et vous serez blessé lorsque vous essaierez de vous présenter à votre patron demain.
#Assurer la reproductibilité
np.random.seed(1)
Passons en revue le flux ci-dessus à la fois.
#Modèle de déclaration
model = LSTM(30, 1)
#Définition de l'optimiseur
optimizer = optimizers.Adam() #L'algorithme d'optimisation utilise Adam
optimizer.setup(model)
#définition de l'itérateur
batchsize = 20
train_iter = chainer.iterators.SerialIterator(train, batchsize)
test_iter = chainer.iterators.SerialIterator(test, batchsize, repeat=False, shuffle=False)
#définition du programme de mise à jour
updater = LSTMUpdater(train_iter, optimizer)
#définition de formateur
epoch = 30
trainer = training.Trainer(updater, (epoch, 'epoch'), out='result')
#extension de formateur
trainer.extend(extensions.Evaluator(test_iter, model)) #Évaluation avec données d'évaluation
trainer.extend(extensions.LogReport(trigger=(1, 'epoch'))) #Afficher le milieu du résultat d'apprentissage
#Perte de sortie pour les données de train et perte pour les données de test pour chaque époque
trainer.extend(extensions.PrintReport(['epoch', 'main/loss', 'validation/main/loss', 'elapsed_time']), trigger=(1, 'epoch'))
Exécution de l'apprentissage
L'exécution de l'apprentissage commence par la commande suivante.
trainer.run()

Comme mentionné ci-dessus, il est affiché en ** interactif **, il est donc très pratique de voir le processus d'apprentissage en un coup d'œil.
Cette fois, les résultats d'apprentissage ci-dessus sont obtenus, mais la «perte» pour les données d'apprentissage diminue, mais la «perte» pour les données de vérification augmente plutôt que diminue. Veuillez essayer différents essais et erreurs, comme essayer ** abandonner **.
Bonus: modèle avec abandon supplémentaire
À propos, lors de l'adoption du décrochage, il est normal de créer un tel modèle.
class LSTM(Chain):
def __init__(self, n_units, n_output):
super().__init__()
with self.init_scope():
self.l1 = L.LSTM(None, n_units)
self.l2 = L.Linear(None, n_output)
def reset_state(self):
self.l1.reset_state()
def __call__(self, x, t, train=True):
y = self.predict(x, train)
loss = F.mean_squared_error(y, t)
if train:
report({'loss': loss}, self)
return loss
def predict(self, x, train=False):
#Ajouter un abandon (à utiliser uniquement pendant l'entraînement)
if train:
h1 = F.dropout(self.l1(x), ratio=0.05)
else:
h1 = self.l1(x)
h2 = self.l2(h1)
return h2
Lorsque cet abandon a été ajouté, la perte de validation a également diminué régulièrement, il semble donc que des mesures de surajustement soient nécessaires pour de telles données.
Tracez les résultats
Examinons d'abord les données d'entraînement.
#Calcul de la valeur prédite
model.reset_state()
y_train = model.predict(Variable(x_train)).data
#terrain
plt.plot(t_train, color='#2980b9') #La valeur mesurée est bleue
plt.plot(y_train, color='#f39c12') #La valeur prédite est orange
plt.show()

Il semble que vous puissiez le prédire dans une certaine mesure.
Ensuite, regardons les données de vérification.
#Calcul de la valeur prédite
model.reset_state()
y_test = model.predict(Variable(x_test)).data
#terrain
plt.plot(t_test, color='#2980b9') #La valeur mesurée est bleue
plt.plot(y_test, color='#f39c12') #La valeur prédite est orange
plt.show()
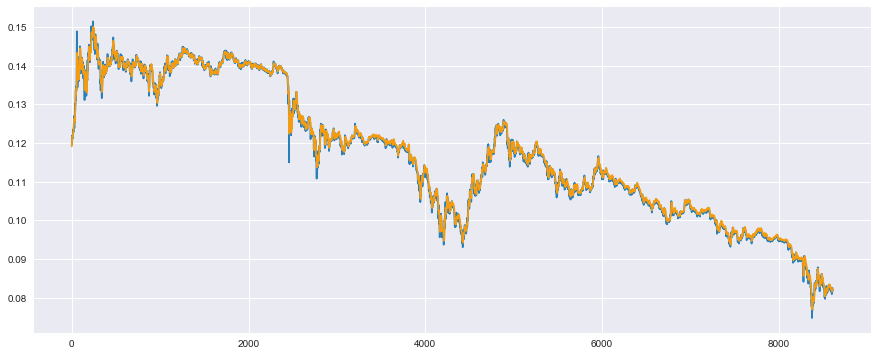
Il semble que les données de vérification puissent être prédites dans une certaine mesure. Je voudrais évaluer cela quantitativement, mais le facteur de décision que j'ai mentionné plus tôt donne d'assez bons résultats même s'il y a un décalage dans le temps, donc il n'est pas fiable, alors jetons un coup d'œil.
Voyons maintenant ce qui était purement faux.
#Jetons un coup d'œil à une partie pour la vérification
plt.plot(t_test, color='#2980b9') #La valeur mesurée est bleue
plt.plot(y_test, color='#f39c12') #La valeur prédite est orange
plt.xlim(200, 300) #Certaines fonctionnalités sont faciles à comprendre
plt.show()

D'une manière ou d'une autre, il semble que le problème d'un écart plus simple que la précédente analyse de régression multiple ait été résolu. Cependant, il y a encore un léger décalage dans le temps, donc ce n'est pas parfait.
Perspectives d'avenir
Cette fois, le but était d'essayer de l'utiliser grossièrement, donc je prévois de faire des essais et des erreurs à partir de maintenant. Nous prévoyons d'introduire les essais et erreurs suivants si nous avons une autre chance.
- Considérez les prix autres que la monnaie virtuelle qui correspondent aux variables d'entrée
- Considérez d'autres indicateurs tels que la différence et le logarithme de la différence
À l'origine, on dit que des fonctionnalités telles que ces dernières sont automatiquement créées en tant que fonctionnalités du réseau neuronal, mais cela ne semble pas être si idéal et cela est compris comme un savoir-faire humain. On dit qu'il vaut mieux l'ajouter docilement si c'est un nombre de fonctionnalités aussi bon qu'il l'est, donc je pense que je devrais essayer ce domaine également.
en conclusion
J'ai remarqué que c'était un très long article, mais il n'y a pas beaucoup de blogs techniques que j'ai parcourus du début à la fin, et je suis heureux d'écrire beaucoup de choses que je veux écrire, et c'est pour les lecteurs. J'espère que cela aide.
Le terme analyse de données semble joli, mais il nécessite également un savoir-faire en ingénierie, tel que l'acquisition et la mise en forme de telles données, ainsi que des considérations mathématiques lors de la construction du LSTM de Chainer. C'est un travail difficile et amusant d'absorber rapidement un large éventail de connaissances, alors essayez-le.
Nous nous réjouissons de votre suivi
Nous fournissons des informations sur l'apprentissage automatique et l'intelligence artificielle d'un point de vue commercial et des ouvrages de référence recommandés.
Kikagaku Co., Ltd. (HP officiel) Président et PDG Ryosuke Yoshizaki
- Twitter:@yoshizaki_kkgk
- Facebook:@ryosuke.yoshizaki --Blog: blog du représentant de Kikagaku
Jusqu'à la fin Merci d'avoir lu.
Recommended Posts