[PYTHON] Traduction japonaise de documents Apache Spark - Présentation du mode cluster
Une traduction en japonais de la présentation de déploiement suivante du projet Apache Spark. http://spark.apache.org/docs/latest/cluster-overview.html
Si vous trouvez quelque chose qui ne va pas avec la traduction, veuillez nous en informer dans les commentaires.
Les traductions japonaises de Quick Start et d'introduction EC2 sont également publiées ci-dessous, alors jetez un œil.
- Quick Start
http://qiita.com/mychaelstyle/items/46440cd27ef641892a58 - Spark on AWS EC2
http://qiita.com/mychaelstyle/items/b752087a0bee6e41c182
Présentation du mode cluster
This document gives a short overview of how Spark runs on clusters, to make it easier to understand the components involved. Read through the application submission guide to submit applications to a cluster.
Ce document est un aperçu rapide du fonctionnement de Spark sur un cluster pour comprendre facilement les composants complexes. Lisez le Guide de soumission d'application pour savoir comment déployer votre application sur votre cluster.
http://spark.apache.org/docs/latest/submitting-applications.html
Composants
Spark applications run as independent sets of processes on a cluster, coordinated by the SparkContext object in your main program (called the driver program).
Les applications Spark fonctionnent ensemble comme un ensemble de processus indépendants sur un cluster avec l'objet SparkContext du programme principal de votre application (appelé programme pilote).
Specifically, to run on a cluster, the SparkContext can connect to several types of cluster managers (either Spark’s own standalone cluster manager or Mesos/YARN), which allocate resources across applications.
En particulier, SparkContext se connecte à plusieurs types de gestionnaires de cluster (le propre gestionnaire de cluster autonome de Spark ou Mesos / YARN) et alloue des ressources entre les applications pour qu'elles fonctionnent dans un seul cluster.
Once connected, Spark acquires executors on nodes in the cluster, which are processes that run computations and store data for your application. Next, it sends your application code (defined by JAR or Python files passed to SparkContext) to the executors. Finally, SparkContext sends tasks for the executors to run.
Une fois connecté, Spark obtient des executeros sur les nœuds du cluster, ils effectuent des calculs pour votre application et stockent les données. Ensuite, votre code d'application (fichiers JAR ou Python passés à SparkContext) est envoyé aux exécutables. Enfin, SparkContext envoie les tâches d'exécution des exécutables.
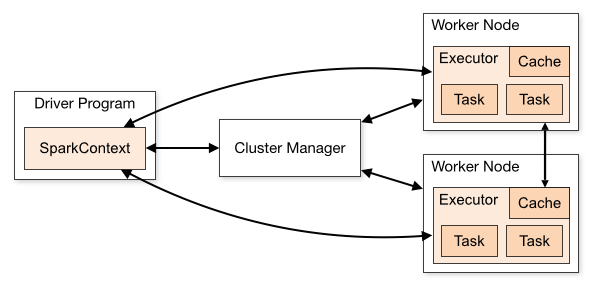
There are several useful things to note about this architecture:
Il y a des choses utiles sur l'architecture.
- Each application gets its own executor processes, which stay up for the duration of the whole application and run tasks in multiple threads. This has the benefit of isolating applications from each other, on both the scheduling side (each driver schedules its own tasks) and executor side (tasks from different applications run in different JVMs). However, it also means that data cannot be shared across different Spark applications (instances of SparkContext) without writing it to an external storage system.
Chaque application obtient son propre ensemble de processus exécutables tandis que chaque thread qui exécute une tâche est exécuté. Ceci est très utile en termes de planification (chaque pilote planifie les tâches indépendamment) et d'exécuteur (les tâches de différentes applications s'exécutant sur différentes JVM) pour séparer chaque application individuellement. Cependant, cela signifie que les données ne peuvent pas être partagées par différentes applications Spark (instances SparkContext) sans l'utilisation d'un système de stockage externe.
- Spark is agnostic to the underlying cluster manager. As long as it can acquire executor processes, and these communicate with each other, it is relatively easy to run it even on a cluster manager that also supports other applications (e.g. Mesos/YARN).
Spark n'a rien à voir avec le gestionnaire de cluster. Tout en demandant des processus d'exécuteur et en communiquant entre eux, Spark s'exécute sur un gestionnaire de cluster qui prend en charge de vraies autres applications relativement facilement.
- Because the driver schedules tasks on the cluster, it should be run close to the worker nodes, preferably on the same local area network. If you’d like to send requests to the cluster remotely, it’s better to open an RPC to the driver and have it submit operations from nearby than to run a driver far away from the worker nodes.
Le pilote planifie les tâches sur le cluster et doit être exécuté à proximité d'un ensemble de nœuds de travail, plutôt dans le même réseau local. Si vous souhaitez envoyer des demandes à distance, il est préférable d'utiliser RPC pour soumettre votre application et l'exécuter à proximité plutôt que de l'exécuter à distance dans les nœuds worker.
Recommended Posts