[PYTHON] Implémenter un réseau neuronal convolutif
Il est courant d'essayer les bibliothèques Deep Learning, mais même si vous pouvez exécuter Example, cela ne fonctionne souvent pas lorsque vous essayez de l'utiliser dans des cas réels.
J'ai essayé de le déplacer, mais la précision n'est pas ressortie, la manière de traiter les données était mauvaise, les paramètres du modèle étaient mauvais, je ne connais pas du tout la cause ... Afin de surmonter la situation, il est encore nécessaire de comprendre le mécanisme. Je vais.
C'est pourquoi, dans ce volume, je voudrais expliquer les étapes à franchir et les raisons de celle-ci, de la toute première ligne de départ de la préparation des images à l'apprentissage du CNN implémenté dans Chainer. Theory est écrit dans la première partie, mais ici comment les paramètres définis dans la bibliothèque, etc. correspondent au côté de la théorie Je voudrais aussi voir environ.
Le savoir-faire introduit cette fois-ci est résumé dans le référentiel suivant. J'espère que cela sera utile lors de la reconnaissance d'image.
Préparation des données
Il est facile de penser que vous devez préparer beaucoup de données telles que des dizaines de milliers, mais dans la reconnaissance d'images récente, il est courant d'utiliser un modèle entraîné.
 CS231n Lecture11 Training ConvNets in practice, p26
CS231n Lecture11 Training ConvNets in practice, p26
Le modèle formé n'est-il pas seulement capable de faire des «tâches entraînées»? Comme vous pourriez le penser (par exemple, la détection de chat), les couches inférieures du modèle ont la capacité d'extraire les caractéristiques de base de l'image. Par conséquent, en entraînant (ou en ajoutant) uniquement la couche supérieure tout en laissant la couche inférieure telle quelle, il est possible d'obtenir des performances de discrimination même avec une petite quantité de données. C'est ce qu'on appelle le réglage fin (ou apprentissage par transfert).
Le nombre de couches que vous devez laisser dépend de la proximité de votre tâche prévue avec la "tâche entraînée" d'origine.
 CS231n Lecture11 Training ConvNets in practice、p33
CS231n Lecture11 Training ConvNets in practice、p33
Caffe est célèbre pour sa bibliothèque de modèles entraînés. Il existe une description officielle de la méthode Fine Tuning utilisant Caffe.
Fine-tuning CaffeNet for Style Recognition on “Flickr Style” Data
Chainer peut charger des modèles Caffe, donc un réglage fin est également possible.
Bonnes pratiques personnelles pour un réglage fin avec Chainer
Si vous ne voulez pas changer la valeur du modèle entraîné que vous avez appris lors de l'entraînement, vous pouvez utiliser l'indicateur volatitle pour arrêter la propagation d'erreur vers la couche inférieure entraînée.
Vous trouverez ci-dessous un didacticiel sur TensorFlow.
Si vous souhaitez apporter un modèle de Caffe, il existe les outils suivants.
De cette manière, le nombre de données à collecter diminue progressivement en raison des réalisations de nos prédécesseurs. Cette fois, j'ai stocké le modèle entraîné, alors veuillez l'utiliser (j'ai utilisé git lfs pour la première fois).
Cependant, on peut dire qu'il devient de plus en plus nécessaire de comprendre quel type de modèle j'utilise comme base. Ce point sera expliqué dans la section suivante, nous allons donc ici expliquer brièvement l'acquisition de données d'image à partir d'ImageNet, qui est célèbre comme un ensemble de données d'image.
Un ensemble de données qui balise les images en fonction de la structure conceptuelle du mot WordNet. Le nombre de mots enregistrés (c'est-à-dire les étiquettes) est d'environ 100 000 et des activités sont menées dans le but de collecter environ 1 000 images pour chaque mot. Il est également connu comme l'ensemble de données utilisé dans ILSVRC (Image Net Large Scale Visual Recognition Challenge).
Maintenant, si vous êtes un chercheur, vous pouvez télécharger l'ensemble de cet ensemble de données si vous postulez et obtenez l'autorisation. Si ce n'est pas le cas, vous pourrez obtenir l'URL de l'image pour chaque étiquette, et vous devrez la déposer vous-même. En plus de cela, des données telles que des données de caractéristiques d'image et des limites d'objet peuvent également être acquises.

Vous pouvez obtenir l'URL de l'image à partir de Télécharger. Cependant, il existe de nombreux liens rompus.

Je l'ai fait parce que c'est dans la nature humaine de vouloir télécharger en traitement parallèle tout en évitant les liens cassés.
mlimages/mlimages/scripts/gather_command.py
Supposons maintenant que vous ayez téléchargé et préparé l'image pour le moment.
Comprendre le modèle
Les images collectées doivent être traitées en fonction de la tâche souhaitée et du modèle formé à utiliser. Par conséquent, je voudrais ici approfondir ma compréhension en suivant le code du modèle actuel. Le code AlexNet de Chainer est utilisé pour l'explication. Il s'agit d'un modèle monumental qui a démarré l'activité du réseau neuronal dans la reconnaissance d'images. Notez que la définition du réseau est presque la même pour les bibliothèques autres que Chainer (Caffe, etc.), vous pouvez donc penser que le contenu expliqué ici peut être appliqué à d'autres que Chainer.
chainer/examples/imagenet/alex.py
C'est un code très court, donc je posterai un extrait de la définition ci-dessous.
class Alex(chainer.Chain):
"""Single-GPU AlexNet without partition toward the channel axis."""
insize = 227
def __init__(self):
super(Alex, self).__init__(
conv1=L.Convolution2D(3, 96, 11, stride=4),
conv2=L.Convolution2D(96, 256, 5, pad=2),
conv3=L.Convolution2D(256, 384, 3, pad=1),
conv4=L.Convolution2D(384, 384, 3, pad=1),
conv5=L.Convolution2D(384, 256, 3, pad=1),
fc6=L.Linear(9216, 4096),
fc7=L.Linear(4096, 4096),
fc8=L.Linear(4096, 1000),
)
self.train = True
def clear(self):
self.loss = None
self.accuracy = None
def __call__(self, x, t):
self.clear()
h = F.max_pooling_2d(F.relu(
F.local_response_normalization(self.conv1(x))), 3, stride=2)
h = F.max_pooling_2d(F.relu(
F.local_response_normalization(self.conv2(h))), 3, stride=2)
h = F.relu(self.conv3(h))
h = F.relu(self.conv4(h))
h = F.max_pooling_2d(F.relu(self.conv5(h)), 3, stride=2)
h = F.dropout(F.relu(self.fc6(h)), train=self.train)
h = F.dropout(F.relu(self.fc7(h)), train=self.train)
h = self.fc8(h)
self.loss = F.softmax_cross_entropy(h, t)
self.accuracy = F.accuracy(h, t)
return self.loss
Désormais, si vous souhaitez le personnaliser et l'utiliser vous-même, les parties les plus importantes sont les parties d'entrée et de sortie.
La partie d'entrée est liée à la taille de l'image et à savoir si elle doit être mise à l'échelle des gris, et la partie de sortie est importante lors de l'ajout ou de la modification du nombre de classes à identifier lors de l'implémentation du réglage fin. Devenir.
Tout d'abord, à propos de l'entrée. Les points sont les suivants.
- Taille de l'image: ʻinsize = 227`
- Première couche à recevoir l'entrée:
conv1 = L.Convolution2D (3, 96, 11, stride = 4)
L'important est la définition de la première couche. Selon l 'API Convolution2D, les paramètres peuvent être interprétés comme suit.
- in_channel: 3
- out_channel: 96
- ksize: 11
- stride: 4
Que représentent ces valeurs d'élément? Ici, dans la section théorie, [Définition du filtre utilisé pour la convolution](http://qiita.com/icoxfog417/items/5fd55fad152231d706c2#%E3%83%95] % E3% 82% A3% E3% 83% AB% E3% 82% BF% E3% 81% AE% E8% A8% AD% E5% AE% 9A) est cité.
- Nombre de filtres (K): Le nombre de filtres à utiliser. La plupart du temps, la valeur de la deuxième puissance est prise (32, 64, 128 ...)
- Taille du filtre (F): la taille du filtre utilisé
- Largeur de mouvement du filtre (S): Largeur pour déplacer le filtre
- Padding (P): combien remplir la zone de bord de l'image
Tout d'abord, un filtre est comme une fenêtre utilisée pour le pliage. L'image suivante détermine dans quelle mesure l'image originale est compressée par cette taille et ainsi de suite.

Ensuite, il est facile de comprendre comment la taille du filtre détermine la taille après compression en regardant la figure ci-dessous.
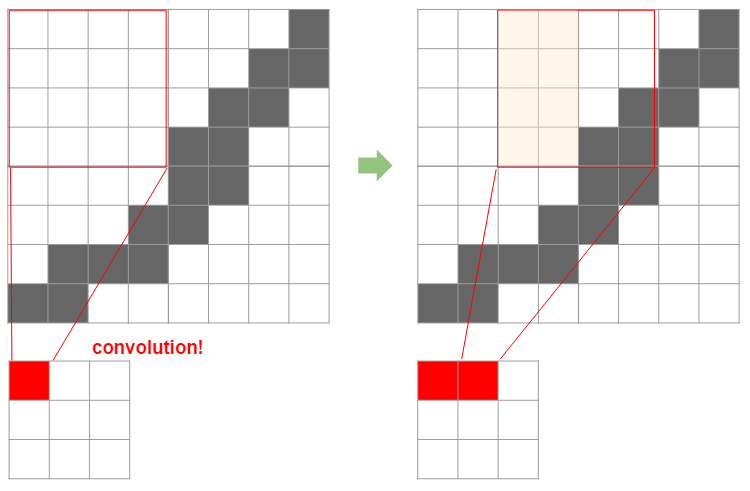
Ici, un filtre 4x4 est appliqué à une image 8x8 en la faisant glisser de deux. Dans ce cas, l'image finale 8x8 sera compressée en 3x3. Ici, la taille d'origine est $ N $, la taille du filtre est $ F $, la largeur de la diapositive est $ S $ et la largeur d'image compressée est calculée par la formule suivante.
Si vous appliquez cette formule, vous pouvez voir que $ (8 -4) / 2 + 1 = 3 $, ce qui est exactement 3. Lorsque le padding $ P $ est utilisé pour créer une marge autour de l'image (en fait, la luminosité est 0 = noir, et dans ce sens, la marge est ** noire **), c'est comme suit.
Ceci est facile à comprendre en regardant la figure ci-dessous, ce qui signifie que la taille de la marge x 2 est ajoutée à la taille d'origine.

Comme vous pouvez le voir du fait que la division est incluse, il est nécessaire d'ajuster la largeur du filtre à appliquer, la largeur de la diapositive, etc. afin qu'ils soient correctement divisibles. Il s'agit de la première limitation lors de l'utilisation d'autres modèles.
Je vais résumer ici. Il a été constaté que la largeur de la couche après application du filtre peut être calculée en utilisant les trois points suivants parmi les premiers points mentionnés.
- Taille du filtre (F): la taille du filtre utilisé
- Largeur de mouvement du filtre (S): Largeur pour déplacer le filtre
- Padding (P): combien remplir la zone de bord de l'image
** Largeur de couche après filtrage = $ (N + P \ fois 2 --F) / S + 1 $ ** ** L'image d'entrée doit correspondre aux filtres utilisés dans le modèle existant (le résultat de la formule ci-dessus sera un entier net) **
Maintenant, ce qui est lié au dernier "nombre de filtres (K)" restant est la "profondeur (nombre de canaux)" de l'image. Le nombre de canaux est l'élément de profondeur de l'image et correspond à la couleur (RVB) de l'image. Par conséquent, le nombre de canaux dans la première couche est souvent de 3. Au contraire, si le réseau existant est utilisé et qu'il vaut 1, cela signifie une échelle de gris et doit être converti en échelle de gris par prétraitement.
Maintenant, réfléchissons à ce qui arrive à la profondeur après le pliage. La profondeur du filtre correspond à la profondeur de l'image d'entrée (sinon elle ne peut pas être calculée), donc la profondeur sera toujours "1" après la convolution. Et si nous ajoutions plus de filtres? Cela augmentera le nombre de couches convolutives avec une profondeur de 1 par le nombre de filtres (voir la figure ci-dessous).

Normalement, CNN utilise plusieurs filtres de cette manière pour la convolution. En d'autres termes, le "nombre de filtres (K)" est la "profondeur (nombre de canaux)" après pliage tel quel. C'est, bien sûr, la même chose que la profondeur d'entrée de la couche suivante (je pense que le out_channel de conv1 et le in_channel de conv_2 ont la même valeur dans le code).
Maintenant que nous avons vu tous les éléments d'un filtre, revisitons la définition de la couche 1.
- in_channel: 3-> Profondeur de la première image. RVB = 3
- out_channel: 96-> Profondeur de couche après convolution = Nombre de filtres (K)
- ksize: 11-> Taille du filtre (F)
- foulée: 4-> Largeur de la glissière du filtre (S)
Convolution2D a également un paramètre pour pad, qui correspond naturellement au padding (P). Vous comprenez maintenant les paramètres. Et à partir de là, vous pouvez voir qu'AlexNet a les restrictions suivantes:
- La taille de l'image d'entrée doit être un nombre divisible par 4 après avoir soustrait 11 (la taille définie 227 le satisfait). * À proprement parler, il est nécessaire de satisfaire à la définition des couches suivantes.
- L'image d'entrée doit être représentée en couleur RVB
Par conséquent, la taille de l'image n'est pas réellement fixe et d'autres tailles peuvent être utilisées si les conditions sont remplies. Cependant, si vous ne savez pas si le contenu appris à l'avance sera appliqué, la partie sortie sera affectée. Dans AlexNet, c'est une fonction linéaire de la 6ème couche, et à partir de là, c'est la partie qui classe en utilisant le résultat alambiqué. Si vous effectuez un réglage fin, vous devrez le remplacer ou le connecter à SVM, mais dans ce cas, vous devez comprendre la définition suivante.
La définition de la 6ème couche de Chainer est fc6 = L.Linear (9216, 4096), d'où il est clair que le nombre d'entrées est de 9216 et le nombre de sorties est de 4096, mais l'entrée "9216" Savez-vous ce que ça veut dire?
Puisque la sortie de la couche de convolution est naturellement "largeur x hauteur x profondeur", on en déduit que la "conv5" précédente est "largeur x hauteur x profondeur = 9216". La profondeur est claire du fait que le out_channel de conv5 est de 256, donc si vous divisez 9216 par 256, vous pouvez voir qu'il est de 36, donc largeur x hauteur = 36, donc la largeur est de 6. Bien sûr, ce "6" est lorsque la largeur de l'image d'entrée est 227 telle que définie, donc si vous souhaitez modifier la taille de l'image d'entrée, vous devez en ajouter plus et ajuster la taille.
Bien sûr, vous pouvez ajuster la taille en la pliant, mais vous pouvez également utiliser le pooling qui ajuste la taille sans utiliser de poids, c'est-à-dire comprime la largeur (voir ici pour plus de détails sur la mise en commun](http: / /qiita.com/icoxfog417/items/5fd55fad152231d706c2#%E3%83%AC%E3%82%A4%E3%83%A4%E6%A7%8B%E6%88%90)).
Cette couche de pooling est également utilisée dans AlexNet, et c'est à cause de ce pooling que la largeur qui était de 13 au stade de conv5 est maintenant de 6 à fc6. La figure ci-dessous montre le processus de calcul jusqu'à fc6, donc si vous êtes intéressé, veuillez le suivre. L'ordre de calcul est conv1> pool1> conv2> pool2> conv3> conv4> conv5> pool5> fc6 (* Il n'y a pas de pooling entre conv3> conv4 et conv4> conv5).
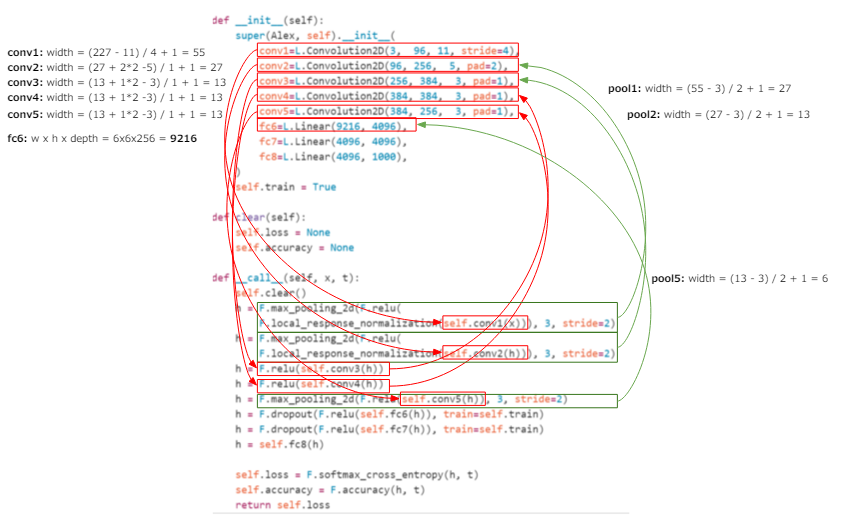
Par conséquent, si vous utilisez une grande image, vous devriez la compresser un peu plus avec ce pooling (au contraire, si elle est petite, elle ne sera pas poolée). Comme mentionné précédemment, cette mise en commun n'utilise pas de pondérations, donc les pondérations que vous apportez du modèle entraîné ne sont pas pertinentes. Par conséquent, si vous utilisez un modèle entraîné, il est préférable d'ajuster en regroupant au lieu de la couche convolutive entraînée et pondérée.
Enfin, je résumerai les points lors de la personnalisation du modèle entraîné. En théorie, je pense que cela peut ou non fonctionner en utilisation réelle. Je voudrais le résumer à nouveau dès que je l’aurai compris.
-
La définition du calque révèle les contraintes de taille et de couleur
-
Si vous souhaitez attacher une machine d'apprentissage pour un réglage fin à une couche spécifique, le nombre d'entrées peut être dérivé en calculant la taille de l'image d'entrée et la définition du filtre de chaque couche dans l'ordre.
-
Récemment, il n'est pas recommandé de le calculer sauf pour étudier car c'est un filtrage un peu compliqué et la couche devient très profonde. La couche supérieure doit correspondre au nombre de classes à classer, il est donc recommandé de l'attacher au sommet avec obéissance.
-
Si vous souhaitez redimensionner l'image d'entrée, conservez la couche de convolution pondérée entraînée et ajustez avec la mise en commun
-
Récemment, il est devenu courant de ne pas mordre le pooling, mais je pense qu'il est possible de le mettre en place pour détourner le modèle entraîné.
-
Pour des informations "récemment", voir Stanford's Lecture (Lecture 7 p89). Il y a aussi un peu d'AlphaGo. Comprendre CNN conduit également à comprendre le mécanisme de pointe de l'IA.
Prétraitement des données
À ce stade, je comprends le modèle et je sais quel type de données doit être préparé. Cependant, ce qui est nécessaire lors de la formation n'est pas une "image", mais une "matrice" qui l'exprime numériquement. Si vous faites une erreur dans ce processus de conversion, le modèle entraîné ne vous aidera pas. Les points les plus importants sont les suivants.
- Transformation matricielle
- Intuitivement, largeur (L) x hauteur (H) x profondeur (K)
- En pensant dans une matrice, les lignes de la matrice correspondent à la hauteur et les colonnes correspondent à la largeur, donc la matrice est H x L x K.
- Lors de l'apprentissage, il est d'usage de le convertir davantage en K x H x W
- Voir chainer / examples / imagenet / train_imagenet.py
read_imagepour le traitement réel. .. - Réglage de la profondeur
- Si le modèle suppose RVB mais uniquement la luminosité, dupliquez la valeur de luminosité et ajustez. La seule luminosité peut être déterminée par le fait que la dimension est 2 (car il n'y a pas de couleur, elle est représentée par une matrice à 2 dimensions).
- Il existe un format appelé RGBA dans le monde, donc dans ce cas, A est supprimé.
- Pour le traitement réel, reportez-vous à
load_imagedans Caffe / io.py. - Normalisation des données d'image
- Normaliser en soustrayant la moyenne calculée de tous les ensembles de données. Notez que, bien sûr, toutes les tailles d'image doivent être identiques.
- Voir chainer / examples / imagenet / compute_mean.py pour le processus de calcul moyen.
- Mise à l'échelle
- La couleur et la luminosité RVB prennent des valeurs de 0 à 255, divisez donc cela par 255 pour le convertir en une valeur de 0 à 1.
- Voir chainer / examples / imagenet / train_imagenet.py
read_imagepour le traitement réel. ..
Dans l'outil créé cette fois, nous avons implémenté une classe (LabeledImage) qui lit une image, ajuste la profondeur, puis effectue une conversion matricielle.
to_array et from_array peuvent être matricés et restaurés à partir de là. Puisqu'il dispose également d'un procédé de redimensionnement de l'image, il est possible de réaliser une matrice après un traitement tel qu'un ajustement de taille. J'espère que vous pourrez l'utiliser comme référence pour la mise en œuvre.
L'implémentation est presque la même pour le calcul de la moyenne, mais j'ai essayé de l'enregistrer en tant qu'image réelle. Cela le rend disponible même si vous n'utilisez pas numpy, et présente l'avantage supplémentaire de pouvoir voir les tendances dans vos données.
Voici une image moyenne créée à partir d'images de chat ImageNet, mais vous pouvez voir qu'aucune caractéristique n'est visible.

C'est une mauvaise tendance. En effet, s'il y a une caractéristique commune à toutes les images, la couleur etc. n'aurait dû changer que dans cette partie (pour un visage humain, la position des yeux et de la bouche, etc.). Bien sûr, si le nombre d'images est grand, il est naturel que ce soit globalement noirâtre, mais je pense que cela peut être utilisé pour saisir la tendance, par exemple ne la faire que dans une certaine classe.
Préparation des données des enseignants
Eh bien, vous ne pouvez pas apprendre simplement en préparant des images. Pour cette image, nous devons créer des données d'enseignant telles que la classe à laquelle elle appartient. Pour cela, le format dans lequel le «chemin de l'image» et «l'étiquette de l'enseignant» sont décrits comme une paire est souvent utilisé (le sentiment ci-dessous).
tabby\51879196_5a4404873a.jpg 10
tortoiseshell\1802271715_d1b3acb8f4.jpg 13
tom\1433889998_6a42ce2633.jpg 12
Bien sûr, si vous faites cela manuellement, le soleil se couchera, donc je veux le créer automatiquement. Si les images sont stockées dans des dossiers pour chaque classe, la structure des dossiers sera les données de l'enseignant telles quelles, vous pouvez donc l'utiliser pour créer des données d'enseignant.
Même avec l'outil créé cette fois, j'ai créé un script simple et l'ai étiqueté (mlimages / mlimages / scripts / label_command.py /label_command.py)).
Si vous collectez automatiquement des images en grattant, etc., il se peut que vous ne puissiez pas les ouvrir ou que certaines d'entre elles ne conviennent pas comme données d'enseignant. C'est une bonne idée d'éliminer ces facteurs ici, car vous aurez envie de pleurer si vous frappez ces images pendant que vous apprenez et qu'une exception vole et que vous arrêtez d'apprendre pendant des heures. Lors de la formation, il est nécessaire de calculer l'image moyenne pour la normalisation (décrite ci-dessus), et à ce moment-là, la conversion et le calcul vers la même matrice que dans la production sont effectués, vous pouvez donc y vérifier. Cette fois, lors du calcul de l'image moyenne, "l'image utilisée (réalisée) pour le calcul moyen" est sortie sous forme de fichier et utilisée comme données d'apprentissage.
De plus, diviser les données en test et entraînement, les mélanger correctement, etc. sont identiques à l'apprentissage automatique normal. Cela peut être fait simplement en divisant le fichier ou en utilisant des nombres aléatoires, donc je ne pense pas que ce soit un problème.
Apprentissage de modèle
Une fois que les données de l'enseignant sont prêtes, il ne vous reste plus qu'à vous entraîner. La plus grande considération ici est la performance et le suivi (cela semble être la gestion opérationnelle ...).
performance
Pour la performance, les points suivants sont importants:
- GPU
- Traitement parallèle
GPU. J'étais parfaitement conscient de cela, mais préparons quand même une machine GPU (AWS est également acceptable). Avec un CPU, vous ne pouvez pas être sûr que la précision s'améliorera même si vous attendez quelques jours, mais avec un GPU, vous pouvez le voir en quelques heures ou le calcul est terminé. De nombreux paramètres doivent être ajustés pendant l'entraînement, tels que la configuration du modèle, les hyperparamètres tels que le taux d'entraînement et la taille du lot. La clé est la vitesse à laquelle ce cycle de vérification / confirmation peut être exécuté, il est donc préférable de le résoudre avec du matériel là où il peut être résolu avec du matériel.
Le traitement parallèle est un appareil en termes de logiciel par rapport à cela. Lors de l'apprentissage d'images, seul le chemin d'accès à l'image est inscrit dans les données de l'enseignant. Par conséquent, il est nécessaire de lire les images au moment de l'apprentissage, mais si vous faites cela dans l'ordre du haut ..., l'apprentissage lent sera encore plus lent, donc les images dans le mini-lot (un groupe de données à former en même temps) sont parallèles. Il est nécessaire de concevoir comme lire avec. Puisque multiprocessing est disponible en Python et ʻasyncio` est disponible à partir de 3, parallélisez là où il peut être parallélisé en utilisant ces modules.
Surveillance
Pendant l'apprentissage, vous devez voir si vous apprenez correctement. Enregistrez l'erreur et la précision pour chaque quantité fixe d'apprentissage (1 lot / époque, etc.). Il est également important de sauvegarder le modèle en cours de route. Si vous venez de sortir sur la console, il ne restera rien en cas de déconnexion ou de coup de foudre, il est donc recommandé d'enregistrer dans un fichier journal, un fichier modèle, etc. qui reste de toute façon sur le disque. ..
L'exemple de Chainer est une bonne référence pour la mise en œuvre d'un script d'apprentissage spécifique.
chainer/examples/imagenet/train_imagenet.py
Comme async / await est devenu plus facile à écrire en Python, je pense que le multitraitement sera un peu plus facile à écrire en Python3. J'ai utilisé Python3 pour l'outil que j'ai créé cette fois (mais il n'y a pas encore de journalisation ...).
mlimages/mlimages/training.py/generate_batches
Ceci complète l'explication de tous les points. Enfin, je vais mettre un script qui résume la collecte de données, la création de données des enseignants et l'apprentissage en l'utilisant comme référence. AlexNet est utilisé pour le modèle comme d'habitude.
mlimages/examples/chainer_alex.py
J'espère que cela vous sera utile lorsque vous apprendrez réellement. La précision de ce script ne s'est pas améliorée du tout sur le CPU même après 2 jours, mais lorsqu'elle est calculée sur le GPU, elle est devenue une précision de 50 à 60% en quelques heures. Dans le modèle réel, contrairement à l'exemple, la précision n'augmente pas en le regardant, et il n'y a aucune garantie. J'étais parfaitement conscient que la contribution de la vitesse est toujours significative dans le rafraîchissement basé sur une évaluation légitime du modèle.