[PYTHON] J'ai essayé de reconnaître le mot de réveil
Qu'est-ce qui s'est passé
bonne année. Ceci est un enregistrement de mon étude de passe-temps que je suis allé pendant mon retour à la maison du Nouvel An.
Normalement, lorsque vous utilisez un assistant vocal, je pense que vous pouvez appeler avec un mot de réveil tel que Google. Quand j'ai reçu Spécialisation en apprentissage profond (Coursera) par le Dr Andrew Ng Il y a eu un problème avec la mise en œuvre d'un modèle qui détecte les vocalisations de veille.
Cet article est une revue du cours ci-dessus, C'est un enregistrement que j'ai généré des données d'entraînement basées sur les données enregistrées de ma propre voix et les ai entraînées avec le modèle implémenté. Il y a peu de données et les résultats sont simples, mais j'aimerais finalement augmenter les données et améliorer le modèle à expérimenter.
Spécialisation en apprentissage profond est volumineux mais facile à comprendre. Je le recommande car j'ai pu le comprendre même en tant que débutant.
Environnement d'exécution
- Google Colaboratory --Type d'exécution: Python 3
- Accélérateur matériel: GPU
- Tensorflow ver 1.15.0
Créer des données d'entraînement
Matériel
- Bruit de fond .wav 2 types --Enregistrement vocal .wav ――Deux types d'enregistrements de votre propre voix disant `` TEST '' (voix au sol, voix arrière)
Contenu
--Défini une fonction pour générer une grande quantité de données d'entraînement à partir d'une petite quantité de matériel
- Changez au hasard le volume du bruit, l'emplacement où la voix est combinée et le nombre (1 à 3) pour garantir la variation
--Ce que vous obtenez
- Données d'entrée X: Spectrogramme de la source sonore synthétique pendant 10 s (nombre de tranches de temps, nombre de tranches de fréquence)
- Libellé correct y: 0 ou 1 drapeau ――L'étiquette environ 40 ms après la partie où la voix a été synthétisée a été réglée sur 1. Le reste est 0
Données générées
--La figure ci-dessus est un spectrogramme qui est des données d'entrée (vertical: fréquence [Hz] horizontal: temps) ――La couleur de la partie correspondante a changé en raison de la composition de la voix. ―― Cette couleur montre la force de la composante de fréquence de la voix.
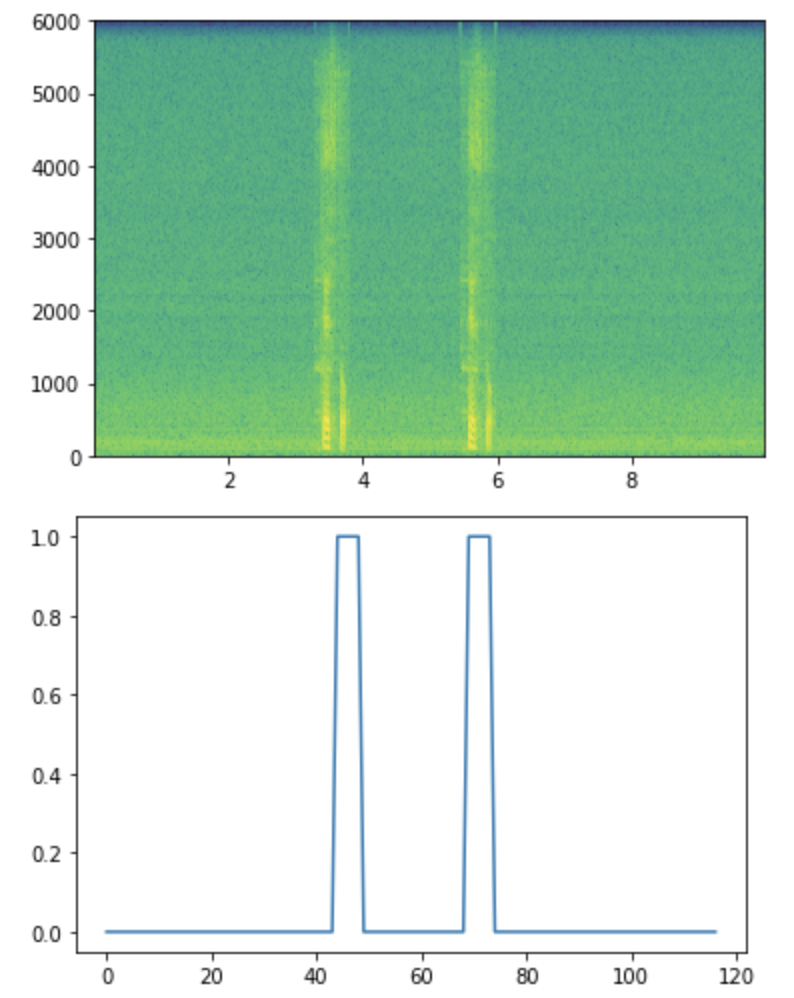
- La figure ci-dessous montre l'étiquette de réponse correcte générée. --L'étiquette de la pièce combinée devient 1.
- Essayez de déduire cela à partir des données d'entrée
Fonction de génération
Une fonction définie pour la génération de données
- make_train_sound(background, target, length, dumpwav=False) --Générer une source sonore synthétique et une étiquette de réponse correcte
- make_train_pattern(pattern_num)
- Appuyez plusieurs fois sur make_train_sound pour générer des données d'entraînement
BACKGROUND_DIR = '/tmp/background'
VOICE_DIR = '/tmp/voice'
RATE = 12000
Ty = 117
TRAIN_DATA_LENGTH = int(10*RATE)
def make_train_sound(background, target, length, dumpwav=False):
"""
arguments
background: background noise data
target: target sound data (will be added to background noise)
length: sample length
dumpwav: make wav data
output
X: spectrogram data ( shape = (NFFT, frames))
y: flag data (shap)
"""
NFFT = 512
FLAG_DULATION = 5
TARGET_SYNTH_NUM = np.random.randint(1,high=3)
# initialize
train_sound = np.copy(background[:length])
gain = np.random.random()
train_sound *= gain
target_length = len(target)
y_size = Ty
y = [0 for i in range(y_size)]
# Synthesize
for num in range(TARGET_SYNTH_NUM):
# Decide where to add target into background noise
range_start = int(length*num/TARGET_SYNTH_NUM)
range_end = int(length*(num+1)/TARGET_SYNTH_NUM)
synth_start_sample = np.random.randint(range_start, high=( range_end - target_length - FLAG_DULATION*(NFFT) ))
# Add
train_sound[synth_start_sample:synth_start_sample + target_length] += np.copy(target)
# get Spectrogram
specgram, freqs, t, img = plt.specgram(train_sound,NFFT=NFFT, Fs=RATE, noverlap=int(NFFT/2), scale="dB")
X = specgram # (freqs, time)
# Labeling
target_end_sec = (synth_start_sample+target_length)/RATE
train_sound_sec = length/RATE
flag_start_sample = int( ( target_end_sec / train_sound_sec ) * y_size)
flag_end_sample = flag_start_sample+FLAG_DULATION
if y_size <= flag_end_sample:
over_length = flag_end_sample-y_size
flag_end_sample -= over_length
duration = FLAG_DULATION - over_length
else:
duration = FLAG_DULATION
y[flag_start_sample:flag_end_sample] = [1 for i in range(duration)]
if dumpwav:
scipy.io.wavfile.write("train.wav", RATE, train_sound)
y = np.array(y)
return (X, y)
def make_train_pattern(pattern_num):
"""
return list of training data
[(X_1, y_1), (X_2, y_2) ... ]
arguments
pattern_num: Number of patterns (X, y)
output:
train_pattern: X input_data, y labels
[(X_1, y_1), (X_2, y_2) ... ]
"""
bg_items = get_item_list(BACKGROUND_DIR)
voice_items = get_item_list(VOICE_DIR)
train_pattern = []
for i in range(pattern_num):
item_no = get_item_no(bg_items)
fs, bgdata = read(bg_items[item_no])
item_no = get_item_no(voice_items)
fs, voicedata = read(voice_items[item_no])
pattern = make_train_sound(bgdata, voicedata, TRAIN_DATA_LENGTH, dumpwav=False)
train_pattern.append(pattern)
return train_pattern
- À l'aide de ceux-ci, 1500 données ont été générées et séparées pour le train, la validation et le test. --Depuis 1500 ou plus ont dépassé la RAM de Colab et arrêté, jusqu'à présent
- Afin de traiter les données d'entrée comme des données de série chronologique, la forme a été modifiée (nombre de tranches de temps, nombre de tranches de fréquence).
#Créer des données
train_patterns = make_train_pattern(1500)
#Entrée du taple obtenu,Divisez en étiquettes de réponses correctes
X = []
y = []
for t in train_patterns:
X.append(t[0].T) # (Time, Freq)
y.append(t[1])
X = np.array(X)
y = np.array(y)[:,:,np.newaxis]
train_patterns = None
# training, validation,Diviser pour le test
train_num = int(0.7*len(X))
val_num = int(0.2*len(X))
test_num = int(0.1*len(X))
X_train = X[:train_num]
y_train = y[:train_num]
X_validation = X[train_num:train_num+val_num]
y_validation = y[train_num:train_num+val_num]
X_test = X[train_num+val_num:]
y_test = y[train_num+val_num:]
train_data_shape = X_train[0].shape
Modèle d'apprentissage
--Défini un modèle avec une couche de CNN et deux couches de LSTM. --input_shape est défini sur la taille des données d'entraînement (spectrogramme)
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_6 (InputLayer) (None, 467, 257) 0
_________________________________________________________________
conv1d_6 (Conv1D) (None, 117, 196) 755776
_________________________________________________________________
batch_normalization_16 (Batc (None, 117, 196) 784
_________________________________________________________________
activation_6 (Activation) (None, 117, 196) 0
_________________________________________________________________
dropout_16 (Dropout) (None, 117, 196) 0
_________________________________________________________________
cu_dnnlstm_11 (CuDNNLSTM) (None, 117, 128) 166912
_________________________________________________________________
batch_normalization_17 (Batc (None, 117, 128) 512
_________________________________________________________________
dropout_17 (Dropout) (None, 117, 128) 0
_________________________________________________________________
cu_dnnlstm_12 (CuDNNLSTM) (None, 117, 128) 132096
_________________________________________________________________
batch_normalization_18 (Batc (None, 117, 128) 512
_________________________________________________________________
dropout_18 (Dropout) (None, 117, 128) 0
_________________________________________________________________
time_distributed_6 (TimeDist (None, 117, 1) 129
=================================================================
Total params: 1,056,721
Trainable params: 1,055,817
Non-trainable params: 904
_________________________________________________________________
--Il semble que vous puissiez appliquer la couche entièrement connectée à la série chronologique en utilisant TimeDistributed.
- La couche entièrement connectée de la fonction d'activation sigmoïde est définie dans la couche finale de sorte que la probabilité est sortie.
X = TimeDistributed(Dense(1, activation='sigmoid'))(X)
--CuDNNL STM a été utilisé pour prioriser la vitesse --Je l'ai changé car la progression était lente lorsque je me suis entraîné avec un LSTM normal --CuDNNLSTM ne fonctionnait pas sur Colab lors de l'utilisation de la série Tensorflow ver2.0
- Est-il possible de l'utiliser en important depuis tf.compat.v1.keras.layers?
- Cette fois, je l'ai essayé avec la version 1.15.0 pour gagner du temps.
Résultat d'apprentissage
――Nous avons procédé à l'apprentissage dans les conditions suivantes
detector = model(train_data_shape)
optimizer = Adam(lr=0.0001, beta_1=0.9, beta_2=0.999, decay=0.01)
detector.compile(loss='binary_crossentropy', optimizer=optimizer, metrics=["accuracy"])
history = detector.fit(X_train, y_train, batch_size=10,
epochs=500, verbose=1, validation_data=(X_validation, y_validation))
――L'apprentissage a duré environ 3 secondes par époque. Haute vitesse au lieu de l'effet CuDNNLSTM
Epoch 1/500
1050/1050 [==============================] - 5s 5ms/step - loss: 0.6187 - acc: 0.8056 - val_loss: 14.2785 - val_acc: 0.0648
Epoch 2/500
1050/1050 [==============================] - 3s 3ms/step - loss: 0.5623 - acc: 0.8926 - val_loss: 14.1574 - val_acc: 0.0733
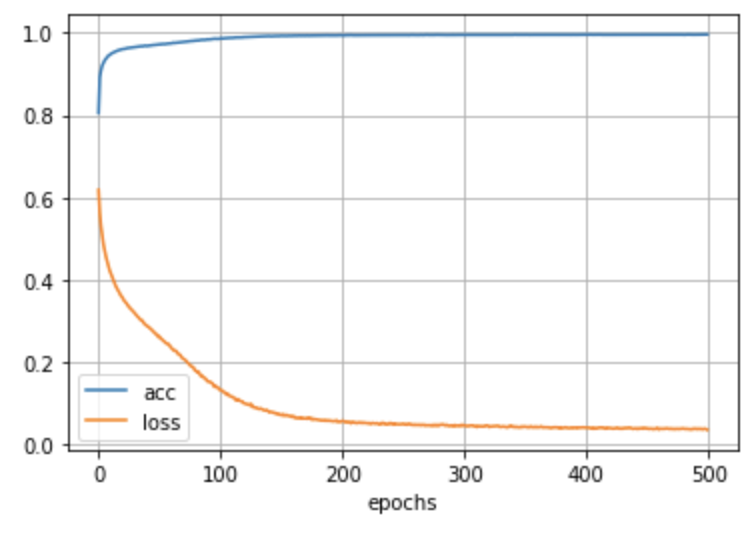
«C'est une transition d'apprentissage. Il semble que j'ai pu en apprendre suffisamment autour de 200 époques
―― Le taux de réponse correcte était élevé même dans les données TEST.
detector.evaluate(X_test, y_test)
150/150 [==============================] - 0s 873us/step
[0.018092377881209057, 0.9983475764592489]
--Il semblait que la prédiction était presque exacte par rapport à l'étiquette correcte des données TEST (bleu: orange correct: prédiction).
C'est trop prévisible et quelque chose ne va pas
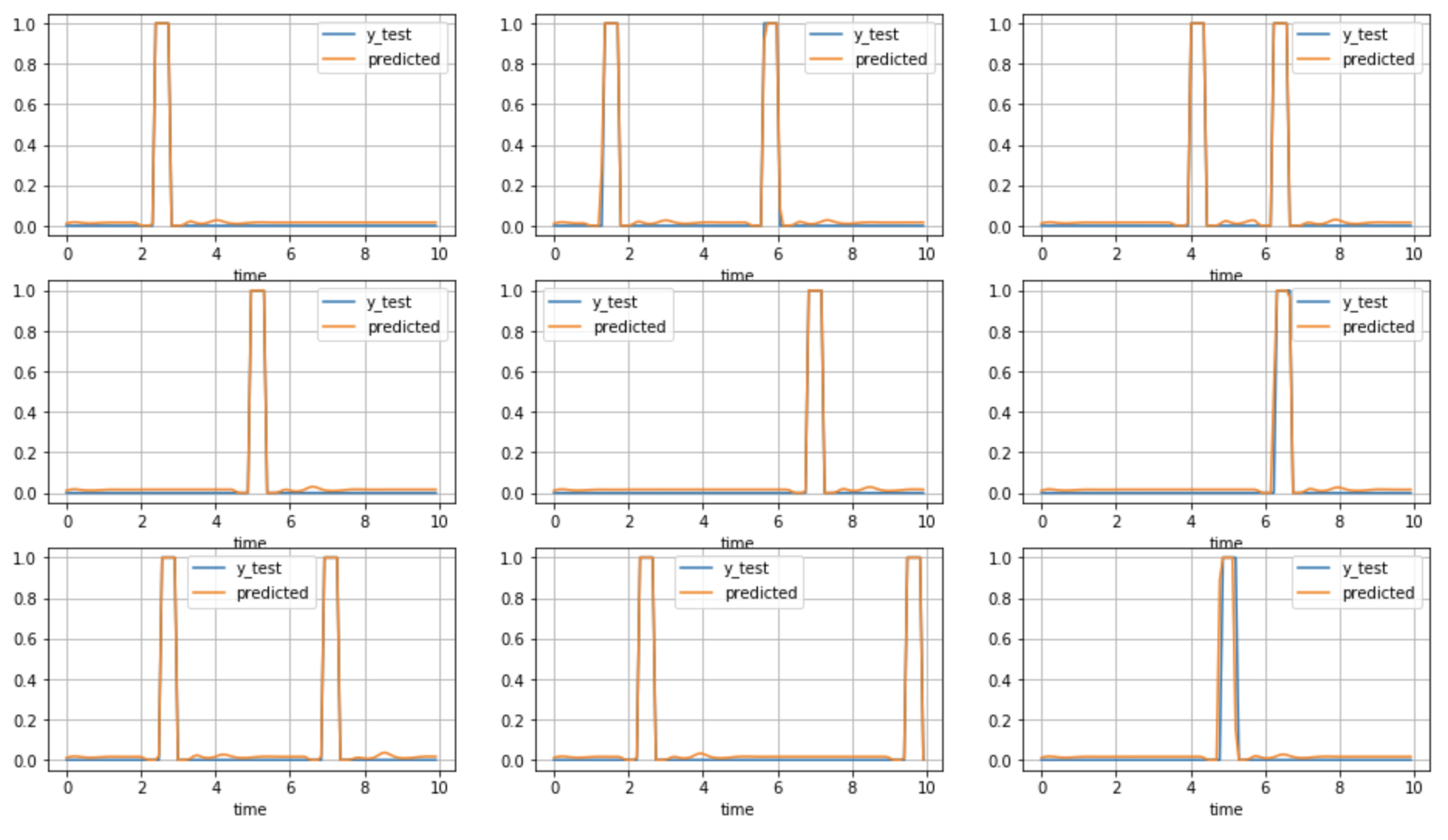
en conclusion
«J'ai approfondi ma compréhension du flux de la génération de données à l'apprentissage. ――C'est devenu un modèle simple qui ne détecte que la voix, mais j'ai appris
- La quantité et la variation des données d'entraînement étaient insuffisantes -Puisqu'il n'y a pas de variation dans les données vocales, il semble qu'il réagira à d'autres mots
- Peut-être qu'il s'agit simplement de détecter la partie que vous synthétisez
À l'avenir, je pense que ce serait bien si nous pouvions améliorer le modèle et les données d'apprentissage, et utiliser les résultats pour créer une application.
Merci beaucoup. Bonne année également cette année.
référence
Recommended Posts